
Language Modeling - Mô hình ngôn ngữ và bài toán thêm dấu câu trong Tiếng Việt
Bài đăng này đã không được cập nhật trong 5 năm
Mô hình ngôn ngữ là một thuật ngữ mà bất cứ ai đã, đang và sẽ tìm hiểu về Xử lí ngôn ngữ tự nhiên (NLP) đều biết và cần phải biết để có thể hiểu rõ hơn về cách thức mà một ngôn ngữ được xây dựng từ một bộ từ vựng, về cách đánh giá, cách xử lí đối với ngôn ngữ tự nhiên cũng như là tiền đề để đi sâu vào tìm hiểu các lĩnh vực sâu xa hơn như : sửa lỗi chính tả, dịch máy, gán nhãn từ loại, ... . Một ứng dụng phổ biến của mô hình ngôn ngữ mà mọi người hầu như tiếp xúc nhiều nhất đó là việc tự động gợi ý từ tiếp theo trên thanh tìm kiếm của Google.
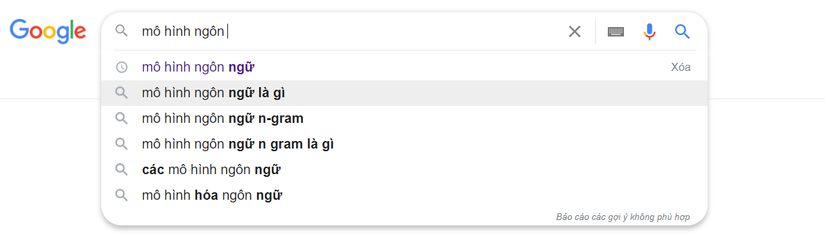
Trong bài viết này, mình sẽ cùng các bạn tìm hiểu một cách chi tiết, rõ ràng nhất về bản chất của một mô hình ngôn ngữ cũng như survey qua các hướng xây dựng mô hình ngôn ngữ đang phổ biến hiện nay. Cuối bài viết, chúng ta cũng sẽ thử xây dựng một mô hình ngôn ngữ nho nhỏ trong tiếng việt và ứng dụng nó vào bài toán thêm dấu câu cho tiếng việt
P/s : Bài viết được tổng hợp từ những kiến thức mình tìm hiểu được trong thời gian gần đây về NLP nên sẽ không tránh khỏi những sai sót trong cách hiểu cũng như cách tiếp cận vấn đề. Rất mong các bạn góp ý thêm dưới comment nếu cảm thấy mình có trình bày không hợp lí phần nào
--( I am a newbie )--
1. Mô hình ngôn ngữ là gì ?
Định nghĩa
Mô hình ngôn ngữ là tập hợp các kiến thức trước đó về một ngôn ngữ nhất định, các kiến thức này có thể là các kiến thức về từ vựng, về ngữ pháp, về tần suất xuất hiện của các cụm từ, ... Một mô hình ngôn ngữ có thể được xây dựng theo hướng chuyên gia hoặc hướng dữ liệu.
Đó là định nghĩa chung nhất về mô hình ngôn ngữ, tuy nhiên khá mơ hồ và chung chung nhỉ. Do đó, mình sẽ nêu lại định nghĩa về mô hình ngôn ngữ dưới góc nhìn hẹp hơn: Về tần suất xuất hiện của cụm từ.
Mô hình ngôn ngữ là một phân bố xác suất trên các tập văn bản, cung cấp các thông tin về phân bố xác suất tiền nghiệm (prior distribution) với là các từ vựng trong bộ từ điển của một ngôn ngữ nhất định. Nói đơn giản, mô hình ngôn ngữ có thể cho biết xác suất một câu (hoặc cụm từ) thuộc một ngôn ngữ là bao nhiêu.
Ví dụ: khi áp dụng mô hình ngôn ngữ cho tiếng Việt:
- P[“hôm nay là thứ bảy”] = 0.001
- P[“bảy thứ hôm là nay”] = 0
Ví dụ trên cho thấy, câu "hôm nay là thứ bảy" có khả năng là một câu tiếng Việt cao hơn so với câu "bảy thứ hôm là nay". Đây là ví dụ đơn giản nhất để các bạn có thể hình dung được một mô hình ngôn ngữ làm gì. Vậy câu hỏi tiếp theo được đặt ra là chúng ta tính cái xác suất kia như thế nào, hay làm thể nào để xây dựng mô hình ngôn ngữ ?
