
Programming Language Detection: Phát hiện ngôn ngữ lập trình dễ hay khó ???
Bài đăng này đã không được cập nhật trong 5 năm
Sau 2 tháng ẩn danh do lười viết và cạn ý tưởng (thật ra mình vẫn đang draft 1 bài viết nữa, cơ mà vẫn chưa ưng lắm nên sẽ publish sau), hôm nay mình đã quay trở lại Viblo với một vài thứ hay ho và thực tế hơn cả.
Nếu các bạn là người hay theo dõi các bài viết của mình, hoặc đơn giản, có hứng thú với tiêu đề bài viết này của mình, thì mình xin mạnh dạn đoán các bạn là 1 coder chân chính hoặc ít nhất đã tiếp xúc với trên 3 ngôn ngữ lập trình trở lên (Pascal nè, C nè, C++ nè, ...). Việc bắt đầu làm quen với một ngôn ngữ lập trình mới, luôn là một quá trình vừa khó và vừa dễ.
- Khó ở đây là việc khác nhau giữa các ngôn ngữ lập trình khác nhau về syntax (cú pháp), IO (nhập xuất), variable (các biến cơ bản), ... các yếu tố này có thể giống nhau ở 1 vài ngôn ngữ , lại có thể rất khác nhau ở các ngôn ngữ khác và thật sự rất khó để bắt đầu.
- Tuy nhiên, khi bạn đã quen với việc thường xuyên học ngôn ngữ mới, bạn sẽ rút ra được kinh nghiệm là nên học để nắm vững các vấn đề nào trước, việc trở nên thành thạo trong ngôn ngữ đó sẽ chỉ là vấn đề thời gian (và thời gian ở đây là rất ngắn) và tư duy giải quyết của bạn.
Đó là quá trình con người học và nắm vững 1 ngôn ngữ. Tuy nhiên, nếu bây giờ bạn nhìn vào đoạn code dưới đây, bạn có thể đoán ra đoạn code được viết bằng ngôn ngữ lập trình nào chứ ???
(defn sample
"Given a map of keys to occurrence counts, return a random key,
respecting the probability distribution reflected in the map.
For example, given the map {:a 10 :b 15 :c 25}, the function should
return :c approximately 50% of the time, :b 30% of the time, and :a
20%."
[m]
(let [total (reduce + (vals m))
pick (inc (rand-int total))]
(loop [cumulative 0
remaining (sort-by val m)]
(let [c (+ cumulative (val (first remaining)))]
(if (<= pick c)
(key (first remaining))
(recur c (rest remaining)))))))
Kết quả là
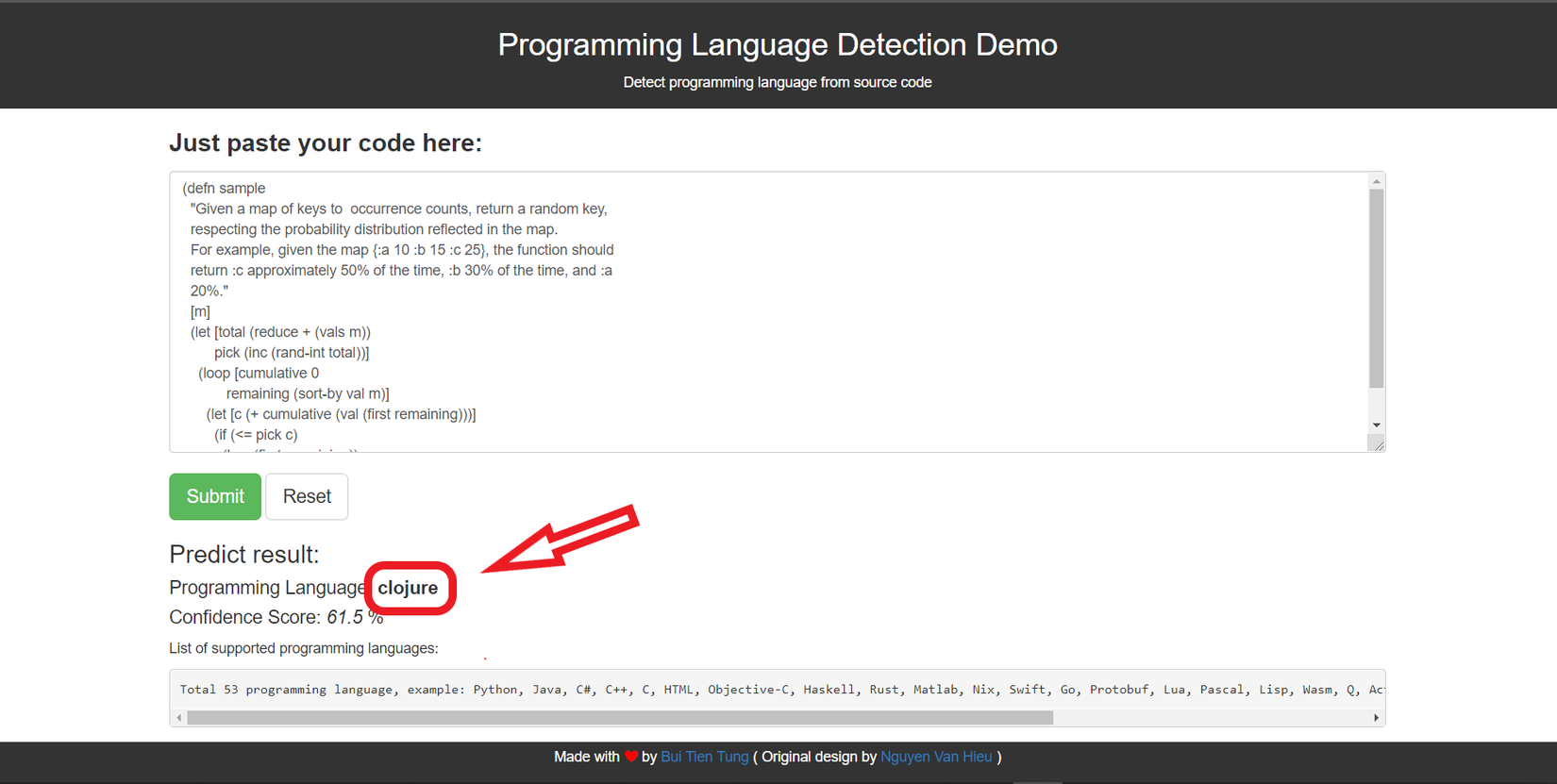
