Tìm hiểu về thư viện dask trong python
Bài đăng này đã không được cập nhật trong 7 năm
Để giới thiệu về dask trước tiên mình xin lấy một ví dụ về bài toán mình hay gặp đó là xử lý một Dataset lớn, thông thường mọi người hay sử dụng panda, tuy nhiên khi mình muốn lấy ra một metrics thì mất rất lâu đôi khi còn gặp tình trạng freeze. Với một lượng data lớn rơi vào khoảng hàng triệu dòng mà sử dụng cùng với panda thì mình luôn gặp tình trạng phải chờ đến vài phút chỉ để xử lý một average đơn giản của một Series. Trong lúc này mọi người thường nghĩ đến sử dụng Hadoop hoặc Spark nhưng theo ý kiến mình thì Hadoop và Spark phù hợp hơn khi xử lý data lớn đến hàng tỷ dòng. Trong trường hợp này mình thường sử dụng dask và đặc biệt với những người đã quen sử dụng numpy, panda và chưa thể tìm hiểu ngay về Hadoop.
Đơn giản thì dask cung cấp cho bạn một abstraction có numpy, pandas, list và hơn hết bạn có thể xử lý các operation song song và multicore processing (đa lõi)
1. DataFrame
Một Dask DataFrame được hiểu là một parallel DataFrame lớn gồm có nhiều Pandas DataFrames nhỏ hơn phân chia theo index. Mỗi operation trên Dask DataFrame sẽ trigger các operation trên các Pandas DataFrames con. Nói một cách đơn giản thì một Dask DataFrame thì được tạo thành từ nhiều Pandas DataFrames do đó nên api của Dask DataFrame giống như là một subset của pandas api. Tuy nhiên api của Dask DataFrame vẫn có 1 số điểm khác biệt:
>>> import dask
>>> import dask.dataframe as dd
>>> df = dask.datasets.timeseries()
>>> df
Dask DataFrame Structure:
id name x y
npartitions=30
2000-01-01 int64 object float64 float64
2000-01-02 ... ... ... ...
... ... ... ... ...
2000-01-30 ... ... ... ...
2000-01-31 ... ... ... ...
Dask Name: make-timeseries, 30 tasks
khi bạn muốn show kết quả giống dataframe của padas ta có thể dùng method compute
>>> df2 = df[df.y > 0]
>>> df3 = df2.groupby('name').x.std()
>>> df3.compute()
name
Alice 0.578483
Bob 0.574182
Charlie 0.578127
Dan 0.576980
Edith 0.577755
Frank 0.575127
Name: x, dtype: float64
>>> computed_df = df3.compute()
>>> type(computed_df)
<class 'pandas.core.series.Series'>
DataFrame thường được dùng trong các trường hợp:
- Thao tác các datasets lớn, ngay cả khi các datasets đó không phù hợp với bộ nhớ
- Tăng tốc độ tính toán bằng cách sử dụng nhiều core
- Distributed computing (tính toán phân tán) trên các dataset lớn với đầu ra giống các operation của panda: groupby, join, time series
2. Bag
Dask Bag có thể được hiểu là các tính toán song song trên một tập lớn các object của python mà tập các object này thông thường không nên fit vào bộ nhớ.Bag thường được chọn để xử lý các data liên quan đến log hoặc json. Trong ví dụ mã này, tất cả các tệp json từ năm 2018 được nạp vào cấu trúc Dask Bag:
>>> import dask.bag as db
>>> import json
>>> records = db.read_text('data/2018-*-*.json').map(json.loads)
>>> records
dask.bag<map-loa..., npartitions=100>
Ta có thể dùng các method map filter aggregate để xử lý với Dask Bag
>>> records.filter(lambda record: record['age'] > 30).take(2)
({u'name': [u'Winfred', u'Mcfarland'], u'credit-card': {u'expiration-date': u'12/16', u'number': u'3799 164742 17478'}, u'age': 64, u'telephone': u'426-189-6039', u'address': {u'city': u'Summit', u'address': u'1217 Lydia Circle'}, u'occupation': u'Cable Jointer'}, {u'name': [u'Efren', u'Castaneda'], u'credit-card': {u'expiration-date': u'04/17', u'number': u'4375 4885 2239 5942'}, u'age': 48, u'telephone': u'826-457-7312', u'address': {u'city': u'Florissant', u'address': u'778 Laura Street'}, u'occupation': u'Marble Mason'})
>>> result = (records.filter(lambda record: record['age'] > 30).map(lambda record: record['occupation']).frequencies(sort=True).topk(10, key=1))
>>> result.compute()
[(u'Marble Mason', 1), (u'Cable Jointer', 1)]
Ngoài ra ta cũng có thể conver từ bag sang dataframe
>>> def flatten(record):
... return {
... 'age': record['age'],
... 'occupation': record['occupation'],
... 'telephone': record['telephone'],
... 'credit-card-number': record['credit-card']['number'],
... 'credit-card-expiration': record['credit-card']['expiration-date'],
... 'name': ' '.join(record['name']),
... 'street-address': record['address']['address'],
... 'city': record['address']['city']
... }
...
