
[Handbook CV with DL - Phần 2] Bài toán phân loại hình ảnh - Image Classification với Tensorflow và Tensorboard
Bài đăng này đã không được cập nhật trong 7 năm
Xin chào các bạn, ngày hôm nay chúng ta sẽ cùng tìm hiểu về bài toán phân loại hình ảnh - image classification là một trong những bài toán thuộc vào loại phổ biến nhất trong lĩnh vực Computer Vision và đây cũng là nội dung đầu tiên mình muốn chia sẻ trên series Handbook Computer Vision with Deep Learning của mình. Rất hi vọng được các bạn đón nhận. OK Chúng ta bắt đầu vào nội dung chính nhé
Mở đầu
Image Classification hay hiểu đơn giản là phân loại hình ảnh là một trong những nhiệm vụ phổ biến trong Computer Vision. Mục tiêu chính của bài toán này đó chính là phân loại một hình ảnh đầu vào (input) thành một nhãn (label) đầu ra (output). Một ví dụ đơn giản chúng ta cần phân biệt bức ảnh đầu vào là con chó hay con mèo chẳng hạn.

Trong bài này chúng ta sẽ đi chi tiết vào các thuật toán phổ biến và sử dụng Tensorflow và Keras để triển khai các model phân loại ảnh. Ngoài ra chúng ta cũng sẽ quan tâm đến các kĩ thuật sử dụng để cải tiến độ chính xác improve accuracy của mô hình. Về cơ bản các nội dung chính sẽ được trình bày trong bài này bao gồm các vấn đề sau:
- Training MINIST bằng Tensorflow
- Training MNIST bằng Keras
- Giới thiệu các dataset thông dụng khác
- Các kiến trúc mạng phổ biến
- Training mô hình phân loại chó mèo
- Những lưu ý khi phát triển một ứng dụng thực tế real-world applications
OK chúng ta sẽ bắt đầu đi sâu vào chi tiết của từng phần nhé
Training MINIST bằng Tensorflow
Trong bài này chúng ta sẽ cùng nhau tìm hiểu về tập dữ liệu Modified National Institute of Standards and Technology - MNIST và xây dựng một mô hình phân loại đơn giản. Mục đích của phần này là trình bày những kiến thức tổng quan về việc xây dựng một mô hình Deep Learning sử dụng Tensorflow. Đầu tiên chúng ta sẽ sử dụng các mô hình đơn giản như Perceptron và Logistic và sau đó chúng ta sẽ tìm hiểu về CNN để tăng độ chính xác. Chúng ta cũng học cách sử dụng Tensorboard để visualize trong quá trình training và để dễ dàng hiểu các paramters của mô hình hơn. Trước tiên chúng ta nên tìm hiểu một chút về tập dữ liệu này đã nhé
Tập dữ liệu chữ viết tay MNIST
MNIST là một tập dữ liệu về chữ số viết tay (từ 0 đến 9) với 60000 ảnh cho việc huấn luyện và 10000 ảnh cho việc kiểm tra mô hình. Đây là một tập dữ liệu phổ biến được sử dụng để thử nghiệm các thuật toán do tính chất khá dễ của nó. Có câu rằng Thuật toán chạy tốt trên MNIST chưa chắc tốt trên dataset khác nhưng không tốt trên MNIST thì đa phần không tốt trên các dataset khác. Chính vì lý do đó nên MNIST được coi là một trong những dataset phổ biến nhất trong bài toán phân loại ảnh. Chúng ta có thể xem một vài ví dụ sau đây:

Giống như chúng ta thấy phía trên, MNIST chứa 10 lớp (labels) tương ứng với 10 chữ số của chúng ta. Mỗi một ảnh đã được chuẩn hoá (normalized) với kích thước 28x28 và chuyển về dạng ảnh xám (gray scale) cũng như đã được căn giữa để cố định vị trí. Đây là một tập dữ liệu rất nhỏ và có thể dễ dàng triển khai các thuật toán trên đó. Trong phần tiếp theo chúng ta sẽ học cách load và sử dụng tập dữ liệu này trong Tensorflow
Load tập dữ liệu MNIST trong Tensorflow
MNIST là một tập dữ liệu phổ biến và được tích hợp sẵn trong Tensorflow giúp chúng ta có thể dễ dàng thử nghiệm các thuật toán. Chúng ta có thể load tập dữ liệu này như sau:
# import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist_data = input_data.read_data_sets('mnist_data', one_hot = True)
Có một lưu ý nhỏ rằng chúng ta có thể định nghĩa kiểu của labels là one-hot hay interger. Đây là hai dạng mã hoá label phổ biến trong Machine Learning. Tại lần chạy đầu tiên các bạn sẽ phải đợi một chút ít thời gian để download dữ liệu về máy local. Trong những lần chạy tiếp theo sẽ nhanh hơn do dữ liệu đã được cached tại local. Trong phần tiếp theo chúng ta sẽ tìm hiểu cách xây dựng một mạng perceptron đơn giản để phân loại các chữ số trong tập MNIST.
