
Ông Toằn Vi Lốc - Bí kíp võ công để tạo mô hình siêu siêu nhỏ li ti với độ chính xác khổng lồ
Bài đăng này đã không được cập nhật trong 6 năm
Xin chào các cháu, lại là ông đây. Hôm nay ông sẽ đem đến cho các cháu một chủ đề hết sức thú vị đó chính là Làm thế nào để xây dựng được các mô hình siêu nhỏ li ti mà vẫn đảm bảo độ chính xác cao. Đây chắc hẳn là một câu hỏi vô cùng thú vị với bất kì cháu nào đang thử nghiệm với các thuật toán Deep Learning và đặc biệt là các cháu đã có thích tìm hiểu về các kĩ thuật tăng hiệu năng cho model thì bài viết này chính là dành cho các cháu đó. Hôm nay không viết về các ứng dụng nữa mà sẽ viết sâu hơn về các kĩ thuật là nhiều các cháu ạ. Hi vọng các cháu vẫn sẽ ủng hộ ông nhé. OK chúng ta bắt đầu thôi
Tại sao mô hình cần phải siêu nhỏ li ti?
Có rất nhiều người chỉ quan tâm đến việc training một mô hình Deep learning sao cho độ chính xác thật là cao các cháu ạ. Đôi khi những mô hình có độ phức tạp khổng lồ mà thực sự không có một quy tắc nào để lựa chọn ra một kiến trúc tốt thật sự cả. Việc tạo dựng một mô hình có độ chính xác đủ tốt nhưng số lượng tính toán thì siêu nhỏ thực sự là một vấn đề đáng được quan tâm phải không các cháu. Có một câu mà ông khá tâm đắc đó là
Mô hình AI chỉ nằm trên jupyter notebook là những mô hình chết (the dead model)
Câu này muốn nói lên rằng dù các cháu có làm mô hình, thí nghiệm tốt đến đâu nhưng chỉ để nó trên jupyter notebook thì cũng chỉ là các mô hình mang tính chất nghiên cứu. Còn nếu muốn áp dụng nó vào trong thực tế thì lại cần rất nhiều yếu tố khác ngoài độ chính xác các cháu ạ. Câu nói này cũng nhấn mạnh hơn đến việc hậu xử lý sau khi traiing mô hình và quá trình deployment lên trên các hệ thống thực. Như vậy đối với các hệ thống thực tế thì chúng ta nên có tư duy làm cho mô hình của mình càng đơn giản, càng nhẹ thì càng tốt. Tất nhiên vẫn phải đảm bảo được độ chính xác nhé. Từ đó khái niệm về compression model ra đời và đây là các lý do chính của nó
- Giúp giảm kích thước lưu trữ: Khi mô hình của chúng ta được deploy trên các siu máy tính thì các cháu cứ thoải con gà mái đi, chả có gì phải lo cả. Rất tiếc rằng đời không phải lúc nào cũng như mơ, không phải lúc nào chúng ta cũng được sờ đến siu máy tính để mà deploy. Đại đa số các dự án đều muốn tiết kiệm chi phí nên việc cân nhắc đưa AI xuống các phần cứng có tốc độ trung bình là điều đáng để nghiên cứu. Chúng ta có thể kể đến các thiết bị có không gian lưu trữ hạn chế như Rapberry Pi, Mobile, Embeded Device... thế nên việc giảm kích thước của mô hình là điều rất quan trọng. Hãy tưởng tượng thay vì lưu trữ 1 mô hình 1GB thì các cháu giảm xuống chỉ còn 10MB thôi thì đã sang một câu chuyện khác. Nếu các cháu ensemble 10 biến thể của mô hình 1GB tức là các cháu sẽ tốn 10GB để lưu trữ bộ nhớ, ngược lại nếu được nén xuống còn 10MB thì các cháu chỉ tốn 100MB bộ nhớ vật lý thôi. Khác bọt quá phải không nào
- Giúp tăng tốc độ xử lý:Điều này là đương nhiên rồi, nếu như cả thế giới này điều là siu máy tính như ông kể trên thì chắc cũng chẳng cần phải quan tâm đến vấn đề này lắm. Tuy nhiên đa phần các mô hình AI kích thước quá lớn sẽ không thể chạy được real time trên các phần cứng có khả năng xử lý thấp. Vậy nên tốt nhất là lựa chọn mô hình đơn giản cho dễ dàng các cháu ạ.
