K-Nearest Neighbour trong opencv2
Bài đăng này đã không được cập nhật trong 4 năm
1. K-Nearest Neighbour (kNN)
- K-nearest neighbor (KNN) là một trong những thuật toán supervised-learning đơn giản nhất trong Machine Learning. Ý tưởng của KNN là tìm ra output của dữ kiệu dựa trên thông tin của những dữ liệu training gần nó nhất. Để hiểu về ý tưởng của KNN thì trước hết ta xem hình ảnh dưới đây
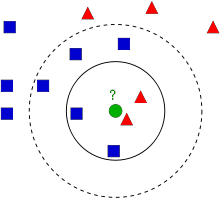
- Giả sử có một bài toán được đặt ra: mình đang thích một bạn gái xinh xắn, tuy nhiên mình là SKY vậy nên mình cần biết cô gái này có phải là fan GD hay không. Làm thế nào để xác định cô gái có phải fan GD hay ko, mình quyết định tìm hiểu xem bạn cô gái này có phải fan GD hay không, nếu như cô ấy chơi với nhiều người là fan GD thì gần như có thể kết luận cổ là fan GD. Sau một thời gian tìm hiểu thì mình đã vẽ tất cả thông tin trên hình vẽ ở trên.
- Có thể dễ dàng thấy trên hình có 2 loại : hình vuông màu xanh và tam giác màu đỏ được phân bố trên hình, trong đó thì hình màu xanh biểu diễn cho những người là fan GD, màu đỏ biểu diễn những người không phải là fan GD. Tiếp đến chấm tròn màu xanh là cô gái mình đang muốn biết là fan GD hay không, khoảng cách giữa chấm tròn và các điểm còn lại biểu thị mức độ thân thiết của cô bạn gái với những người bạn.
- Vậy với những dữ liệu trên làm thế nào để ta xác định cô gái thuộc nhóm nào? Phương pháp đơn giản nhất là kiểm tra xem cô gái chơi thân với người nào nhất tức là tìm xem điểm gần chấm xanh nhất thuộc class nào(hình vuông màu xanh hay tam giác màu đỏ). Từ hình trên ta có thể dễ dàng thấy điểm gần chấm xanh nhất là hình tam giác màu đỏ, do đó nó sẽ được phân loại thành tam giác đỏ. Phương pháp này gọi là simply Nearest Neighbour vì điểm cần phân loại chỉ phụ thuộc nào điểm gần nó nhất
- Có một vấn đề trong phương pháp trên, có thể là điểm màu đỏ gần điểm ta đang xét nhất tuy nhiên xung quanh đó có rất nhiều điểm xanh. Vì vậy, việc xét điểm gần nhất là chưa đủ, thay vào đó ta sẽ xét k điểm gần nhất. Giả sử, ta lấy k=3, dự theo hình ảnh trên, ta có thể dễ dàng nhận ra có 2 điểm đỏ và 1 điểm xanh gần điểm ta đang xét nhất. Do đó, chấm xanh vẫn được phân loại thành hình tam giác đỏ. Nếu ta lấy k=7, thì hiện tại xung quanh có 5 điểm xanh 2 điểm đỏ, lúc này chấm xanh lại được xếp vào hình vuống xanh. Vì vậy, việc chọn giá trị k thực sự quan trọng. Có 1 điều không biết các bạn có nhận ra không nhưng nếu ta lấy k=4 thì sẽ có 2 điểm xanh, 2 điểm đỏ, đây là 1 tie. Vì vậy, người ta thường chọn k là số lẻ. Đó là ý tưởng của KNN
- Với trường hợp k=4 hay là các trường hợp tie, lúc này LNN sẽ so sánh khoảng cách của các điểm neighbour với điểm ta đang xét.
Ưu điểm
- Dễ sử dụng và cài đặt
- Độ phức tạp tính toán nhỏ
- Việc dự đoán kết quả của dữ liệu mới rất đơn giản.