Xây dựng mạng Perceptron đơn giản
Một perceptron được coi là một mạng nơ ron chỉ có một lớp ẩn. Chúng ta cũng sẽ tìm hiểu thêm về các khái niệm trong việc thiết kế một mạng nơ ron như fully connected layer các hàm kích hoạt - activation function các hàm tối ưu optimizer như SGD - Strochatis Gradient Descent, lớp softmax, khái niệm logits, one hot encoding và khái niệm về hàm mất mát cross-entropy cũng sẽ được đề cập đến trong những phần tiếp theo. Bây giờ các chúng ta sẽ cùng nhau tìm hiểu cách sử dụng Tensorflow để định nghĩa các thành phần của một mạng nơ ron khi training MNIST.
Xây dựng placeholder cho input_data và labels
Trong Tensorflow một placeholder được sử dụng để truyền dữ liệu vào trong quá trình training. Giá trị của placeholder sẽ không được định nghĩa cụ thể mà sẽ được truyền vào trong quá trình tính toán. Hãy tưởng tượng như khi bạn tiêm thuốc thì người ta sẽ sử dụng một chiếc ống tiêm để tiêm cho bạn, chiếc ống tiêm đó mỗi lần sẽ chứa một loại thuốc khác nhau tuỳ vào hiện trạng bệnh của bạn (tức là dữ liệu đầu vào khác nhau) rồi sau đó nó được sử dụng để tiêm thuốc và trong người bạn (tức là đem dữ liệu đi tính toán). Lúc này chiếc ống tiêm đóng vai trò là placeholder, thuốc trong ống tiêm đóng vai trò là dữ liệu. Quay trở lại với MNIST chúng ta cần định nghĩa các tham số đầu vào của perceptron như kích thước dữ liệu (input_size) số lượng labels, số lượng dữ liệu training trong từng batch (batch_size) và số tổng số lần dữ liệu được lặp qua trong quá trình training. Chúng ta thực hiện nó như sau:
# Building the perceptron
input_size = 784
nb_classes = 10
batch_size = 100
total_batches = 200
x_input = tf.placeholder(tf.float32, shape=[None, input_size])
y_input = tf.placeholder(tf.float32, shape=[None, nb_classes])
trong đó x_input là một placeholder mà chúng ta sẽ truyền dữ liệu vào sau này, y_input là một placeholder chứa các labels tương ứng. Giá trị None trong tham số shape thể hiện rằng thành phần đầu tiên có thể chứa bất kì giá trị nào. Tức là bạn có thể truyền vào cùng lúc một ảnh hoặc nhiều ảnh (trường hợp batch_size > 1). Tham số thứ hai của shape là kích thước của tensor. Dựa trên type của placeholder tf.float32 mà chúng ta có thể truyền dữ liệu vào theo dạng số thực. Phần tiếp theo chúng ta sẽ tiến hành định nghĩa mô hình perceptron.
