
Compression model: Áp dụng các kỹ thuật nén để tăng hiệu năng sử dụng các mô hình deep learning(Phần 1)
Bài đăng này đã không được cập nhật trong 5 năm
Trong suốt một thập kỉ qua, sự phát triển mạnh mẽ các công nghệ phần cứng cũng như sự giàu có về nguồn dữ liệu đã là đòn bẩy cho sự phát triển mạnh mẽ của ngành nghiên cứu trí tuệ nhân tạo. Sự nổi bật nhất mang tên Deep learning. Cứ vài ba tháng, một mô hình Deep learning mới lại ra đời, các state-of-the-art của các bài toán gần như đều đã thuộc về các mô hình Deep learning với vô vàn kiểu thiết kế, cấu hình mạng khác nhau. Thực sự Deep learning đã và đang làm nên điều kỳ diệu, nhiều bài toán sử dụng Deep learning có độ chính xác vượt xa cả con người. Không cần đến hai triệu năm, chỉ trong vài năm, xung quanh ta đã ngập tràn các loại kiến trúc, models và các kiến trúc, model có kích thước ngày càng lớn.

Tuy vậy, những mô hình này đều mang một đặc điểm chung là đều rất lớn dẫn đến việc tốn kém tài nguyên tính toán(khó có khả năng thực hiện real-time, tốn nhiều tài nguyên phần cứng,...) và tốn nhiều năng lượng(điện nuôi GPU). Có thể bạn nên đọc qua bài báo này Training a Single AI Model Can Emit As Much Carbon As Five Cars In Their Lifetimes. Có thể đọc đến đây, bạn đã có thể liên hệ ngay đến tiêu đề bài viết này và kết luận rằng mục đích của kĩ thuật mình đang muốn đề cập sắp tới ở đây là một mục đích vô cùng thánh thiện Chung tay bảo vệ trái đất xanh . Nhưng không, những công ty công nghệ lớn như Google, Facebook hay Amazon thì thường chẳng để ý mấy tới chút tiền điện nhỏ nhoi hay ít thải ra môi trường đâu, vậy vấn đề thực sự là gì?
Để thực hiện triển khai các ứng dụng Deep learning cho khách hàng, các công ty hoàn toàn có thể thiết kế hệ thống theo dạng client-server. Tức là mọi yêu cầu tính toán, dự đoán từ phía máy khách sẽ được chuyển về server xử lý sau đó lại trả kết quả về phía client. Đó là cách thiết kế phổ biến nhất. Và dĩ nhiên, họ giàu họ có thể thiết kế một server GPU vài ba tỏi để tăng tốc độ xử lý, chẳng vấn đề gì. Google phát triển khá nhiều các dịch vụ AI API trên hệ thống cloud của mình như một cách giải quyết đơn giản cho các bài toán yêu cầu khả năng tính toán lớn, nhưng nó đi kèm với một loạt các vấn đề. Một trong những vấn đề chính chính là kết nối mạng. Hệ thống cần phải hoạt động trơn tru, ổn định tại mọi thời điểm.
Mình cũng đã từng làm một ứng dụng sử dụng API cloud của Google Cloud Platform và mình cũng cảm nhận sâu sắc được vấn đề này. Thiết bị di động của mình thực hiện ghi âm và sử dụng API speech2text của Google để xử lý, tuy nhiên, tại buổi demo tốc độ xử lý lại không được như kì vọng khiến mình phát rồ. Vấn đề là khi phát triển ứng dụng, nhóm mình sử dụng mạng wifi với tốc độ khá ổn định và khi đi demo lại là tốc độ mạng 3G lúc có lúc không. Nhưng đúng, thực tế mà, đâu phải ai cũng có điều kiện mạng mẽo ổn định để sử dụng ứng dụng của bạn và bọn mình fail.
Do đó, việc tính toán tại local là vô cùng quan trọng đối với các hệ thống không đủ khả năng đảm bảo cho bất kỳ sự trễ mạng nào.