Các hướng tiếp cận
Để xây dựng mô hình ngôn ngữ, chúng ta có thể tiếp cận theo 3 hướng chính: Knowledge-based Language Model, Statistical Language Model (Count-based), và Neural Network Language Model (Continuous-space). Ngoài ra còn một số mô hình ngôn ngữ khác chẳng hạn như KenLM, ...
-
Knowledge-based Language Model
Đây là những mô hình ngôn ngữ được xây dựng dựa trên những kiến thức đã được con người (cụ thể là các chuyên gia về ngôn ngữ học) tích luỹ, phân tích từ cú pháp một câu, cách chia động từ hoặc sự phân rã của tính từ ... .
Khi các kiến thức này được định nghĩa bằng các luật, nó sẽ xây dựng lên một mô hình ngôn ngữ, do đó Knowledge-based Language Model còn được gọi là rule-based language model.
- Grammatical - Ungrammatical
- Intra-grammatical - Extra-grammatical
- Non-grammatical - Out-of-grammatical
- Qualitative LM - Quantitative LM
Một số thách thức và bất lợi khi cố gắng xây dựng một Knowledge-based Language Model có thể kể đến như: (trích từ bài viết Language Model là chi rứa?)
- Khó xây dựng: Trước tiên, bạn cần phải là một chuyên gia ngôn ngữ học. Tiếp theo, bạn cần đủ khả năng để tổng hợp và tái cấu trúc lại các kiến thức của bạn về một ngôn ngữ thành tập các luật biểu diễn nó. (Thế thôi, chắc nghỉ game nhỉ
 )
) - Chỉ nhận diện được các từ thuộc intra-grammatical: Intra-grammatical có thể hiểu như là văn viết (formal), trái ngược với extra-grammatical là văn nói (informal). Nếu học ngôn ngữ thì ngôn ngữ nào cũng có sự khác biệt giữa văn nói và văn viết.
- Thiếu tính tần số (Lack of frequencies): Độ phổ biến của câu từ đóng vai trò không kém quan trọng, chẳng hạn như "How to recognize speech" và "How to wreck a nice beach" đều đúng ngữ pháp nhưng câu đầu đúng hơn vì phổ biến hơn và câu sau có nghĩa hơi kì lạ.
- Chỉ phân biệt được hợp lý hay không: Do cấu trúc của mô hình nên kết quả của mô hình này đối với một câu là có hợp lý (hay đúng ngữ pháp) của một ngôn ngữ hay không chứ không có dự đoán hay gợi ý được từ.
Do một loạt các lí do trên, các hướng tiếp cận mình giới thiệu tiếp theo thường được quan tâm và tập trung phát triển hơn
-
Statistical Language Model
Xây dựng mô hình ngôn ngữ dựa trên thống kê là việc cố gắng đi xác định giá trị của từ tập dữ liệu thu thập được.
hiểu đơn giản là xác suất cụm từ thuộc một ngôn ngữ cụ thể, mà trong trường hợp với tập dữ liệu thu thập được, ta có thể tính
với N là số lượng cụm từ có độ dài N trong tập dữ liệu. Do đó, Statistical Language Model còn được gọi là Count based Model
Hoặc trong trường hợp việc xác định N là khó thực hiện, chúng ta hoàn toàn có thể sử dụng công thức xác suất có điều kiện trong trường hợp này :
Trong đó.