- Độ chính xác thay đổi không đáng kể: Có lẽ các cháu đang thắc mắc là nếu cứ lựa chọn mô hình đơn giản thì không đạt được độ chính xác cần thiết thì sao. Điều này tất nhiên là một thắc mắc đúng. Tuy nhiên nếu việc nén mô hình chỉ được hiểu đơn giản là thay vì training mô hình to thì ta training một mô hình nhỏ hơn thì chưa hoàn toàn đúng. Ý nghĩa của từ nén ở đây đó chính là từ một mô hình lớn hơn, ta giảm kích thước lại mà vẫn giữ được độ chính xác của mô hình lớn ban đầu. Điểm mấu chốt ở đây là độ chính xác không bị thay đổi quá nhiều đó các cháu ạ. Đây chính là kĩ thuật để thiết kế ra một mô hình nhỏ nhưng có võ
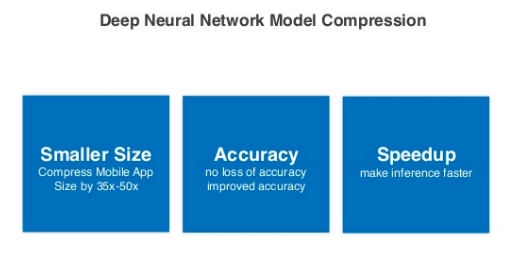
Làm sao để mô hình "nhỏ nhưng có võ"
Từ việc luyện võ đến training mô hình
Nghe lạ chưa nè, nhỏ nhưng có võ cứ làm ta liên tưởng đến một bộ truyện kiếm hiệp nào đó phải không các cháu. Các cao thủ hồi xưa đa phần đều là anh hùng xuất thiếu niên tuy nhiên có một điểm chung giữa họ đó chính là các thiếu niên anh hùng này thường là do được lĩnh hội từ một sư phụ nổi tiếng nào đó hoặc có kì duyên gặp được bí kíp võ công thượng thừa. Thế nên là không phải tự nhiên mà thành được anh hùng đâu các cháu nhé.
 Quay lại với việc training mô hình của chúng ta, nếu như mô hình của chúng ta xây dựng ban đầu là siêu nhỏ mà muốn nó có được sức mạnh siêu to khổng lồ thì khó lắm đấy các cháu nhé. Phải try hard rất nhiều mà kết quả chẳng được là bao. Những mô hình này chỉ được gọi là tuổi nhỏ làm việc nhỏ, tùy theo sức của mình thôi các cháu ạ. Vậy làm thế nào để đạt được cảnh giới thượng thừa như trên đây ta. Có một vài cách cơ bản các cháu nắm được như sau:
Quay lại với việc training mô hình của chúng ta, nếu như mô hình của chúng ta xây dựng ban đầu là siêu nhỏ mà muốn nó có được sức mạnh siêu to khổng lồ thì khó lắm đấy các cháu nhé. Phải try hard rất nhiều mà kết quả chẳng được là bao. Những mô hình này chỉ được gọi là tuổi nhỏ làm việc nhỏ, tùy theo sức của mình thôi các cháu ạ. Vậy làm thế nào để đạt được cảnh giới thượng thừa như trên đây ta. Có một vài cách cơ bản các cháu nắm được như sau:
- Tự tu luyện bí kíp rồi chắt lọc lại thành của riêng mình: Học hỏi từ các bí kíp tức là học hỏi các võ công cao siêu thượng thừa nhưng lại biết cách sáng tạo để tối giản, biến thành võ công của mình. Điều này thể hiện trong việc nén mô hình đó là training một mô hình lớn hơn đạt độ chính xác thật tốt sau đó tinh giản, loại bỏ đi các thành phần không cần thiết trong mô hình đó để đạt được mô hình siêu nhỏ li ti. Cách này có vẻ khá là tự thân vận động, đòi hỏi bạn phải có một nền tảng võ học vững chắc (tương tự như có một kiến trúc mạng tốt, đủ phức tạp để học hết các trường hợp) tuy nhiên kết quả đạt được thường là rất khả quan.
- Hấp thu nội lực từ các bậc tiền bối: Trong võ lâm cũng thi thoảng xuất hiện nhiều thanh niên gặp may, võ học thì cũng chưa có căn cơ gì nhưng lại gặp được cao nhân quý mến truyền cho nội công thâm hậu và tự nhiên trở thành cao thủ. Hẳn tuổi thơ của các cháu vẫn còn nhớ thanh niên bên dưới chứ. Đó là trong giới võ lâm, trong việc training model cũng chẳng khác là mấy các cháu ạ. Có một kĩ thuật người ta gọi là Knowledge distillation tức là cách training một mô hình nhỏ hơn bằng cách học hỏi lại kiến thức đã học được của một mô hình lớn hơn. Kiểu này gần giống như kiểu sư phụ dành hết tâm sức cả đời để truyền dạy ra các đệ tử chân truyền ý các cháu ạ.