Một vấn đề khác của các hệ thống client-server chính là vấn đề bảo vệ quyền riêng tư và bảo mật dữ liệu khách hàng. Không phải ai cũng sẵn sàng đưa dữ liệu của mình lên 1 cái server nào đó để tính toán(và có thể lưu trữ). Ví dụ như việc bạn lắp đặt một thiết bị giúp ghi âm và dịch các hội thoại trong phòng họp của công ty bạn với khách hàng, bạn có chấp nhận những đoạn ghi âm nhỏ đấy được bắn lên 1 server có dịch vụ API speech2text không. Dĩ nhiên là không. Đối với những bài toán kiểu này, khách hàng thường yêu cầu các tính toán được thực hiện tại luôn thiết bị client hơn là các dịch vụ liên quan tới điện toán đám mây.
Tuy nhiên khó khăn lớn nhất khi đưa việc xử lý, tính toán về phía local chính là khả năng tính toán hạn chế của các thiết bị và tính toán nhiều thì thường đi kèm với vấn đề về pin(một vấn đề không nhỏ). Mặc dù những mô hình Deep learning đã thành công trong việc tạo ra kết quả với độ chính xác phi thường và hiệu suất ở mức chấp nhận được nhưng chúng yêu cầu sự hỗ trợ không nhỏ từ các GPU tốc độ cao, đắt tiền và tốn nhiều chi phí để vận hành, duy trì server hoặc khó có khả năng thực hiện trên các thiết bị phần cứng đơn giản. Như mình đã đề cập trong một bài viết trước đây của mình, sự thành công của một ứng dụng tích hợp AI không chỉ nằm ở độ chính xác mà còn nằm ở thời gian xử lý và chi phí duy trì, do vậy, để có một sản phẩm, ứng dụng tốt, ta không thể không quan tâm đến vấn đề này.
Đó chính là những lý do buộc các nhà nghiên cứu nghĩ đến việc thực hiện các kĩ thuật nén các model Deep learning.
Một thực tế đã được chỉ ra rằng không phải tất cả các trọng số model học được đều quan trọng cho qua trình suy luận, phán đoán của nó. Deep learning được thiết kế để end-to-end quá trình phán đoán của một thuật toán, quá trình trích xuất đặc trưng, đánh trọng số cho từng đặc trưng được thực hiện hoàn toàn tự động, do vậy bạn có thể thấy, nhiều đặc trưng dù có trọng số cực kì thấp(gần như không đóng góp gì trong quá trình phán đoán) vẫn được thực hiện tính toán như tất cả các đặc trưng khác(dĩ nhiên vì nó là black box nên mình cũng chẳng thế chỉ ra được tên của từng feature). Nghiên cứu về phương pháp pruning (cắt tỉa) và quantization đã chỉ ra rằng các kết nối thực sự quan trọng trọng model chỉ là một tỉ lệ vô cùng nhỏ trong mạng.

Mục tiêu của kĩ thuật này là có thể nén được các mô hình Deep learning phức tạp, chuyển chúng sang các thiết bị phần cứng cơ bản, chấm dứt sự phụ thuộc của chúng và các tài nguyên tính toán khổng lồ. Đạt được điều này có thể giúp chúng ra nhúng được các mô hình AI và mọi hệ thống chip, nhúng, các thiết bị IoT nhỏ xung quanh chúng ta. Ví dụ, các mô hình ImageNet nổi tiếng như AlexNet và VGG-16 đã được nén tới 40-50 lần so với kích thước ban đầu của chúng mà không làm giảm độ chính xác(thực tế còn tăng hơn một chút cơ). Điều này làm tăng đáng kể tốc độ tính toán của model và giúp nó có thể dễ dàng triển khai trên nhiều thiết bị khác nhau.
Model compression (nén model) có thể chia thành 2 kĩ thuật chính như đã đề cập ở trên là Pruning và Quantization. Ngoài ra cũng có các kĩ thuật khác như Weight Sharing, Low-Rank Approximation, Binary / Ternary Net, Winograd Transformation mà có thể mình sẽ đề cập đến trong một bài viết khác.