Dựa theo cách thức xác định giá trị xác suất , trong Statistical Language Model lại được chia thành 2 hướng tiếp cận nhỏ hơn
N-gram Language Models
Việc tính giá trị trong trường hợp n vô hạn, thực tế là vô cùng khó khăn. Để giảm độ phức tạp cho việc tính toán cũng như tạo ra một hướng đi khả thi để có thể mô hình hóa ngôn ngữ, mô hình n-gram ra đời. Mô hình n-gram giả định việc mô hình ngôn ngữ là một chuỗi Markov, thỏa mãn tính chất Markov. Chúng ta có tính chất Markov được định nghĩa như sau:
Một quá trình mang tính ngẫu nhiên có thuộc tính Markov nếu phân bố xác suất có điều kiện của các trạng thái tương lai của quá trình, khi biết trạng thái hiện tại, phụ thuộc chỉ vào trạng thái hiện tại đó
Hiểu một cách đơn giản, nếu giả định mô hình ngôn ngữ có thuộc tính Markov, ta có thể tính xác suất theo công thức sau :
Công thức trên là dạng giả định đơn giản nhất : mô hình ngôn ngữ là một mô hình markov bậc 1. Tuy nhiên, thực tế điều giả định là quá đơn giản, và các mô hình markov bậc 2, 3, 4 thường được sử dụng nhiều hơn. Điều giả định này đã giúp việc tính toán trở nên đơn giản hơn rất nhiều
Ví dụ, chúng ta có câu : W = "Today is Sarturday and towmorrow is Sunday". Khi đó với mô hình markov bậc 2
Dễ hình dung hơn rồi nhỉ, chúng ta sẽ chỉ xét các từ đứng gần từ đang xét thôi, còn lại thì bỏ qua =))
Khi giả định một mô hình ngôn ngữ là mô hình Markov bậc n-1, ta gọi các mô hình đó là mô hình n-gram. Việc tính toán cụ thể hơn, mình sẽ tiếp tục trình bày ở ngay bên dưới để các bạn có thể nắm rõ hơn 
Structured Language Models
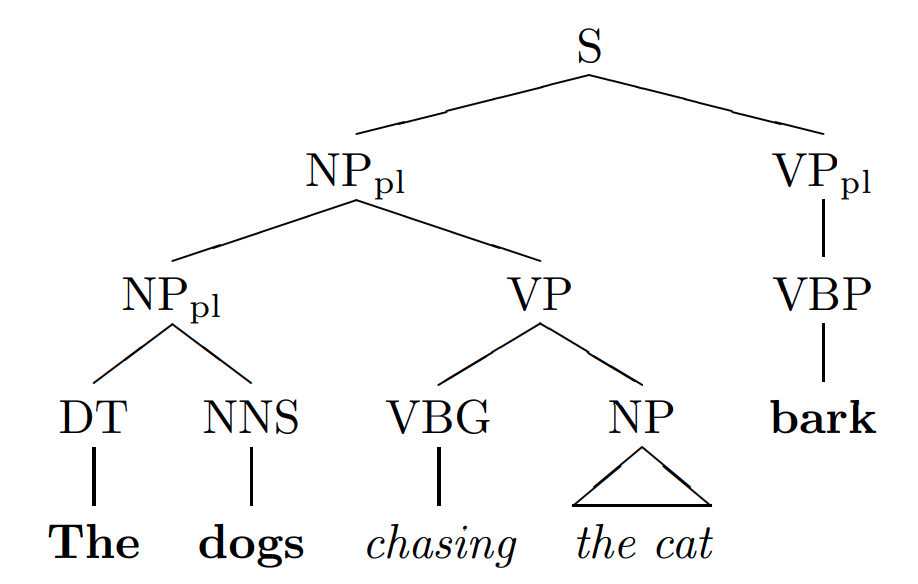
Một nhược điểm của mô hình n-gram là không đánh giá được ngữ cảnh của toàn bộ câu, do đó, trong nhiều trường hợp, nó không thể đưa ra một xác suất chính xác. Một ví dụ có thể kể đến như W = "The dogs chasing the cat bark" (tạm dịch là Những con chó vừa nãy đuổi con mèo thì đang sủa). Động từ "bark" (sủa) ở đây nhận chủ ngữ là "The dogs", tuy nhiên, nếu sử dụng 3-gram, mô hình sẽ đi tính xác suất , và kết quả thu được sẽ là bằng 0.
Để giải quyết vấn đề này, Structured Language Models ra đời. Structured Language Models hay mô hình ngôn ngữ có cấu trúc, cố gắng hướng đến một hệ thống phân cấp cho các từ vựng trong một câu văn. Việc này kết hợp với n-gram sẽ cho kết quả bao quát được ngữ cảnh của toàn câu văn, cải thiện độ chính xác của mô hình
-
Neural Network Language Model
Neural Network Language Model là những phương pháp mới nhất dựa trên mạng Neural để xây dựng mô hình ngôn ngữ, các mô hình này còn có một tên gọi khác là Continuous-space language models. Neural Network Language Model cũng được chia thành 2 hướng tiếp cận chính
Feed-forward neural network based LM: Feed-forward neural network được đề xuất để giải quyết 1 vấn đề khác của N-gram liên quan đến độ thưa thớt dữ liệu (khi tồn tại nhiều câu, cụm từ trong thực tế nhưng lại không được thu thập trong dữ liệu train). Mạng neural được sử dụng ở đây là 1 mạng neural 3 lớp, nhằm mục tiêu học được các tham số cần thiết để tính xác suất .