Khẩu quyết tâm pháp
Các cháu ạ, các phương pháp luyện võ cũng tương tự như việc training mô hình AI, có rất nhiều nột thăng trầm, rất nhiều biến cố xảy ra để có thể đạt được môt mô hình tốt. Mong là các cháu hiểu được điều đó. Bây giờ cũng đã đến lúc ông chỉ cho các cháu khẩu quyết và tâm pháp của môn võ công nén mô hình này cho các cháu rồi đó. Khuyến khích các cháu nên đọc hết phần này, chớ vội nhảy vào thực hành ngay là dễ bị tẩu hỏa nhập ma lắm đó các cháu à. Bắt đầu nhé các cháu.
Cắt tỉa
Network pruningkhông phải là một khái niệm mới mẻ, nhất là đối với các cháu làm việc nhiều với các mô hình Deep Learning. Thực ra việc dropout mà các cháu thường sử dụng trong quá trình training cũng là một dạng cắt tỉa để tránh hiện tượng overfit. Tuy nhiên việc cắt tỉa ứng dụng trong mô hình nén thì là một khái niệm không hẳn giống với dropout. Nếu như dropout sẽ bỏ ngẫu nhiên một tỉ lệ phần trăm số lượng kết nối giữa các layer trong quá trình training thì khái niệm Network pruning ở đây tức là tìm các connection không cần thiết trong mạng (loại bỏ đi cũng không ảnh hưởng nhiều đến độ chính xác) để cắt tỉa đi. Thuật toán này có thể được thực hiện qua ba bước như sau:
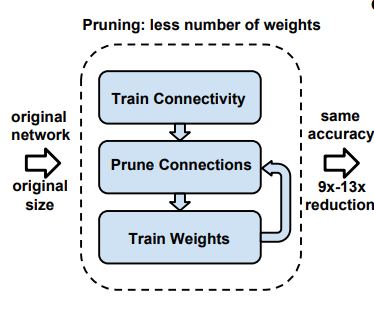
- Training mạng khởi tạo mạng này thường là một mạng lớn với các kết nối đầy đủ giữa từng layer. Sở dĩ chọn một mạng đủ lớn để giúp cho việc học mô hình đạt được độ chính xác cao nhất định
- Loại bỏ các connection dư thừa: Chúng ta sẽ loại bỏ các connection với các trọng số nhỏ hơn một ngưỡng nào đó định trước. Thông thường các trọng số này là các trọng số không quá quan trọng và có thể bỏ đi được. Tất nhiên khi loại bỏ đi các connection này, mạng của các cháu sẽ trở nên thưa thớt hơn vì có rất nhiều các connection được mang giá trị 0 và sẽ làm ảnh hưởng đến độ chính xác lúc đầu. Chính vì thế nên để khôi phục lại được độ chính xác lúc đầu thì các cháu cần phải làm bước thứ 3
- Retrain lại kiến trúc mạng đã được cắt tỉa sau khi cắt tỉa thì độ chính xác sẽ có phần thay đổi, việc của các cháu là training lại các tham số (của mô hình đã được cắt tỉa) sao cho đạt được độ chính xác tương đương với độ chính xác lúc đầu. Và cuối cùng các cháu sẽ thu được một mô hình vừa nhỏ, vừa có võ rồi đấy

Lượng tử hóa và share weight
Sau khi đã nén được mô hình bằng phương pháp cắt tỉa (Trong thí nghiệm dưới của ông nó giảm đến 90% so với mạng lúc đầu). Chúng ta sẽ sử dụng một kĩ thuật gọi là lượng tử hóa để giảm số lượng các bit cần thiết trong quá trình lưu trữ các weight của mạng nơ ron. Nói một cách đơn giản như thế này nhé, các cháu phải nấu cơm cho một đại gia đình gồm rất nhiều thế hệ, nấu một món canh mà bố chồng thì thích cho 0.9 lít nước mắm, mẹ chồng thích cho 0.95 lít nước mắm còn chồng thì thích cho 1 lít nước mắm. Nếu mà nấu như vậy thì chắc sẽ rất mất công nên các cháu chỉ cần chọn một lượng nước mắm vừa đủ cho cả nhà ăn và con số 0.95 lít nước mắm (theo sở thích của mẹ chồng) là cân bằng và khéo léo hơn