Git deep dive: xây dựng git clone bằng Javascript
Bài đăng này đã không được cập nhật trong 2 năm
Nội dung:
- Tổng quan git:
- Tóm tắt git internals
- Git blob storage
- Git tree, commit
- Git clone:
- Git smart protocol
- Git pack file
- Git delta compression
- Clone
Tổng quan mô hình hoạt động của git:
Mô hình hoạt động
Git hoạt động dựa trên ba loại objects chính là blob, tree, và commit:

Khi bạn git add thì git sẽ write tất cả các file thành git blob, tạo một git tree object của các file trong folder. Các file sẽ có một working copy là git blob và một file index đặc biệt cho git pack sau đó.
Khi bạn commit lần đầu, git sẽ tạo file HEAD chứa path của branch master. HEAD là pointer cho branch, branch là pointer cho commit mới nhất ở từng branch .
Trong git folder file master chứa SHA hash của commit đầu tiên. Commit này sẽ có tree là tree bạn tạo khi git add.

Từ đó các branch mới sẽ theo cấu trúc một DAG (Directed Acyclic Graph).
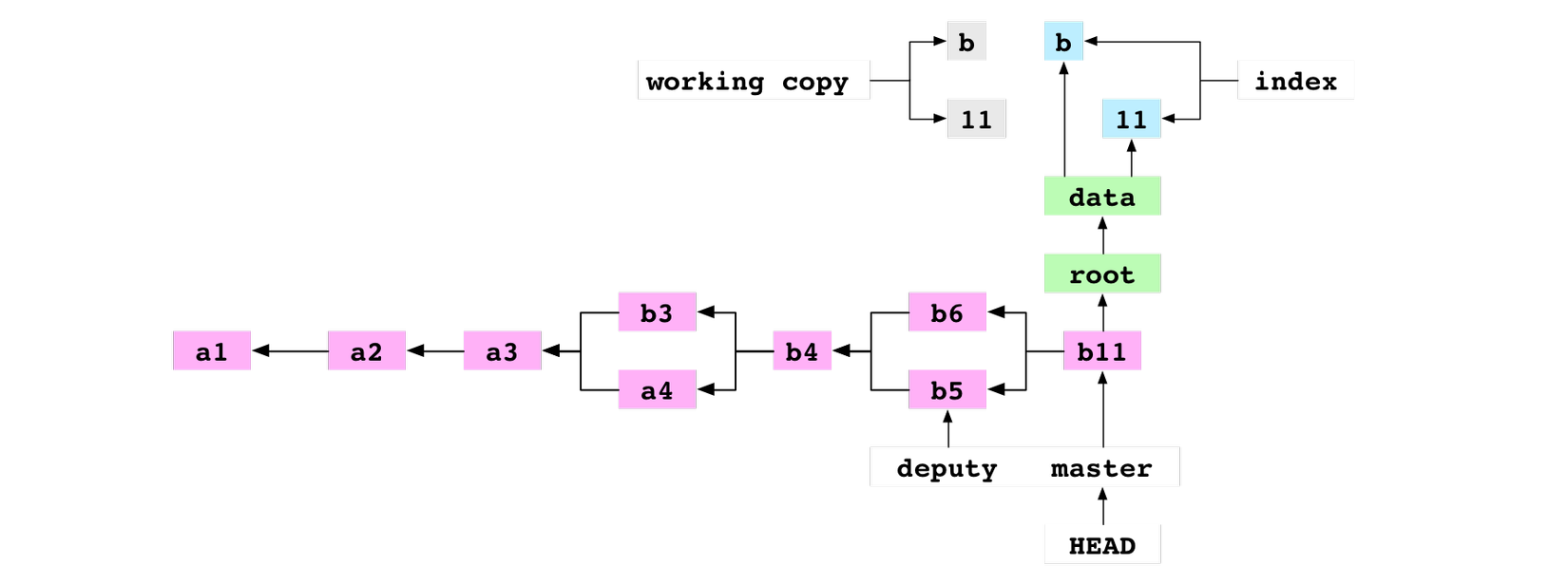
Khi merge branch có cùng parent thì git sẽ so sánh và yêu cầu sửa conflict trước khi merge.
Blob
Mỗi file trong git folder được chứa là git blob, có cấu trúc sau:
blob <size>\0<content>
Bạn có thể dùng cat file để có thể thấy nội dung của git blob:
git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
File git blob bắt đầu với từ khoá blob, độ dài của của content trong bytes, một null byte, và cuối cùng là content được nén dùng zlib.
Blob được chứa trong folder .git/objects
Toàn bộ nội dung từ blob đến content (chưa được nén) sẽ được dùng để tạo một hash SHA-1 20 bytes được viết thành 40 ký tự hexadecimal.
Hai ký tự đầu được dùng làm folder và các ký tự còn lại làm tên file.