Recurrent Neural Network Based LM: Recurrent Neural Network lại tập trung giải quyết một khía cạnh khác về ngữ cảnh của toàn bộ câu, giúp giải quyết được các giới hạn về ngữ cảnh. Hiện nay, các mô hình ngôn ngữ dựa trên RNN hoặc các phát triển từ nó như LSTM, ... đang đạt được các kết quả State of the art.
Nếu như với mô hình Feed-forward neural network, dữ liệu đầu vào cần yêu cầu số từ cố định, tuy nhiên, điều này là không thể xảy ra trong thực tế, do các câu có độ dài ngắn khác nhau, Recurrent Neural Network cũng đồng thời khắc phục được nhược điểm này với việc chấp nhận đầu vào có độ dài bất kì.
2. Ứng dụng mô hình ngôn ngữ trong bài toán thêm dấu tiếng việt
OK, tạm xong phần survey khiến các bạn nhức não (và khiến mình nhức tay - do viết nhiều quá @@), trong phần này, chúng ta sẽ bắt tay xây dựng một mô hình ngôn ngữ cho Tiếng Việt để cảm thấy chút hứng thú với chủ đề này.
Note: Do trên Viblo hiện đã có một bài viết khá hay và chi tiết của tác giả Phạm Hoàng Anh về việc xây dựng mô hình ngôn ngữ cho tiếng Việt bằng mạng LSTM (tức là theo hướng Neural Network Language Model) : Tạo Language Model để tự động sinh văn bản tiếng Việt, thế nên mình sẽ tập trung giới thiệu cụ thể hơn về 1 phương pháp khác : N-gram model
Dữ liệu
Để tiện so sánh với phương pháp LSTM được xây dựng của tác giả Phạm Hoàng Anh, chúng ta sẽ sử dụng lại luôn bộ dữ liệu trong bài viết của tác giả. Tất nhiên, cũng sẽ hơi khác một xíu. Nếu tác giả chỉ sử dụng 1/4 bộ dữ liệu đấy thì chúng ta sẽ sử dụng full tất cả (train n-gram nhanh mà ^^).
Mình xin trích lại link bộ dữ liệu tại đây luôn https://github.com/hoanganhpham1006/Vietnamese_Language_Model/blob/master/Train_Full.zip
Giới thiệu sơ qua một chút :
- Tập dữ liệu bao gồm 42744 bài viết, được thu thập từ các trang tin tức, báo chí, xã hội
- Gồm 8 thư mục về 8 chủ đề khác nhau: Chính trị xã hội, Đời sống, Kinh doanh, Pháp luật, Sức khỏe, Thế giới, thể thao, văn hóa
- Định dạng file .txt
- Ví dụ về 1 file trong thư mục Thế giới:
Anh: Nữ hoàng phản đối việc tổ chức lễ cưới hoang phí Thái tử Charles và vị hôn thê Camilla tại lâu đài Windsor. Nữ hoàng Anh Elizabeth II đã yêu cầu Thái tử Charles tổ chức lễ cưới bình dị với vị hôn thê Camilla hơn là một lễ cưới đình đám như mong muốn của thái tử. Tờ The Sun trích nguồn tin từ hoàng gia cho biết nữ hoàng cũng đã khuyên hai người nên ngủ riêng cho đến khi chính thức tổ chức lễ thành hôn vào ngày 8/4 tới. Trước đó, Thái tử Charles (56 tuổi) hy vọng sẽ tổ chức một bữa tiệc hoành tráng tại lâu đài Windsor với sự hiện diện của các quan khách hoàng gia, những người nổi tiếng và các chính khách. Thái tử cũng muốn phục vụ loại rau hữu cơ quý hiếm tại quê hương Highgrove của ông cho bữa tiệc tối nhưng nữ hoàng đã không ủng hộ. Theo The Sun, nữ hoàng cho rằng không đáng để tổ chức một đám cưới phung phí và bà không muốn làm công chúng tức giận với lễ cưới khoa trương như thế. Lễ cưới sẽ vẫn được tổ chức hoành tráng nhưng ở mức độ vừa phải, theo như những tiêu chuẩn vốn có của hoàng gia. (AFP)
Ý tưởng
Ý tưởng để chúng ta thực hiện bài toán thêm dấu Tiếng Việt bao gồm các bước sau :
- Xây dựng mô hình Trigram để đưa ra xác suất xuất hiện 1 từ nếu biết 2 từ đứng trước nó
- Đối với mỗi từ Tiếng Việt không dấu, tiến hành generate tất cả các trường hợp có thể điền dấu cho từ
- Sử dụng Greedy Search hoặc Beam Search để lấy ra được câu cho xác suất lớn nhất
- Test thử kết quả
OK, bắt tay vào công đoạn đầu tiên, là cơ sở cho sự thành bại của toàn bộ bài toán nào : Xây dựng mô hình Trigram.