Đây chính là phần mình sẽ trình bày trong các phần dưới đây của bài viết. Chúng ta sẽ cùng xây dựng một mô hình machine learning (chính xác hơn là Deep Learning) cho phép dự đoán ra được ngôn ngữ lập trình mà đoạn code bất kì đang sử dụng (Programming Language Detection). Ở cuối bài sẽ là phần đưa model của chúng ta lên thành 1 web app demo để mọi người có thể cùng test và đánh giá kết quả.
Link web demo : https://programming-language-detection-demo.glitch.me/
OK, bắt đầu nào 
Note: Nhớ upvote nếu thấy hứng thú nha
1. Programming Language Detection
1.1 Đặt vấn đề
Vấn đề detect ngôn ngữ nói chung và detect ngôn ngữ lập trình nói riêng là vấn đề liên quan nhiều đến việc phân tích cấu trúc của văn bản, cú pháp của câu cũng như keyword của từng ngôn ngữ.
Nhìn từ góc độ của machine learning, chúng ta có 1 bài toán quen thuộc hơn : dữ liệu là các đoạn code, và label của những đoạn code này chính là ngôn ngữ của nó.
Công việc sau đó của chúng ta sẽ chỉ là biến các đoạn code này thành 1 vector (bằng 1 thuật toán nào đó) và đưa vào một mô hình phân lớp. Việc còn lại sẽ do máy móc lo liệu và bạn có model đã được huấn luyện của riêng mình
==> Bài toán : Multi-Class Classification
Một số điểm chúng ta cần chú ý sau đây :
- Biết là multi-class classification, nhưng dữ liệu ở đâu ra ?
- Biến code --> vector thì biết làm như nào ? Code là text, là string mà ?

1.2 Thu thập dữ liệu
Chúng ta sẽ đi giải quyết vấn đề đầu tiên ở đây trước: "Dữ liệu ở đâu ra ???"
Nếu các bạn có để ý một chút thì chúng ta đã có sẵn 2 kho dữ liệu khổng lồ chứa các source code đa dạng về đủ thể loại, và đương nhiên đã được gán nhãn sẵn (tiện lợi ghê).
-
Stackoverflow
Stackoverflow là nền tảng hỏi đáp trực tuyến lớn nhất, đáng tin cậy nhất dành cho những người lập trình để tìm hiểu, chia sẻ kiến thức phát triển các kỹ năng mới và tìm kiếm cơ hội việc làm của họ. Được thành lập vào năm 2008 bởi Jeff Atwood và Joel Spolsky với hơn 50 triệu lập trình viên chuyên nghiệp truy cập Stack Overflow mỗi tháng nhiều năm nay, Stack Overflow đã là một trong những nguồn tham khảo phổ biến nhất của giới lập trình viên. Các câu hỏi trên Stack Overflow cũng thường xuất hiện đầu trang tìm kiếm Google về hầu hết các vấn đề liên quan tới lập trình.