Git chọn mô hình này vì cần so sánh nhanh sự khác biệt giữa các git objects.A
Code để viết và đọc một git blob object:
ReadBlob:
const path = require("path");
const fs = require("fs");
const zlib = require("node:zlib");
function readGitBlob(sha, basePath = "") {
const blobPath = path.resolve(basePath, ".git", "objects", sha.slice(0, 2), sha.slice(2));
const data = fs.readFileSync(blobPath);
const dataUncompressed = zlib.unzipSync(data);
const nullByteIndex = dataUncompressed.indexOf("\0");
const blobData = dataUncompressed.toString().slice(nullByteIndex + 1);
if (dataUncompressed) {
process.stdout.write(blobData);
return blobData;
} else {
throw new Error("Can't decompress git blob");
}
}
module.exports = readGitBlob;
WriteBlob:
const fs = require("fs");
const path = require("path");
const zlib = require("zlib");
const { sha1 } = require("./utils");
function writeBlob(write, fileName) {
const filePath = path.resolve(fileName);
let data = fs
.readFileSync(filePath)
.toString()
.replace(/(\r\n|\n|\r)/gm, "");
data = `blob ${data.length}\0` + data;
const hash = sha1(data);
if (write) {
const header = hash.slice(0, 2);
const blobName = hash.slice(2);
const blobFolder = path.resolve(".git", "objects", header);
const blobPath = path.resolve(blobFolder, blobName);
if (!fs.existsSync(blobFolder)) {
fs.mkdirSync(blobFolder);
}
let dataCompressed = zlib.deflateSync(data);
fs.writeFileSync(blobPath, dataCompressed);
}
return hash;
}
module.exports = writeBlob;
Tree
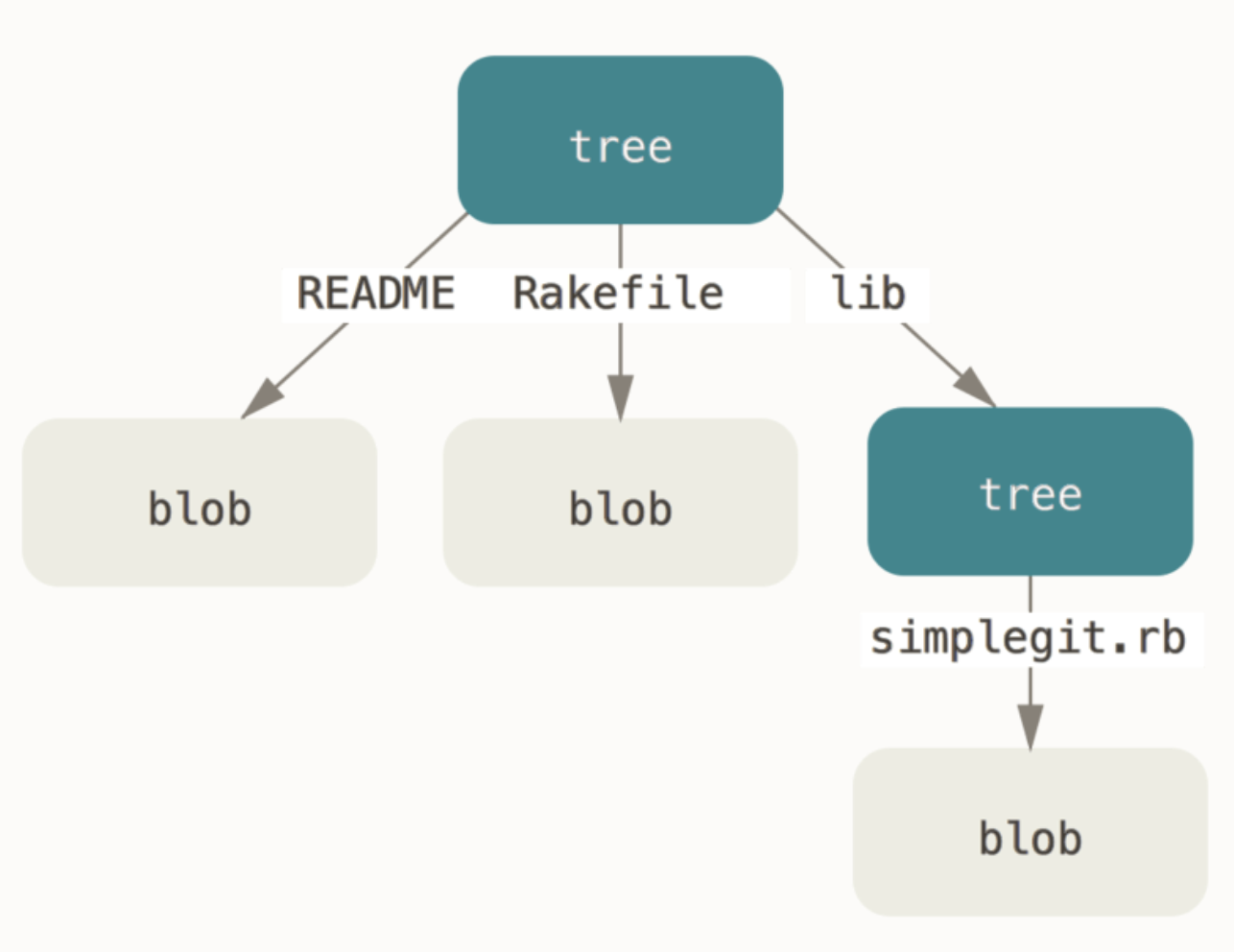
Tree được dùng để mã hoá thông tin cấu trúc thư mục.
tree <size>\0
<mode> <name>\0<20_byte_SHA>
<mode> <name>\0<20_byte_SHA>
...
Bạn có thể dùng git cat-file để coi nôi dung của tree object và write-tree để write folder hiện tại:
git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Như blob tree bắt đầu với từ khoá tree, độ dài nội dung trong bytes, null byte.
Mỗi dòng tiếp theo đại diện cho một object trong folder.
Mỗi mode đại diện cho một loại tập tin hoặc thư mục khác nhau dựa theo Unix file permission code (eg: 040000 - dir, 100644 - file with read write, 100755 - file exec).