cả. Đây là quy tắc chọn đánh giá đại diện và cũng là tư tưởng chính của việc lượng tử hóa và share weight. Đây là quá trình chia toàn bộ số lượng weight của một layer thành các cụm nhỏ (clusters) và mỗi cụm sẽ được chia sẻ chung một giá trị weight. Giá trị này thường là giá trị tâm cụm (centroid) thể hiện được đặc trựng nhất của cụm đó. Điều ày cũng giống như việc các cháu chọn mẹ chồng làm trung tâm của gia đình đó các cháu ạ. Để hình dung rõ hơn thì mời các cháu xem hình dưới đây:
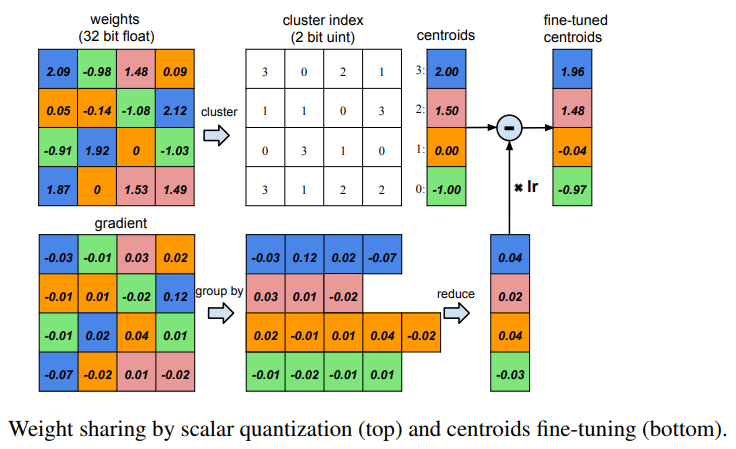
Các cháu có thể nhận ra được một vài điều:
- Ma trận Weight đầu tiên (ở trên cùng bên trái) là weight lúc đầu. Từ ma trận này này ta chia là 4 cụm khác nhau thể hiện bằng 4 màu xanh dương, xanh lá, da cam và hồng phấn. Đây được thực hiện bằng cách sử dụng k-means với k bằng 4.
- sau đó ở mỗi cụm sẽ được lưu một giá trị giống nhau là giá trị của tâm cụm, thể hiện ở phía trên cùng bên phải. Như vậy với 4 cụm các cháu chỉ cần lưu 4 giá trị của centroid và tốn bit để lưu vị trí của index
- Một cách tổng quát để tính toán được độ nén của mạng khi sử dụng quantization và share weight thì các cháu cần hình dung như sau. Lúc đầu có weight và tốn bits để lưu trữ weight đó. Vậy lượng bit sử dụng là . Sau khi lượng tử hóa thành cụm thì sẽ tốn bits để lưu giá trị centroid của mỗi cụm và thêm bits để lưu giá trị của các index. Vậy tỉ số nén sẽ là
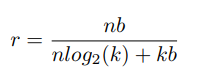
Truyền nội công - Knowledge distillation
Knowledge distillation là một tư tưởng mới của compression network, nó không dựa trên cắt tỉa trên chính mạng cũ mà sử dụng một mạng nơ ron lớn hơn đã được trained sẵn để dạy lại cho một mạng nhỏ hơn. Bằng cách dạy lại mạng nhỏ học từng features map sau mỗi lớp tích chập của mạng lớn, đây có thể coi là một soft-label cho mạng nhỏ đó các cháu ạ. Hiểu đơn giản thì thay vì học trực tiếp từ dữ liệu gốc ban đầu thì mạng nhỏ sẽ học lại cách mà mạng lớn đã học, học lại các distribution của wieght và các feature map đã được tổng quát từ mạng lớn. Mạng nhỏ sẽ cố gắng học lại các cách xử lý của mạng lớn ở mọi lớp trong mạng chứ không chỉ là hàm loss tổng đâu nhé. Các cháu có thể hình dung nó trong hình sau nhé. Riêng về phương pháp truyền nội công này thì ông sẽ dành riêng một bài để viết về các kĩ thuật và các cách implement mạng trong đó nha.
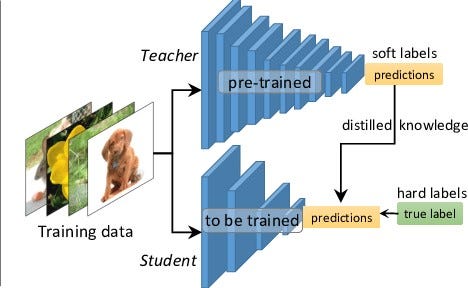
Tu luyện bí kíp
Giờ đến phần mà cháu nào cũng mong ngóng đây, chúng ta đi vào code thôi nhé. Dù sao thì học lý thuyết mãi rồi giờ cũng phải lôi ra thực hành chứ nhỉ. Trong phần này ông sẽ không sử dụng một thư viện cắt tỉa nào mà sẽ hướng dẫn các cháu implement từ đầu để hiểu được bản chất của thuật toán này nhé. Không quá phức tạp đâu. Bắt đầu thôi nào
Cắt tỉa
Phương pháp đầu tiên chúng ta sẽ xem xét đến đó chính là cắt tỉa. Để demo cho bài này ông sử dụng kết trúc của Fully Connected đơn giản thôi nhé. Việc implement các mô hình CNN hay LSTM cũng tương tự nếu các cháu hiểu được tư tưởng của nó rồi.