Bạn có thể gọi đơn giản hơn, Stackoverflow đầu tiền là nơi chúng ta nghĩ đến khi gặp bug, và tất nhiên, chúng ta gặp bug như cơm bữa, thế nên các đoạn code trên stackoverflow là 1 nguồn dữ liệu khổng lồ.
Các bạn có thể dễ dàng lấy được các đoạn code này trong mục Tag của stackoverflow. Chi tiết về cách crawl code trên stackoverflow, các bạn có thể tham khảo bài viết https://nguyenvanhieu.vn/du-doan-ngon-ngu-lap-trinh-voi-machine-learning/

Tuy nhiên, một vấn đề của stackoverflow mà chúng ta không thể bỏ qua ở đây, đó là về độ tin cậy của các Tags. Thông thường, khi crawl 1 đoạn code về, chúng ta sẽ lấy luôn Tag để làm label cho đoạn code đó. Label này hoàn toàn có thể sai vì rất nhiều câu hỏi trên stackoverflow gắn những đoạn code không liên quan gì đến tag.
Trong bài viết này, mình lựa chọn 1 nguồn dữ liệu khác đáng tin cậy hơn : github
-
Github
GitHub là một hệ thống quản lý dự án và phiên bản code, hoạt động giống như một mạng xã hội cho lập trình viên. GitHub được sử dụng để hợp tác nhiều người lại với nhau, từ mọi nơi trên thế giới, lên kế hoạch, theo dõi và làm chung một dự án. GitHub cũng là một nền tảng lưu trữ online lớn nhất trên thế giới về các dự án nhiều người làm.
Crawl dữ liệu github như thế nào ??
Chúng ta sẽ để ý một vài điểm như sau :
-
Github cho phép search các repository theo từng ngôn ngữ lập trình khác nhau (mà không cần yêu cầu đăng nhập)
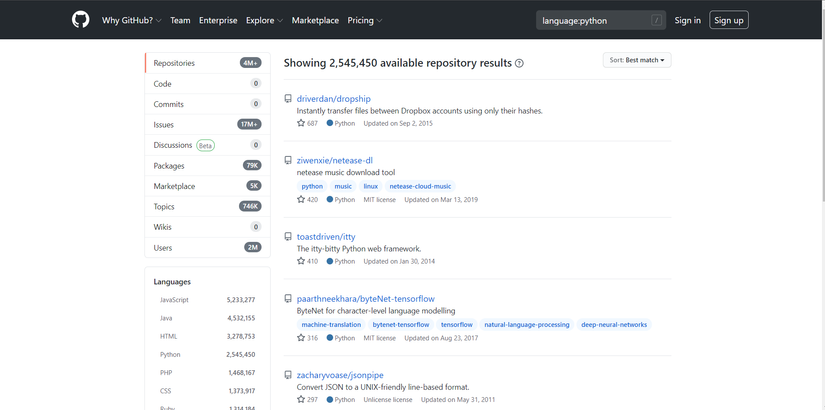
-
Ở trong mỗi repository, chúng ta tiếp tục có thể search ra từng file được viết theo một ngôn ngữ lập trình cụ thể
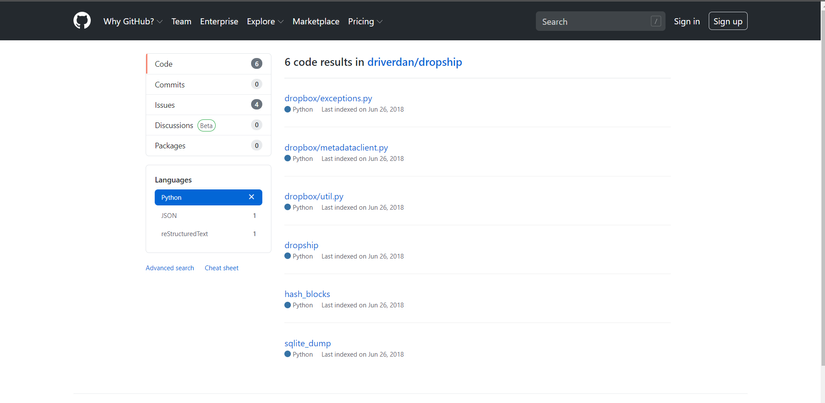
Bằng những quan sát này, chúng ta có 1 cách tiếp cận đơn giản hơn bao giờ hết để xây dựng một bộ dữ liệu của riêng chúng ta. Hãy cùng quan sát đoạn code dưới đây (chỉ đơn giản sử dụng thư viện requests chứ không cần Selinium hay thư viện gì đó quá phức tạp gì cả)
search_link = "https://github.com/search?p={}&q=language%3A{}&type=Repositories"
i = 1
lang = python
while (True):
print("Crawl page {} in language {}:".format(i, lang))
search_url = search_link.format(i, lang)
response = requests.get(search_url)
parser = BeautifulSoup(response.text, 'html.parser')
list_repo = parser.find_all('li', class_="repo-list-item")
print("Found {} repo".format(len(list_repo)))
if (len(list_repo) == 0):
break
links = [repo.find("a").get("href") for repo in list_repo]
i += 1
Với đoạn code trên, chúng ta có thể dễ dàng lấy được link github của các repository liên quan đến ngôn ngữ mình muốn. Thứ duy nhất chúng ta cần cung cấp là tên ngôn ngữ lập trình đó . Tiếp theo :
index = 0
for link in tqdm(links):
link = "https://github.com/{}/search?l={}".format(link, lang)
source = requests.get(link)
parser = BeautifulSoup(source.text, 'html.parser')
list_code = parser.find_all('div', class_="code-list-item")