Định nghĩa các biến (variables) cho lớp fully-connected
Ở phần này chúng ta sẽ định nghĩa một bộ phân lớp tuyến tính - linear classifier hay perceptron bằng cách định nghĩa các biến tương ứng là weights và bias. Trước tiên chúng ta cần hiểu về tư tưởng chung. Giá sử chúng ta sẽ định nghĩa một hàm y = f(x) tính toán giá trị của label y dựa vào thông tin ảnh đầu vào x. Chúng ta có thể viết dưới dạng tuyển tính như sau:
trong đó được gọi là weights và được gọi là bias mà chúng ta đang cần phải tìm. Để làm được điều đó chúng ta cần định nghĩa hai biến trong Tensorflow như sau
# Define the weights and bias
weights = tf.Variable(tf.random_normal([input_size, nb_classes]))
bias = tf.Variable(tf.random_normal([nb_classes]))
Chúng ta có một ảnh đầu vào sẽ có chiều là 1x784 tức là ảnh vuông 28x28 đã được reshape lại. Chúng ta thấy cả weights và bias đều được khởi tạo ban đầu bằng phân phối chuẩn. Về cơ bản chúng ta có thể khởi tạo chúng bằng 0 tuy nhiên việc khởi tạo bằng một phân phối ngẫu nhiên sẽ làm cho việc training mô hình được dễ hội tụ hơn, hay hiểu đơn giản là mượt hơn.
Sau đó chúng ta cần phải tính toán giá trị của logits đầu ra của mạng perceptron giống như công thức phía trên.
# Compute logits
logits = tf.matmul(x_input, weights) + bias
Giá trị này được mạng perceptron dự đoán ra và sẽ được so sánh với one-hot labels là y_input để tính toán hàm loss. Giống như được nhắc đến trong Phần 1 của series này, đối với bài toán phân lớp - classification thường sử hàm softmax kết hợp với cross_entropy để tính toán sự khác biệt giữa logits và one-hot labels.
Trong Tensorflow chúng ta sử dụng hàm tf.nn.softmax_cross_entropy_with_logits API để thực hiện điều đó. Hàm loss sẽ tính toán trung bình - averange của tất cả các cross-entropies. Mục tiêu của việc huấn luyện mô hình đó chính là việc cực tiểu hoá - minimize hàm loss, tức là phải thay đổi các tham số trong mạng để hàm loss của chúng ta thay đổi theo chiều hướng nhỏ dần giá trị. Công việc đó được xử lý bằng tf.train.GradientDescentOptimizer. Hàm tối ưu - optimizer này sẽ có một tham số là learning_rate = 0.5 để giúp điều chỉnh tốc độ học.
# Define softmax cross entropy and optimizer
softmax_cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y_input, logits=logits)
loss = tf.reduce_mean(softmax_cross_entropy)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.5).minimize(loss)
Cả hàm softmax và cross_entropy đều được tính toán trong module tf.nn. Đây là một module rất đắc lực trong Tensorflow. hỗ trợ trong việc xây dựng các mạng nơ ron nhân tạo - neural netwwork - được nhanh chóng hơn. Module tf.train bao gồm các hàm tối ưu phổ biến các bạn có thể tham khảo trực tiếp tại documentation của Tensorflow. Cho đến thời điểm này chúng ta đã khai báo đầy đủ các thành phần của một mạng nơ ron perceptron và chúng ta sẽ sử dụng để tính toán trong các phần tiếp theo.
Tham khảo
Danh sách các optimizer có sẵn trong Tensorflow các bạn có thể tham khảo thêm tại https://www.tensorflow.org/api_docs/python/tf/train trong đó Adam Optimizer được sử dụng một cách phổ biến trong các bài toán Computer Vision. Nhìn chung Adam cho tốc độ hội tụ tốt hơn và không cần khởi tạo giá trị learning rate khi bắt đầu training. Nếu muốn tìm hiểu sâu hơn về các optimizer dựa trên đạo hàm thì có thể tham khảo tại https://arxiv.org/pdf/1609.04747.pdf
Training mô hình với dữ liệu
Chúng ta vừa mới định nghĩa mô hình perceptron và các biến, các placedholder cần trong quá trình training. Trong bước tiếp theo chúng ta bắt đầu huấn luyện mô hình với data. Trong quá trình training, đạo hàm sẽ được tính toán và các weigths sẽ được cập nhật. Các variables cần được khởi tạo và trong Tensorflow chúng ta cần làm việc đó như sau:
# Init variables and session
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
Đoạn code trên sẽ xuất hiện trên tất cả các ví dụ training mô hình với Tensorflow. Hiểu đơn giản thì Tensorflow được xây dựng dựa trên cấu trúc graph-based, có thể ví von một người xây dựng mô hình với tensorflow giống như một người thiết kế đường ống nước cho một toà nhà. đầu tiên chúng ta đặt một nguồn cấp nước gọi là placholder sau đó sẽ thiết kế các đường ống dẫn nối với nhau thành một đồ thị tính toán - computation graph. Sau khi chúng ta đã ghép nối xong các đường ống nước này thì cần phải khơi thông tất cả các van nối tương tự như việc khởi tạo tất cả các biến chúng ta làm bên trên để chuẩn bị cho nước - hay dữ liệu đi qua. Mỗi lần như vậy được gọi là một phiên - session. Thông qua việc sử dụng vòng lặp chúng ta sẽ đọc dữ liệu theo batch và đưa vào trong mô hình. Hàm tối ưu - optimizer sẽ được trong mỗi lần lặp để cập nhật lại trọng số cho mạng.
