Language Model là chi rứa?
Bài đăng này đã không được cập nhật trong 6 năm
Giới thiệu
Hi guys, hôm nay mình sẽ nói về "mô hình ngôn ngữ" (language model). Chắc hẳn các bạn đã từng gõ chữ trên điện thoại và biết tính năng gợi ý từ như ảnh này nhỉ:
Tính năng ấy cũng có trong các công cụ tìm kiếm chẳng hạn như google, bing, ...
Nó hoạt động bằng cách đưa ra những chữ hay từ thường xuyên xuất hiện khi ta nhập vào một chữ hay từ nào đó.
Để tính được sự thường xuyên ấy thì người ta sử dụng Language Model đó. Để hiểu hơn về "mô hình ngôn ngữ" cũng như cách mà nó giúp gợi ý từ thì ta đi qua khái niệm trước tiên nhé.
Khái niệm
Language Model (LM) là một mô hình đại diện cho những kiến thức đã biết về một ngôn ngữ, những kiến thức ấy có thể là những từ, chuỗi các từ có thể có hay mức độ thường xuyên mà chúng xuất hiện.
LM được chia thành ba nhóm đó là Statistical LM (Count-based), Neural Network LM (Continuous-space) và Knowledge-based LM, Ngoài ra còn một số LM khác chẳng hạn như KenLM, ...
Statistical LM được sử dụng phổ biến nhất từ trước tới giờ nên mình sẽ nói về nó trước nhé.
Statistical Language Models (Count-based)
Những mô hình thuộc nhóm này đều dựa trên việc đếm tần suất xuất hiện của từng từ hay chuỗi, do đó nó cần một lượng dữ liệu lớn, càng nhiều càng tốt.
Statistical LM là phân bố xác suất trên tập hợp tất cả các chuỗi (câu văn) có trong tập dữ liệu thuộc bộ từ vựng của một ngôn ngữ nào đó.
Khi đó, và .
Trong đó, xác suất của một chuỗi có độ dài được tính như sau:
là xác suất của từ khi đã biết chuỗi và được tính bằng cách đếm chuỗi như sau:
Tuy nhiên, nếu càng lớn thì tần suất xuất hiện của chuỗi từ ấy càng nhỏ và sẽ có trường hợp tần suất xuất hiện của chuỗi từ dẫn trước là lớn, khiến cho xác suất gần như bằng 0, dẫn tới việc chuỗi từ ấy không bao giờ xảy ra (nói đơn giản hơn là chuỗi ấy không có mặt trong tập huấn luyện). Giải pháp để giảm thiểu vấn đề này là thay vì tính theo thì ta chỉ chọn từ dẫn trước thôi, và thế là ta có N-gram Language Models:
N-gram Language Models
Như vậy ta sẽ có xác suất của một chuỗi là như sau:
Thông thường người ta sẽ chọn
Người ta còn gọi mô hình này với cái tên khác là (N-1)-order Markov Models.
Nhưng mà, mô hình này có các nhược điểm như sau:
- Sai điều kiện về sự phụ thuộc: Việc chuyển từ về ngay từ đầu đã không đúng rồi.
- Bão hoà (Saturation): Data càng nhiều thì model sẽ càng tốt nhưng sẽ đến lúc thêm data khác thì phân bố xác suất không thay đổi. Điều này xảy ra với bigram, trigram khi số từ đạt tới hàng tỷ.
- Thiếu tính tổng quát hoá: Từng thể loại, chủ đề, phong cách thì sẽ có các kết hợp câu, từ khác nhau. Do đó với các nguồn dữ liệu khác nhau thì chất lượng mô hình sẽ khác nhau, nhất là khi tập train với test khác kiểu viết thì performance của mô hình sẽ rất tệ.
- Thưa thớt dữ liệu (Data sparseness): Khi thiếu dữ liệu hoặc dữ liệu bị mất thì sẽ dẫn về lại vấn đề chuỗi không có mặt trong tập train mà có mặt trong tập test khiến xác suất bằng 0, N-gram chỉ giảm hiện tượng này chứ chưa giải quyết được hẳn.
Structured Language Models
Giả sử chúng ta có câu sau: "The dogs chasing the cat bark". Ta sẽ thấy rằng xác suất của trigram sẽ rất thấp vì một mặt là mèo không kêu "gâu gâu", mặt khác là từ "bark" là số nhiều trong khi "the cat" là số ít (sai ngữ pháp). Điều này dẫn tới mô hình N-gram hoạt động không tốt, ta cũng có thể tăng N để giải quyết vấn đề này nhưng như thế nó sẽ gặp lại vấn đề của Statistical LM. Do đó, ta cần áp dụng cấu trúc phân cấp (hierarchical structure) của câu văn vào mô hình, những models được áp dụng đó người ta gọi là structured language models.