for code in list_code:
link_code = "https://raw.githubusercontent.com" + code.find("a").get("href").replace("/blob", "")
source_code = requests.get(link_code)
f = open(os.path.join(out_folder, "{}_{}.txt".format(lang, index)), 'wb')
f.write(source_code.content)
f.close()
index += 1
Ở trong mỗi repository, bằng cách tương tự, chúng ta có thể lấy ra link của các file code có sử dụng ngôn ngữ đó. Cuối cùng, bằng việc thay link github thường thành link raw github, công việc crawl đến đây là hoàn thành. Ở đây, mình lưu các file code thành các file .txt và đặt tên theo format chung là "languagename_index.txt", lưu vào các folder riêng.
Sau một vài ngày đi crawl, thành quả là chúng ta có tất cả hơn 285.000 file code với khoảng 53 loại ngôn ngữ khác nhau.
Link data của mình ở đây: https://drive.google.com/file/d/1mGVnbimQotX0cJsZ_ErEjY66D7FC4dbT/view?usp=sharing (các bạn hoàn toàn có thể crawl thêm dữ liệu về các ngôn ngữ lập trình khác nếu các bạn muốn)
1.3 Các hướng giải quyết
Sau khi đã có đủ lượng dữ liệu cần thiết, chúng ta lại tiếp tục có 3 hướng tiếp cận để giải quyết bài toán chủa chúng ta
-
Deep Neural Network
Cách tiếp cận được nghĩ đến đầu tiên và đơn giản nhất là chúng ta sẽ sử dụng một mạng Deep Neural Network (nhỏ thôi, 1-2 lớp Hidden Layer cũng đủ rồi) để phân loại các đoạn code này. Đươnng nhiên, các phương pháp khác như Decision Tree hay SVM cũng hoàn toàn có thể sử dụng được, nhưng mình nghĩ DNN sẽ có lợi thế hơn với dữ liệu dạng này. Về embedding vector, chúng ta cũng sử dụng cách đơn nhất : Bag of Word.

-
FastText
Đây là mã nguồn mở của Facebook, được giớ thiệu năm 2016. FastText là một thư viện mã nguồn mở, miễn phí, nhẹ, cho phép người dùng tìm hiểu các cách biểu diễn văn bản và phân loại văn bản. Nó là một phiên bản nâng cấp của Word2Vec. Để biết thêm chi tiết, các bạn có thể tham khảo thêm tại docs của fastText tại đây
Một số điểm chú ý là khi train fastText, format của dữ liệu cần theo đúng chuẩn của fastText, thế nên chúng ta cần chỉnh lại format của dữ liệu chúng ta vừa crawl 1 chút.
__label__1 this is my text
__label__2 this is also my text
Tuy nhiên, trong bài viết này, mình sẽ không đi sâu về phương pháp này, đơn giản là vì đã có một bài viết khác rất chi tiết về cách áp dụng fastText cho programming language detection của tác giả Nguyễn Văn Hiếu rồi. Các bạn có thể tìm đọc tại : Dự đoán ngôn ngữ lập trình với Machine learning

-
CodeBERT Transfer Learning
Cách thứ 3 này là một cách khá mới, được một người bạn của mình, Đào Quang Huy suggest. Bằng việc sử dụng một trong những mô hình ngôn ngữ mạnh mẽ và đang là trending trong lĩnh vực Xử lí ngôn ngữ tự nhiên ở đây là BERT, chúng ta sẽ transfer learning bằng cách lấy ra context vector từ cấu trúc của BERT và thêm 2 lớp Dense (hoặc Linear) để phục vụ cho tác vụ classification.