Nhược điểm
- Với K nhỏ, kinh gặp nhiễu dễ đưa ra kết quả ko chính xác
- Cần thời gian lưu trainning set, khi dữ liệu trainning và test tăng lên thì sẽ tốn rất nhiều thời gian
2.KNN trong opencv
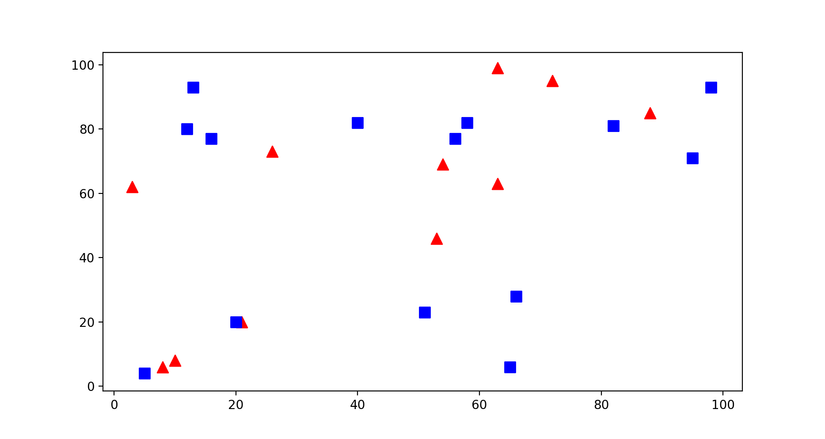
Như bài toán đã nói ở trên, bây giờ ta sẽ thực hiện phương pháp được nêu. Có 2 loại: hình vuông màu xanh: class-0 và tam giác màu đỏ: class-1. Trước hết ta tạo random 25 được phân loại thành class 0 và 1, đây chính là các điểm ban đầu như trên hình vẽ
trainData = np.random.randint(0,100,(51,2)).astype(np.float32)
responses = np.random.randint(0,2,(51,1)).astype(np.float32)
red = trainData[responses.ravel()==0]
blue = trainData[responses.ravel()==1]
Đây là kết quả được tạo ra
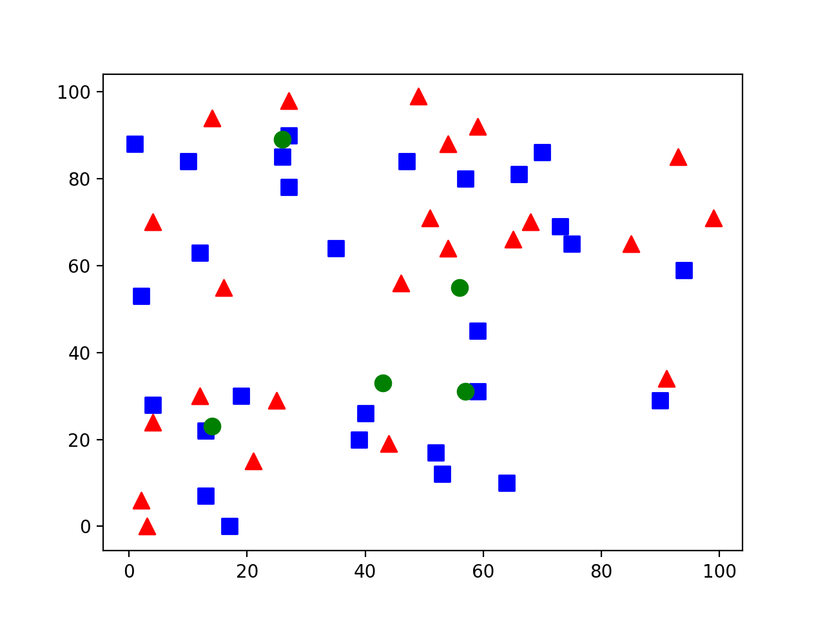
 Tiếp đến chúng ta sẽ tạo ra các điểm mới và sử dụng KNN trong opencv để phân loại chúng vào các class
Tiếp đến chúng ta sẽ tạo ra các điểm mới và sử dụng KNN trong opencv để phân loại chúng vào các class
newpoint = np.random.randint(0,100,(5,2)).astype(np.float32)
plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o')
knn = cv2.ml.KNearest_create()
knn.train(trainData,cv2.ml.ROW_SAMPLE,responses)
ret, results, neighbours, dist = knn.findNearest(newpoint, 3)
Và đây là kết quả
3.KNN và MNIST
Từ ví dụ ở trên thì mình đã thử xây dựng model cho mnist dataset
MNIST là bộ cơ sở dữ liệu lớn nhất về chữ số viết tay và được sử dụng trong hầu hết các thuật toán nhận dạng hình ảnh.