Pruning:
Ý tưởng cắt tỉa mạng neural network(Deep learning là trường hợp đặc biệt) được lấy cảm hứng từ chính sự cắt tỉa liên kết neural trong não người, nơi các liên kết thần kinh giữa các neural(axon) bị phân dã hoàn toàn và chết đi xảy ra giữa thời thơ ấu và sự sự khởi đầu của dậy thì.
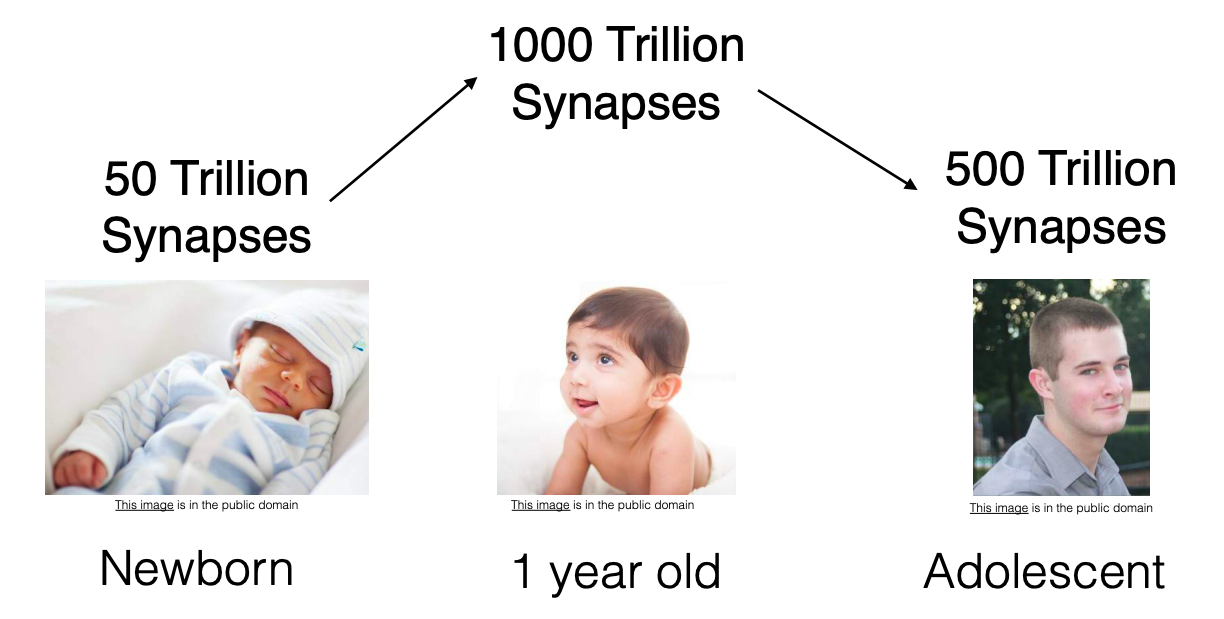
Hiểu một cách đơn giản, não bộ chúng ta thực hiện lưu trữ thông tin thông qua các liên kết thần kinh và cắt tỉa chúng khi được nhận biết đó là những thông tin không cần thiết. Những thông tin mà não người coi là không cần thiết chính là những thông tin lâu không được tác động tới, do vậy, muốn nhớ lâu thì ta thường hay phải làm nhiều lần và thỉnh thoảng nhớ lại. Kiến thức lâu rồi không động lại kiểu gì cũng sẽ quên.
Pruning chính là loại bỏ các kết nối dư thừa trong kiến trúc. Các kết nối dư thừa là các kết nối có trọng số không quan trọng(thường là các trọng số có giá trị tuyệt đối nhỏ, sát gần 0). Việc cắt tỉa các kết nối này sẽ không gây ảnh hưởng nhiều đến quá trình inference của mạng. Việc cắt bỏ này thực chất là đưa các giá trị trọng số gần 0 về 0 để loại bỏ những kết nối không cần thiết chứ để giảm quá trình tính toán chứ không phải như nhiều bạn nghĩ là cầm cái kéo cắt đứt kết nối như cái hình dưới này đâu.
