Sử dụng EXPLAIN để tối ưu câu lệnh MySQL
Bài đăng này đã không được cập nhật trong 4 năm
Bài viết sau dịch từ nguồn sitepoint.com.
Khi bạn muốn thực thi một câu truy vấn (query), MySQL Query Optimizer sẽ cố gắng đưa ra một kế hoạch tối ưu nhất cho việc thực hiện query. Bạn có thể thấy thông tin về kế hoạch đó bằng cách thêm lệnh EXPLAIN vào đầu mỗi query. EXPLAIN là một trong những công cụ quan trọng giúp hiểu và tối ưu truy vấn MySQL, tuy nhiên, điều đáng tiếc là rất nhiều lập trình viên hiếm khi dùng nó. Trong bài viết này, bạn sẽ được học ý nghĩa từng thành phần trong kết quả trả về của EXPLAIN và cách dùng nó để tối ưu thiết kế cơ sở dữ liệu cũng như câu truy vấn.
Tìm hiểu kết quả trả về của lệnh EXPLAIN
Việc sử dụng EXPLAIN hết sức đơn giản, chỉ cần thêm nó vào trước SELECT trong câu truy vấn. Trước tiên hãy cùng tìm hiểu kết quả trả về của một câu truy vấn đơn giản để bạn có thể làm quen với các cột trong bảng kết quả.
EXPLAIN SELECT * FROM categories\G
********************** 1. row **********************
id: 1
select_type: SIMPLE
table: categories
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra:
1 row in set (0.00 sec)
Có rất nhiều thông tin được bao hàm trong 10 cột trên. Đó là:
-
id- Số thứ tự cho mỗi câuSELECTtrong truy vấn của bạn (trường hợp bạn sử dụng các truy vấn lồng nhau (nested subqueries). -
select_type- Loại của câuSELECT. Có thể có các giá trị sau.SIMPLE- Truy vấn là một câuSELECTcơ bản, không có bất cứ truy vấn con (subqueries) hay câu lệnh hợp (UNION) nào.PRIMARY- Truy vấn là câuSELECTngoài cùng của một lệnhJOIN.DERIVED- Truy vấn là một truy vấn con của truy vấn khác, nằm trong lệnhFROM.SUBQUERY- Truy vấn đầu tiên của một truy vấn con.DEPENDENT SUBQUERY- Truy vấn con, phụ thuộc vào một truy vấn khác bên ngoài nó.UNCACHEABLE SUBQUERY- Truy vấn không thể lưu lại được (có quy định điều kiện cụ thể, thế nào là một truy vấn có thể lưu lại được).UNION- Truy vấn là câuSELECTthứ hai của lệnhUNION.DEPENDENT UNION- Truy vấn thứ hai hoặc các truy vấn tiếp theo của lệnhUNIONphụ thuộc vào một truy vấn bên ngoài.UNION RESULT- Truy vấn là kết quả của lệnhUNION.