Tên object trong thư mục, một null byte, và 20 bytes SHA của object trong .git/objects
ReadTree:
const path = require("path");
const fs = require("fs");
const zlib = require("zlib");
const dirName = hash.slice(0, 2);
const fileName = hash.slice(2);
const objectPath = path.join(".git", "objects", dirName, fileName);
function readTree(hash) {
if (!fs.existsSync(objectPath)) {
throw new Error("Object path does not exist");
}
const dataFromFile = fs.readFileSync(objectPath);
const decompressedData = zlib.inflateSync(dataFromFile);
let dataStr = decompressedData.toString("binary");
let nullByteIndex = dataStr.indexOf("\0");
dataStr = dataStr.slice(nullByteIndex + 1);
const entries = [];
while (dataStr.length > 0) {
const spaceIndex = dataStr.indexOf(" ");
if (spaceIndex === -1) break; // Invalid format
const mode = dataStr.slice(0, spaceIndex);
dataStr = dataStr.slice(spaceIndex + 1);
const nullIndex = dataStr.indexOf("\0");
if (nullIndex === -1) break; // Invalid format
const name = dataStr.slice(0, nullIndex);
if (!name) continue; // skip empty names
dataStr = dataStr.slice(nullIndex + 1); // Move past the null byte
const sha = dataStr.slice(0, 20);
dataStr = dataStr.slice(20);
entries.push(name);
}
const response = entries.join("\n"); // Removed the trailing newline for better handling
if (response) {
process.stdout.write(response + "\n"); // Append newline here
} else {
throw new Error("No valid entries found");
}
}
module.exports = readTree;
WriteTree:
const fs = require("fs");
const path = require("path");
const { readGitObject } = require("./utils");
function createTree(hash, gitDir, basePath = "") {
const { type, length, content } = readGitObject(hash, gitDir);
if (type !== "tree") {
throw new Error("Not a tree");
}
let entries = parseTreeEntries(content);
for (let entry of entries) {
if (entry.mode === "100644") {
const blob = readGitObject(entry.hash, gitDir);
fs.writeFileSync(path.join(basePath, entry.name), blob.content);
} else if (entry.mode === "40000") {
let folder = path.join(basePath, entry.name);
fs.mkdirSync(folder);
createTree(entry.hash, gitDir, folder);
}
}
}
function parseTreeEntries(data) {
const result = [];
let startIndex = 0;
while (startIndex < data.length) {
const modeEndIndex = data.indexOf(" ", startIndex);
if (modeEndIndex === -1) break; // Exit loop if delimiter not found
const mode = data.slice(startIndex, modeEndIndex).toString();
const fileNameStartIndex = modeEndIndex + 1;
const nullByteIndex = data.indexOf("\0", fileNameStartIndex);
if (nullByteIndex === -1) break; // Exit loop if delimiter not found
const name = data.slice(fileNameStartIndex, nullByteIndex).toString();
const hashStartIndex = nullByteIndex + 1;
const hashEndIndex = hashStartIndex + 20;
const hash = data.slice(hashStartIndex, hashEndIndex).toString("hex");
result.push({ mode, name, hash });
startIndex = hashEndIndex;
}
return result;
}
module.exports = createTree;
Commit:
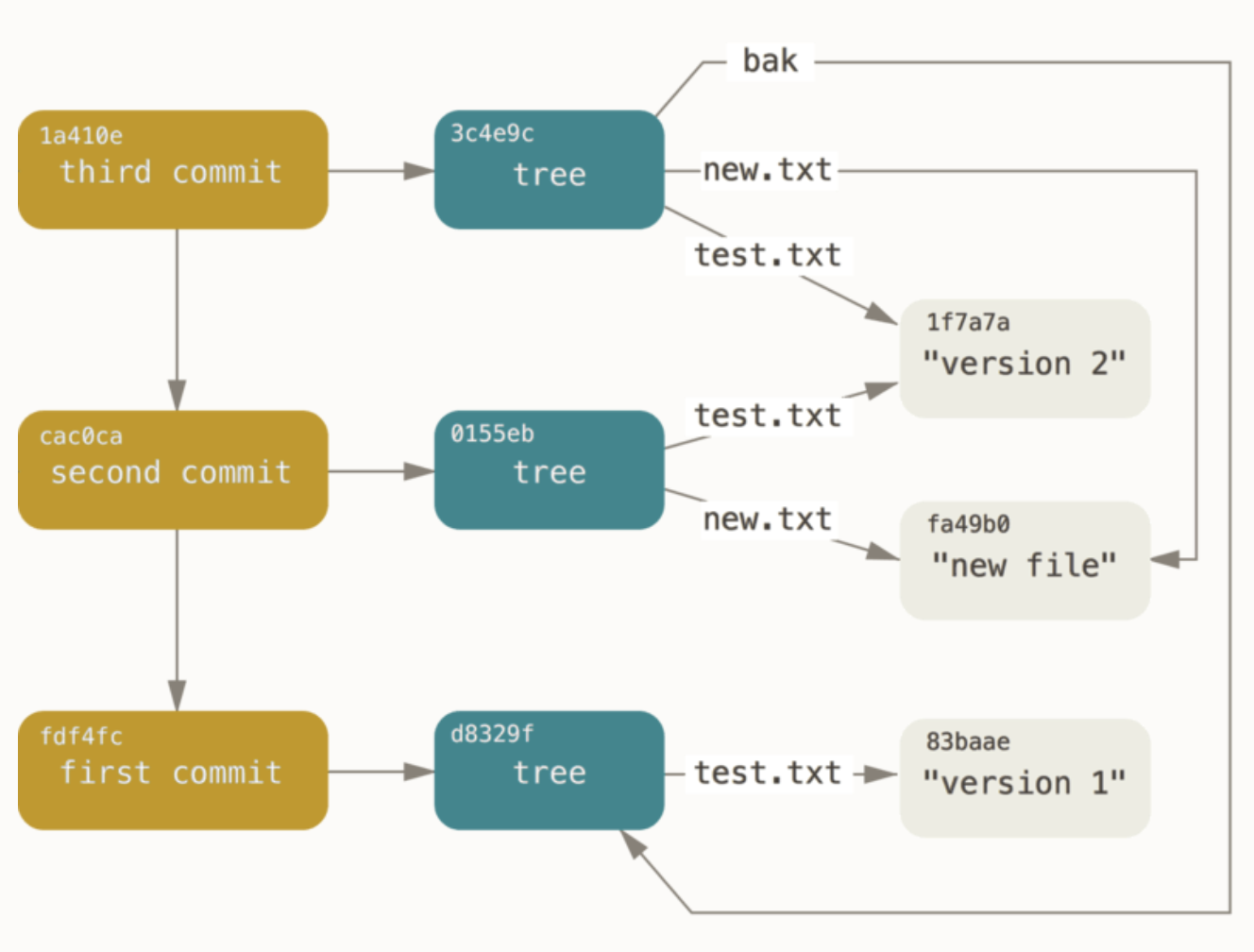
commit <length>/0
tree \0<20_byte_SHA>
parent? \0<20_byte_SHA>
author <name> <email> <seconds_since_1970> <time_zone>
committer <name> <email> <seconds_since_1970> <time_zone>
<commit message>
Ví dụ: Trong git log b có thể thấy commit như sau:
commit 160\0tree 4b825dc642cb6eb9a060e54bf8d69288fbee4904
parent e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
author John Doe <john.doe@example.com> 1627884000 +0200
committer John Doe <john.doe@example.com> 1627884000 +0200
Initial commit
Mỗi commit chỉ tới một tree và có thể có hoặc không có parent. Commit không có parent là commit đầu tiên.