>>> df = b.map(flatten).to_dataframe()
>>> df.head()
age city credit-card-expiration credit-card-number \
0 64 Summit 12/16 3799 164742 17478
1 48 Florissant 04/17 4375 4885 2239 5942
name occupation street-address telephone
0 Winfred Mcfarland Cable Jointer 1217 Lydia Circle 426-189-6039
1 Efren Castaneda Marble Mason 778 Laura Street 826-457-7312
3. Array
Dask Array có thể được hiểu như một subset của numpy array
>>> import dask.array as da
>>> x = da.random.random((10000, 10000), chunks=(1000, 1000))
>>> x
dask.array<random_sample, shape=(10000, 10000), dtype=float64, chunksize=(1000, 1000)>
Bạn có thể sử dụng với syntax giống như numpy tuy nhiên vẫn cần sử dụng compute để có ouput giống như với định dạng output của numpy
>>> y = x + x.T
>>> z = y[::2, 5000:].mean(axis=1)
>>> z
dask.array<mean_agg-aggregate, shape=(5000,), dtype=float64, chunksize=(500,)>
>>> z.compute()
array([ 0.99924684, 0.9882781 , 0.99274818, ..., 1.00368868,
1.00002605, 0.99157146])
4. Cài đặt
Thông thường các thư viện của python thường cài thông qua pip, dask cũng vậy tuy nhiên bạn có thể chọn cài các phần core cơ bản bằng câu lệnh pip install dask hoặc chỉ định phần muốn cài pip install "dask[array]" hoặc pip install "dask[bag]" và cài tất cả các phần pip install "dask[complete]".
Ngoài ra dask còn có thể thiết theo phần cứng: thiết lập trên 1 máy hoặc 1 cụm máy hoặc một distributed cluster (cụm phân tán)
Dask có 2 loại task scheduler:
- Single machine scheduler: cung cấp các tính năng cơ bản trên một process hoặc thread pool, được thiết lập mặc định, rất đơn giản, dễ dàng sử dụng. Chỉ có thể được sử dụng trên một máy và không có khả năng mở rộng
- Distributed schedule: Cung cấp nhiều tính năng hơn, có thể chạy ở local hoặc phân tán trên 1 cluster
Khi bạn import dask, gọi
computelúc này bạn sẽ sử dụng single-machine scheduler đây là schedulẻ mặc định. Nếu muốn dùng dask.distributed scheduler ta cần phải set up thêm một Client
import dask.dataframe as dd
df = dd.read_csv(log/test.csv)
df.x.sum().compute()
from dask.distributed import Client
client = Client(...)
df.x.sum().compute()
Distributed computing có thể thiết lập bằng nhiều cách
- Manual Setup
- SSH
- Docker
- Cloud(Amazon, Google, Microsoft Azure,..)
- ...
5. Visualize
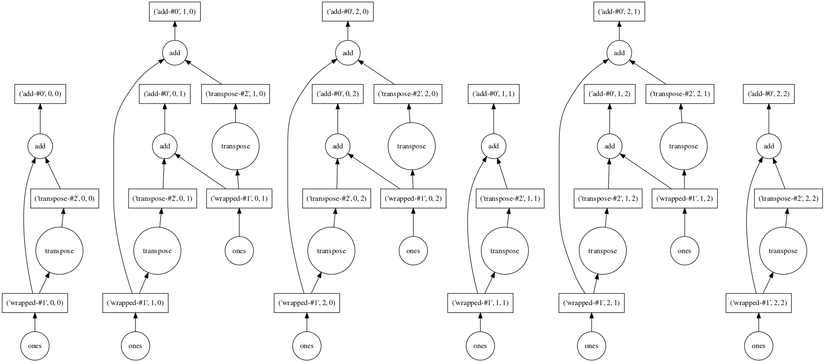
Trước khi thực hiện các tính toán của mình, dask cung cấp cho bạn 1 method visualize giúp bạn có thể trực quan hóa thảnh biểu đổ. Biểu đồ này có thể giúp chúng ta tìm ra được bottlenecks, một số điểm chưa hợp lý, các task đang phụ thuộc lẫn nhau,..
Method visualize họat động giống với phuơng thức của compute ngọai trừ việc compute trả về kết qủa còn visualize thì trả về 1 graph.
Tuy nhiên graph của visualize được hiển thị bằng GraphViz, do vậy bạn cần cài GraphViz trước, và việc hiển thị 1 graph lớn cũng khá khó khắn
import dask.array as da
x = da.ones((15, 15), chunks=(5, 5))
y = x + x.T
# y.compute()
y.visualize(filename='transpose.svg')
All rights reserved