Import các thư viện cần thiết
Trong bài này ông sử dụng Pytorch nên các cháu import một số thư viện cần thiết nha
import numpy as np
import torch
from torch.nn import Parameter
from torch.nn.modules.module import Module
import torch.nn.functional as F
import math
from torch import nn
Xây dựng base model
Model cắt tỉa cần được kế thừa từ base Module của Pytorch các cháu ạ. Như đã nói với các cháu từ phần lý thuyết rồi, bản chất của cắt tỉa là lựa chọn ra một ngưỡng để lọc ra các weight nào nhỏ hơn ngưỡng đó (các weight kém quan trọng). Để cho đơn giản thì ông sẽ sử dụng độ lệch chuẩn để tính toán threshold.
class PruningModule(Module):
def prune_by_std(self, s=0.25):
# Note that module here is the layer
# ex) fc1, fc2, fc3
for name, module in self.named_modules():
if name in ['fc1', 'fc2', 'fc3']:
threshold = np.std(module.weight.data.cpu().numpy()) * s
print(f'Pruning with threshold : {threshold} for layer {name}')
module.prune(threshold)
các cháu có thể tùy chỉnh tham số s=0.25 để tính toán giá trị của threshold cần cắt tỉa nhé
Xây dựng module cắt tỉa
class MaskedLinear(Module):
def __init__(self, in_features, out_features, bias=True):
super(MaskedLinear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
# Initialize the mask with 1
self.mask = Parameter(torch.ones([out_features, in_features]), requires_grad=False)
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input):
# Caculate weight when forward step
return F.linear(input, self.weight * self.mask, self.bias)
def __repr__(self):
return self.__class__.__name__ + '(' \
+ 'in_features=' + str(self.in_features) \
+ ', out_features=' + str(self.out_features) \
+ ', bias=' + str(self.bias is not None) + ')'
# Customize of prune function with mask
def prune(self, threshold):
weight_dev = self.weight.device
mask_dev = self.mask.device
# Convert Tensors to numpy and calculate
tensor = self.weight.data.cpu().numpy()
mask = self.mask.data.cpu().numpy()
new_mask = np.where(abs(tensor) < threshold, 0, mask)
# Apply new weight and mask
self.weight.data = torch.from_numpy(tensor * new_mask).to(weight_dev)
self.mask.data = torch.from_numpy(new_mask).to(mask_dev)
Trong hàm trên các cháu cần quan tâm đến một số chức năng chính như sau:
- Mặt nạ: các cháu có để ý được layer
self.maskđược định nghĩa không. Đây là một mặt nạ hay một bộ lọc cho phép chúng ta quyết định những weight nào được tính toán, những weight nào không được tính toán. Ban đầu mặt nạ này được khởi tạo là ma trận toàn số 1. Sau khi cắt tỉa những weight nào không cần nữa thì sẽ thành số 0. Tư tưởng chính là vậy - Hàm forward hàm này thực hiện chức năng tính toán weight, thay vì nhân thẳng weight với input thông thường thì lúc này weight sẽ được nhân với bộ lọc trước. Điều này giúp loại bỏ đi các weight không cần thiết sau khi đã cắt tỉa
F.linear(input, self.weight * self.mask, self.bias)
- Hàm prune hàm này thực hiện chức năng chính là cắt tỉa. Tại mỗi lần cắt tỉa nó sẽ tính toán các trong số nào có weight nhỏ hơn ngưỡng quy định, cập nhật lại mask và weight tại các vị trí đó về giá trị 0. Cũng khá đơn giản thôi phải không các cháu.
Cài đặt mạng Fully Connected
class LeNet(PruningModule):
def __init__(self, mask=False):
super(LeNet, self).__init__()
linear = MaskedLinear if mask else nn.Linear
self.fc1 = linear(784, 300)
self.fc2 = linear(300, 100)
self.fc3 = linear(100, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.log_softmax(self.fc3(x), dim=1)
return x
Đơn giản là kết nối tất cả các module lại với nhau thôi, giống như các bài toán phân loại thông thường thôi các cháu ạ. Mạng này bao gồm 3 lớp fully connected (chính là instance của lớp MaskedLinear đã cài phía trước). 3 lớp này kết nối với nhau tạo thành mạng của chúng ta.