Xây dựng mô hình ngôn ngữ
Việc trước tiên, chúng ta cần load dữ liệu trước đã
import os
full = []
for dirname, _, filenames in os.walk('/content/Train_Full'):
for filename in filenames:
with open(os.path.join("/content", os.path.join(dirname, filename)), 'r', encoding='UTF-16') as f:
full.append(f.read())
print(len(full))
Tiếp theo là các bước tiền xử lí cơ bản để lấy đầu vào cho mô hình n-gram:
- Tách đoạn văn ra thành từng câu nhỏ
- Loại bỏ các dấu câu trong câu
- Tách từ (tokenize) với mỗi câu
import re
from nltk import word_tokenize
import string
from tqdm import tqdm
def tokenize(doc):
tokens = word_tokenize(doc.lower())
table = str.maketrans('', '', string.punctuation.replace("_", "")) #Remove all punctuation
tokens = [w.translate(table) for w in tokens]
tokens = [word for word in tokens if word]
return tokens
full_data = ". ".join(full)
full_data = full_data.replace("\n", ". ")
corpus = []
sents = re.split(r'(?<=[^A-Z].[.?]) +(?=[A-Z])', full_data)
for sent in tqdm(sents):
corpus.append(tokenize(sent))
Ở đây, mình chỉ có 1 lưu ý nhỏ đến vấn đề tokenize (tách từ). Có thể các bạn sẽ thắc mắc tại sao mình lại dùng word_tokenize() của nltk mà không phải là word_tokenize của underthesea hay ViTokenizer của pyvi, vốn là những tokenize thực sự tốt trong tiếng Việt. Câu trả lời rất đơn giản, là vì mô hình này mình xây dựng cho bài toán thêm dấu câu
Các bạn có thể hình dung vấn đề như sau :
- Với 1 câu bình thường : "Ứng dụng trong bài toán thêm dấu tiếng Việt"
- ViTokenizer hoặc underthesea.word_tokenize : [ứng _dụng, trong, bài_toán, thêm, dấu , tiếng _việt]
- Với 1 câu không dấu : "Ung dung trong bai toan them dau tieng viet"
- ViTokenizer hoặc underthesea.word_tokenize : [ung, dung, trong, bai, toan, them, dau, tieng, viet]
Chúng ta có thể dễ dàng nhận ra việc tokeinze là không khớp với 2 cụm từ, đó đó, việc áp dụng tokenize cho Tiếng Việt là không phù hợp ở đây (tất nhiên, với bài toán generate text, ... thì pyvi và underthesea luôn là những lựa chọn hàng đầu). Còn với bài này, mình ưu tiên sử dụng word_tokenize của nltk (một tokenize cho tiếng anh)
Bây giờ chúng ta đã có input, bắt đầu tiếp tục lí thuyết về Trigram nào!
Phía trên là công thức Maximum likelihood estimation (tạm dịch là ước lượng hợp lí cực đại). Chúng ta có thể dễ dàng implement lại cái ý tưởng này bằng việc đếm từ với đoạn code sau
from nltk import bigrams, trigrams
from collections import Counter, defaultdict
# Create a placeholder for model
model = defaultdict(lambda: defaultdict(lambda: 0))
# Count frequency of co-occurance
for sentence in tqdm(corpus):
for w1, w2, w3 in trigrams(sentence, pad_right=True, pad_left=True):
model[(w1, w2)][w3] += 1
# Let's transform the counts to probabilities
for w1_w2 in model:
total_count = float(sum(model[w1_w2].values()))
for w3 in model[w1_w2]:
model[w1_w2][w3] /= total_count
Tuy nhiên, mình sẽ không sử dụng đoạn code này vì một vài lí do sau :
- Công thức ước lượng trên chỉ đơn thuần ước lượng dựa trên "đếm", vậy sẽ tồn tại 2 trường hợp
- Tử số bằng 0 : tức là count(u, v, w) = 0, hay không tồn tại cụm từ uvw trong dữ liệu train (mà thực tế sẽ rất nhiều trường hợp bằng 0 như thế này)
- Mẫu số bằng 0: khi không tồn tại cụm từ uv trong tập dữ liệu, ta có count(u, v) = 0, công thức ước lượng bây giờ dính vào lỗi chia cho 0 và không thể ước lượng được xác suất.
