MiniCPM: Khai Phá Tiềm Năng Của Các Mô Hình Ngôn Ngữ Nhỏ (SLMs)

Trong những năm gần đây, cả thế giới và cộng đồng AI đều chứng kiến sự bùng nổ ấn tượng của các mô hình ngôn ngữ lớn (LLMs), với quy mô hàng tỷ đến hàng chục tỷ tham số. Tuy nhiên, chính vì kích thước đồ sộ của các mô hình này mà việc huấn luyện và triển khai chúng đã trở thành thách thức lớn, vượt quá khả năng của nhiều tổ chức, công ty, hay cá nhân. Để giải quyết vấn đề này, các mô hình ngôn ngữ nhỏ (SLMs) đã xuất hiện, đóng vai trò như một giải pháp thay thế hiệu quả, giúp duy trì hiệu suất cao nhưng với chi phí và tài nguyên thấp hơn. Sự ra đời của các mô hình như MiniCPM đã minh chứng cho xu hướng này, mang lại sự cân bằng giữa hiệu suất và khả năng triển khai.
I. MiniCPM là gì?
MiniCPM là một mô hình ngôn ngữ nhỏ (SLM) được phát triển với mục tiêu chính là tối ưu hoá hiệu suất và khả năng mở rộng. Với hai phiên bản 1.2B và 2.4B tham số, MiniCPM cho ra kết quả tương đương với những mô hình lớn hơn ba đến sáu lần về quy mô như LLaMA2-7B và Mistral-7B.
II. Những kỹ thuật quan trọng đằng sau MiniCPM
Không chỉ là một mô hình nhỏ gọn, MiniCPM còn là một mô hình có khả năng mở rộng, mở rộng về cả kích thước mô hình và dữ liệu mà không cần đào tạo lại từ đầu. Khả năng đó là nhờ một số kỹ thuật đột phá dưới đây:
1. Warmup-Stable-Decay (WSD) Learning Rate Scheduler
Bộ điều chỉnh tốc độ học này chia quá trình huấn luyện mô hình thành ba giai đoạn:
a. Giai đoạn khởi động (Warm-up Stage)
Khi bắt đầu quá trình huấn luyện, mô hình học bước nhỏ chậm rãi và cập nhập từng chút một. Khi độ chính xác dần được cải thiện hơn, learning rate cũng được gia tăng dần.
b. Giai đoạn ổn định (Stable Stage)
Sau giai đoạn khởi động, tốc độ học được duy trì ổn định trong một thời gian dài. Đây cũng là phần lớn thời gian mà mô hình được huấn luyện. Việc này giúp cho mô hình cải thiện một cách ổn định mà không thay đổi quá đột ngột hay “liều mạng".
c. Giai đoạn giảm tốc (Decay Stage)
Ở giai đoạn cuối này, learning rate lại từ từ giảm khi quá trình huấn luyện dần kết thúc. Vì khi mô hình đang tiến gần đến quá trình hội tụ, ta muốn mô hình học các bước nhỏ lại để không đi qua mất điểm tối ưu này.
2. Thử nghiệm mô hình Wind Tunnel
Lấy cảm hứng từ quy trình kiểm thử trong hầm mô phỏng gió của ngành hàng không, các thử nghiệm này kiểm tra các điều chỉnh các siêu tham số, kích thước batch và tốc độ học sao cho mô hình được tối ưu hoá mà vẫn duy trì được độ chính xác cao.
2.1. Mở rộng mô hình ngôn ngữ với các siêu tham số bất biến
- Tăng chiều rộng: Là tăng số units trong layer.
- Tăng chiều sâu: Chỉnh sửa số lượng layer trong mô hình. Thường thì các mô hình càng sâu càng chính xác, nhưng không phải lúc nào cũng vậy
2.2. Lựa chọn batch size tối ưu
Batch size quyết định sự cân bằng giữa tốc độ hội tụ của mô hình và lượng tài nguyên phần cứng cần sử dụng. Sau các thử nghiệm với mô hình siêu nhỏ (0.009B, 0.03B và 0.17B) với 6 batch size khác nhau, họ đưa ra một sơ đồ thể hiện mối quan hệ giữa batch size và loss. Trong quá trình tăng batch size, loss chỉ giảm đến một điểm nhất định, qua điểm đó thì việc tăng batch size không ảnh hưởng đáng kể đến loss nữa và chỉ làm tốn thêm tài nguyên.