Cài đặt một số hyperparemeter
Trước khi bước vào training mạng thì các cháu cần định nghĩa các tham số cần thiết của mô hình
# Define some const
BATCH_SIZE = 128
EPOCHS = 100
LEARNING_RATE = 0.001
USE_CUDA = True
SEED = 42
LOG_AFTER = 10 # How many batches to wait before logging training status
LOG_FILE = 'log_prunting.txt'
SENSITIVITY = 2 # Sensitivity value that is multiplied to layer's std in order to get threshold value
# Control Seed
torch.manual_seed(SEED)
# Select Device
use_cuda = USE_CUDA and torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else 'cpu')
Cài đặt dataloader
Trong bài này ông sẽ sẽ sử dụng tập dữ liệu MNIST quen thuộc để cho tốc độ training được nhanh hơn nhé. Các cháu tiến hành cài đặt với transforms của PyTorch
# Create the dataset with MNIST
from torchvision import datasets, transforms
# Train loader
kwargs = {'num_workers': 5, 'pin_memory': True} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True, **kwargs)
# Test loader
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=False, **kwargs)
Sau đó thì định nghĩa model để chuẩn bị cho bước training
model = LeNet(mask=True).to(device)
Định nghĩa optimizer
Các cháu sử dụng Adam Optimizer quen thuộc trong các bài toán classification rồi nhé
import torch.optim as optim
# Define optimizer with Adam function
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE, weight_decay=0.0001)
initial_optimizer_state_dict = optimizer.state_dict()
Training mô hình
from tqdm import tqdm
# Define training function
def train(model):
model.train()
for epoch in range(EPOCHS):
pbar = tqdm(enumerate(train_loader), total=len(train_loader))
for batch_idx, (data, target) in pbar:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
# zero-out all the gradients corresponding to the pruned connections
for name, p in model.named_parameters():
if 'mask' in name:
continue
tensor = p.data.cpu().numpy()
grad_tensor = p.grad.data.cpu().numpy()
grad_tensor = np.where(tensor==0, 0, grad_tensor)
p.grad.data = torch.from_numpy(grad_tensor).to(device)
optimizer.step()
if batch_idx % LOG_AFTER == 0:
done = batch_idx * len(data)
percentage = 100. * batch_idx / len(train_loader)
pbar.set_description(f'Train Epoch: {epoch} [{done:5}/{len(train_loader.dataset)} ({percentage:3.0f}%)] Loss: {loss.item():.6f}')
return model
Đây là bước khá quan trọng, sau khi chúng ta đã lên được kiến trúc của mô hình rồi thì việc training mô hình cũng rất quan trọng. Đặc biệt là training mô hình sau khi đã cắt tỉa, các cháu chú ý vào đoạn code phía dưới
# zero-out all the gradients corresponding to the pruned connections
for name, p in model.named_parameters():
if 'mask' in name:
continue
tensor = p.data.cpu().numpy()
grad_tensor = p.grad.data.cpu().numpy()
grad_tensor = np.where(tensor==0, 0, grad_tensor)
p.grad.data = torch.from_numpy(grad_tensor).to(device)
Đoạn code này thực hiện việc đưa tất cả các đạo hàm của các weight đã được cắt tỉa về 0 để optimizer sẽ bỏ qua những weight đó. Các cháu lưu ý là hàm này sẽ không chạy trong lần đầu training mà sẽ chạy sau khi mạng đã được cắt tỉa và cần fine-tuning lại. Mục đích của nó là giúp optimizer chỉ tối ưu vào các trọng số chưa được cắt tỉa (quan trọng) thôi các cháu nhé. Sau khi xây dựng được hàm này các cháu tiến hành training theo câu lệnh:
model = train(model)
Làm cốc cafe và ngồi đợi mô hình chạy thôi các cháu
Train Epoch: 94 [58880/60000 ( 98%)] Loss: 0.005322: 100%|██████████| 469/469 [00:02<00:00, 165.10it/s]
Train Epoch: 95 [58880/60000 ( 98%)] Loss: 0.019957: 100%|██████████| 469/469 [00:02<00:00, 163.42it/s]
Train Epoch: 96 [58880/60000 ( 98%)] Loss: 0.009064: 100%|██████████| 469/469 [00:02<00:00, 169.39it/s]
Train Epoch: 97 [58880/60000 ( 98%)] Loss: 0.001462: 100%|██████████| 469/469 [00:02<00:00, 166.62it/s]
Train Epoch: 98 [58880/60000 ( 98%)] Loss: 0.043480: 100%|██████████| 469/469 [00:02<00:00, 161.13it/s]
Train Epoch: 99 [58880/60000 ( 98%)] Loss: 0.046619: 100%|██████████| 469/469 [00:02<00:00, 167.76it/s]
Testing mô hình
Sau khi training các cháu đã thu được mô hình, việc tiếp theo cần phải test mô hình và kiểm tra số lượng tham số khác 0
from time import time
def test(model):
start_time = time()
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%). Total time = {time() - start_time}')
return accuracy
Hàm này cũng rất cơ bản rồi, các cháu chỉ việc chạy thôi