- Với trường hợp dữ liệu train không thể cover hết các trường hợp dữ liệu thực tế, một giá trị xác suất bằng 0 hoặc không xác định có thể ảnh hưởng kết quả đến toàn bộ quá trình
Do lí do đó, chúng ta có một vài hướng xử lí như sau
Interpolation : ý tưởng của phương pháp này được xuất phát từ một nhận xét đơn giản như sau :
Các mô hình n-gram bậc cao và bậc thấp đều có những ưu điểm và nhược điểm riêng
n-gram bậc cao nhạy cảm hơn nhiều với ngữ cảnh của câu, tuy nhiên lại dính một nhược điểm về độ thưa thớt dữ liệu
n-gram bậc thấp thì chỉ xem xét được trong ngữ cảnh rất hạn chế, nhưng có số lượng thu thập được lớn hơn rất nhiều
Vì lí do này, phương pháp Interpolation được sinh ra nhằm kết hợp các mô hình n-gram lại (có đánh trọng số)
Giá trị ở đây sẽ giúp đảm bảo giá trị của luôn khác 0 và tránh được nhược điểm trước đó.
Ngoài ra, còn có một phương pháp khác là Discounting cũng như các phương pháp smoothing (làm mịn), các bạn có thể tham khảo thêm tại bài viết Language Modeling là gì hoặc slide
Trong bài viết này, mình sẽ code theo một pipeline hỗ trợ sãn cho việc xây dựng mô hình n-gram trên nltk. Cụ thể, trước tiên, chúng ta cần tách ra các gram từ các câu vừa thu được
from nltk.lm.preprocessing import padded_everygram_pipeline
train_data, padded_sents = padded_everygram_pipeline(n, corpus)
Tiếp theo, chúng ta sẽ sử dụng phương pháp KneserNey Interpolation để xây dựng mô hình ngôn ngữ (một phương pháp sử dụng absolute-discounting interpolation). Bên cạnh đó, các bạn cũng có thể sử dụng các mô hình khác như MLE, Lapalace, ...
from nltk.lm import MLE, Laplace, KneserNeyInterpolated, WittenBellInterpolated
import pickle
import os
n = 3
vi_model = KneserNeyInterpolated(n)
vi_model.fit(train_data, padded_sents)
print(len(vi_model.vocab))
model_dir = "/content/drive/My Drive/Colab Notebooks/Ngram_model"
with open(os.path.join(model_dir, 'kneserney_1st_ngram_model.pkl'), 'wb') as fout:
pickle.dump(vi_model, fout)
Chờ đợi ít phút để mô hình fit vào dữ liệu và chúng ta đã có một mô hình ngôn ngữ của riêng mình được xây dựng từ lý thuyết n-gram.
Trước khi đi vô phần ứng dụng chính, các bạn có thể test thử mô hình của mình bằng việc sinh thử ra một đoạn text nhỏ :
from nltk.tokenize.treebank import TreebankWordDetokenizer
detokenize = TreebankWordDetokenizer().detokenize
def generate_sent(model, num_words, pre_words=[]):
"""
:param model: An ngram language model from `nltk.lm.model`.
:param num_words: Max no. of words to generate.
:param random_seed: Seed value for random.
"""
content = pre_words
for i in range(num_words):
token = model.generate(1, text_seed=content[-2:])
if token == '<s>':
continue
if token == '</s>':
break
content.append(token)
return detokenize(content)
generate_sent(vi_model, 10, ["đất", "nước"])
#đất nước việt nam các phương tiện như ở vn sử dụng
Ứng dụng trong việc thêm dấu câu Tiếng Việt
Oke, bây giờ sẽ vào phần ứng dụng chính của bài chia sẻ này : TỰ ĐỘNG THÊM DẤU CÂU CHO TIẾNG VIỆT
Hiện tại chúng ta đã có mô hình ngôn ngữ, chúng ta cần cần chuẩn bị thêm một yếu tố nữa : Hàm sinh dấu cho từ
Ví dụ, nếu chúng ta có một từ bất kì : chuyen --> [chuyện, chuyến, chuyên, chuyển, chuyễn, ...]. Điều này có thể được thực hiện như thế nào ???.