MNIST bao gồm hai tập con: tập dữ liệu huấn luyện có 60000 ví dụ khác nhau về chữ số viết tay từ 0 đên 9, tập dữ liệu kiểm tra có 10000 ví dụ khác nhau. Tất cả đều đã được gán nhãn. Mỗi ảnh trong MNIST là một ảnh đen trắng , có kích thước 28x28 pixel (tổng cộng 784 pixels).
Bạn có thể download dataset của mnist tại http://yann.lecun.com/exdb/mnist/
Đầu tiên ta cần load data training và data test, mình có sử dụng thêm python-mnist để load dữ liệu từ file dataset
mnist = MNIST(mnist_dir_path)
images_train, labels_train = mnist.load_training()
images_test, labels_test = mnist.load_training()
Tiếp đến là tạo một object KNearest, mình sử dụng opencv ver 3.0.0 với các version 2.x thì có thể sử dụng knn = cv2.KNearest(). sau đó sẽ sử dụng train data và train label để tranning. KNearest hỗ trợ nhiều tham số khác, tuy nhiên opencv-python chỉ support cv2.ml.ROW_SAMPLE với các ver 2.x thì ta không cần tham số này
model = cv2.ml.KNearest_create()
X_train = np.float32(images_train)
y_train = np.float32(labels_train)
model.train(X_train,cv2.ml.ROW_SAMPLE, y_train)
Khi đã có được model ta sẽ tiến thành chạy với data test để đánh giá độ chính xác, ở đây mình chọn k=3, với những gái trị k khác có thể sẽ cho ra kết quả khác
X_test = np.float32(images_test)
retval, results, neigh_resp, dists = model.findNearest(X_test, 3)
correct = np.count_nonzero(results.flatten() == labels_test)
accuracy = correct*100.0/len(labels_train)
print accuracy
Kết quả mình nhận được là 98.6716666667, tốt hơn những gì mong đợi
Để kiểm tra model mình đã chạy thử với ảnh như sau 
img = cv2.imread(img_path, 0)
img = split2d(img)
retval, results, neigh_resp, dists = model.findNearest(np.float32(img), 3)
Đây là kết quả trả về, chỉ có duy nhất một số cuối cùng bị sai
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 3. 3. 3. 3. 3. 3.
3. 3. 3. 3. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 5. 5. 5. 5.
5. 5. 5. 5. 5. 5. 6. 6. 6. 6. 6. 6. 6. 6. 6. 6. 7. 7.
7. 7. 7. 7. 7. 7. 7. 7. 8. 8. 8. 8. 8. 8. 8. 8. 8. 8.
9. 9. 9. 9. 9. 9. 9. 9. 9. 0.]
Ngoài ra, mình cũng thử với bộ datase Iris flower. Iris là một bộ dữ liệu nhỏ chỉ chứa thông tin của ba loại hoa Iris khác nhau: Iris setosa, Iris virginica và Iris versicolor. Mỗi loại có 50 bông hoa được đo với dữ liệu là 4 thông tin: chiều dài, chiều rộng đài hoa và chiều dài, chiều rộng cánh hoa. Kết quả trả ra cũng vô cùng tốt. Ngoài ra bạn có thể thử với một số bộ dữ liệu chữ viết tay như http://archive.ics.uci.edu/ml/datasets/Letter+Recognition
All rights reserved