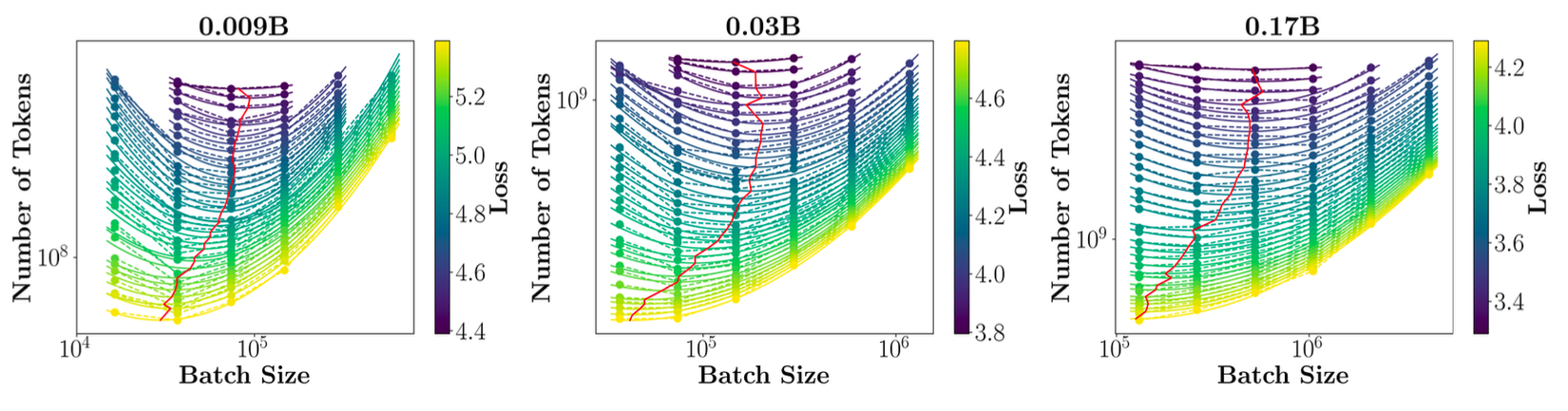
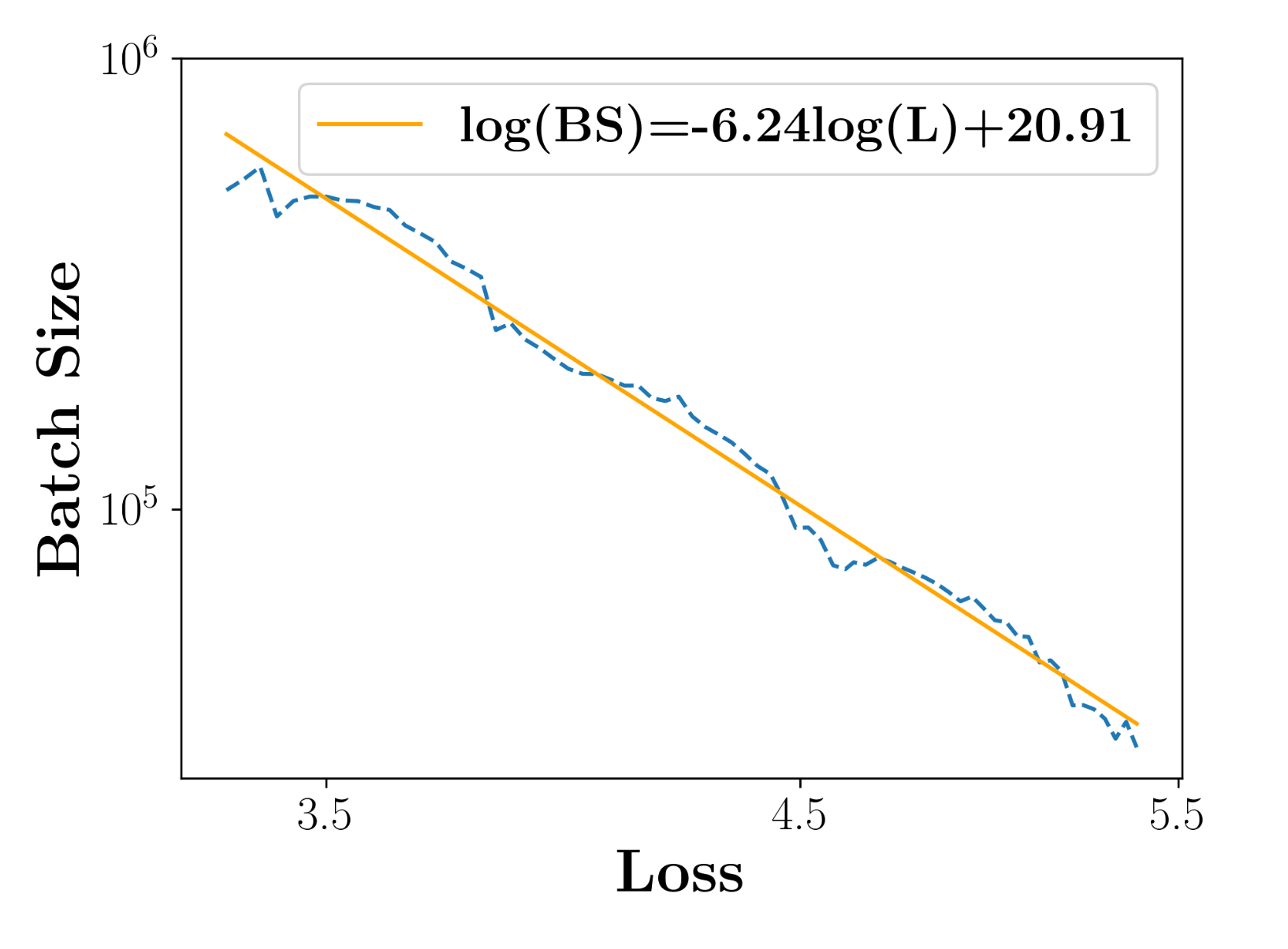
Tác giả đã đưa ra một phương trình lấy cơ sở dựa trên mối quan hệ này để dự đoán batch size tối ưu nhất cho nhiều kích thước mô hình khác nhau với batch size và C4 Loss :
2.3. Lựa chọn learning rate tối ưu
Tác giả cũng thực hiện các thực nghiệm sử dụng các learning rate khác nhau trên các kích thước model từ 0.004B đến 0.5B. Kết quả nhận được là mức learning rate tối ưu nằm xung quanh 0.01. Learning rate này cũng đã được xác nhận là có loss thấp nhất sau khi chạy validate trên mô hình 2.1B.
