
Làm thế nào để dùng một model cho nhiều công chuyện?
Bài đăng này đã không được cập nhật trong 6 năm
Đầu bài
Các bạn có biết rằng, để dạy cho máy học một mô hình, chúng ta đã thải ra lượng các-bon lớn gấp 5 lần một chiếc xe ô-tô trong cả quá trình vòng đời của nó? Vậy thì phải xem có thể làm gì với mô hình đó nữa cho bõ công phá hoại môi trường nào.
Chắc các bạn cũng biết, điểm xuất phát của các trọng số trong một mô hình có ảnh hưởng khá nhiều đến kết quả học máy. Nếu bạn xuất phát ở một nơi xa xôi, bạn sẽ khó và mất rất lâu để đến được miền đất hứa. Nếu bạn khởi điểm bằng một ma trận tạm ổn (sử dụng Xavier/Glorot initialization) thì mô hình sẽ không bị về (vanishing gradient) hay (exploding gradient). Và nếu bạn bắt đầu bằng trọng số của một mô hình khác (tưởng tượng như là lấy một cái quạt giấy làm điểm xuất phát để tạo ra một cái đập ruồi), thì mô hình sẽ hội tụ nhanh hơn rất nhiều! Bạn đã có cái quạt rồi (và bạn có thể copy cái quạt đó không mất gì  ), tại sao chúng ta không từ đó tạo một cái vợt ruồi để về quê phe phẩy mâm cỗ?
), tại sao chúng ta không từ đó tạo một cái vợt ruồi để về quê phe phẩy mâm cỗ?
Theo chủ trương 3R (Reduce-Reuse-Recycle), như ý tưởng ở trên, chúng ta sẽ xài lại mô hình đã train để làm việc khác. Vừa đỡ tốn tài nguyên bảo vệ môi trường, chất lượng tốt hơn train mới từ đầu, vừa được một bài Viblo để viết.
Lưu ý: chúng ta cần làm cả 2 việc chứ không phải bỏ việc 1 qua việc 2. Trong ví dụ cái quạt đập ruồi ở trên, chúng ta muốn vừa quạt các cụ vừa đuổi ruồi mâm cỗ. Hè nóng lắm.
Nếu bạn có thể copy cái quạt
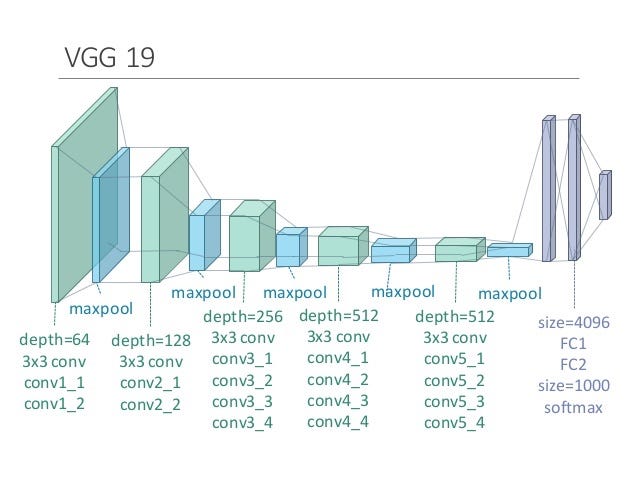
Tiêu đề là meme bắt nguồn từ đây. Nếu bạn không hiểu/không biết thì cũng kệ mình nha, mình nhạt lắm. Còn ảnh minh họa là VGG tiêu chuẩn thôi.
Cũng như việc 3D in ra một cái quạt mới, bạn Ctrl+C Ctrl+V mô hình đã có của bạn để đi làm việc mới. Giả sử bạn sử dụng một mô hình nhận diện mặt để đi nhận diện xúc xích chẳng hạn, bạn cần phải làm những gì? Khá chắc kèo bạn đã nghe đến thuật ngữ transfer learning -- nếu chưa thì đừng lo, đó chính là chủ đề của phần này! Chúng ta sẽ liệt kê ra các phương thức cơ bản bạn có thể sử dụng:
Trích xuất đặc trưng (Feature Extraction)
Đó là khi bạn sử dụng mạng (ví dụ như CNN/VGG nhé) chỉ để tách ra các đặc trưng sâu mà thôi. Từ mạng đã học, bạn giữ (đóng băng) toàn bộ trọng số cho đến lớp ngay trước softmax -- vector 1000 chiều đó sẽ là các đặc trưng được trích xuất. Sau đó bạn chỉ thay lớp softmax cuối để dự đoán xúc xích thay vì mặt.
