Cách scrape một trang web bằng python và BeautifulSoup
Bài đăng này đã không được cập nhật trong 7 năm
Trong thực tế đôi khi bạn cần thu thập 1 số lượng lớn thông tin (ảnh, video, bài viết, ..) từ 1 trang web để phục vụ cho nhiều mục đích khác nhau. Tuy nhiên, để lấy các thông tin này một cách thù công thì cần rất nhiều thời gian. Lúc này thì bạn cần phải scrape trang web đó. Web scraping nói đơn ginar là một kỹ thuật giúp lấy thông tin thông tin từ các trang web. Kỹ thuật này chủ yếu tập trung vào việc chuyển đổi dữ liệu phi cấu trúc (HTML) trên web thành dữ liệu có cấu trúc (cơ sở dữ liệu, bảng tính,..). Có rất nhiều cách để crapy một trang web, thậm chí bạn có thể vào trang https://import.io/ cũng giúp bạn scrape một trang web, nhưng trong bài viết này mình sẽ sử dụng python.
1. Trước khi scrape một trang web
- Quan trọng nhất bạn cần kiểm tra phần Điều khoản và Điều kiện(Terms and Conditions ) của trang web trước khi scrape trang đó. Hãy cẩn thận đọc các vấn đề về việc sử dụng dữ liệu hợp pháp. Thông thường thì dữ liệu scrape không nên sử dụng cho các mục đích thương mại.
- Không nên tạo quá nhiều request đến trang web trong 1 thời điểm, vì nó có thể gấy ra sập trang web(có thể bị liệt vào ấn công ddos
 ). Thông thường thì 1 request / 1s là ổn
). Thông thường thì 1 request / 1s là ổn - Trang web sẽ thường xuyên thay đổi giao diện, bố cục (HTML) nên bạn cần thường xuyên cập nhập code của mình
2. Thư viện BeautifulSoup
Beautiful Soup là một thư viện Python để lấy dữ liệu ra khỏi HTML và XML. Nó phân tích các cấu trúc thành các dữ liêu, các dữ liệu này thường được dùng để điều hướng, tìm kiếm, ... Phiên bản hiện tại là BeautifulSoup 4, còn BeautifulSoup3 đã ngừng phát triển và hầu như không được dùng nữa
Cài đặt pip install BeautifulSoup4
Filter
Có nhiều cách khác nhau để filter: dựa trên tag, attributes, text,... hoặc kết hợp các kiểu trên
content = urllib2.urlopen(url)
soup = BeautifulSoup(content)
print(soup.prettify())