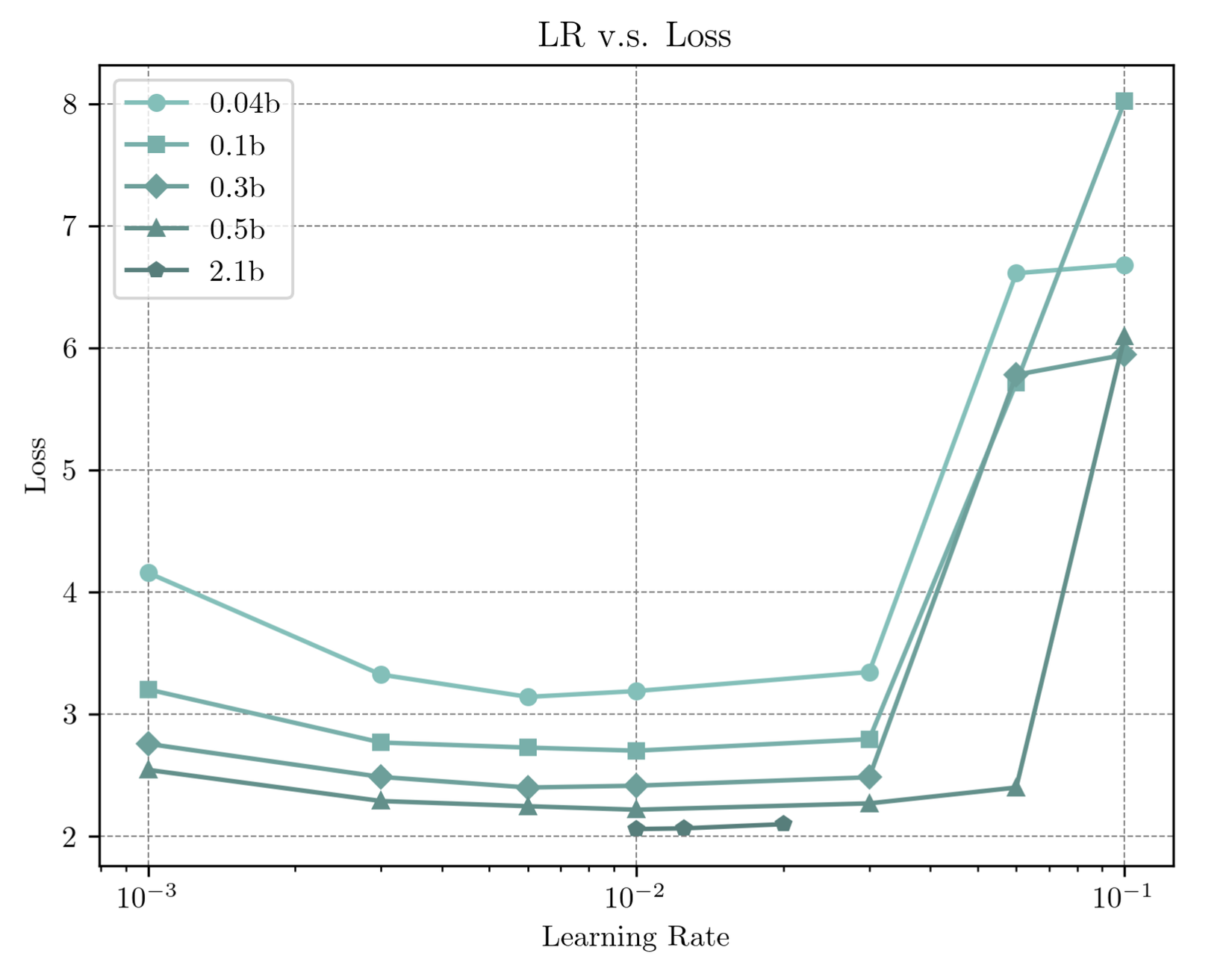
III. Mô hình MiniCPM
1. Chi tiết mô hình
a. Từ vựng (Vocabulary)
Họ sử dụng hai tokenizers với vocab size là gần 123K vocab size cho MiniCPM-2.4B và hơn 73K cho MiniCPM-1.2B. Tuy vocab size cho bản 1.2B nhỏ nhưng vẫn mang lại hiệu suất tốt và hiệu quả cao cho mô hình.
b. Chia sẻ lớp đầu vào và đầu ra (Shared Input-Output Layer)
Đối với các Mô Hình Ngôn Ngữ Nhỏ (SLMs), phần embedding chiếm một không gian tham số lớn. Để giảm kích thước tham số của mô hình, chúng tôi sử dụng kỹ thuật chia sẻ embedding (Embedding Sharing) cho cả MiniCPM-2.4B và MiniCPM-1.2B.
c. Mạng sâu và mỏng (Deep-and-Thin Network)
MiniCPM-2.4B được huấn luyện trước MiniCPM-1.2B. Trong quá trình huấn luyện, họ đã áp dụng kiến trúc sâu hơn và mỏng hơn dựa trên MobileLLM cho MiniCPM-2.4B, sau đó tiếp tục tinh chỉnh và làm cho kiến trúc của MiniCPM-1.2B thậm chí còn sâu và mỏng hơn.
d. Truy vấn chú ý theo nhóm (Group Attention Query)
Họ giữ nguyên lớp attention khi huấn luyện MiniCPM-2.4B, nhưng áp dụng Group Attention Query cho MiniCPM-1.2B để tiếp tục giảm số lượng tham số.