Trước hết, chúng ta học lại về nguyên âm, phụ âm, cũng như cách ghép vần trong Tiếng Việt 1 chút nhỉ. Ở đây mình sẽ nói nhiều hơn về nguyên âm và cách đánh dấu thanh cho câu
- Tiếng Việt có ... phụ âm (các bạn tự điền vào chỗ trống nhá ), bao gồm 2 loại : phụ âm đơn và phụ âm kép
- Về nguyên âm, có tất cả 15 nguyên âm, được chia thành
- 10 nguyên âm đơn: i, y, ư, u, ê, ơ, ô, e, a, o
- 5 bán nguyên âm, trong đó có 2 bán nguyên âm đơn (ă, â) và 3 bán nguyên âm kép (iê/yê, uô, ươ)
- Về cách ghép vần, bao gồm 4 loại vần chính
- Vần đơn giản : Là các vần nguyên âm đơn (i/y, ư, u, ê, ơ, ô,e, a, o )
- Vần đơn giản : Là các vần được tạo thành từ nguyên âm + phụ âm cuối (anh= a+nh; em= e+m; )
- Vần hòa âm : Là vần được tạo thành khi ghép 2 nguyên âm, và cách phát âm phụ thuộc chính vào 1 trong 2 nguyên âm đó (eo –ao -ai –oe –oa –oi –êu –ơi –ôi –ia –iu –ưa –ưi –ưu –ua –uê –ui –uy)
- Vần hợp âm : Là vần được tạo thành khi ghép 2 nguyên âm, tuy nhiên tạo ra 1 âm hoàn toàn mới (ay –ây –âu –au) hoặc cần thêm 1 phụ âm nữa (oă_, uâ_,iê_, yê_, ươ_, uô_ )
Sơ lược như vậy để thấy Tiếng Việt của chúng ta lằng nhằng như thế nào =)). Các bạn có hứng thú có thể đọc thêm tại Vần & Cách Ráp ÂmTrong Tiếng Việt
Quay trở lại bài toán của chúng ta, khá may mắn khi tác giả của bài viết All syllables in Vietnamese language đã xây dựng một bộ thư viện trên github về các âm tiết trong Tiếng Việt, công việc code bây giờ trở lên khá nhẹ nhàng
# Download VN syllables
!wget -O vn_syllables.txt "https://gist.githubusercontent.com/hieuthi/0f5adb7d3f79e7fb67e0e499004bf558/raw/135a4d9716e49a981624474156d6f247b9b46f6a/all-vietnamese-syllables.txt"
Tiến hành sinh các trường hợp có thể có dấu của 1 từ bằng việc mapping nó với tập từ vựng trong file "vn_syllables.txt"
import re
def remove_vn_accent(word):
word = re.sub('[áàảãạăắằẳẵặâấầẩẫậ]', 'a', word)
word = re.sub('[éèẻẽẹêếềểễệ]', 'e', word)
word = re.sub('[óòỏõọôốồổỗộơớờởỡợ]', 'o', word)
word = re.sub('[íìỉĩị]', 'i', word)
word = re.sub('[úùủũụưứừửữự]', 'u', word)
word = re.sub('[ýỳỷỹỵ]', 'y', word)
word = re.sub('đ', 'd', word)
return word
def gen_accents_word(word):
word_no_accent = remove_vn_accent(word.lower())
all_accent_word = {word}
for w in open('vn_syllables.txt').read().splitlines():
w_no_accent = remove_vn_accent(w.lower())
if w_no_accent == word_no_accent:
all_accent_word.add(w)
return all_accent_word
gen_accents_word("hoang")
#{'hoang', 'hoàng', 'hoáng', 'hoãng', 'hoăng', 'hoạng', 'hoảng', 'hoắng', 'hoằng', 'hoẳng', 'hoẵng', 'hoặng'}
Công việc sau cùng là áp dụng các kiến thức về Searching để tìm ra kết quả tối ưu. Về các phương pháp Search này thì các bạn có thể thử sử dụng Breadth-first search (Tìm kiếm theo chiều rộng), Depth-first search (Tìm kiếm theo chiều sâu), Greedy Algorithms (Thuật toán tham lam), Beam Search, ...