accuracy = test(model)
Các cháu sẽ thu được kết quả ví dụ như sau:
Test set: Average loss: 0.0758, Accuracy: 9818/10000 (98.18%). Total time = 0.545386552810669
Sau đó các cháu có thể lưu lại gía trị log này vào một file để theo dõi cho tiện
def save_log(filename, content):
with open(filename, 'a') as f:
content += "\n"
f.write(content)
Và thực hiện lưu lại cả wieght của mô hình
save_log(LOG_FILE, f"initial_accuracy {accuracy}")
torch.save(model, f"save_models/initial_model.ptmodel")
Tính toán số lượng non-zeros parameters
Điều này có ý nghĩa và cần thiết để các cháu quyết định xem nên cắt tỉa ở những layer nào
# Print number of non-zeros weight in model
def print_nonzeros(model):
nonzero = total = 0
for name, p in model.named_parameters():
if 'mask' in name:
continue
tensor = p.data.cpu().numpy()
nz_count = np.count_nonzero(tensor)
total_params = np.prod(tensor.shape)
nonzero += nz_count
total += total_params
print(f'{name:20} | nonzeros = {nz_count:7} / {total_params:7} ({100 * nz_count / total_params:6.2f}%) | total_pruned = {total_params - nz_count :7} | shape = {tensor.shape}')
print(f'alive: {nonzero}, pruned : {total - nonzero}, total: {total}, Compression rate : {total/nonzero:10.2f}x ({100 * (total-nonzero) / total:6.2f}% pruned)')
Sau đó chạy thử
print_nonzeros(model)
các cháu có thể thu được kết quả tương tự như sau:
fc1.weight | nonzeros = 235200 / 235200 (100.00%) | total_pruned = 0 | shape = (300, 784)
fc1.bias | nonzeros = 300 / 300 (100.00%) | total_pruned = 0 | shape = (300,)
fc2.weight | nonzeros = 30000 / 30000 (100.00%) | total_pruned = 0 | shape = (100, 300)
fc2.bias | nonzeros = 100 / 100 (100.00%) | total_pruned = 0 | shape = (100,)
fc3.weight | nonzeros = 1000 / 1000 (100.00%) | total_pruned = 0 | shape = (10, 100)
fc3.bias | nonzeros = 10 / 10 (100.00%) | total_pruned = 0 | shape = (10,)
alive: 266610, pruned : 0, total: 266610, Compression rate : 1.00x ( 0.00% pruned)
Có thể thấy rằng khi chưa được cắt tỉa thì mạng này có toàn bộ các weight là khác 0.
Tiến hành cắt tỉa
Chạy một lệnh duy nhất
# Pruning
model.prune_by_std(SENSITIVITY)
>>> Output
Pruning with threshold : 0.07490971684455872 for layer fc1
Pruning with threshold : 0.11689116805791855 for layer fc2
Pruning with threshold : 0.37801066040992737 for layer fc3
sau đó test lại một lần nữa xem lúc này accuracy đã giảm như thế nào
accuracy = test(model)
>>> Output
Test set: Average loss: 1.2319, Accuracy: 5805/10000 (58.05%). Total time = 0.6268196105957031
Lưu kết quả vào log file và kiểm tra lại số lượng tham số của mạng
save_log(LOG_FILE, f"accuracy_after_pruning {accuracy}")
print_nonzeros(model)
>>> Output
fc1.weight | nonzeros = 13395 / 235200 ( 5.70%) | total_pruned = 221805 | shape = (300, 784)
fc1.bias | nonzeros = 300 / 300 (100.00%) | total_pruned = 0 | shape = (300,)
fc2.weight | nonzeros = 2100 / 30000 ( 7.00%) | total_pruned = 27900 | shape = (100, 300)
fc2.bias | nonzeros = 100 / 100 (100.00%) | total_pruned = 0 | shape = (100,)
fc3.weight | nonzeros = 59 / 1000 ( 5.90%) | total_pruned = 941 | shape = (10, 100)
fc3.bias | nonzeros = 10 / 10 (100.00%) | total_pruned = 0 | shape = (10,)
alive: 15964, pruned : 250646, total: 266610, Compression rate : 16.70x ( 94.01% pruned)
Các cháu thấy mô hình đang bị giảm độ chính xác đi khá nhiều, từ 98.18% xuống còn 58.05% trong khi số lượng tham số bị cắt tỉa là 94.01% tương ứng với tỉ lệ nén khoảng 16 lần. Việc cần làm tiếp theo của chúng ta là training lại nó. Cũng bằng một lệnh duy nhất
# Retraining
optimizer.load_state_dict(initial_optimizer_state_dict) # Reset the optimizer
model = train(model)
Lại ngồi uống cafe và chờ đợi kết quả thôi. Sau khi training xong các cháu tiến hành test lại độ chính xác của mô hình
accuracy = test(model)
>>> Output
Test set: Average loss: 0.0800, Accuracy: 9839/10000 (98.39%). Total time = 0.5431315898895264
Các cháu thấy điều kì diệu chưa, độ chính xác còn cao hơn một chút so với mô hình lúc đầu trong khi tỉ lệ nén của mô hình là 16 lần rồi đó. Các cháu tiến hành lưu lại log nữa là chúng ta sẽ hoàn thành xong phần cắt tỉa mô hình
save_log(LOG_FILE, f"accuracy_after_retraining {accuracy}")
torch.save(model, f"save_models/model_after_retraining.ptmodel")
Tiếp theo để tiến hành tăng tỉ số nén chúng ta sẽ đến với phần lượng tử hóa và share weight nhé.