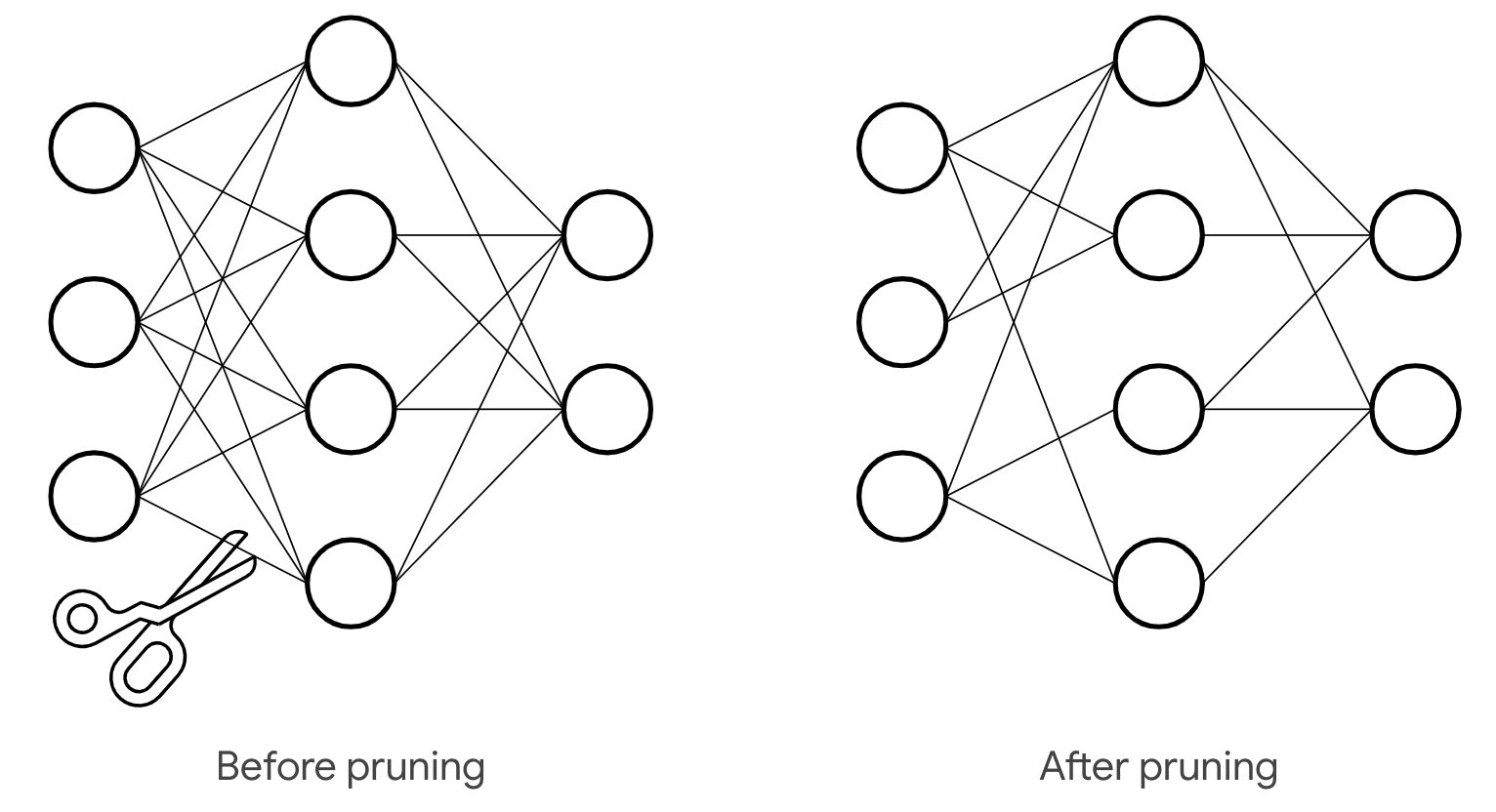
Với một mô hình đã được training sẵn(pre-trained model), để đạt được mức độ cắt tỉa là k%, chúng ta chỉ việc đặt xếp hạng các trọng số của mạng theo độ lớn của chúng, sau đó đặt k% lượng trọng số về giá trị 0. Thật đơn giản phải không.