# Training and update weights
for batch_no in range(total_batches):
# Get mnist batch data
mnist_batch = mnist_data.train.next_batch(batch_size=batch_size)
_, loss_value = sess.run([optimizer, loss], feed_dict={
x_input : mnist_batch[0],
y_input : mnist_batch[1]
})
print(loss_value)
Tham số đầu tiên của hàm run là một list các biến cần tính toán giá trị. Mục đích của việc tính toán và in ra giá trị hàm loss là để xem mô hình của chúng ta có đang được training hay không. Theo như kì vọng thì loss sẽ càng ngày càng giảm. Chúng ta sử dụng từ khoá feed_dict để truyền dữ liệu vào trong mô hình thông qua placeholder. Thử chạy đoạn code trên chúng ta sẽ in ra được giá trị của loss qua mỗi vòng lặp:
Epoch 194 loss 1.3516849279403687
Epoch 195 loss 0.7368113994598389
Epoch 196 loss 0.6730934977531433
Tuy nhiên nó rất khó hình dung xem mô hình đã đủ tốt hay chưa - dù chúng ta biết loss càng nhỏ thì mô hình có khá năng dự đoán càng chính xác. Chính vì thế chúng ta cần một đại lượng khác có khả năng giúp chúng ta hình dung dễ hơn đó chính là accuracy - tức độ chính xác của việc dự đoán. Chúng ta thêm đoạn code định nghĩa giá trị này vào bên dưới phần khai báo loss và optimizer và phía trước phần init = tf.global_variables_initializer()
# Define accuracy
predictions = tf.argmax(logits, 1)
correct_predictions = tf.equal(predictions, tf.argmax(y_input, 1))
accuracy = tf.reduce_mean(tf.cast(correct_predictions, tf.float32))
Hãy thử in giá trị của accuracy bằng cách thay đổi một chút đoạn code trong vòng lặp.
_, loss_value, accuracy_value = sess.run([optimizer, loss, accuracy], feed_dict={
x_input : mnist_batch[0],
y_input : mnist_batch[1]
})
print('Epoch {} loss {} accuracy {}'.format(batch_no, loss_value, accuracy_value))
Và chúng ta thử chạy lại mô hình với 200 bước lặp - epochs đầu tiên:
Epoch 194 loss 1.319211483001709 accuracy 0.7599999904632568
Epoch 195 loss 1.091304063796997 accuracy 0.8399999737739563
Epoch 196 loss 0.977190375328064 accuracy 0.75
Epoch 197 loss 1.3010931015014648 accuracy 0.7900000214576721
Epoch 198 loss 1.174759864807129 accuracy 0.7699999809265137
Epoch 199 loss 1.1929301023483276 accuracy 0.8100000023841858
Chúng ta có thể thấy sau khi chạy khoảng 200 bước lặp thì độ chính xác của chúng ta rơi vào khoảng 85%. Việc training mô hình Perceptron của chúng ta trở nên khá đơn giản với những API trong Tensorflow. Có thể bạn đang thấy kết quả chưa được cao chính vì thế chúng ta cần phải sử dụng các mạng phức tạp hơn là Perceptron, hơn nữa loss và accuracy đang thay đổi khá lớn và không theo quy luật do learning_rate đang để khá cao. Chúng ta có thể tăng số lần lặp trong lúc training với một learning_rate nhỏ hơn để thấy sự khác biệt trong kết quả. Trong phần tiếp theo chúng ta sẽ tìm hiểu về mạng nơ ron tích chập - Convolutional Neural Netwwork - CNN để giúp cải tiến hiệu năng của mô hình phân loại.