2. Các giai đoạn huấn luyện
a. Giai đoạn ổn định (Stable Stage)
Số lượng lớn dữ liệu được sử dụng để huấn luyện mô hình vào giai đoạn này (hơn 1 nghìn tỷ tokens), với batch size 3.39 triệu và learning rate max 0.01 (theo thực nghiệm trước đó).
b. Giai đoạn giảm tốc (Decay Stage)
Giai đoạn giảm tốc (Decay stage): Họ tiếp tục sử dụng dữ liệu pretrain trước đó cùng với dữ liệu chất lượng đã được đánh nhãn để tiếp tục cải thiện model. Đồng thời họ cũng giảm learning rate theo cấp số mũ (sử dụng exponential annealing) để model đạt được kết quả cuối cùng mà không bị vượt quá điểm tối ưu.
Trong đó:
- : training step hiện tại
- : step khởi điểm khi bắt đầu quá trình giảm
- : tổng thời gian (số bước) mà quá trình giảm diễn ra, trong trường hợp này là 5000 steps
c. Giai đoạn FIne-tuning có giám sát (SFT Stage)
Ở giai đoạn này, mô hình được huấn luyện với dữ liệu (có nhãn) sát sườn các tác vụ thực tế sử dụng, lượng dữ liệu sử dụng rơi vào khoảng 6 tỉ token.
3. Phân bố của dữ liệu huấn luyện

Dữ liệu cho giai đoạn ổn định (Stable stage) chủ yếu mang tính cân bằng và có cấu trúc rõ ràng, bao gồm các nguồn dữ liệu lớn như CommanCrawl.Chn, C4 và các tập dữ liệu dành riêng cho các tác vụ coding.
Giai đoạn giảm tốc (Decay stage) sử dụng thêm nhiều nguồn dữ liệu đa dạng và độc quyền hơn, phản ánh sự chuyển đổi của mô hình sang việc học fine-tune, đặc biệt trong các tác vụ chuyên biệt như lập trình, giải toán và trả lời câu hỏi. Các tập dữ liệu được sử dụng như UltraChat, Slim Orca, OSSInstruct, và EvolInstruct, cùng với dữ liệu độc quyền như các câu hỏi từ LeetCode và sách giáo khoa từ mẫu giáo đến lớp 12 (K-12).
4. Training Loss
Như kỳ vọng, đồ thị loss ở giai đoạn ổn định giảm đều đặn và tương đối mịn do quá trình huấn luyện đã được ổn định hoá và tổng quát hoá. Ngoài ra, khi đến giai đoạn giảm tốc, loss đã giảm sâu do learning rate đã được giảm dần từ bắt đầu giai đoạn.

Phần màu cam ở đuôi của đường loss là phần cuối của giai đoạn giảm tốc, sẽ không được sử dụng trong phiên bản phát hành của MiniCPM.
IV. Kết quả hiệu suất và so sánh với các mô hình khác
MIniCPM được đánh giá qua các chỉ số chuẩn và benchmark, cho thấy khả năng xử lý tốt nhiều loại tác vụ khác nhau.
1. Độ bối rối (Perplexity)
Một trong những chỉ số quan trọng để đánh giá hiệu suất của mô hình ngôn ngữ là Perplexity. Chỉ số này đo lường khả năng dự đoán một cuỗi từ của mô hình, giá trị càng thấp thì chứng tỏ mô hình càng tốt trong việc hiểu và tạo ngôn ngữ tự nhiên. MiniCPM-2.4B đạt điểm perplexity tương đối ấn tượng, thể hiện khả năng dự đoán và xử lý ngôn ngữ hiệu quả.
2. Benchmark cho các tác vụ cụ thể (Task-Specific Benchmarks)
MiniCPM đã được thử nghiệm trên nhiefu bài toán chuyên môn như phân loại văn bản, tóm tắt, hỏi đáp (QA), và các nhiệm vụ liên quan đến mã nguồn. Kết quả cho thấy mô hình có khả năng giải quyết tốt các tác vụ này, đặc biệt là các vấn đề liên quan đến toán học và lập trình, nhờ vào việc fine-tune sau giai đoạn SFT (Supervised Fine-Tuning).
3. So sánh với các mô hình lớn hơn
MiniCPM được so sánh với nhiều mô hình có số lượng tham số lớn hơn, bao gồm Llama2-7B, Mistral-7B và Gemma-7B,... Ngoài ra, mô hình cũng được so sánh với các mô hình có kích thước tương đương như TinyLlama-1.1B, Qwn-1.8B, và Gemma-2B.