Tinh chỉnh (Fine-tuning)
Bạn chả đóng băng gì hết. Lấy mô hình đã luyện để nhận diện mặt làm điểm khởi tạo, bạn dạy lại nó đi nhận biết có phải là xúc xích không. Có thể bạn chọn một tốc độ học thấp để nó không đi xa quá khỏi những gì nó đã biết. Hoặc bạn cũng có thể đóng băng một vài lớp đầu và chỉ tinh chỉnh một số lớp cuối thôi; việc đó hơi tương tự với cách trích xuất đặc trưng đã nói phía trên.
Và nếu bạn phải xài lại cái quạt
... thì ít nhất bạn có thể gập nó lại để đập ai đó.
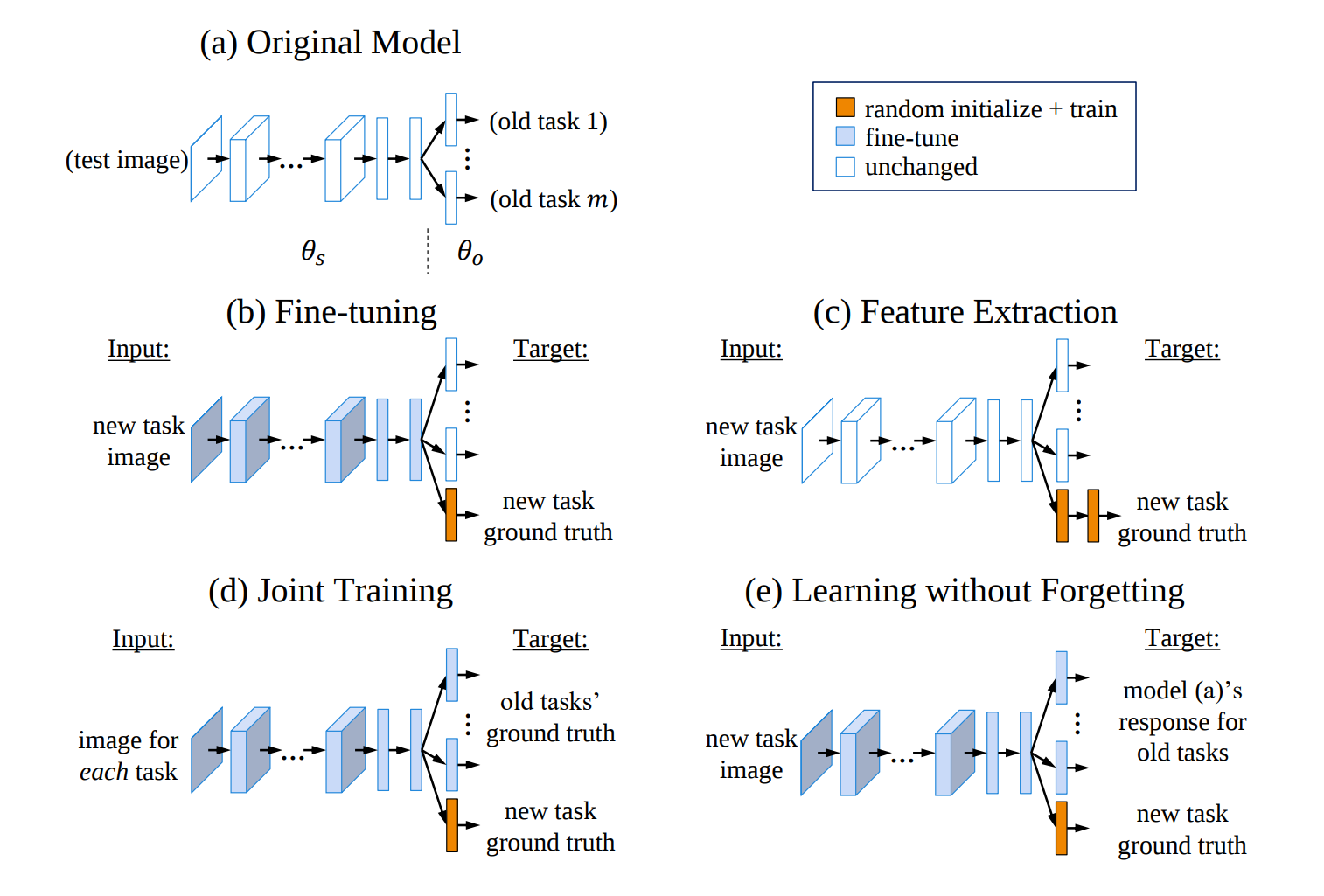
Sửa lại các phương pháp cơ bản ở trên
Chúng ta vẫn sử dụng mạng theo phương pháp trích xuất đặc trưng hoặc tinh chỉnh, tuy nhiên thay vì copy cả mạng thành 2, chúng ta chỉ thêm một lớp softmax khác cho nhiệm vụ mới của nó thôi. Tuy nhiên, chắc các bạn cũng nhận ra rằng bằng việc sử dụng các trọng số cũ/dạy đè lên nó, chất lượng các mô hình sẽ bị đi xuống. Vậy phải làm sao đây?