Xây dựng mô hình mạng nơ ron tích chập đa lớp
OK chúng ta sẽ cùng nhau tìm hiểu các thức triển khai một mô hình mạng nơ ron tích chập đa lớp hay còn gọi là multilayer convolutional network bằng Tensorflow và cũng từ đó lý giải xem tại sao các mạng nơ ron với nhiều lớp thường đem lại hiệu quả phân loại tốt hơn. Chúng ta sẽ cùng nhau tìm hiểu cách sử dụng Layers API trong Tensorflow để thực hiện xây dựng mô hình từ đầu đến cuối. Trong phần này mình sẽ cố gắng trình bày cho các bạn cách tổ chức code trong một chương trình sử dụng Tensorflow như nào cho chuẩn và dễ dàng maintain sau này. Các khai niệm về import thư viện, sử dụng MNIST datasets cũng như placeholders vẫn giống như các phần đã trình bày ở phần trước. Ngoài việc tổ chức code cho hợp lý và dễ đọc thì trong phần này chúng ta sẽ cùng học cách sử dụng một công cụ GUI rất hữu ích của Tensorflow đó là TensorBoard để hiển thị kết quả cũng như thống kê số liệu trong quá trình training theo đó chúng ta học cách thêm dữ liệu bằng tf.summary để lưu trữ các giá trị của các biến trong quá trình training vào một thư mục mà từ đó có thể tương tác trực tiếp với TensorBoard.
Summary variable
Chúng ta sẽ xây dựng một hàm để thực hiện việc đó như sau:
def add_variable_summary(tf_variable, summary_name):
with tf.name_scope(summary_name + '_summary'):
mean = tf.reduce_mean(tf_variable)
tf.summary.scalar('Mean', mean)
with tf.name_scope('standard_deviation'):
standard_deviation = tf.sqrt(tf.reduce_mean(
tf.square(tf_variable - mean)))
tf.summary.scalar('StandardDeviation', standard_deviation)
tf.summary.scalar('Maximum', tf.reduce_max(tf_variable))
tf.summary.scalar('Minimum', tf.reduce_min(tf_variable))
tf.summary.histogram('Histogram', tf_variable)
Hàm summary được sử dụng để lưu trữ giá trị thay đổi của từng biến trong quá trình huấn luyện thuật toán. Đầu tiên chúng ta sẽ thêm các giá trị mang tính thống kê như giá trị trung bình (mean), độ lệch chuẩn (standard deviation), giá trị lớn nhất, giá trị nhỏ nhất và histogram. Giá trị được lưu trữ trong summary có thể có dạng số thực (scalar) hoặc dạng histogram. Lát nữa khi visualize trên Tensorboard chúng ta sẽ làm rõ hơn hai trường hợp này.
Reshape input data
Do trong phần này chúng ta sẽ sử dụng phương pháp CNN đã được trình bày ở Phần 1 nên chúng ta sẽ có chút thay đổi trong dữ liệu đầu vào của tập MNIST. Chúng ta sẽ chuyển dữ liệu từ dạng vector 1 chiều kích thước sang dạng vector hai chiều kích thước . Chúng ta sử dụng đoạn code sau để chuyển đổi dữ liệu từ 1 chiều sang 2 chiều
x_input_reshape = tf.reshape(x_input, [-1, 28, 28, 1],
name='input_reshape')
Chúng ta có thể để ý thấy chiều -1 tượng trưng cho việc chúng ta có thể truyền bất kì một số lượng ảnh nào trong quá trình training (tương ứng với một batch size). Việc đặt thêm tham số name vào trong mỗi biến nhằm mục đích dễ hiểu khi visualize bằng Tensorboard.
Định nghĩa lớp tích chập
Tiếp theo chúng ta sẽ định nghĩa lớp quan trọng nhất của chúng ta đó chính là lớp tích chập hay còn gọi là convolution layer. Do dữ liệu của chúng ta là 2 chiều nên lớp tích chập cũng sẽ là một 2D convolution layer. Một lớp tích chập sẽ bao gồm các tham số như input đầu vào, kích thước của kernel, giá trị của filters và loại hàm kích hoạt (activations). Chúng ta có thể định nghĩa nó như sau:
def convolution_layer(input_layer, filters, kernel_size=[3, 3],
activation=tf.nn.relu):
layer = tf.layers.conv2d(
inputs=input_layer,
filters=filters,
kernel_size=kernel_size,
activation=activation
)
add_variable_summary(layer, 'convolution')
return layer
Chúng ta sẽ có các tham số mặc định như kernel_szie và activation các tham số còn lại như input_layer sẽ được truyền trong quá trình xây dựng mạng của chúng ta và tuỳ thuộc vào vị trí của lớp tích chập trong mạng nữa. Việc định nghĩa như vậy giúp code của chúng ta trở nên đơn giản hơn rất nhiều và việc tổ chức code của chúng ta cũng trở nên khoa học và dễ dàng maintain hơn.