Lượng tử hóa và Share weight
from sklearn.cluster import KMeans
from scipy.sparse import csc_matrix, csr_matrix
def apply_weight_sharing(model, bits=5):
for module in model.children():
dev = module.weight.device
weight = module.weight.data.cpu().numpy()
shape = weight.shape
mat = csr_matrix(weight) if shape[0] < shape[1] else csc_matrix(weight)
min_ = min(mat.data)
max_ = max(mat.data)
space = np.linspace(min_, max_, num=2**bits)
kmeans = KMeans(n_clusters=len(space), init=space.reshape(-1,1), n_init=1, precompute_distances=True, algorithm="full")
kmeans.fit(mat.data.reshape(-1,1))
new_weight = kmeans.cluster_centers_[kmeans.labels_].reshape(-1)
mat.data = new_weight
module.weight.data = torch.from_numpy(mat.toarray()).to(dev)
return model
Giải thích thêm một chút cho các cháu về hàm này nhé. Có một vài điểm cần lưu ý
- Lưu trữ dưới dạng compressed sparse row (CSR) hoặc compressed sparse column (CSC) format đây là hai format để lưu trữ ma trận thưa nhằm tính toán được dễ dàng do tiết kiệm về bộ nhớ. Các cháu có nhớ rằng weight của chúng là là một ma trận rất thưa với 94% các trọng số là khác 0. Do vậy cần phải có một cấu trúc phù hợp để lưu trữ và tính toán. Ông không giải thích sâu về format này, nếu cần các cháu có thể tự tìm hiểu ở đây nhé.
- Sử dụng Kmean để phân cụm: Điều này được thực hiện trong hàm sau
min_ = min(mat.data)
max_ = max(mat.data)
print(min_, max_)
space = np.linspace(min_, max_, num=2**bits)
kmeans = KMeans(n_clusters=len(space), init=space.reshape(-1,1), n_init=1, precompute_distances=True, algorithm="full")
kmeans.fit(mat.data.reshape(-1,1))
Ở đây số lượng bits được sử dụng để lưu trữ các giá trị weight là 5. Do đó các cháu sẽ có tối đa là cụm của Kmeans. Sau khi thực hiện phân cụm xong thì các cháu tiến hành share lại centroid vào các vị trí weight bằng hàm
new_weight = kmeans.cluster_centers_[kmeans.labels_].reshape(-1)
Sau khi tiến hành share weight các cháu cần tính toán lại accuracy
accuracy = test(model)
Test set: Average loss: 0.0705, Accuracy: 9840/10000 (98.40%). Total time = 0.5958971977233887
Có thể thấy độ chính xác sau khi share weight nhỉnh hơn một chút so với trước khi share weight. Cái này cũng tùy trường hợp thôi nhé các cháu không phải trường hợp nào cũng cao hơn. Nếu kêt quả tệ hơn các cháu nên xem xét lại các threshold cắt tỉa để sao cho kết quả sau khi fine tune đạt cao nhất có thể nhé
Kết luận
Các kĩ thuật về nén mô hình là một trong những kĩ thuật rất hay và quan trọng trong bước deploy. Kĩ thuật này giúp cho việc deploy mô hình lên các phần cứng có cấu hình thấp khả thi hơn, tận dụng được không gian lưu trữ của bộ nhớ máy tính. Đối với các mạng khác thì dung lượng mô hình sau khi giải nén giảm đi rất nhiều lần. Các cháu có thể xem ví dụ trong ảnh sau:

Hi vọng rằng với bài viết này các cháu có thể tự mình thực hiện được các thao tác liên quan đến cắt tỉa mô hình. Xin chào tạm biệt các cháu và hẹn gặp lại trong những bài viết tiếp theo nha
All rights reserved