Ở đây chúng ta ưu tiên cho tốc độ xử lí hơn thì chúng ta có thể sử dụng Greedy Search (nhanh + đơn giản nhất), hoặc muốn kết quả tốt hơn 1 xíu thì có thể sử dụng Beam Search (Beam Search có tư tưởng giống như Greedy Search: ở mỗi bước, có gắng tìm ra k bước cho kết quả tốt nhất hiện tại rồi tiếp tục các bước tiếp theo - Các bạn có thể đọc thêm về Beam Search tại How to Implement a Beam Search Decoder for Natural Language Processing
# beam search
def beam_search(words, model, k=3):
sequences = []
for idx, word in enumerate(words):
if idx == 0:
sequences = [([x], 0.0) for x in gen_accents_word(word)]
else:
all_sequences = []
for seq in sequences:
for next_word in gen_accents_word(word):
current_word = seq[0][-1]
try:
previous_word = seq[0][-2]
score = model.logscore(next_word, [previous_word, current_word])
except:
score = model.logscore(next_word, [current_word])
new_seq = seq[0].copy()
new_seq.append(next_word)
all_sequences.append((new_seq, seq[1] + score))
all_sequences = sorted(all_sequences,key=lambda x: x[1], reverse=True)
sequences = all_sequences[:k]
return sequences
OK, tất cả đã xong, check thử thành quả nào
from nltk.tokenize.treebank import TreebankWordDetokenizer
detokenize = TreebankWordDetokenizer().detokenize
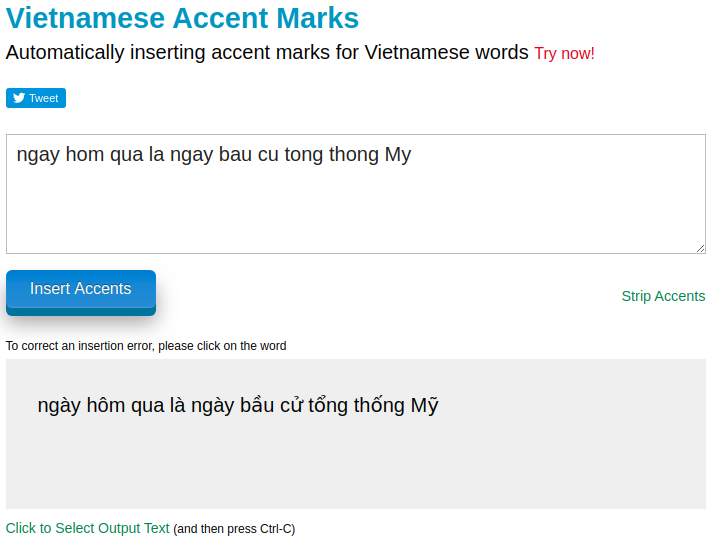
sentence = "ngay hom qua la ngay bau cư tong thong My"
result = beam_search(sentence.lower().split(), model_loaded)
print(detokenize(result[0][0]))
#ngày hôm qua là ngày bầu cử tổng thống mỹ
3. Kết luận
Trong bài viết này, mình đã giới thiệu với các bạn về lí thuyết của mô hình ngôn ngữ cũng như survey qua các phương pháp xây dựng một mô hình ngôn ngữ hiện nay. Việc hiểu và ứng dụng được mô hình ngôn ngữ sẽ tạo ra cho các bạn một tấm nền vững chắc để bước đi trên con đường dài tìm hiểu về NLP. Về bài thực hành với bài toán thêm dấu câu trong Tiếng Việt, các bạn có thể tiếp tục cải thiện mô hình cả vè tốc độ và kết quả bằng nhiều cách : sử dụng một bộ dữ liệu đa dạng hơn, sử dụng phương pháp search tối ưu hơn, .... Các bạn cũng hoàn toàn có thể phát triển nó thành 1 ứng dụng web như trên trang https://vietnameseaccent.com/ (vài dòng lệnh Flask là đủ rồi  )
)
Nếu cảm thấy bài viết hữu ích, đừng quên upvote, clip và share bài viết cho mình nha. See ya  Full source code của mình hiện public tại đây : https://colab.research.google.com/drive/1dw2sLBUpyVierdbx2QzO-ENB2bne1RCK?usp=sharing
Full source code của mình hiện public tại đây : https://colab.research.google.com/drive/1dw2sLBUpyVierdbx2QzO-ENB2bne1RCK?usp=sharing
All rights reserved