Định nghĩa lớp pooling
Tương tự như thế chúng ta sẽ định nghĩa tiếp layer pooling như sau:
def pooling_layer(input_layer, pool_size=[2, 2], strides=2):
layer = tf.layers.max_pooling2d(
inputs=input_layer,
pool_size=pool_size,
strides=strides
)
add_variable_summary(layer, 'pooling')
return layer
Chúng ta định nghĩa hai tham số của hàm này đó là pool_size = [2, 2] và strides = 2. Hai tham số này về cơ bản có thể hoạt động tốt trong đa số trường hợp nhưng chúng ta có thể thay đổi chúng nếu cần thiết.
Định nghĩa lớp fully connected
Tiếp theo chúng ta sẽ định nghĩa một layer là fully_connected layer hay dense layer
def dense_layer(input_layer, units, activation=tf.nn.relu):
layer = tf.layers.dense(
inputs=input_layer,
units=units,
activation=activation
)
add_variable_summary(layer, 'dense')
return layer
Layerr pooling được sử dụng phía sau layer tích chập để giảm thiểu số lượng tham số của layer tích chập sử dụng pool size và strides. Như trong trường hợp của chúng ta số lượng tham số sẽ giảm đi một nửa nếu sử dụng bộ tham số mặc định pool_size = [2, 2] và strides = 2. Chúng ta cần phải định nghĩa graph của Tensorflow bằng cách kết nối các layer này với nhau để trở thành một mạng neural hoàn chỉnh. Về cơ bản chúng ta có thể sử dụng các lớp tích chập liên tiếp nhau để tăng hiệu quả của việc trích chọn đặc trưng từ ảnh. Sau khi pooling chúng ta có thể thực hiện biển đổi thông qua hàm activation và cuối cùng của mạng là lớp fully connected layer. Trước khi đưa vào lớp fully connected chúng ta có thể sử dụng kĩ thuật flatten dữ liệu từ 2 chiều trở thành 1 chiều để việc tính toán được dễ dàng hơn.
Xây dựng mạng CNN
Chúng ta định nghĩa một mạng đơn giản gồm 2 layer tích chập, 2 layer pooling và 1 layer dense như sau:
convolution_layer_1 = convolution_layer(x_input_reshape, 64)
pooling_layer_1 = pooling_layer(convolution_layer_1)
convolution_layer_2 = convolution_layer(pooling_layer_1, 128)
pooling_layer_2 = pooling_layer(convolution_layer_2)
flattened_pool = tf.reshape(pooling_layer_2, [-1, 5 * 5 * 128],
name='flattened_pool')
dense_layer_bottleneck = dense_layer(flattened_pool, 1024)
Chúng ta có thể thấy sự khác nhau duy nhất giữa các lớp tích chập (convolution) đó chính là kích thước của filter. Đây là một tham số quan trọng để quyết định đến kích thước đầu ra của một lớp tích chập. Lựa chọn kích thước của kernel và stride thường dựa trên kinh nghiệm của người xây dựng mạng. Như trong mạng vừa rồi chúng ta đã định nghĩa 2 layer tích chập và theo sau đó là các layer pooling và 1 layer fully connected. Layer dense có thể nhận đầu vào là bất kì một vector một chiều nào và ánh xạ tương ứng với bất kì số hidden units nào (trong mạng trên là 1024). Hàm kích hoạt được sử dụng trong mạng trên là hàm ReLU đã được thảo luận tại Phần 1 của series này.