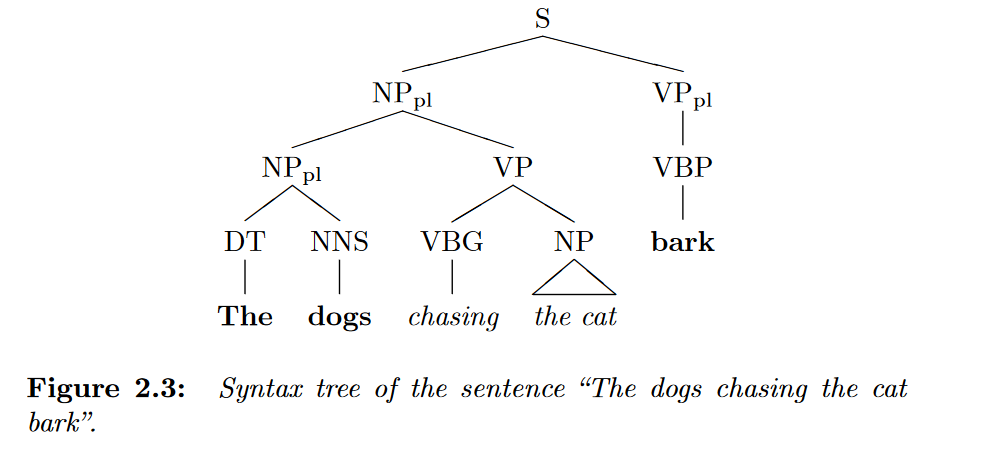
Thông thường các models dạng này sử dụng một cái gọi là statistical parser đã được train để làm hierarchical structure.
Một số parser được sử dụng cùng với N-gram LM:
- Grammatical Trigrams
- Statistical Parsing with a CFG and Word Statistics
- TWO DECADES OF STATISTICAL LANGUAGE MODELING: WHERE DO WE GO FROM HERE?
- Robust Probabilistic Predictive Syntactic Processing
- RICHER SYNTACTIC DEPENDENCIES FOR STRUCTURED LANGUAGE MODELING
- Language modeling using efficient best-first bottom-up parsing
- Language modeling using a statistical dependency grammar parser
- Head-Driven Parsing for Word Lattices
Knowledge Based Models
Những mô hình thuộc nhóm này được xây dựng theo những kiến thức đã được con người (cụ thể là các chuyên gia về ngôn ngữ học) tích luỹ, nào là cú pháp, các cụm từ, các thì, ... Nếu những kiến thức này được định nghĩa bằng các luật thì mô hình sẽ được gọi là rule-based model.
Mô hình này có ưu điểm là không yêu cầu một chút dữ liệu nào để huấn luyện.
Tuy nhiên, mô hình kiểu này cũng có nhược điểm là:
- Khó xây dựng: Do yêu cầu về kiến thức chuyên sâu về ngôn ngữ học mà lại thể hiện chúng dưới dạng mô hình và thuật toán thì rất tốn thời gian và chi phí.
- Chỉ nhận diện được các từ thuộc intra-grammatical: Intra-grammatical có thể hiểu như là văn viết (formal), trái ngược với extra-grammatical là văn nói (informal). Nếu học ngôn ngữ thì ngôn ngữ nào cũng có sự khác biệt giữa văn nói và văn viết.
- Thiếu tính tần số (Lack of frequencies): Độ phổ biến của câu từ đóng vai trò không kém quan trọng, chẳng hạn như "How to recognize speech" và "How to wreck a nice beach" đều đúng ngữ pháp nhưng câu đầu đúng hơn vì phổ biến hơn và câu sau có nghĩa hơi kì lạ.
- Chỉ phân biệt được hợp lý hay không: Do cấu trúc của mô hình nên kết quả của mô hình này đối với một câu là có hợp lý (hay đúng ngữ pháp) của một ngôn ngữ hay không chứ không có dự đoán hay gợi ý được từ.
Neural Network Language Models (Continuous-space)
Loại mô hình ngôn ngữ này được giới thiệu để xử lý vấn đề thưa thớt dữ liệu (data sparseness) của N-gram Language Models. Mô hình kiểu này được chia làm hai dạng là Feed Forward Neural Networks (FNNs) và Recurrent Neural Networks (RNNs).
Mọi mô hình kiểu này đều có input và output là:
- Input: Word Embedding hay Character Embedding, là chuyển từ hay ký tự sang vector số thực trong một không gian chiều (dimensions) cố định
- Output: Với mỗi output unit là xác suất của một từ hay ký tự khi đã biết context. Context là gì thì còn tùy thuộc vào dạng mô hình sử dụng.
Đối với dạng FNNs, context là một chuỗi có độ dài cố định và là những từ hay ký tự đúng trước ký tự đang xét, nghĩa là giống như N-gram Language Models vậy đó.
Đối với dạng RNNs, context như của FNNs nhưng có độ dài không cố định và dạng này giúp giải quyết vấn đề Limited context của FNNs, tức là không còn là N-gram nữa và các nhược điểm của N-gram Language Models không còn nữa.
Tổng kết
Như vậy, mô hình ngôn ngữ đại diện cho những kiến thức đã biết về một ngôn ngữ, những kiến thức đó là sự hợp lý về mặt cấu trúc, cú pháp hay sự phổ biến của câu từ.
Mô hình ngôn ngữ ngày nay được sử dụng khá phổ biến và tùy thuộc vào mục đích sử dụng mà ta chọn loại mô hình ngôn ngữ phù hợp, chẳng hạn như trong nhận diện giọng nói, nhận diện chữ viết tay hay các bài toán có đầu ra là một chuỗi các từ hay ký tự có sử dụng Connectionist Temporal Classification thì mô hình ngôn ngữ được dùng để "rescore" trong giải thuật beam search decoding như ở đây.
Tham khảo
All rights reserved