WriteCommit:
const fs = require("fs");
const crypto = require("crypto");
const zlib = require("zlib");
const path = require("path");
function getFormattedUtcOffset() {
const date = new Date();
const offsetMinutes = -date.getTimezoneOffset();
const offsetHours = Math.abs(Math.floor(offsetMinutes / 60));
const offsetMinutesRemainder = Math.abs(offsetMinutes) % 60;
const sign = offsetMinutes < 0 ? "-" : "+";
const formattedOffset = `${sign}${offsetHours
.toString()
.padStart(2, "0")}${offsetMinutesRemainder.toString().padStart(2, "0")}`;
return formattedOffset;
}
function commitObject(tree_hash, commit_hash, message) {
let contents = Buffer.from("tree " + tree_hash + "\n");
if (commit_hash) {
contents = Buffer.concat([contents, Buffer.from("parent " + commit_hash + "\n")]);
}
let seconds = new Date().getTime() / 1000;
const utcOffset = getFormattedUtcOffset();
contents = Buffer.concat([
contents,
Buffer.from("author " + "John Doe" + "<JohnDoe@mail.com> " + seconds + " " + utcOffset + "\n"),
Buffer.from("committer " + "John Doe" + "<JohnDoe@mail.com> " + seconds + " " + utcOffset + "\n"),
Buffer.from("\n"),
Buffer.from(message + "\n"),
]);
let finalContent = Buffer.concat([Buffer.from("commit " + contents.length + "\0"), contents]);
let new_object_path = crypto.createHash("sha1").update(finalContent).digest("hex");
fs.mkdirSync(path.join(".git", "objects", new_object_path.slice(0, 2)), {
recursive: true,
});
fs.writeFileSync(
path.join(".git", "objects", new_object_path.slice(0, 2), new_object_path.slice(2)),
zlib.deflateSync(finalContent),
);
process.stdout.write(new_object_path);
return;
}
module.exports = commitObject;
Git clone:
Git Smart Protocol
Khi dùng fetch, push, hay clone thì client và server git sẽ giao kết qua giao thức gitprotocol-pack với hai loại là smart hoặc dumb. Server của github dùng smart protocol.
Giao thức này xác định dữ liệu mà server có mà client chưa có để trích xuất từ server.
Format URL:
http://<host>:<port>/<path>?<searchpart>
Trước tiên, client phải gọi lệnh khám phá các ref đang tồn tại trên server:
GET $GIT_URL/info/refs?service=git-upload-pack
Git smart server sẽ reply như sau:
S: 200 OK
S: Content-Type: application/x-git-upload-pack-advertisement
S: Cache-Control: no-cache
S:
S: 001e# service=git-upload-pack\n
S: 0000
S: 004895dcfa3633004da0049d3d0fa03f80589cbcaf31 refs/heads/maint\0multi_ack\n
S: 003fd049f6c27a2244e12041955e262a404c7faba355 refs/heads/integration
S: 003ff4j332i23o4009f0sd9f9s0df9qjfq0q7fj8ư892 refs/heads/master
S: 003c2cb58b79488a98d2721cea644875a8dd0026b115 refs/tags/v1.0\n
S: 003fa3c2e2402b99163d1d59756e5f207ae21cccba4c refs/tags/v1.0^{}\n
S: 0000
Ở trên là các refs hiện có trong server.
Để clone thì thông thường ta sẽ chọn refs/heads/master hoặc main. Sử dụng code dưới ta sẽ truy xuất được ref và hash của master hoặc main repo cần clone từ server.
Tiếp tục client và server sẽ đến bước negotiate dữ liệu cần. Bước đầu client sẽ gửi đến server các dữ liệu muốn trích xuất với nhiều options về commit depths hoặc filter...
Sau đó client kết thúc want bằng '0000' là chỉ dấu kết thúc pkt-line. Sau đó client cũng có thể gửi thêm một list các lệnh have và chờ server gửi ACK để server biết client đã có file nào để server có thể skip những file đó. Cuối cùng server sẽ gửi ACK nếu có have hoặc NAK nếu chỉ có want và pack file đi kèm.