Khi thực hiện cắt tỉa, mô hình mới được hình thành sẽ bị thay đổi ít nhiều và có thể có độ chính xác thấp hơn so với mô hình thực sự được đào tạo ban đầu. Tuy nhiên, một mẹo nhỏ để khắc phục vấn đề đó là ta có thể thực hiện quá trình fine-tuned lại model sau cắt tỉa để tăng độ chính xác ngang bằng với độ chính xác ban đầu hoặc thậm chí là hơn. Cần lưu ý rằng các lớp fully connected và CNN thường có thể thưa hóa đến trong khi vẫn giữ được độ chính xác ban đầu(do vậy cứ thoải mái mà tỉa đi).
Quantization:
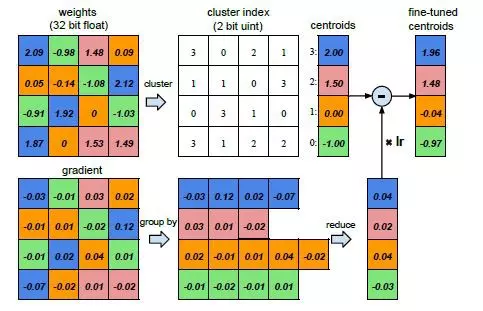
Thực sự mình cũng chẳng biết dịch quantization là gì nữa nên cứ gọi tạm vậy thế thôi ha. Hiểu một cách đơn giản, quantization liên quan đến việc kết hợp các trọng số với nhau bằng cách phân cụm chúng hoặc làm tròn chúng để có thể biểu diễn cùng một số lượng liên kết/kết nối nhưng với ít bộ nhớ hơn.
Quantization được thực hiện bằng cách phân cụm sử dụng số lượng giá trị số thực khác nhau ít hơn để biểu diễn số một lượng feature nhiều hơn. Đây là một trong những kĩ thuật phổ biến nhất. Như hình dưới đây là một ví dụ dễ hiểu về việc quantization bằng cách phân cụm. Các trọng số cùng màu được nhóm lại với nhau và được biểu diễn bằng trung bình cộng của chúng gọi là các centroids. Điều này làm giảm lượng bộ nhớ cần thiết để lưu trữ các trọng số này. Trước đó, mô hình yêu cầu để biểu diễn các trọng số. Sau khi sử dụng phân cụm, nó sẽ chỉ yêu cầu để biểu diễn chúng. Tương tự như quá trình cắt tỉa, chúng ta cần fine-tuned lại mô hình sau quá trình quantization. Điểm quan trọng ở đây là kiểu biểu diễn và tính chất của các trọng số trong quá trình quantization cần được duy trì trong quá trình fine-tuning. Trong quá trình tinh chỉnh, gradient cho tất cả các trọng số thuộc cùng một màu được tính tổng và sau đó được trừ với các centroids. Điều này đảm bảo rằng việc quantization phân cụm được duy trì trong quá trình fine-tuning.
Một kĩ thuật phổ biến khác là chuyển đổi trọng số(số thực) thành các biểu diễn cố định bằng cách làm tròn chúng(rời rạc hóa miền biểu diễn liên tục) . Cái này chắc dễ hình dung rồi. Ví dụ trọng số của mạng của bạn đang được lưu lại dưới dạng float64, bạn có thể làm tròn đưa về float32, float16, int8 hoặc thậm trí là các giá trị binary.
Lý thuyết về các cách nén model là vậy, thực tế áp dụng chúng như thế nào thì chúng ta cùng bắt đầu bằng cách sử dụng các Toolkit hỗ trợ chúng. Đầu tiên, hãy nghĩ tới là TensorFlow Model Optimization Toolkit.
TensorFlow Model Optimization Toolkit
TensorFlow Model Optimization Toolkit là một toolkit được phát triển bởi chính đội ngũ phát triển TensorFlow framework. Bạn có thể dễ dàng đọc được các hướng dẫn về Weight pruning ở đây cũng như Quantization một cách rất chi tiết. Bạn có thể dễ dàng nhìn thấy các kết quả đáng kinh ngạc khi áp dụng Weight pruning tại đây(không lại bảo mình chém).