-
table- Bảng liên quan đến câu truy vấn. -
type- Cách MySQL join các bảng lại với nhau. Đây là một trong những trường quan trọng nhất của kết quả trả về, nó chỉ ra đâu là nơi thiếu chỉ mục (index) và làm cách nào truy vấn của bạn cần phải xem xét lại. Các giá trị trả về có thể là.system- Bảng không có hoặc chỉ có 1 dòng.const- Bảng chỉ có duy nhất 1 dòng đã được đánh chỉ mục mà khớp với điều kiện tìm kiếm. Đây là loại join nhanh nhất, bởi bảng chỉ cần đọc một lần duy nhất và giá trị của cột được xem như là hằng số khi join với các bảng khác.eq_ref- Tất cả các thành phần của index được sử dụng bởi lệnh join và index thuộc loạiPRIMARY KEYhoặcUNIQUE NOT NULL. Đây là loại join tốt thứ hai (chỉ sauconst).ref- Tất cả các dòng khớp với điều kiện tìm kiếm và chưa cột đã được index đều được đọc cho mỗi sự kết hợp với các dòng của bảng trước đó. Loại join này có thể thấy khi so sánh cột với điều kiện=hoặc<=>.fulltext- join sử dụng chỉ mục dạngFULLTEXT.ref_or_null- Gần giống nhưrefnhưng chứa cả các dòng với cột mang giá trị null.index_merge- join sử dụng một danh sách các chỉ mục để tạo ra tập kết quả. Cộtkeytrong kết quả củaEXPLAINsẽ liệt kê các khóa được sử dụng.unique_subquery- Truy vấn con với lệnhINtrả về duy nhất một kết quả và sử dụngprimary key.index_subquery- Gần giống nhưunique_subquerynhưng trả về nhiều hơn một dòng.range- Chỉ mục được dùng để tìm ra các dòng thỏa mãn điều kiện tìm kiếm, cụ thể là khi khóa được so sánh với hằng số thông qua các toán tửBETWEEN,IN,>,>=,...index- Toàn bộ cây chỉ mục được duyệt để tìm ra dòng thỏa mãn điều kiện.all- Toàn bộ bảng được duyệt để tìm dòng cho join. Đây là loại join tồi tệ nhất và thường cho thấy sự thiếu xót trong việc đánh chỉ mục.
-
possible_keys- Hiển thịkeyscó thể được dùng bởi MySQL để tìm dòng trong bảng, tuy nhiên nó có thể hoặc không thể được dùng. Trong thực tế, cột này đôi khi giúp cho việc tối ưu truy vấn, bởi nếu cột này trống (NULL), nó thường cho thấy không có chỉ mục liên quan được định nghĩa trong bảng. -
key - Khóa thực sự được sử dụng bởi MySQL. Cột này có thể chứa khóa không được liệt kê ở cột
possible_keys. Trình tối ưu của MySQL luôn cố gắng tìm kiếm khóa tối ưu nhất cho truy vấn. Khi kết hợp nhiều bảng, nó có thể dùng khóa không nằm trong danh sáchpossible_keysnhưng lại đem về hiệu quả cao hơn. -
key_len- Chiều dài của khóa mà trình tối ưu truy vấn (Query Optimizer) sử dụng. Ví dụ,key_lenmang giá trị 4 có nghĩa là nó cần bộ nhớ để lưu 4 ký tự. Bạn đọc có thể xem lại Yêu cầu về bộ nhớ cho từng kiểu dữ liệu trong MySQL. -
ref- Tên cột hoặc hằng số được dùng để so sánh với chỉ mục được nêu ra ở cộtkey. MySQL có thể lấy ra một hằng số, hoặc một cột cho quá trình thực hiện truy vấn. Bạn có thể thấy trong ví dự sẽ được liệt kê dưới đây. -
rows- Số lượng bản ghi đã được duyệt để trả về kết quả. Đây cũng là một cột hết sức quan trọng cho việc tối ưu truy vấn, nhất là khi bạn dùngJOINhoặc truy vấn con. -
Extra- Các thông tin bổ sung liên quan đến quá trình thực hiện truy vấn. Các giá trị kiểu nhưUsing Temporary(dùng tạm thời),Using filesort(dùng sắp xếp file),... của cột này có thể cho thấy một truy vấn không thực sự tốt. Danh sách đầy đủ của các giá trị có thể có ở cột này có thể xem tại Tài liệu MySQL
Bạn có thể bổ sung thêm từ khóa EXTENDED sau EXPLAIN và MySQL sẽ đưa ra các thông tin bổ sung về quá trình thực hiện truy vấn. Để xem chi tiết, thực hiện lệnh SHOW WARNINGS ngay sau lệnh EXPLAIN. Nó thường được dùng để xem các câu truy vấn được thực hiện sau bất cứ thay đổi nào được tạo ra bởi Query Optimizer.