Phương pháp nghe hơi "lấy dao mổ trâu giết gà", tuy nhiên kì vọng sẽ đem lại những kết quả tốt vượt trội. Để transfer learning, hay chỉ đơn giản là muốn sử dụng BERT thôi thì pretrained model là điều không thể thiếu (lí do là chúng ta sẽ không bao giờ có mô hình Bert đủ tốt nếu chỉ có dữ liệu nhỏ nhoi của chúng ta). May mắn thay , chúng ta có codeBERT: https://github.com/microsoft/CodeBERT
CodeBERT: A Pre-Trained Model for Programming and Natural Languages. CodeBERT is a pre-trained model for programming language, which is a multi-programming-lingual model pre-trained on NL-PL pairs in 6 programming languages (Python, Java, JavaScript, PHP, Ruby, Go).
Hướng này mình xin dành cho các bạn hứng thú với BERT, các bạn thể triển khai tương tự như trong blog sau: Multi Class Text Classification With Deep Learning Using BERT

2. Coding
Có vẻ tất cả đã clear về ý tưởng, trong phần này, chúng ta sẽ cùng nhau triển khai code thuật toán. Thuật toán mình sử dụng ở đây là thuật toán đầu tiên: Sử dụng Deep Neural Network cùng Bag of Word. Một điểm đặc biệt là ở đây mình sẽ code bằng Tensorflow nhưng không phải Tensorflow Keras mà sẽ là Tensorflow Estimator API
The Estimators API was added to Tensorflow in Release 1.1, and provides a high-level abstraction over lower-level Tensorflow core operations. It works with an Estimator instance, which is TensorFlow's high-level representation of a complete model.
You can run Estimator-based models on a local host or on a distributed multi-server environment without changing your model. Furthermore, you can run Estimator-based models on CPUs, GPUs, or TPUs without recoding your model.

Các bạn có thể đọc thêm về so sánh giữa Keras và Estimator tại What's the difference between a Tensorflow Keras Model and Estimator?
2.1 DataLoader với Tensorflow Dataset
Trước tiên, chúng ta cần đọc file để lấy ra content và label tương ứng
def read_file(file_path):
"""Read a source file, return the content and the extension"""
data = tf.io.read_file(file_path)
filename = tf.strings.split([file_path], '/').values[-1]
label = tf.strings.lower(tf.strings.split([filename], '_').values[0])
return data, label
Thông thường việc preprocess với text sẽ là loại bỏ đi những stopword hoặc những từ không liên quan đến context vector. Tuy nhiên, trong bài toán này, mình sẽ giữ nguyên si nội dung của file, vì 1 vài lí do sau :
- Việc loại bỏ đi nhưng comment trong code sẽ đem lại hiệu quả tốt hơn, nhưng do cú pháp của các loại ngôn ngữ lập trình quá khác nhau, nên đôi khi cách comment trong code này lại có thể là cách định nghĩa biến, định nghĩa hàm trong code khác. Thế nên mình quyết định giữ nguyên comment.
- Việc loại bỏ các khoảng trắng (space) cũng có thể gây ảnh hưởng, ví dụ như trong python : "Python sử dụng kí tự ":" và "khoảng trắng thụt đầu dòng" (indentation). Một code block sẽ bắt đầu bằng một khoảng trắng thụt đầu dòng "indentation’"và kết thúc bằng 1 dòng không indentation hoặc indentation bằng với code block sub nếu có nhiều code block con như kiểu if lồng if"
Sau khi có content, chúng ta chỉ cần đơn giản tách nó thành từng bit sau đó nhóm lại theo Ngram (ở đây mình sử dụng n = 2). Có thể thêm padding là khoảng trắng để đưa về 1 list có độ dài cố định (ở đây là 10000)
def preprocess(data, label):
"""Process input data as part of a workflow"""
data = preprocess_text(data)
return {'content': data}, label
def preprocess_text(data):
"""Feature engineering"""
padding = tf.constant(['']*HyperParameter.NB_TOKENS)
data = tf.strings.bytes_split(data)
data = tf.strings.ngrams(data, HyperParameter.N_GRAM)
data = tf.concat((data, padding), axis=0)
data = data[:HyperParameter.NB_TOKENS]
return data
Các bước tuần tự là như trên, còn để thuận tiện nhất cho việc load data, chúng ta sẽ sử dụng Tensorflow Dataset. Các bạn có thể đọc thêm 1 bài viết ở đây : Chuẩn bị dữ liệu với Tensorflow Dataset của tác giả Phạm Minh Hoàng.