- MiniCPM-2.4B xếp hạng cao nhất trong số tất cả các mô hình SLM (Small Language Models), thậm chí vượt qua Llama2-7B trong các tác vụ liên quan đến ngôn ngữ Trung Quốc, và có hiệu suất tương đương trong các tác vụ Tiếng Anh.
- Mô hình cũng vượt qua hầu hết các mô hình lớn hơn ở các bài test về toán học và suy luận thông thường (commonsense reasoning). Tuy nhiên, khi xét đến khả năng suy luận logic, kích thước mô hình dường như đóng vai trò quan trọng hơn. Ở những nhiệm vụ đòi hỏi suy luận logic phức tạp, các mô hình lớn hơn như Llama2-7B vẫn có ưu thế hơn.
4. Fine-tuning cho các tác vụ cụ thể (Specific Task Fine-tuning)
Sau giai đoạn SFT, MiniCPM đã được fine-tune cho các bài toán chuyên biệt như toán học và lập trình, cũng như các nhiệm vụ yêu cầu kiến thức chuyên sâu. Điều này giúp mô hình có hiệu suất nổi bật trong các bài kiểm tra về toán học và các nhiệm vụ liên quan đến code, mang lại khả năng cạnh tranh so với các mô hình ngôn ngữ lớn hơn.
V. Các phiên bản MiniCPM
MiniCPM không chỉ là một mô hình đơn lẻ mà còn được phát triển thành nhiều phiên bản khác nhau, mỗi phiên bản được tối ưu hóa cho các nhiệm vụ và yêu cầu cụ thể. Các phiên bản này bao gồm:
- MiniCPM-DPO (Direct Preference Optimization): Phiên bản này được thiết kế để tối ưu hóa theo phản hồi của người dùng, giúp cải thiện hiệu suất trong các nhiệm vụ mà sở thích hoặc ý kiến của người dùng đóng vai trò quan trọng. Nó đặc biệt hữu ích trong các tác vụ như hội thoại AI hoặc các hệ thống gợi ý.
- MiniCPM-128K: Đây là phiên bản được tối ưu hóa để xử lý các văn bản đầu vào rất dài, với khả năng xử lý lên tới 128,000 tokens trong một chuỗi. MiniCPM-128K phù hợp cho các nhiệm vụ yêu cầu hiểu biết về ngữ cảnh dài hạn, chẳng hạn như tóm tắt tài liệu dài hoặc phân tích văn bản pháp lý.
- MiniCPM-MoE (Mixture of Experts): Phiên bản này sử dụng Mixture of Experts, với 4 tỷ tham số hoạt động (active parameters). Điều này giúp phiên bản này trở nên chuyên biệt hơn và hiệu quả hơn trong các nhiệm vụ cụ thể mà không cần tăng kích thước tổng thể của mô hình. MiniCPM-MoE có thể kích hoạt các "chuyên gia" (expert) khác nhau tùy theo loại nhiệm vụ, giúp tiết kiệm tài nguyên nhưng vẫn đảm bảo hiệu suất cao.
VI. Kết luận
MiniCPM đã chứng minh rằng các mô hình ngôn ngữ nhỏ có thể đạt hiệu suất mạnh mẽ mà không đòi hỏi quá nhiều tài nguyên. Nhờ vào các kỹ thuật như Warmup-Stable-Decay, Embedding Sharing, và các chiến lược huấn luyện tối ưu, MiniCPM không chỉ hiệu quả mà còn linh hoạt, dễ mở rộng cho nhiều tác vụ chuyên biệt.
Các phiên bản như MiniCPM-DPO, MiniCPM-128K, và MiniCPM-MoE giúp mô hình này đáp ứng tốt nhiều yêu cầu đa dạng, từ ngữ cảnh dài hạn đến các nhiệm vụ chuyên biệt như toán học và lập trình. Với hiệu suất vượt trội, MiniCPM là một giải pháp tối ưu cho các tổ chức muốn tận dụng AI mà không cần đầu tư vào các mô hình lớn.
Tham khảo
🔗 Kết nối với Pixta Vietnam: http://bit.ly/3kdkzvW
All rights reserved