Định nghĩa dropout layer
Một trong những phương pháp để giảm độ phức tạp của mạng và để tránh hiện tượng overfiting là sử dụng dropout. Chúng ta sẽ xây dựng layer này và add nó vào sau layer fully connected.
dropout_bool = tf.placeholder(tf.bool)
dropout_layer = tf.layers.dropout(
inputs=dense_layer_bottleneck,
rate=0.4,
training=dropout_bool
)
Trong layer này có một tham số rate tương ứng với tỉ lệ loại bỏ các trọng số trong layer và một tham số training gồm hai giá trị True và False để quyết định việc sử dụng layer này trong lúc training hay khi predict (dropout chỉ sử dụng trong quá trình training thôi nhé).
Tính toán logits vector
Sau khi xây dựng layer dropout chúng ta sẽ lấy kết quả đầu ra của layer dropout và đưa vào một lớp dense để tạo vector đầu ra với chiều dài là no_classes = 10 tương ứng với số lượng class của tập MNIST.
logits = dense_layer(dropout_layer, no_classes)
logits vector cũng tương tự như đầu ra của mô hình chúng ta đã xây dựng ở các phần trước. Bây giờ chúng ta sẽ đưa kết quả của logits qua hàm softmax và tính toán hàm loss dựa vào cross-entropy như các phần trước đó. Để hiển thị tốt trên Tensorboard chúng ta có thể add vào trong scope và sử dụng summary.
Tính toán hàm loss
with tf.name_scope('loss'):
softmax_cross_entropy = tf.nn.softmax_cross_entropy_with_logits(
labels=y_input, logits=logits)
loss_operation = tf.reduce_mean(softmax_cross_entropy, name='loss')
tf.summary.scalar('loss', loss_operation)
Định nghĩa phương pháp tối ưu
Hàm loss của chúng ta có thể sử dụng API tf.train để tối ưu. Một hàm tối ưu chúng ta thương fhay sử dụng đó là Adamoptimiser bởi nó đem lại hiệu quả tốt trong đa số các bài toán và không bị phụ thuộc vào giá trị khởi tạo của learning rate.
with tf.name_scope('optimiser'):
optimiser = tf.train.AdamOptimizer().minimize(loss_operation)
Tính toán accuracy
Tiếp theo để thể hiện được độ chính xác của mô hình chúng ta có thể sử dụng phương pháp đo là accuracy. Chúng ta có thể định nghĩa chúng như sau:
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
predictions = tf.argmax(logits, 1)
correct_predictions = tf.equal(predictions, tf.argmax(y_input, 1))
with tf.name_scope('accuracy'):
accuracy_operation = tf.reduce_mean(
tf.cast(correct_predictions, tf.float32))
tf.summary.scalar('accuracy', accuracy_operation)
Khởi tạo session và lưu summary variable
Tương tự như các phần trước chúng ta cần khởi tạo sessions cho mô hình đã được khai báo để tiến hành training thuật toán.
session = tf.Session()
session.run(tf.global_variables_initializer())
Tiếp theo chúng ta cần phải lưu trữ giá trị của các biến trong quá trình training vào một thư mục để tiện sử dụng với Tensorboard sau này. Thực hiện điều đó với câu lệnh rất đơn gián như sau :