def build_input_fn(all_data_paths, mode):
pattern = all_data_paths[mode]
def input_function() -> tf.data.Dataset:
dataset = tf.data.Dataset
dataset = dataset.from_tensor_slices(pattern).map(read_file,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
if mode == "test":
return dataset.batch(1)
if mode == "train":
dataset = dataset.shuffle(Training.SHUFFLE_BUFFER).repeat()
dataset = dataset.map(preprocess, num_parallel_calls=tf.data.experimental.AUTOTUNE).batch(HyperParameter.BATCH_SIZE)
return dataset.prefetch(tf.data.experimental.AUTOTUNE)
return input_function
2.2 Build Model với Tensorflow Estimator API
Ở đây, chúng ta sẽ sử dụng tf.estimator.DNNLinearCombinedClassifier cho tác vụ phân lớp. Một số điểm chú ý cần quan tâm ở đây là
Input of train and evaluate should have following features, otherwise there will be a KeyError:
For each column in dnn_feature_columns + linear_feature_columns:
- if column is a CategoricalColumn, a feature with key=column name whose value is a SparseTensor.
- if column is a WeightedCategoricalColumn, two features: the first with key the id column name, the second with key the weight column name. Both features' value must be a SparseTensor.
- if column is a DenseColumn, a feature with key=column name whose value is a Tensor.
Key cho column name ở đây là "content", tương ứng với hàm preprocess trước đó.
def build(self, labels):
"""Build a Tensorflow text classifier """
strategy = tf.distribute.MirroredStrategy()
with TemporaryDirectory() as temporary_model_base_dir:
config = tf.estimator.RunConfig(
model_dir=temporary_model_base_dir,
save_checkpoints_steps=Training.CHECKPOINT_STEPS,
train_distribute=strategy
)
categorical_column = tf.feature_column.categorical_column_with_hash_bucket(
key='content',
hash_bucket_size=HyperParameter.VOCABULARY_SIZE,
)
dense_column = tf.feature_column.embedding_column(
categorical_column=categorical_column,
dimension=HyperParameter.EMBEDDING_SIZE,
)
return tf.estimator.DNNLinearCombinedClassifier(
linear_feature_columns=[categorical_column],
dnn_feature_columns=[dense_column],
dnn_hidden_units=HyperParameter.DNN_HIDDEN_UNITS,
dnn_dropout=HyperParameter.DNN_DROPOUT,
label_vocabulary=labels,
n_classes=len(labels),
config=config,
)
2.3 Trainning function
Vì Estimator API là một abstract class bậc cao rồi, nên hầu như công việc cũng không có gì quá khó khăn, ngoại trừ việc sử dụng các hàm hỗ trợ sẵn để load data và train model thôi (max_steps mình sử dụng là 10000 steps)
def training(estimator, all_data_paths, max_steps):
"""Train a Tensorflow estimator"""
train_spec = tf.estimator.TrainSpec(
input_fn=build_input_fn(all_data_paths, "train"),
max_steps=max_steps,
)
if max_steps > Training.LONG_TRAINING_STEPS:
throttle_secs = Training.LONG_DELAY
else:
throttle_secs = Training.SHORT_DELAY
eval_spec = tf.estimator.EvalSpec(
input_fn=build_input_fn(all_data_paths, "valid"),
start_delay_secs=Training.SHORT_DELAY,
throttle_secs=throttle_secs,
)
results = tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
training_metrics = results[0]
return training_metrics
Dưới đây là các thông số mà mình sẽ sử dụng cho mô hình, các bạn hoàn toàn có thể thay đổi và thử các tham số khác nhau:
class HyperParameter:
"""Model hyper parameters"""
BATCH_SIZE = 128
NB_TOKENS = 10000
VOCABULARY_SIZE = 5000
EMBEDDING_SIZE = max(10, int(VOCABULARY_SIZE**0.5))
DNN_HIDDEN_UNITS = [512, 256, 32]
DNN_DROPOUT = 0.5
N_GRAM = 2
class Training:
"""Model training parameters"""
SHUFFLE_BUFFER = HyperParameter.BATCH_SIZE * 10
CHECKPOINT_STEPS = 1000
LONG_TRAINING_STEPS = 10 * CHECKPOINT_STEPS
SHORT_DELAY = 60
LONG_DELAY = 5 * SHORT_DELAY
3. Đánh giá mô hình và phát triển ứng dụng web
Trước khi tiến hành trainning, mình có chia bộ dữ liệu thành 3 phần : TRAIN, VALID và TEST.
def get_all_data_paths(source_files_dir):
"""Get all data file, divide into TRAIN, VALID, TEST
:return: Dictionary.