EXPLAIN EXTENDED SELECT City.Name FROM City
JOIN Country ON (City.CountryCode = Country.Code)
WHERE City.CountryCode = 'IND' AND Country.Continent = 'Asia'\G
********************** 1. row **********************
id: 1
select_type: SIMPLE
table: Country
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 3
ref: const
rows: 1
filtered: 100.00
Extra:
********************** 2. row **********************
id: 1
select_type: SIMPLE
table: City
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4079
filtered: 100.00
Extra: Using where
2 rows in set, 1 warning (0.00 sec)
SHOW WARNINGS\G
********************** 1. row **********************
Level: Note
Code: 1003
Message: select `World`.`City`.`Name` AS `Name` from `World`.`City` join `World`.`Country` where ((`World`.`City`.`CountryCode` = 'IND'))
1 row in set (0.00 sec)
Khắc phục sự cố về hiệu năng với EXPLAIN
Giờ hãy cùng tìm hiểu làm cách nào chúng ta có thể tối ưu một truy vấn hiệu năng thấp bằng cách phân tích kết quả của EXPLAIN. Trong thực tế, không có gì phải nghi ngờ khi chúng ta sẽ có rất nhiều bảng với rất nhiều quan hệ với nhau, tuy nhiên đôi khi thật khó để biết được cách tốt nhất để viết một truy vấn.
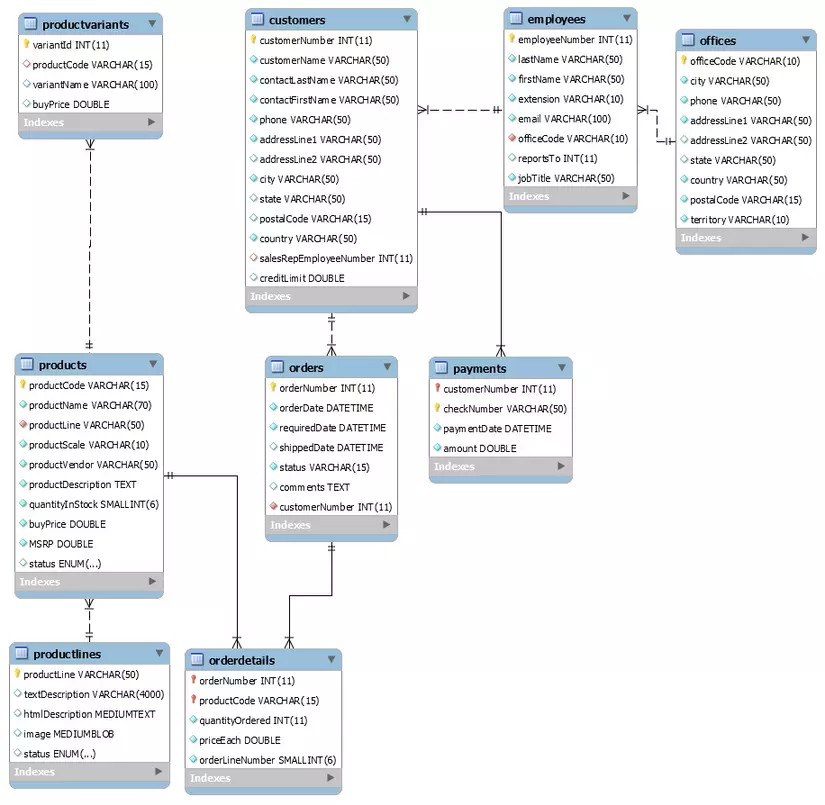
Ở đây, tôi đã tạo ra một cơ sở dữ liệu mẫu cho một ứng dụng thương mại mà ở đó không có chỉ mục, khóa chính và sẽ mô tả ảnh hưởng của thiết kế tồi tệ này bằng cách viết ra các truy vấn phức tạp. Bạn có thể download Mô hình DB từ Github.
Từ người dịch: Để bạn đọc có thể hiểu được mô hình DB dùng trong bài viết này, tôi đã vẽ lại theo mô hình của tác giả và đính kèm ảnh phía dưới. Rất mong có thể giúp ích cho phần tìm hiểu query sau đây.