Dạy cả hai (Joint Training/Multitask Learning)
Sau khi đã tạo 2 đầu cho mô hình, bạn thỉnh thoảng bón thìa data ảnh mặt, lâu lâu đút thìa data xúc xích (và thay đổi đầu ra tương ứng đang được dạy). Nếu làm việc đó, mô hình sẽ được học đều đều sao cho nó làm tốt cả 2 việc một cách cân bằng nhất. Tuy nhiên, vấn đề là đâu phải lúc nào cũng có data của mô hình gốc đâu, vậy thì làm thế nào bây giờ?
Học không quên! (Learning without Forgetting)
Nếu không có data mô hình gốc, chúng ta chỉ cần tạo ra data đó thôi. Lấy các input dành cho mô hình mới và tính ra kết quả bằng mô hình cũ sẽ cho bạn một output mới thay thế ground truth -- vòila, bạn đã có một tập dữ liệu thay thế tập dữ liệu gốc. Ngoài ra, do dùng lại bộ data của task mới thay vì việc train lại trên data của task cũ, bạn không phải train model của bạn trên nhiều data như trên mục "dạy cả hai."
Chú ý! Toán phía trước. Có thể bỏ qua đoạn văn, chỉ là công thức thôi. Sự khác biệt có thể thấy được khi việc cân bằng chất lượng 2 mô hình của phương pháp LwF nằm gọn trong cùng một hàm mất mát (đã tạm rút gọn phần weight decay cho đơn giản):
với phần đầu là hàm mất mát cho mô hình cũ ( là output của mô hình cũ cho input mới), phần sau là hàm mất mát cho mô hình mới, và tham số điều khiển xem bạn muốn chú trọng vào việc giữ chất lượng mô hình cũ hơn hay tập trung dạy mô hình mới hơn.
So sánh giữa các phương pháp nói trên:
| tiêu chí | Fine-tuning | Trích xuất đặc trưng | Dạy cả hai | Học không quên |
|---|---|---|---|---|
| bài mới | ổn | bình thường | tốt | tốt |
| bài cũ | tệ | ổn | ổn | ổn |
| lúc train | nhanh | nhanh | chậm | nhanh |
| lúc test | nhanh | nhanh | nhanh | nhanh |
| bộ nhớ | vừa | vừa | to | vừa |
| cần data cũ | không | không | có | không |
Trọng số lò xo (Elastic Weight Consolidation)
