Phía sau 1 câu query đơn giản
Bài đăng này đã không được cập nhật trong 5 năm
Giống như hầu hết những đứa trẻ ngày nay dường như không biết tại sao bầu trời lại có màu xanh lam, một điều đáng báo động là số lượng các dev không (thực sự) biết dữ liệu của họ đến từ đâu và nó được xử lý và lưu trữ như thế nào. Bài viết này phải là một điểm khởi đầu trong hành trình của một developer trong việc hiểu cách hoạt động của nó.
Okey, một câu query rất đơn giản, dù bạn bắt đầu ở level nào thì cũng từng thấy: Lấy tất cả users trong db
SELECT * FROM users;
Sooo, Bạn thực sự biết điều gì đang xảy ra giữa việc nhấn enter trong terminal psql của bạn và nhận lại kết quả? Ồ, mình cũng chả rõ, và rồi tìm được bài viết này What’s behind a simple SQL query?, nhờ đó mà mình cũng tìm được đáp án cho câu hỏi vừa rồi, và mong rằng bài dịch sẽ giúp bạn tiếp cận câu trả lời 1 cách dễ dàng hơn 
Kiến thức nền tảng
Để hiểu được điều này, cùng bắt đầu từ kiến trúc của PostgresDB nào! yoyoo
Một cách dễ hiểu, nó là một ứng dụng client / server được viết bằng C ++. Client là bất kỳ ai truy cập vào DB, ví dụ: terminal psql của bạn, hàm Lambda, JDBC driver, v.v. và server là backend PGDB, chấp nhận request của bạn, lưu trữ dữ liệu, v.v.
Đây là tổng quan kiến trúc cơ bản của PostgresDB
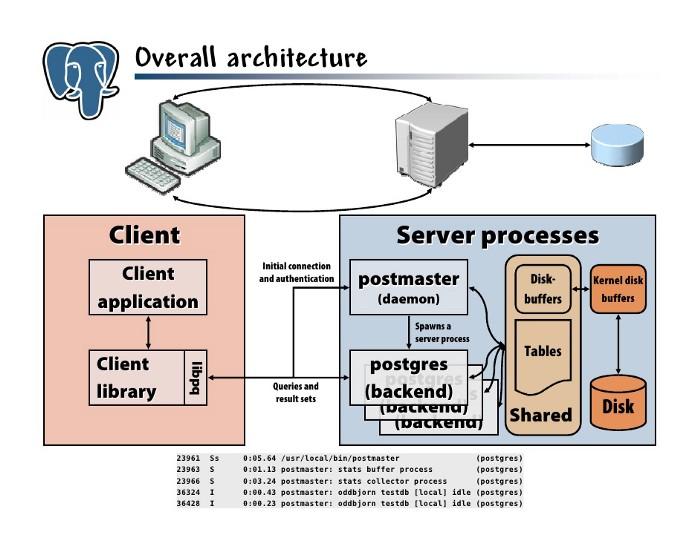
Bạn có thể tìm hiểu kỹ hơn ở 2 bài post này nhé Architecture of PostgreSQL DB, Document of PostgresSQL
"Đường đời" của 1 query
Đây sẽ là một cái nhìn tổng quan khá tốt về “path of a query” trong tài liệu PostgresDB chính thức.
1. Thiết lập kết nối, truyền query và ... chờ kết quả
PGDB có thể xử lý nhiều kết nối một cách đồng thời (thông qua “postmaster”, xem kiến trúc ở ảnh trên nè) và đối với mỗi kết nối, nó tạo ra một tiến trình mới (“postgres”, tiếp tục xem kiến trúc ở ảnh trên) để xử lý các yêu cầu (ví dụ: câu lệnh SQL) của kết nối đó. Nói cách khác, nó là một mô hình client / server: “process per user”. postmaster xử lý kết nối và xác thực ban đầu, sau đó chuyển giao kết nối đó cho một tiến trình postgres mới. Các tiến trình đó giao tiếp với nhau bằng bộ nhớ dùng chung (shared memory) để đảm bảo tính toàn vẹn của dữ liệu ngay cả với các kết nối đồng thời (bạn nhớ ACID chứ?)