EXPLAIN SELECT * FROM
orderdetails d
INNER JOIN orders o ON d.orderNumber = o.orderNumber
INNER JOIN products p ON p.productCode = d.productCode
INNER JOIN productlines l ON p.productLine = l.productLine
INNER JOIN customers c on c.customerNumber = o.customerNumber
WHERE o.orderNumber = 10101\G
********************** 1. row **********************
id: 1
select_type: SIMPLE
table: l
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 7
Extra:
********************** 2. row **********************
id: 1
select_type: SIMPLE
table: p
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 110
Extra: Using where; Using join buffer
********************** 3. row **********************
id: 1
select_type: SIMPLE
table: c
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 122
Extra: Using join buffer
********************** 4. row **********************
id: 1
select_type: SIMPLE
table: o
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 326
Extra: Using where; Using join buffer
********************** 5. row **********************
id: 1
select_type: SIMPLE
table: d
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2996
Extra: Using where; Using join buffer
5 rows in set (0.00 sec)
Nhìn vào kết quả trên, bạn thấy được tất cả biểu hiện của một truy vấn tồi tệ. Tuy nhiên, kể cả khi tôi có viết truy vấn tốt hơn, thì kết quả vẫn tương tự, bởi không có chỉ mục. Loại join là ALL (loại tồi nhất), có nghĩa rằng MySQL không thể xác định bất cứ khóa nào để dùng cho join, và do vậy cả possible_keys và key đều trống. Quan trọng hơn, trường rows cho thấy MySQL phải duyệt tất cả các bản ghi của từng bảng cho câu truy vấn này. Có nghĩa, để chạy câu truy vấn, nó cần duyệt 7*110*122*326*2996 = 91,750,822,240 bản ghi để tìm ra kết quả. Điều này thật khủng khiếp và nó sẽ còn tăng thêm khi cơ sở dữ liệu lớn hơn.
Bây giờ, chúng ta thử thêm 1 số chỉ mục khá hiển nhiên, như khóa chính cho từng bảng, và thực hiện truy vấn một lần nữa. Theo thông lệ cơ bản, bạn tìm đến các cột dùng để JOIN và cho chúng làm khóa, bởi MySQL sẽ luôn tìm theo các cột đó để tra cứu các bản ghi.
ALTER TABLE customers
ADD PRIMARY KEY (customerNumber);
ALTER TABLE employees
ADD PRIMARY KEY (employeeNumber);
ALTER TABLE offices
ADD PRIMARY KEY (officeCode);
ALTER TABLE orderdetails
ADD PRIMARY KEY (orderNumber, productCode);
ALTER TABLE orders
ADD PRIMARY KEY (orderNumber),
ADD KEY (customerNumber);
ALTER TABLE payments
ADD PRIMARY KEY (customerNumber, checkNumber);
ALTER TABLE productlines
ADD PRIMARY KEY (productLine);
ALTER TABLE products
ADD PRIMARY KEY (productCode),
ADD KEY (buyPrice),
ADD KEY (productLine);
ALTER TABLE productvariants
ADD PRIMARY KEY (variantId),
ADD KEY (buyPrice),
ADD KEY (productCode);
Giờ chúng ta chạy lại truy vấn sau khi đã thêm chỉ mục.
********************** 1. row **********************
id: 1
select_type: SIMPLE
table: o
type: const
possible_keys: PRIMARY,customerNumber
key: PRIMARY
key_len: 4
ref: const
rows: 1
Extra:
********************** 2. row **********************
id: 1
select_type: SIMPLE
table: c
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: const
rows: 1
Extra:
********************** 3. row **********************
id: 1
select_type: SIMPLE
table: d
type: ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: const
rows: 4
Extra:
********************** 4. row **********************
id: 1
select_type: SIMPLE
table: p
type: eq_ref
possible_keys: PRIMARY,productLine
key: PRIMARY
key_len: 17
ref: classicmodels.d.productCode
rows: 1
Extra:
********************** 5. row **********************
id: 1
select_type: SIMPLE
table: l
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 52
ref: classicmodels.p.productLine
rows: 1
Extra:
5 rows in set (0.00 sec)
Sau khi thêm chỉ mục, số lượng bản ghi cần duyệt giảm xuống còn 1*1*4*1*1 = 4. Điều đó có nghĩa là, với mỗi bản ghi có orderNumber là 10101 trong bảng orderDetails, MySQL có thể tìm trự tiếp bản ghi thỏa mãn trong tất cả các bản ghi khác bằng cách sử dụng chỉ mục và không cần phải duyệt lại cả bảng.