#<html>
# <head>
# <title>
# Demo Beautiful soup
# </title>
# </head>
# <body>
# <p class="title">
# <b>
# Hello, world!
# </b>
# </p>
# <p class="story">
# Lorem ipsum dolor sit amet
# <a class="thumb_1" href="http://example.com/demo1" id="link1">
# Demo1
# </a>
# ,
# <a class="thumb_2" href="http://example.com/demo2" id="link2">
# Demo2
# </a>
# and
# <a class="thumb_3" href="http://example.com/demo3" id="link3">
# Demo3
# </a>
# Consectetur adipiscing elit
# </p>
# <p class="story">
# ...
# </p>
# </body>
#</html>
# tìm tất cả các thẻ a trong page
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/demo1
# http://example.com/demo2
# http://example.com/demo3
#tìm tag qua id, hoặc attubutes
soup.find(id="link1")
# <a class="thumb_1" href="http://example.com/demo1" id="link1"> Demo1</a>
soup.find_all('a',attrs={"class": "thumb_3"})
[<a class="thumb_3" href="http://example.com/demo3" id="link3"> Demo3</a>]
import re
for tag in soup.find_all(re.compile("^img")):
print(tag.name)
# Tìm tất cả các thẻ a và b
print soup.find_all(["a", "b"])
#[<b>Hello, world!</b>,
#<a class="thumb_1" href="http://example.com/demo1" id="link1"> Demo1</a>,
#<a class="thumb_2" href="http://example.com/demo2" id="link2"> Demo2</a>,
#<a class="thumb_3" #href="http://example.com/demo3" id="link2"> Demo3</a>]
# in ra tất cả các tag
for tag in soup.find_all(True):
print(tag.name)
Object Soup
Với một object soup giúp ta có thể lấy ra attibutes của tag, parent hay child của tag đó
# lấy thông tin của pgae hoặc tag
soup.title
# <title>Demo Beautiful soup</title>
soup.title.name
# u'title'
soup.title.string
# u'Demo Beautiful soup'
soup.title.parent.name
# u'head'
soup.p.b
# <b>Hello, world!</b>
Soup object
Ví dụ scrape một trang web
Trong ví dụ này mình sẽ scrape từ 1 trang chia sẻ ảnh các trích dẫn, ta sẽ lấy text và ảnh từ trang này
- Inspecting trang web
- Trước tiên ta cần xem xét bố cục của trang web, các thẻ html được đặt như thế nào bằng cách sử dụng inspect của brower
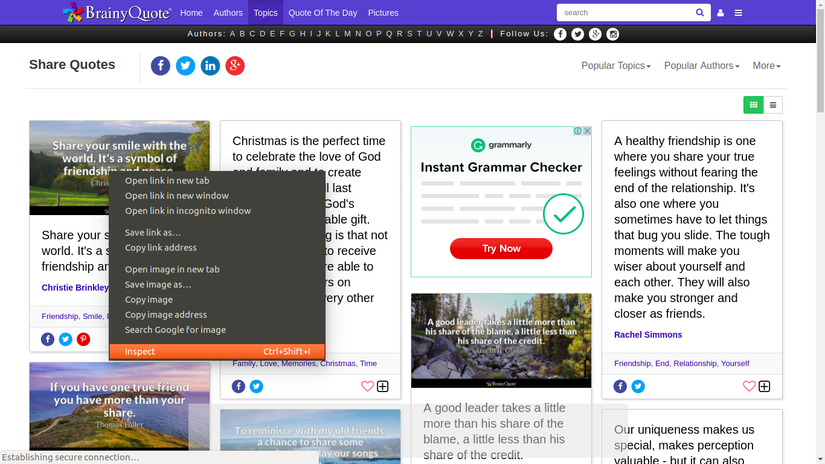 Trong ví dụ này ta cần lấy ảnh từ thẻ img có cấu trúc như bên dứới
Trong ví dụ này ta cần lấy ảnh từ thẻ img có cấu trúc như bên dứới
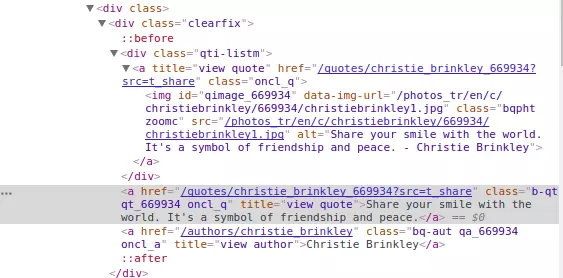
- import thư viện
import urllib2 #với python: import urllib.request
from bs4 import BeautifulSoup # func để parse data
#set url của trang web
url = "https://www.brainyquote.com/topics/share"
#get trang web về
page = urllib2.urlopen(url) #Với python 3: urllib.request.urlopen(wiki)
#Parse html từ 'page'và store thành format của Beautiful Soup
soup = BeautifulSoup(page)
for tag in soup.find_all('a', attrs={"title": "view quote"}):
if tag.img:
print tag.img['alt'], tag.img['src']
else:
print tag.getText()
Cho tới đây ta có thể lấy được các text mong muốn, từ các thông tin này thì có thể dễ dàng save lại thành dạng csv để lưu trữ
BeautifulSoup rất hữu đụng cho các bài toàn phân tích dữ liệu, xử lý với nhiều data nhưng mà việc tìm kiếm data từ nhiều nguồn cần rất nhiều thời gian.
All rights reserved