Ví dụ:
Client:
C: 0032want <20_byte_SHA> <options> \n
C: 0032want <20_byte_SHA> <options> \n
C: 0000
C: 0032have <20_byte_SHA> <options> \n
C: 0032have <20_byte_SHA> <options> \n
C: 0000
C: 0009done\n
Server:
S: 0007ACK\n
S: [PACKFILE]
Để clone thì ta chỉ cần gửi:
0032want <master_SHA> \n
0009done\n
Code:
const axios = require('axios')
async function getPackFile(url) {
const { packHash, ref } = await getPackFileHash(url);
const packRes = await getPackFileFromServer(url, packHash);
return { data: packRes.data, head: { ref, hash: packHash } };
}
async function getPackFileHash(url) {
const gitPackUrl = "/info/refs?service=git-upload-pack";
const response = await axios.get(url + gitPackUrl);
const data = response.data;
let hash = "";
let ref = "";
for (const line of data.split("\n")) {
if (line.includes("refs/heads/master") || line.includes("refs/heads/main")) {
const head = line.split(" ");
hash = head[0].substring(4);
ref = head[1].trim();
break;
}
}
return { packHash: hash, ref };
}
async function getPackFileFromServer(url, hash) {
const gitPackPostUrl = "/git-upload-pack";
const hashToSend = Buffer.from(`0032want ${hash}\n00000009done\n`, "utf8");
const headers = {
"Content-Type": "application/x-git-upload-pack-request",
"accept-encoding": "gzip,deflate",
};
const response = await axios.post(url + gitPackPostUrl, hashToSend, {
headers,
responseType: "arraybuffer", // Keep everything as buffer
});
return response;
}
Git pack file
Sau khi giao kết với server thì toàn bộ nội dung sẽ được gói trong định dạng pack file.
Pack file dùng định dạng byte. Gồm 2 phần là header và entries
Header:
<4_byte_PACK> <4_byte_version_number> <4_byte_entry_length>
Entry:
<type_bits + size_bits> <compressed_data>
Có 6 type với mỗi type được đại diện bởi một số gồm:
- Commit
- Tree
- Blob
- Tag
- OFS_Delta
- REF_Delta
Để có thể đọc pack file, đầu tiên ta tìm PACK signature trong response để tìm điểm khởi đầu của pack file và tách header khỏi nội dung:
async function getRawGitObjects(url) {
const { data, head } = await getPackFile(url);
const packFile = data;
const packIndex = packFile.indexOf("PACK"); // Find the position of "PACK"
if (packIndex === -1) {
throw new Error('Invalid pack file: "PACK" header not found.');
}
const entries = packFile.slice(packIndex + 8);
const packObjectCount = Buffer.from(packFile.slice(packIndex + 4, packIndex + 8)).readUInt32BE(0);
...
Size được đại diên bởi một số little-edian variable-length vì size của mỗi object là variable.
Ví dụ nếu size của entry là bytes thì trong nhị nguyên sẽ là:
decimal 21759
binary 101010011111111
Sau đó ta sẽ chia thành một nhóm đầu 4 bits và các nhóm còn lại 7bit hoặc ít hơn từ phải qua trái:
decimal 21759
binary 1010 1001111 1111
sau đó đảo thứ tự little-endian:
binary 1010 1001111 1111
little-endian 1111 1001111 1010
cuối cùng pad mỗi nhóm thành 8 bit với bit 1 đầu là tiếp tục và bit 0 đầu với nhóm cuối:
little-endian 1111 1001111 1010
padded 10001111 10001111 00001010
cuối cùng, ta dùng chỗ luôn trống ở nhóm 4 bit ở đầu để chứa type (1-7 hay 111).
Ví dụ nếu entry của ta có type 1 thì sẽ thành:
padded 10001111 10001111 00001010
type-1 10011111 10001111 00001010
hex 9F CF A
Khi đọc entry trong pack file, ta phải process byte đầu tiên. 4 bits đầu sẽ chứa type và 4 bit còn lại đến khi bắt gặp một byte có bit đầu tiên là 0 sẽ là size trong trật tự little-endian.
Đây là code để đọc header mỗi entry:
function parsePackObjectHeader(buffer, i) {
let cur = i;
const type = (buffer[cur] & 112) >> 4; // 01110000
let size = buffer[cur] & 15; // 00001111
let offset = 4;
while (buffer[cur] >= 128) {
cur++;
size += (buffer[cur] & 127) << offset;
offset += 7;
}
return [cur - i + 1, type, size];
}
Đầu tiên ta tìm 4 bit đầu bằng bitwise byte đầu tiên với 112 (01110000), filter bit đầu tiên:
let cur = i;
const type = (buffer[cur] & 112) >> 4; // 01110000
10011111
& 01110000
-----------
00010000
Sau đó shift 4 bit để đổi ra decimal:
00010000 >> 4 = 0000001
Sau đó ta bitwise để lấy 4 bit cuối là size:
let size = buffer[cur] & 15; // 00001111
10011111
& 00001111
-----------
00001111
Ta tiếp túc xử lý các byte tiếp theo, dừng ở byte có bit đầu là 0 (< 10000000).
Ở mỗi byte ta bitwise lấy 7 bit bằng bitwise với 01111111 (127) và shift theo hệ số mũ của nó theo số các bit đã xử lý (4 bit byte đầu và 7 bit mỗi byte sau)
let offset = 4;
while (buffer[cur] >= 128) {
cur++;
size += (buffer[cur] & 127) << offset;
offset += 7;
}
0xCF & 127
11001111
& 01111111
-----------
01001111
0xCF << 4 = 010011110000
Tiếp đến ta phải giải nén nội dung mỗi entry. Một điểm khó lá vì size là size của nối dung trước khi được nén nên ta không thể dùng nó để slice dữ liệu nhận được.