2. Phân tích câu query (Parsing the query)
Nó gồm 2 giai đoạn
- Prsing - Phân tích cú pháp: trình phân tích cú pháp PGDB sử dụng công cụ UNIX bison và flex làm trình phân tích cú pháp và lexer để xác thực xem chuỗi truy vấn đầu vào (văn bản ASCII) có phải là truy vấn SQL hợp lệ hay không. Điều này chỉ được thực hiện với các luật cố định về cú pháp của SQL mà không có bất kỳ hiểu biết nào về ngữ nghĩa cơ bản của chuỗi truy vấn. Đầu ra là một cây phân tích cú pháp:
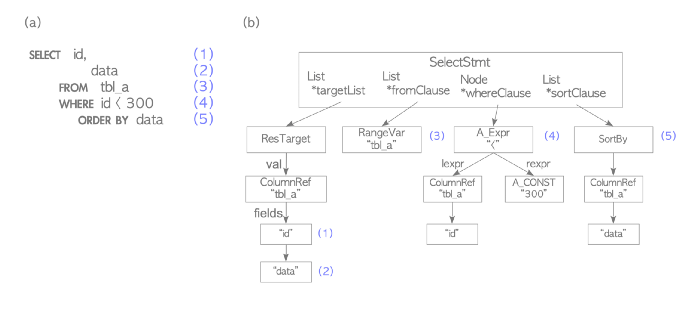
- Transform: sử dụng cây phân tích cú pháp để xây dựng cây truy vấn, cây này chứa phần diễn giải ngữ nghĩa của truy vấn, ví dụ: bảng, kiểu dữ liệu, toán tử và hàm nào được tham chiếu. Gốc của cây truy vấn là cấu trúc dữ liệu Truy vấn được định nghĩa ở đây. Đầu ra:
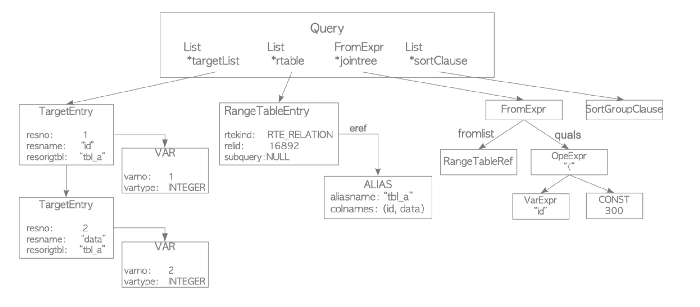
Tìm hiểu 1 chút về Query: * targetList: đầu ra của truy vấn và kiểu dữ liệu của nó; trong trường hợp này là cột id và data, cả hai đều là số nguyên * rtable: tham chiếu đến bảng * Jointree: giữ các toán tử FROM và WHERE * sortClause: lưu trữ cách sắp xếp dữ liệu
Một lưu ý quan trọng trực tiếp từ óp-fi-sồ docs:
The reason for separating raw parsing from semantic analysis is that system catalog lookups can only be done within a transaction, and we do not wish to start a transaction immediately upon receiving a query string. The raw parsing stage is sufficient to identify the transaction control commands (BEGIN, ROLLBACK, etc), and these can then be correctly executed without any further analysis. Once we know that we are dealing with an actual query (such as SELECT or UPDATE), it is okay to start a transaction if we’re not already in one. Only then can the transformation process be invoked.
3. Viết lại truy vấn (The rewrite)
Rewrite system của PGDB sử dụng cây truy vấn làm đầu vào và thực hiện các phép biến đổi dựa trên các luật được lưu trữ trong danh mục hệ thống có thể được áp dụng cho cây truy vấn. Đầu ra lại là một cây truy vấn. Một ví dụ điển hình là việc thực hiện các chế độ xem (bảng ảo) trong đó Rewrite system viết lại truy vấn của người dùng để truy cập các bảng gốc trong View được định nghĩa thay vì alias View.
Có thể tìm thấy một ví dụ toàn diện về cách hệ thống Rule hoạt động cho các View ở đây
4. Kế hoạch truy vấn (The query plan)
planner/optimizer sử dụng cây truy vấn được viết lại từ bước cuối cùng để tạo kế hoạch thực thi tối ưu / rẻ nhất (= nhanh nhất / hiệu quả nhất) cho truy vấn - the query plan. Trình tối ưu hóa xem xét tất cả các đường dẫn có thể có để thực hiện truy vấn. Trừ khi câu lệnh có số lượng các phép joins quá lớn, vượt quá ngưỡng geqotreshold - nơi mà việc xem xét tất cả các khả năng là không khả thi về mặt tính toán. Trong trường hợp đó, một Trình tối ưu hóa Truy vấn Generic Query Optimizer sẽ được sử dụng để thay thế.
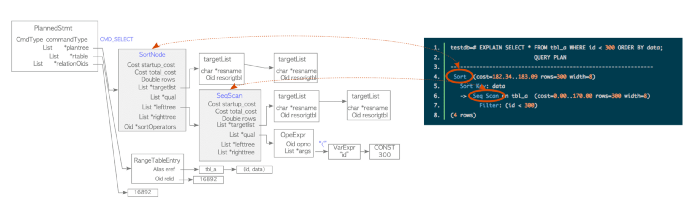
Ví dụ trong sơ đồ trên cho thấy một ví dụ đơn giản, trong đó executor phải quét tuần tự bảng tbl_a theo sau là một sắp xếp. Bạn có thể kiểm tra kế hoạch truy vấn của mình bằng cách nhập EXPLAIN trước truy vấn của mình:
EXPLAIN SELECT (...)