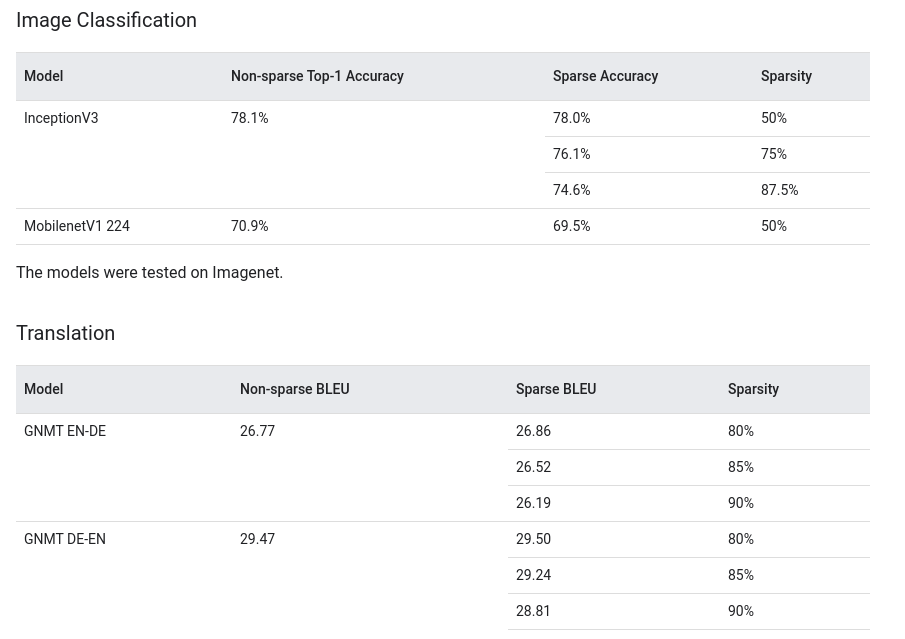
API cắt tỉa trọng số mạng hay còn gọi văn hoa là weight pruning API được xây dựng dựa trên Keras, do đó chúng ta dễ dàng áp dụng kĩ thuật này cho bất kì mô hình nào được huấn luyện bởi Keras framework(mình cũng thích làm Deep learning bằng Keras vì nó khá nhanh). Thư viện này mới được phát triển thôi và bản phát hành mới nhất là vào ngày 24/08 vừa rồi nên mình đoán nhiều bạn chưa biết. Để cài đặt, bạn thực hiện đơn giản qua pip.
pip install --user --upgrade tensorflow-model-optimization
Bạn có thể tham khảo code hướng dẫn sử dụng Weight pruning với Sentiment analysis task tại đây hay như huấn luyện một mô hình CNN về nhiệm vụ phân loại chữ số viết tay của MNIST với weight pruning tại đây.
Mình cũng sẽ giải thích một cách đơn giản về code ngay phần bên dưới này cho các bạn tiện theo dõi với bộ dữ liệu MNIST. Đầu tiên là việc chuẩn bị dữ liệu, MNIST là bộ dữ liệu có sẵn trong thư viện tensorflow nên mọi thứ đơn giản thôi.
import tensorflow as tf
# input image dimensions
img_rows, img_cols = 28, 28
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
Giờ đây chúng ta đã có 60000 ảnh huấn luyện về chữ số viết tay với kích thước , bắt đầu build một model đơn giản với bộ dữ liệu này.
from keras.models import Sequential
from keras import layers
model = Sequential()
model.add(layers.Conv2D(32, 5, padding='same', activation='relu', input_shape=input_shape))
model.add(MaxPooling2D((2, 2), (2, 2), padding='same'))
model.add(BatchNormalization())
model.add(Conv2D(64, 5, padding='same', activation='relu'))
model.add(MaxPooling2D((2, 2), (2, 2), padding='same'))
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
Huấn luyện mô hình:
from keras.losses import categorical_crossentropy
from keras.models import save_model
batch_size = 128
num_classes = 10
epochs = 10
model.compile(
loss=categorical_crossentropy,
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
save_model(model, "mnist.h5", include_optimizer=False)
Kết quả đạt được với Test accuracy: 99.17%. Mô hình có kích thước 13.1MB.