Ta sẽ phải read tới khi zlib đưa dấu hiệu là đã giải nén xong một stream dữ liệu:
const zlib = require('zlib');
async function decompressPackObject(buffer, size) {
return new Promise((resolve, reject) => {
const inflater = zlib.createInflate();
let decompressedData = Buffer.alloc(0);
let parsedBytes = 0;
inflater.on("data", (chunk) => {
decompressedData = Buffer.concat([decompressedData, chunk]);
if (decompressedData.length > size) {
inflater.emit("error", new Error("Decompressed data exceeds maximum output size"));
}
});
inflater.on("end", () => {
parsedBytes = inflater.bytesRead;
resolve([decompressedData, parsedBytes]);
});
inflater.on("error", (err) => {
reject(err);
});
inflater.write(buffer);
inflater.end();
});
}
Cuối cùng ta có thể giải nén pack object như sau:
async function parsePackObject(buffer, i) {
const TYPE_CODES = {
1: "commit",
2: "tree",
3: "blob",
7: "delta",
};
let [parsedBytes, type, size] = parsePackObjectHeader(buffer, i);
i += parsedBytes;
// console.log(`Parsed ${parsed_bytes} bytes found type ${type} and size ${size}`,);
// console.log(`Object starting at ${i} ${buffer[i]}`);
if (type < 7 && type != 5) {
const [data, length] = await decompressPackObject(buffer.slice(i), size);
return [parsedBytes + length, { content: data, type: TYPE_CODES[type] }];
} else if (type == 7) {
const ref = buffer.slice(i, i + 20);
parsedBytes += 20;
const [data, length] = await decompressPackObject(buffer.slice(i + 20), size);
return [parsedBytes + length, { content: data, type: TYPE_CODES[type], ref }];
}
}
Lưu ý là git object type 7 thì còn có một 20 byte SHA trước dữ liệu.
Cuối cùng để trích xuất dữ liệu của master từ repo trong khi clone ta sẽ có function sau:
const fs = require('fs');
const zlib = require('zlib');
async function getParsedGitObjects(url) {
try {
const { data, head } = await getPackFile(url);
const packFile = data;
const packObjects = packFile.slice(20);
const packObjectCount = Buffer.from(packFile.slice(16, 20)).readUInt32BE(0);
let i = 0;
const gitObjects = [];
const deltaObjects = {};
for (let count = 0; count < packObjectCount; count++) {
const [byteRead, obj] = await parsePackObject(packObjects, i);
i += byteRead;
gitObjects.push(obj);
if (obj.type === "delta") {
deltaObjects[obj.ref.toString("hex")] = obj;
}
}
const checkSum = packObjects.slice(packObjects.length - 20).toString("hex");
return { gitObjects, deltaObjects, checkSum, head };
} catch (err) {
throw err;
}
}
Unpacking Delta
Tuy nhiên ta vẫn chưa có đủ dữ liệu để rebuild lại repo.
Để có thể nén dữ liệu càng nhiều càng tốt, git chỉ chứa những khác biệt từ các commit mới chứ không chứa riêng lẻ.
Dữ liệu này được chứa trong git object có type 7 là delta. Để có thể rebuild lại toàn bộ commit graph thì ta cần phải unpack delta
XDelta compression
Dữ liệu delta sử dụng trong git pack file sử dụng thuật toán XDelta để lưu trữ sự khác biệt giữa các file cũ và mới.
XDelta so sánh 2 string, và cho ra các lệnh copy hoặc add. Hai lệnh này thực hiện động thái copy nội dung từ base string hoặc thêm nội dung mới để cho ra target string.
Ví dụ:
base: the quick brown fox jumps over the slow lazy dog
target: a swift auburn fox jumps over three dormant hounds
Đầu tiên để tìm điểm chung để copy từ base string thì ta common substring của cả hai.
Đầu tiên ta tiền sử lý base string thành các block 16 bytes, chứa thành offset:
{
"the quick brown " => [ 0],
"fox jumps over t" => [16],
"he slow lazy dog" => [32]
}
Tiếp theo dùng sliding window 16 bytes đi qua target string ở từng offset và put từng chữ cái khác base ở offset vào lệnh insert
offset | sliding window | insert buffer
--------+-----------------------+------------------
0 | "a swift auburn f" | ""
1 | " swift auburn fo" | "a"
2 | "swift auburn fox" | "a"
3 | "wift auburn fox " | "a s"
4 | "ift auburn fox j" | "a sw"
Ở mỗi iteration ta match thử nội dung trong sliding window với các block 16 bytes của base string.
Đến index 15 thì ta tìm thấy "fox jumps over t" giống với block tại offset 16 của base.
Ta tiếp tục thử iterate sang chữ cái trước và sau để add vô copy đến khi không còn chữ cái giống nhau, và note lại offset đầu và cuối của common substring
base: the quick brow(n fox jumps over t)he slow lazy dog
target: a swift aubur(n fox jumps over t)hree dormant hounds
Cuối cùng ta có các lệnh sau:
insert "a swift aubur"
copy 14 19
insert "ree dormant hounds"
Dĩ nhiên lệnh copy và insert sẽ chỉ là một số chiếm vài byte và chuối ký tự 19 byte "a swift aubur" được rút gọn chỉ còn nhiều nhất là 3 byte (độ dài lớn nhất của một lẹnh copy)
Thuật toán này có độ compression cao vì không quan tâm đến vị trí của các substring ở đâu.
Time complexity của sliding window và hashtable ban đầu là O(n) Space complexity là O(n / k) với k là block size
Delta encoding trong git pack
Delta object trong git pack gồm 2 phần là header và instructions
Header
Định dạng header:
<type><base_size><target_size>
Type có định dạng như đã bàn ở phần git pack.
Theo sau sẽ có hai số variable length trong định dạng little-endian.
Các số này được chia thành nhóm 7 bit từ phải qua trái. Mỗi nhóm được đệm từ đầu thành đủ 8bit để thành 1 byte và bắt đầu từ byte có bit 1 và kết thúc tại byte có bit 0.