Ý tưởng cơ bản của EWC tương tự với LwF, tuy nhiên các trọng số quan trọng hơn sẽ được giữ lại nhiều hơn. Phần này rất nhiều toán nên bạn có thể bỏ qua nếu câu giải thích chung chung phía trên là đủ với bạn rồi
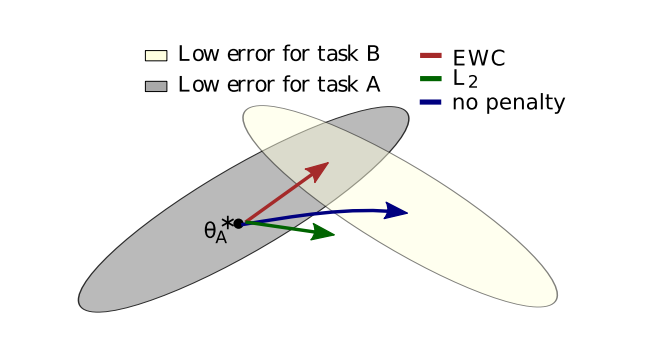
Bài báo lấy ví dụ dễ giải thích là một mạng tuyến tính chung chung dùng để phân loại (đưa ra xác suất 0/1). Vì việc train một mô hình là tìm ra các trọng số phù hợp nhất (xác suất cao nhất) với data đã có, chúng ta cần tối đa hóa xác suất , hay tương đương là log của nó (vì hàm log là hàm tăng dần). Sử dụng Bayes' rule, ta có
Chia nhỏ data ra thành 2 phần và , với A là task đầu đã học trọng số, và B là task mới, ta có
rồi thay thế ở công thức (1) với và thay thế vế phải của (2) ta có
Chú ý rằng , với là hàm mất mát của bài toán phân lớp (negative log-likelihood, bạn có thể tìm hiểu thêm tại đây, và đây). Từ công thức trên, bạn có thể thấy rằng, để tối ưu hóa một mạng kép, ta chỉ cần tối thiểu hóa hàm mất mát của task mới cộng thêm một số biểu diễn độ quan trọng của trọng số theo data task gốc (và không liên quan đến bài toán và có thể coi là một hằng số). Chúng ta ước lượng sử dụng Laplace transformation với ma trận thông tin Fisher :
Ma trận đó sẽ quyết định việc trọng số có được đi xa quá không. Cho (1) = (2) (và để ý là hằng số), ghép tất cả vào với nhau, ta có
với điều khiển tốc độ trọng số rời xa khỏi tối ưu của task gốc.
Nếu võ bạn to nữa
Nếu bạn vẫn sống sót sau chỗ toán kia thì mình xin một vái tại mình vẫn không hiểu hẳn biến đổi Laplace cho miền xác suất và ma trận thông tin Fisher đâu  Mình đưa tin mừng đến với bạn đây: toán đến đây đã hết, và từ đây toàn chưởng học sâu (và chúng ta biết rằng học sâu chẳng có bao nhiêu toán...)