Keras-based weight pruning API được thiết kế có thể để loại bỏ các kết nối không quan trọng trong quá trình đào tạo. Lưu ý là trong quá trình đào tạo nên việc xác định thư hóa mô hình phải được thiết kế ngay từ đầu lúc xây dựng model. Về cơ bản, độ thưa của mô hình sẽ được chỉ định sẵn(ví dụ 90%) với lịch trình cắt tỉa được chỉ định sẵn. Dưới đây mình thực hiện cắt tỉa 90% mạng, bắt đầu từ step thứ 2000 đến hết quá trình training. Mô hình được weigth pruning tại các layer CNN và Dense.
from tensorflow_model_optimization.sparsity import keras as sparsity
import numpy as np
epochs = 12
num_train_samples = x_train.shape[0]
end_step = np.ceil(1.0 * num_train_samples / batch_size).astype(np.int32) * epochs
print('End step: ' + str(end_step))
pruning_params = {
'pruning_schedule': sparsity.PolynomialDecay(initial_sparsity=0.50,
final_sparsity=0.90,
begin_step=2000,
end_step=end_step,
frequency=100)
}
pruned_model = tf.keras.Sequential([
sparsity.prune_low_magnitude(
l.Conv2D(32, 5, padding='same', activation='relu'),
input_shape=input_shape,
**pruning_params),
l.MaxPooling2D((2, 2), (2, 2), padding='same'),
l.BatchNormalization(),
sparsity.prune_low_magnitude(
l.Conv2D(64, 5, padding='same', activation='relu'), **pruning_params),
l.MaxPooling2D((2, 2), (2, 2), padding='same'),
l.Flatten(),
sparsity.prune_low_magnitude(l.Dense(1024, activation='relu'),
**pruning_params),
l.Dropout(0.4),
sparsity.prune_low_magnitude(l.Dense(num_classes, activation='softmax'),
**pruning_params)
])
pruned_model.summary()
Huấn luyện mô hình:
from keras.models import save_model
pruned_model.compile(
loss=tf.keras.losses.categorical_crossentropy,
optimizer='adam',
metrics=['accuracy'])
callbacks = [
sparsity.UpdatePruningStep(),
]
pruned_model.fit(x_train, y_train,
batch_size=batch_size,
epochs=10,
verbose=1,
callbacks=callbacks,
validation_data=(x_test, y_test))
score = pruned_model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
final_model = sparsity.strip_pruning(pruned_model)
final_model.summary()
tf.keras.models.save_model(final_model, "pruned_model_mnist.h5", include_optimizer=True)
Mô hình thu được với Test accuracy: 99.36%. Mô hình cũng có kích thước là 13.1MB nhưng vấn đề quan trọng ở đây là khi nén lại model đã tiến hành weigth pruning chỉ có dung lượng 2.7MB trong khi model ban đầu nén lại là 12.1MB. Chứng tỏ quá trình thưa hóa, cắt tỉa thành công. Do có nhiều weight được đưa về giá trị không nên quá trình inference của mạng diễn ra nhanh hơn rất nhiều và giảm bớt số lượng tính toán cần phải tính.
Trên đây là cách sử dụng TensorFlow Model Optimization Toolkit với kĩ thuật Weight pruning, còn Quantization thì như mình đã giới thiệu phần lý thuyết ở trên, các bạn có thể tham khảo thêm tại document của tensorflow tại đây nha.
Trong bài viết này mình đã giải thích với các bạn thế nào Weigth pruning và Quantization, cách sử dụng TensorFlow Model Optimization Toolkit để weight pruning. Đấy thực sự là chưa phải là những gì mình muốn trình bày trong bài viết này nhưng bài viết đã dài rồi nên mình tạm ngắt để viết sang phần 2 về Model Compression. Nếu bài viết có gì sai sót mong các bạn comment ở phía dưới bài viết để mình tiến hành chỉnh sửa. Cảm ơn các bạn đã đọc bài và chờ đón phần 2 thôi.
Tài liệu tham khảo
All rights reserved