"""
TRAIN = set()
TEST = set()
lang_paths = [os.path.join(source_files_dir, name) for name in os.listdir(source_files_dir)
if os.path.isdir(os.path.join(source_files_dir, name))]
for path in lang_paths:
files = set([os.path.join(path, name) for name in os.listdir(path) if ".txt" in name])
rand = set(random.sample(files, int(0.85*len(files))))
TRAIN |= rand
TEST |= files - rand
VALID = set(random.sample(TRAIN, int(0.2*len(TRAIN))))
TRAIN = TRAIN - VALID
return {
"train" : list(TRAIN),
"valid" : list(VALID),
"test" : list(TEST)
}
2 phần TRAIN và VALID thì các bạn cũng thấy trước đó rồi, tập TEST được mình để riêng ra 1 chỗ và không động chạm gì đến nó cả. Bây giờ là lúc chúng ta đánh giá performance của model trên tập TEST
3.1 Metric đánh giá
Để đánh giá một mô hình multi-class classification, chúng ta có rất nhiều cách tiếp cận khác nhau. Bảng dưới đây tổng hợp 1 cách đầy đủ và rõ ràng nhất về các metric đánh giá phù hợp. Và đương nhiên, xuất hiện ở tất cả các vị trí là confusion matrix, thế nên mình sẽ xây dựng confusion matrix trên tập test để đánh giá, và sau đó có thể convert sang các metric khác như accuracy, precision, recall, F1-score, ...
- Accuracy = (TP+TN)/(TP+TN+FP+FN).
- Misclassification Rate = (FP+FN)/(TP+TN+FP+FN) or (1-Accuracy).
- Precision = TP/(TP+FP).
- Recall = TP/(TP+FN).
- Specificity = TN/(TN+FP).
- F1 - score = 2TP/(2TP + FP + FN)
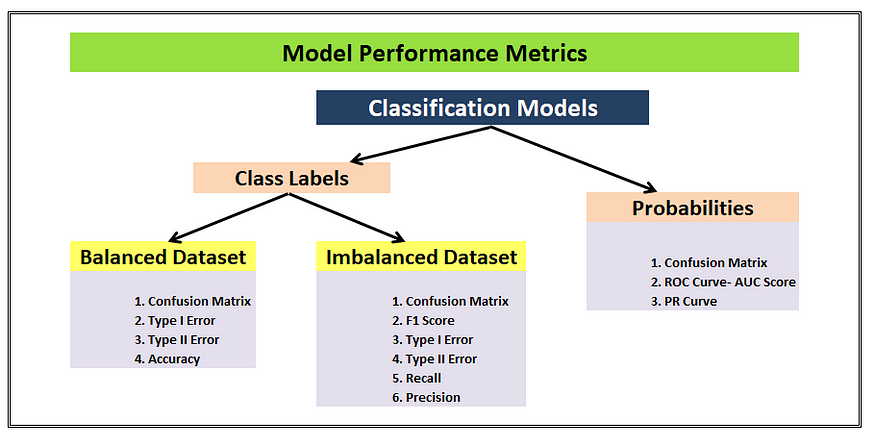
Về định nghĩa của confusion matrix, chắc các bạn có thể tự tìm hiểu, ở đây chúng ta sẽ quan tâm 1 cái khác sâu hơn 1 chút, confusion matrix trong multi-class classification và cách convert nó sang các metric khác: Confusion Matrix for Your Multi-Class Machine Learning Model

3.2 Đánh giá mô hình
Trước tiên cần xây dựng hàm test, output trả ra là một confusion matrix
def test(saved_model, all_data_paths):
"""Test a Tensorflow saved model"""
values = {language: 0 for language in all_languages}
matches = {language: deepcopy(values) for language in values}
input_function = build_optimal_input(all_data_paths, "test")
all_predict = 0
true_predict = 0
for test_item in input_function():
content = test_item[0]
label = test_item[1].numpy()[0].decode()
infer = saved_model.signatures['predict']
result = infer(content)
predicted = result['classes'].numpy()[0][0].decode()
matches[label][predicted] += 1
return matches
Tiếp đó, tính toán các giá trị TP, TN, FP, FN từ confusion matrix để tiện convert ra các giá trị Accuracy hoặc F1-score
def get_TP_TN_FP_FN(confusion_matrix, label, all_labels):
TP = confusion_matrix[label][label]
FP = sum([confusion_matrix[label][i] for i in all_labels if i != label])
FN = sum([confusion_matrix[i][label] for i in all_labels if i != label])
TN = 0
for i in all_labels:
for j in all_labels:
if i!= label and j != label:
TN += confusion_matrix[i][j]
return TP, TN, FP, FN
Kết quả trên tập test cụ thể sau 100000 steps training :
Train Metric: {'accuracy': 0.96734375, 'average_loss': 0.3622289, 'loss': 0.3622289, 'global_step': 100000}
Test model time: 82.2637951374054
samples test: 46525
Weighted F1: 0.9681125779639757
3.3 Tiến hành dự đoán với dữ liệu thực tế và Xây dựng web app demo
Sau khi train và test hoàn thành, chúng ta đã có 1 file model serving, công việc tiếp theo chỉ là viết 1 web app nhỏ bằng Flask với 1 file html để làm giao diện hiển thị.