Ví dụ:
size
decimal 21759
binary 1 0101001 1111111
little-endian 1111111 0101001 1
padded 11111111 10101001 00000001
Đầu tiên ta sẽ process hai size trước:
function decodeDelta(instructions, refContent) {
refContent = Buffer.from(refContent, "utf8");
content = Buffer.alloc(0);
let i = 0;
let { parsedBytes: refParsedBytes, size: refSize } = parseSize(instructions, i);
i += refParsedBytes;
let { parsedBytes: targetParsedBytes, size: targetSize } = parseSize(instructions, i);
i += targetParsedBytes;
...
}
function parseSize(data, i) {
size = data[i] & 127;
parsedBytes = 1;
offset = 7;
while (data[i] > 127) {
i++;
size += (data[i] & 127) << offset;
parsedBytes++;
offset += 7;
}
return { parsedBytes, size };
}
Function decode delta của ta sẽ nhận 2 params là instructions là byte code của entry có type 7 trong git pack file. Như đã nói ở phần parse git pack file thì entry có type 7 sẽ có hash của base string trong entry và instructions trong mỗi entry.
Ở phần xử lý header của lệnh insert, như khi parse type của pack object, ta chỉ cần tìm byte đầu tiên có bit đầu tiên là 1, loop khi tìm thấy byte có bit đầu là 0 và cộng theo số mũ là offset.
Instructions
Tiếp đến, ta sẽ parse instructions trong delta file. Cả 2 lệnh đều sẽ là dạng variable length number
Định dạng insert:
<size><content>
Byte đầu tiên của insert sẽ luôn có bit đầu là 0 và 7 bit còn lại chứa độ dài của những byte theo sau trong byte stream dữ liệu thô cần được dùng để insert.
Code:
function decodeDelta(instructions, refContent) {
refContent = Buffer.from(refContent, "utf8");
content = Buffer.alloc(0);
let i = 0;
let { parsedBytes: refParsedBytes, size: refSize } = parseSize(instructions, i);
i += refParsedBytes;
let { parsedBytes: targetParsedBytes, size: targetSize } = parseSize(instructions, i);
i += targetParsedBytes;
while (i < instructions.length) {
if (instructions[i] <= 127) { // fist bit in byte is 0
let { parsedBytes, insertContent } = parseInsert(instructions, i);
content = Buffer.concat([content, insertContent]);
i += parsedBytes;
}
...
}
function parseInsert(data, i) {
const size = data[i];
let parsedBytes = 1;
i += parsedBytes;
const insertContent = data.slice(i, i + size);
parsedBytes += size;
return { parsedBytes, insertContent };
}
Định dạng copy:
<header_byte><content>
Lệnh copy luôn có bit đầu tiên của byte đầu tiên là 1.
Hai số offset và size cần copy sử dụng số hexadecimal.
Offset là index bắt đầu của substring và size là độ dài cần cắt sau offset để lấy substring trong base string
Git không sử dụng hết 7 byte mà còn tiếp tục nén cả hai lệnh này như sau
Ví dụ nếu ta có lệnh copy ở offset 13, và size là 1,000,000 là:
decimal: copy 13 1,000,0000
hex: copy 13 0F4240
Git sẽ đặt một mask 10000000 (hay 128) làm header, tiếp đến git sẽ biến size và off set thành little-endian, lấy 4 byte offset và 3 byte size và cuối cùng đặc mỗi bit đại diện cho một byte cần dùng trong header byte:
size: 00 00 00 00 0F 42 40
truncate: 0F 42 40
little-endian: 40 42 0F
---------------------------------
offset: 13
offset + size: 13 40 42 0F
---------------------------------
header: 1 0 0 0 0 0 0 0
header: 1 0 0 0 1 1 1 1 = 143 = 8F
---------------------------------
copy: 8F 13 40 42 0F
Để xử lý lệnh copy thì đầu tiên ta sẽ đọc byte đầu tiên và xử lý bit mask
function parseCopy(data, i) {
let offSetBytes = [];
let sizeBytes = [];
let mask = data[i]; // 10000000
let parsedBytes = 1;
i++;
for (let k = 0; k < 7; k++) {
if (k < 4) {
// 4 bits in mask
if (mask & (1 << (6 - k))) {
offSetBytes.push(data[i]);
i++;
parsedBytes++;
} else {
offSetBytes.push(0);
}
} else if (k >= 4) {
// 3 bits in mask
if (mask & (1 << (6 - k))) {
sizeBytes.push(data[i]);
i++;
parsedBytes++;
} else {
sizeBytes.push(0);
}
}
}
let offset = 0;
for (let [index, value] of offSetBytes.entries()) {
offset += value << (index * 8);
}
let size = 0;
for (let [index, value] of sizeBytes.entries()) {
size += value << (index * 8);
}
return {
parsedBytes,
offset,
size,
};
}
Ta sẽ loop 7 byte tiếp theo trong delta file. Nếu trong mask có bit 1 ở vị trí k thì ta thêm byte ở trong copy instruction ở vị trí đó vào.