merged_summary_operation = tf.summary.merge_all()
train_summary_writer = tf.summary.FileWriter('logs/train', session.graph)
test_summary_writer = tf.summary.FileWriter('logs/test')
Chúng ta có thể thấy rằng các giá trị trong graph được lưu lại sau mỗi lần gọi summary_writer . Tiếp sau đây chúng ta sẽ tiến hành training mô hình
Training mô hình
Chúng ta tiến hành load dữ liệu theo batch và training mô hình trên đó:
test_images, test_labels = mnist_data.test.images, mnist_data.test.labels
for batch_no in range(total_batches):
mnist_batch = mnist_data.train.next_batch(batch_size)
train_images, train_labels = mnist_batch[0], mnist_batch[1]
_, merged_summary = session.run([optimiser, merged_summary_operation],
feed_dict={
x_input: train_images,
y_input: train_labels,
dropout_bool: True
})
train_summary_writer.add_summary(merged_summary, batch_no)
if batch_no % 10 == 0:
merged_summary, _ = session.run([merged_summary_operation,
accuracy_operation], feed_dict={
x_input: test_images,
y_input: test_labels,
dropout_bool: False
})
test_summary_writer.add_summary(merged_summary, batch_no)
Summaries sẽ được tổng hợp lại thông qua từng lần lặp trong quá trình training. Còn sau 10 vòng lặp chúng ta sẽ tính toán loss trên tập test và lưu lại. Chú ý rằng dropout chỉ được sử dụng trong quá trình training mà không được sử dụng trong quá trinh testing. Để theo dõi quá trình này chúng ta khởi động Tensorboard lên
Sử dụng Tensorboard
Như đã đề cập chúng ta sẽ sử dụng Tensorboard để theo dõi quá tình training mô hình. Trước tiên là khởi động nó
tensorboard --logdir=./logs
Sau đó chúng ta có thể vào link Tensorboard trên trình duyệt http://localhost:6006/. Và trên trình duyệt sẽ hiển thị thông tin như sau
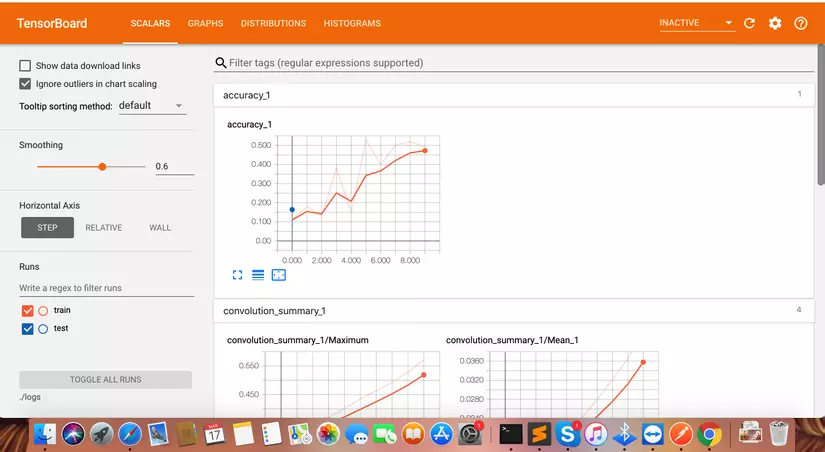
Chúng ta có thể theo dõi các gía trị của accuracy trong quá trình training, gía trị của loss function trong quá trình training. Đây là một công cụ rất hữu ích giúp bạn trong quá trình training thuật toán và đặc biệt hữu dụng khi cần phải vẽ các biểu đồ phục vụ nghiên cứu khoa học.
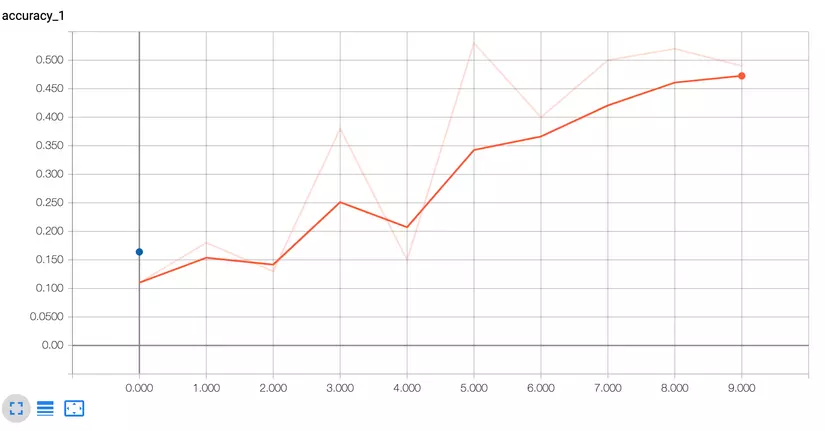
Tổng kết
Chúng ta đã cùng nhau tìm hiểu về bài toán phân loại hình ảnh trong Computer Vision và cách thực hiện nó với Framework Tensorflow. Chúng ta thực hiện ví dụ trên tập MNIST và với hai mô hình là MLP và CNN. Các bạn hãy chịu khó training và so sánh kết quả nhé. Trong phần tiếp theo chúng ta sẽ cùng nhau tìm hiểu bài toán phân loại hình ảnh trên tập dữ liệu khác và với các phương pháp, mô hình CNN khác cũng như một Framework dễ chịu hơn Tensorflow rất nhiều đó là Keras. Hẹn gặp lại các bạn trong phần tiếp theo của series này nhé.
All rights reserved