Mình đưa tin mừng đến với bạn đây: toán đến đây đã hết, và từ đây toàn chưởng học sâu (và chúng ta biết rằng học sâu chẳng có bao nhiêu toán...)
Các phương pháp sau đây sẽ sử dụng việc các mô hình thường có đa số các trọng số gần bằng 0, và sử dụng các phương pháp cắt tỉa để tạo chỗ trong mô hình để chứa một mô hình tương tự khác. Về việc cắt tỉa, các bạn có thể tham khảo phiên bản rút gọn tại đây, một bài viết khá hay của đệ mình Phạm Hữu Quang (chỉ cần đọc mục Pruning thôi nhé!); hoặc phiên bản dài dằng dặc tại đây, một bài viết từ sếp của mình Phạm Văn Toàn.
PackNet
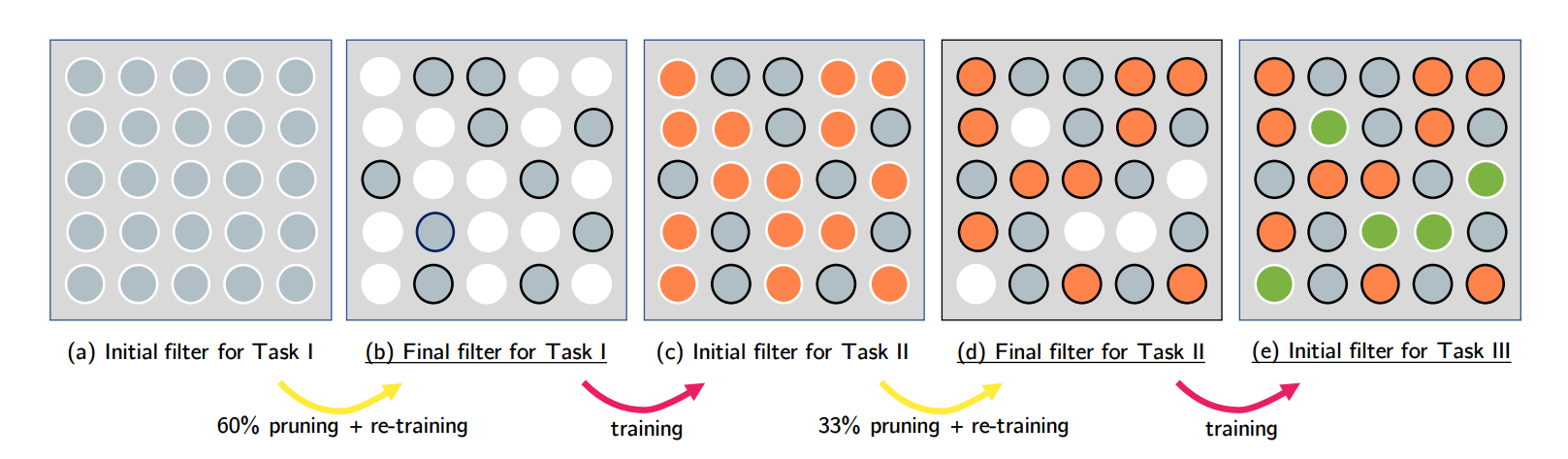
Như hình minh họa trên, từ một mô hình rất nhiều tham số chúng ta train cho task 1, chúng ta prune (đặt về 0) một số số tham số. Sau đó, chúng ta chỉ train chỗ tham số đã về 0 kia (và freeze chỗ trọng số được giữ lại không thay đổi gì hết) cho task 2 (lưu ý rằng task 2 vẫn được dùng chỗ trọng số đã được học từ task 1). Sau đó, chúng ta lại prune một phần chỗ trọng số của task 2, nhảy qua task 3, và cứ thế cho đến khi kín hết các trọng số.
Việc chọn các trọng số để giữ lại có thể hiểu như một phép ước lượng có thông số (parameterized estimation) của EWC, khi thay vì thay đổi các trọng số theo độ quan trọng của chúng, ta chọn luôn một số cố định các trọng số quan trọng để giữ nguyên, và các trọng số còn lại dạy lại từ đầu. Đồng thời, kết quả thí nghiệm thực cho thấy loại bớt 95% trọng số của mô hình thậm chí còn tăng chất lượng của chúng (!); và việc dùng lại các ô được giữ lại cho task sau có thể được coi như một phiên bản của transfer learning, khi nhưng thông tin quan trọng nhất đã học được truyền cho đời sau.
Về suy nghĩ cá nhân, có một số điểm họ không nhắc tới trong bài báo mà mình quan tâm.
(?) Tại sao họ prune chỗ weight đó đi thay vì chỉ mask chúng lúc train lại, để rồi bỏ đi những kiến thức nhỏ đã được học?