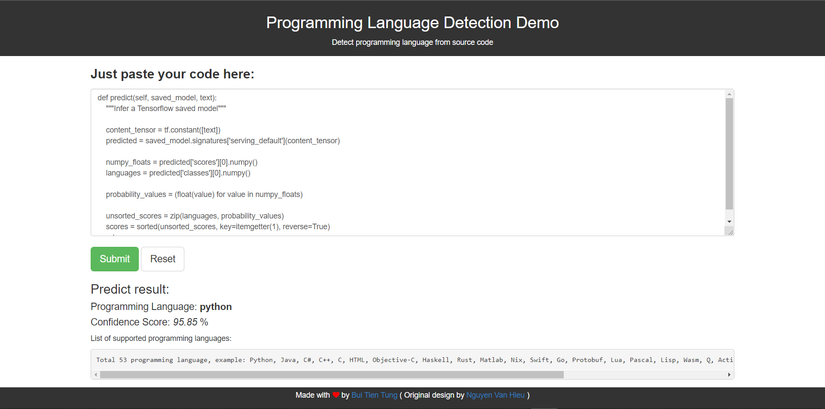
def predict(self, saved_model, text):
"""Infer a Tensorflow saved model"""
content_tensor = tf.constant([text])
predicted = saved_model.signatures['serving_default'](content_tensor)
numpy_floats = predicted['scores'][0].numpy()
languages = predicted['classes'][0].numpy()
probability_values = (float(value) for value in numpy_floats)
unsorted_scores = zip(languages, probability_values)
scores = sorted(unsorted_scores, key=itemgetter(1), reverse=True)
return scores
Đây là công việc nhẹ nhàng sau cùng, nên mình sẽ để dành cho các bạn tự mày mò tiếp. Mình sẽ giới thiệu 1 thứ hay ho hơn giúp các bạn chia sẻ được web app của bản thân cho người khác cũng có thể dử dụng. Đó là sử dụng nền tảng Glitch
Glitch là 1 nền tảng mà bạn có thể xây dựng ứng dụng web trên cloud. Về cơ bản nó giống github ở chỗ, bạn có thể public hoặc private dự án của mình và có thể share nó với partner để cùng tạo ra một ứng dụng hay ho. Trang chủ của Glitch có giới thiệu: Làm việc trên Glitch giống như làm việc cùng nhau trên Google Docs, nhiều người cùng làm việc trên một dự án và cùng một thời điểm, bạn có thể thấy ngay sự thay đổi trực tiếp ngay trên trang web của bạn.

Để build một ứng dụng Flask tren Glitch, bạn có thể bắt đầu chỉnh sửa một project mẫu trên Glitch: Flask Office starter code hoặc đơn giản là build từ source github của bạn. Nếu các bạn cần 1 bài hướng dẫn cụ thể hơn 1 chút, các bạn có thể đọc thêm tại bài viết : Build a Python Flask App on Glitch!
Bài viết đến đây có vẻ đã khá đầy đủ rồi, mình xin kết thúc tại đây. Source code cũng như link web demo mình sẽ để ngay bên dưới nếu các bạn muốn hiểu thêm chi tiết.
- Link web demo : https://programming-language-detection-demo.glitch.me/
- Link source code : https://colab.research.google.com/drive/1Le5QTa7iYXWYTI4uIFgHC9cfAM94OVd2#scrollTo=7bpy4y0skR8z
Rất mong các bạn có những thiết kế giao diện đẹp, bắt mắt có thể comment dưới bài viết này để mọi người cùng tham khảo.
Cảm ơn các bạn đã theo dõi đến cuối bài viết này. Nếu thấy hay, đừng quên upvote, clip và share bài viết để mình có thêm động lực viết bài. See you soon
Tài liệu tham khảo
All rights reserved