Ở dòng đầu tiên, loại join là const, loại nhanh nhất với bảng có nhiều hơn 1 bản ghi. MySQL có thể sử dụng khóa chính trong trường hợp này. Trường ref trả về kết quả const, có nghĩa là không gì ngoài giá trị 10101 được dùng trong lệnh WHERE.
Tiếp theo hãy xem một truy vấn khác. Ở đây, chúng ta chỉ đơn giản hợp 2 bảng lại, products và productvariants, cả hai đều được join với productline. Bảng productvariants gồm các biến thể của productCode ở dạng khóa ngoài.
EXPLAIN SELECT * FROM (
SELECT p.productName, p.productCode, p.buyPrice, l.productLine, p.status, l.status AS lineStatus FROM
products p
INNER JOIN productlines l ON p.productLine = l.productLine
UNION
SELECT v.variantName AS productName, v.productCode, p.buyPrice, l.productLine, p.status, l.status AS lineStatus FROM productvariants v
INNER JOIN products p ON p.productCode = v.productCode
INNER JOIN productlines l ON p.productLine = l.productLine
) products
WHERE status = 'Active' AND lineStatus = 'Active' AND buyPrice BETWEEN 30 AND 50G
********************** 1. row **********************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 219
Extra: Using where
********************** 2. row **********************
id: 2
select_type: DERIVED
table: p
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 110
Extra:
********************** 3. row **********************
id: 2
select_type: DERIVED
table: l
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 52
ref: classicmodels.p.productLine
rows: 1
Extra:
********************** 4. row **********************
id: 3
select_type: UNION
table: v
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 109
Extra:
********************** 5. row **********************
id: 3
select_type: UNION
table: p
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 17
ref: classicmodels.v.productCode
rows: 1
Extra:
********************** 6. row **********************
id: 3
select_type: UNION
table: l
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 52
ref: classicmodels.p.productLine
rows: 1
Extra:
********************** 7. row **********************
id: NULL
select_type: UNION RESULT
table: <union2,3>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra:
7 rows in set (0.01 sec)
Bạn có thể thấy rất nhiều vấn đề ở câu truy vấn này. Nó duyệt tất cả bản ghi ở bảng products và productvariants. Vì không có chỉ mục nào ở các bảng này cho trường productLine và buyPrice, kết quả trả về cột possible_keys và key đều là trống. Trạng thái của products và productlines được kiểm tra sau khi hợp lại UNION, do vậy việc cho chúng vào trong UNION sẽ giảm số lượng bản ghi. Giờ chúng ta thử thêm vài chỉ mục và viết lại truy vấn.