(!) Chắc chúng giúp mô hình không bị tắc ở một cực tiểu địa phương.
(?) Tại sao họ không chỉ cho task sử dụng một số (thay vì tất cả) các trọng số được học từ các task trước?
(!) Chắc tại việc đó khó quá ¯\_(ツ)_/¯
Piggyback
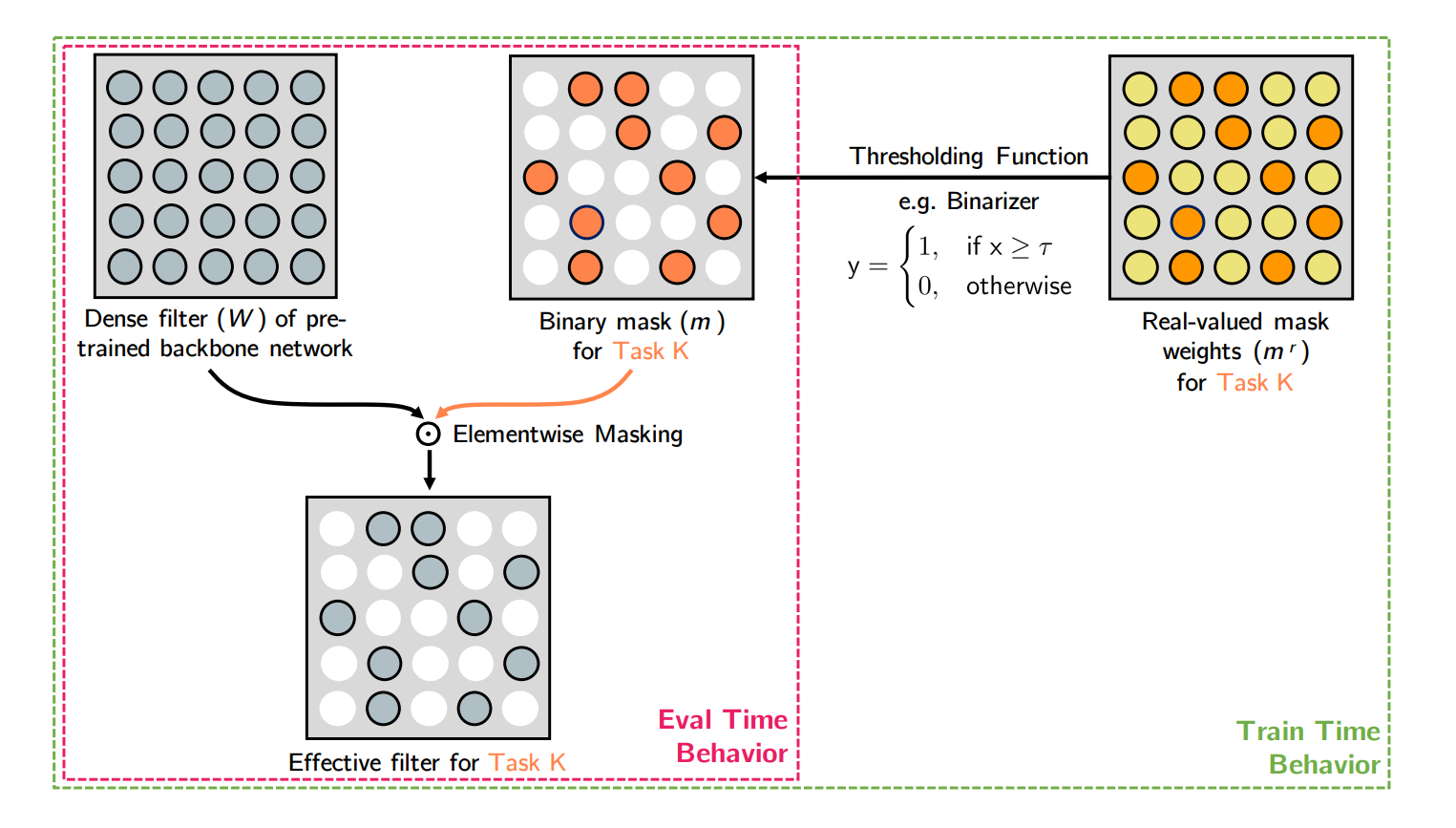
2 trong 3 tác giả của bài báo này là 2/2 tác giả của bài báo gốc về PackNet, nên chắc các bạn sẽ đoán ngay rằng đây là một mô hình cải tiến tốt hơn của mô hình nói trên. Tuy nhiên, không... Mô hình này train một lớp 0/1 mask đè lên một mạng gốc (VGG-16/ResNet-50) cho mỗi task cần làm, sử dụng một trọng số là ngưỡng chọn 0/1 -- có thể dễ nhận ra rằng lớp mask này đạo hàm được. Ý tưởng đơn giản, nhưng bài viết đó dài ơi là dòng với những thứ không cần thiết, nên các bạn hãy đọc lướt qua nó thôi. Chưa kể, nếu chỉ lọc ra các trọng số để tạo ra một mạng mới (không retrain lại các trọng số được chọn) và đạt được kết quả tốt hơn optimize full network thì hơi khó tin (hoặc là biết đâu lại đúng và mình chỉ thiếu niềm tin). Dù gì chăng nữa, mình vẫn liệt kê mạng này ra cho bài này toàn diện.
Kết bài và các nguồn tham khảo
Đến đây thì mình hết võ rồi. Nếu các bạn còn thì hãy nhắn mình ở dưới comment nhé. Đồng thời dạo này mình bị kẹt ý tưởng cho bài viết/nghiên cứu/luận án nên nếu các bạn có xin các cao nhân đừng ki bo hãy chia sẻ, tại hạ hứa sẽ credit đầy đủ =(( Xin cảm ơn và hẹn các bạn vào tháng sau!
Và sau đây là các bài báo tác giả đã phải vừa khóc vừa đọc để viết được bài này:
Learning without Forgetting:
https://arxiv.org/pdf/1606.09282.pdf
Elastic Weight Consolidation:
https://arxiv.org/pdf/1612.00796.pdf
PackNet:
https://arxiv.org/pdf/1711.05769.pdf
Piggyback:
https://arxiv.org/pdf/1801.06519.pdf
All rights reserved