5. Thực thi (Executor)
Óp-fi-sồ doc giải thích là chuẩn nhất nè
The executor recursively steps through the plan tree and retrieves rows in the way represented by the plan. The executor makes use of the storage system while scanning relations, performs sorts and joins, evaluates qualifications and finally hands back the rows derived.
Trình thực thi được sử dụng để đánh giá tất cả 4 kiểu truy vấn SQL cơ bản SELECT, INSERT, DELETE và UPDATE. Bạn có thể tìm thêm chi tiết về các bước của người thực thi cho từng loại truy vấn tại đây.
Bộ nhớ
Okey, Bây giờ bạn đã biết (1) điều gì sẽ xảy ra khi bạn kết nối với một PGDB và (2) cách các truy vấn SQL được phân tích cú pháp, tối ưu hóa và thực thi. Điều duy nhất còn thiếu là cách dữ liệu được lưu trữ. Có một bài viết giải thích tuyệt vời về chủ đề này ở đây, và dưới đây mình sẽ tóm tắt 1 cách ngắn gọn.
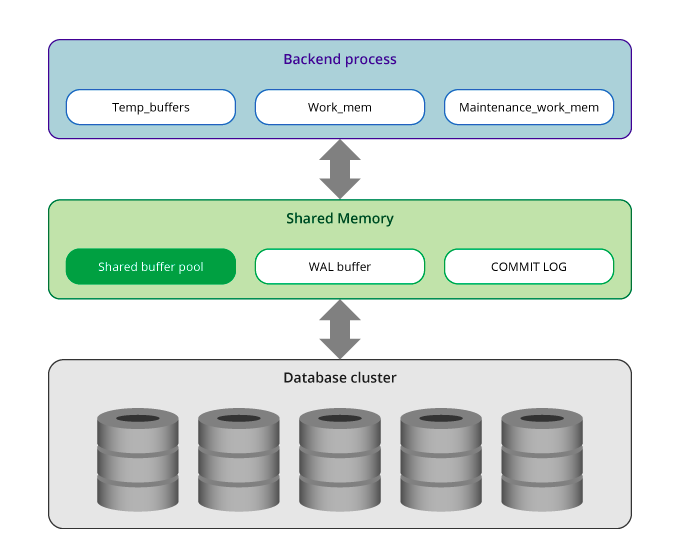
Có 2 loại bộ nhớ: local memory và shared memory. Cùng tìm hiểu nhé.
1. Local memory
Nó được sử dụng bởi mỗi postgres backend process. Bộ nhớ này được cấp phát bởi mỗi tiến trình để xử lý truy vấn và bao gồm:
- temp_buffers: lưu trữ bảng tạm thời bởi executor
- work_mem: được sử dụng bởi executor để joins, v.v.
- maint_work_mem: các hoạt động maintenance như REINDEX
2. Shared memory
Nó được cấp phát khi server PGDB khởi động và được sử dụng bởi tất cả các tiến trình để đảm bảo tính toàn vẹn của dữ liệu (bạn có nhớ phần đầu của bài viết không?). Đây cũng là bộ nhớ mà các tiến trình giao tiếp - nó thường không giao tiếp trực tiếp với bộ nhớ lưu trữ liên tục . Bộ nhớ dùng chung này bao gồm:
- Shared buffer pool: nơi các pages trong bảng và chỉ mục được tải vào
- WAL buffer: Postgres có write ahead log tức là transactio log đảm bảo không có dữ liệu nào bị mất do lỗi máy chủ. Dữ liệu WAL được lưu trữ trong bộ đệm WAL trước khi được chuyển sang lưu trữ liên tục.
- Commit log: lưu giữ tất cả các trạng thái của transaction như một phần của cơ chế kiểm soát đồng thời.
Bạn có thể điều chỉnh các giá trị này và lượng bộ nhớ được cấp cho chúng để tăng hiệu suất của cơ sở dữ liệu của bạn. Bạn có thể tìm thấy thêm thông tin về các tiện ích cho từng phần của bộ nhớ tại đây.
Preferences
Bây giờ bạn đã có những hiểu biết cơ bản về hoạt động bên trong của một trong những cơ sở dữ liệu phổ biến nhất! Hy vọng rằng điều này loại bỏ một số kỳ thị về "cơ sở dữ liệu phức tạp". Có thể nó thậm chí sẽ truyền cảm hứng cho bạn đào sâu hơn và hiểu cách bạn có thể tối ưu hóa các ứng dụng của mình bằng cách hiểu rõ hơn cách dữ liệu của bạn được lưu trữ - một trong những nút thắt lớn nhất trong kỹ thuật phần mềm hiện đại.
Sources:
All rights reserved