Ví dụ:
header: 1 0 0 0 1 1 1 1
k: -----------------------
0: 1 0 0 0 0 0 0 0 => copy bit
1: 0 1 0 0 0 0 0 0 offset => 0
2: 0 0 1 0 0 0 0 0 => 0
3: 0 0 0 1 0 0 0 0 => 0
4: 0 0 0 0 1 0 0 0 => 13
5: 0 0 0 0 0 1 0 0 size => 40
6: 0 0 0 0 0 0 1 0 => 42
7: 0 0 0 0 0 0 0 1 => 0F
--------------------------
Sau đó ta sẽ shift 8 bit mỗi byte trong offset và size để giải mã vì byte nằm ở trật tự little endian
let offset = 0;
for (let [index, value] of offSetBytes.entries()) {
offset += value << (index * 8);
}
let size = 0;
for (let [index, value] of sizeBytes.entries()) {
size += value << (index * 8);
}
return {
parsedBytes,
offset,
size,
};
Cuối cùng ta có function giải mã delta như sau:
function decodeDelta(instructions, refContent) {
refContent = Buffer.from(refContent, "utf8");
content = Buffer.alloc(0);
let i = 0;
let { parsedBytes: refParsedBytes, size: refSize } = parseSize(instructions, i);
i += refParsedBytes;
let { parsedBytes: targetParsedBytes, size: targetSize } = parseSize(instructions, i);
i += targetParsedBytes;
while (i < instructions.length) {
if (instructions[i] <= 127) {
let { parsedBytes, insertContent } = parseInsert(instructions, i);
content = Buffer.concat([content, insertContent]);
i += parsedBytes;
} else if (instructions[i] > 127 && instructions[i] < 256) {
let { parsedBytes, offset, size } = parseCopy(instructions, i);
let copyContent = refContent.slice(offset, offset + size);
content = Buffer.concat([content, copyContent]);
i += parsedBytes;
} else {
throw new Error("Not copy or insert");
}
}
if (targetSize == content.length) {
return content;
} else {
throw new Error("Wrong target size, error in decoding delta");
}
}
Tuy nhiên vì các object delta có thể phụ thuộc vào một delta khác được giải mã nên ta phải loop để giải mã hết các delta:
function resolveDeltaObjects(deltas, basePath = "") {
let results = {};
let pending = {};
for (let key in deltas) {
try {
let delta = deltas[key];
let hash = delta.ref.toString("hex");
let instructions = delta.content;
const { type, length, content } = readGitObject(hash, basePath);
let decoded = { type: type, content: decodeDelta(instructions, content) };
decoded = parseGitObject(decoded);
writeGitObject(decoded.hash, decoded.parsed, basePath);
} catch (err) {
pending[deltas[key].hash] = deltas[key];
}
}
if (pending.length > 0) {
resolveDeltaObjects(pending, basePath);
}
return results;
}
Clone
Để tiếp tục quá trình clone đầu tiên ta sẽ tạo git folder:
const fs = require("fs");
const path = require("path");
function createGitDirectory(basePath = "") {
fs.mkdirSync(path.join(process.cwd(), basePath, ".git"), { recursive: true });
fs.mkdirSync(path.join(process.cwd(), basePath, ".git", "objects"), {
recursive: true,
});
fs.mkdirSync(path.join(process.cwd(), basePath, ".git", "refs"), {
recursive: true,
});
fs.writeFileSync(
path.join(process.cwd(), basePath, ".git", "HEAD"),
"ref: refs/heads/main\n",
);
//console.log('Initialized git directory')
}
async function clone(url, directory) {
const gitDir = path.resolve(directory);
fs.mkdirSync(gitDir);
init(directory);
...
Sau đó ta request git pack và parse các entry từ file, giải mã từng deltaObjects khi đã viết xong các gitObjects
async function clone(url, directory) {
...
const { gitObjects, deltaObjects, checkSum, head } = await getParsedGitObjects(url);
fs.writeFileSync(path.join(gitDir, ".git", "HEAD"), `ref: ${head.ref.toString("utf8")}`);
fs.mkdirSync(path.join(gitDir, ".git", "refs", "heads"), { recursive: true });
fs.writeFileSync(path.join(gitDir, ".git", "refs", "heads", head.ref.split("/")[2]), head.hash);
resolveDetaObjects(deltaObjects)
...
Sau khi đã có được các objects từ server, ta chỉ việc write các object thành blob
for (let key in gitObjects) {
let obj = gitObjects[key];
writeGitObject(obj.hash, obj.parsed, gitDir);
}
Sau đó ta sẽ checkout commit lấy từ server. Lệnh checkout chỉ đơn giản tìm đọc nội dung của một git tree và dựa trên các file, subtree để viết nội dung git repo vào thư mục.
Đầu tiên ta đọc commit từ hash từ master branch
async function clone(url, directory) {
const { gitObjects, deltaObjects, checkSum, head } = await getParsedGitObjects(url);
...
checkout(findTreeToCheckout(head.hash, directory), gitDir, gitDir);
return
}
function findTreeToCheckout(hash, basePath = "") {
const { type, length, content } = readGitObject(hash, basePath);
if (type !== "commit") {
throw new Error("Not a commit");
}
let commit = content.slice(content.indexOf("\0"));
commit = content.toString().split("\n");
let treeToCheckout = commit[0].split(" ")[1];
return treeToCheckout;
}
Có thể thấy: Tổ chức dữ liệu có cấu trúc và quản lý metadata là rất quan trọng để kiểm soát phiên bản hiệu quả và đảm bảo tính toàn vẹn của dữ liệu trong trường hợp của git. Việc sử dụng cấu trúc dữ liệu ảnh hưởng xuyên suốt cấu trúc và hành vi của dữ liệu trong git. Theo mình thấy thì design của git là một trường hợp ví dụ cực kỳ hay về cách thiết kế và tối ưu hiệu năng, công năng của phần mềm dựa trên kiến thức cấu trúc dữ liệu và giải thuật.
Cảm ơn các bạn đã đọc bài viết dài và phức tạp!
Mình xin lỗi nếu có sai sót gì. Mình chỉ viết để học tập nên nếu có sai sót gì xin các bạn bỏ qua và sửa sai giúp mình nhé.
Code của toàn bộ dự án có thể được xem ở repo sau: https://github.com/cnhhoang850/Jit
Nguồn tham khảo:
- Building Git - James Coglan
- Git protocol manual
- https://medium.com/@concertdaw/sneaky-git-number-encoding-ddcc5db5329f
All rights reserved