CREATE INDEX idx_buyPrice ON products(buyPrice);
CREATE INDEX idx_buyPrice ON productvariants(buyPrice);
CREATE INDEX idx_productCode ON productvariants(productCode);
CREATE INDEX idx_productLine ON products(productLine);
EXPLAIN SELECT * FROM (
SELECT p.productName, p.productCode, p.buyPrice, l.productLine, p.status, l.status as lineStatus FROM products p
INNER JOIN productlines AS l ON (p.productLine = l.productLine AND p.status = 'Active' AND l.status = 'Active')
WHERE buyPrice BETWEEN 30 AND 50
UNION
SELECT v.variantName AS productName, v.productCode, p.buyPrice, l.productLine, p.status, l.status FROM productvariants v
INNER JOIN products p ON (p.productCode = v.productCode AND p.status = 'Active')
INNER JOIN productlines l ON (p.productLine = l.productLine AND l.status = 'Active')
WHERE
v.buyPrice BETWEEN 30 AND 50
) productG
********************** 1. row **********************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 12
Extra:
********************** 2. row **********************
id: 2
select_type: DERIVED
table: p
type: range
possible_keys: idx_buyPrice,idx_productLine
key: idx_buyPrice
key_len: 8
ref: NULL
rows: 23
Extra: Using where
********************** 3. row **********************
id: 2
select_type: DERIVED
table: l
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 52
ref: classicmodels.p.productLine
rows: 1
Extra: Using where
********************** 4. row **********************
id: 3
select_type: UNION
table: v
type: range
possible_keys: idx_buyPrice,idx_productCode
key: idx_buyPrice
key_len: 9
ref: NULL
rows: 1
Extra: Using where
********************** 5. row **********************
id: 3
select_type: UNION
table: p
type: eq_ref
possible_keys: PRIMARY,idx_productLine
key: PRIMARY
key_len: 17
ref: classicmodels.v.productCode
rows: 1
Extra: Using where
********************** 6. row **********************
id: 3
select_type: UNION
table: l
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 52
ref: classicmodels.p.productLine
rows: 1
Extra: Using where
********************** 7. row **********************
id: NULL
select_type: UNION RESULT
table: <union2,3>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra:
7 rows in set (0.01 sec)
Như bạn thấy ở kết quả, số lượng dòng được duyệt đả giảm đáng kể, từ 2,625,810 (219 * 110 * 109) xuống còn 276 (12 * 23), thực sự là một hiệu quả rất đáng ghi nhận. Nếu bạn cố gắng chạy cùng truy vấn, mà không sắp xếp lại từ trước, ngay sau khi thêm chỉ mục, bạn sẽ không thể thấy được số lượng giảm đáng kể như vậy. MySQL không thể sử dụng chỉ mục bởi nó dùng WHERE trong kết quả trả về. Sau khi di chuyển điều kiện vào bên trong UNION, MySQL đã có thể dùng chỉ mục. Điều đó có nghĩa là thêm chỉ mục không phải là đủ, MySWL sẽ không thể dùng được chỉ mục đó trừ khi bạn viết câu truy vấn thích hợp.
Kết luận
Trong bài viết này, tôi đã thỏa luận về từ khóa EXPLAIN của MySQL, ý nghĩa của kết quả trả về và cách dùng nó để viết truy vấn tốt hơn. Trong thực tế, nó còn có thể hữu dụng hơn ví dụ được đưa ra ở đây. Thực tế, bạn sẽ thường xuyên join nhiều bảng với câu lệnh WHERE phức tạp. Việc chỉ đơn giản thêm chỉ mục sẽ không phải lúc nào cũng giúp bạn, bạn cần dành thời gian suy nghĩ kỹ càng hơn và viết truy vấn tốt hơn.
Quan điểm cá nhân
Lần đầu tiên tôi biết đến EXPLAIN cũng là khi tôi biết được chương trình của mình thực hiện quá nhiều truy vấn sử dụng filesort (Phần Extra trả về Using filesort). Đây là 1 sắp xếp không có index và rất nguy hiểm khi làm việc với lượng dữ liệu lớn. Việc dùng EXPLAIN giúp tôi phát hiện ra thiếu xót trong thiết kế DB của mình ở thời điểm đó và qua đó biết cách chỉnh sửa thiết kế của mình.
Ngày nay, việc sử dụng các framework hỗ trợ ORM khiến cho các lập trình viên không quan tâm đến quá trình truy vấn dữ liệu trong DB, kéo theo đó là các vấn đề về hiệu năng khi ứng dụng to lên. Ngược lại, việc viết truy vấn bằng tay, dù tốn thời gian nhưng lại đem lại hiệu quả cao về hiệu năng sau này cũng như nâng cao hiểu biết của lập trình viên. Khi tôi còn là thực tập sinh, tôi phải viết tất cả truy vấn bằng tay và theo chỉ định của người hướng dẫn, tôi phải tự EXPLAIN tất cả query trước khi code. Những trải nghiệm đó đã giúp tôi tích lũy được rất nhiều kinh nghiệm cho công việc sau này. Rất mong mọi người cũng có cùng quan điểm và dành thời gian EXPLAIN câu query của mình trước khi bắt tay vào code ứng dụng thực tế.
All rights reserved
