Gemma - Bước tiến mới của Google
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu
Gần đây, Google giới thiệu một mô hình ngôn ngữ mới hẹn tạo nên nhiều đột phát trong lĩnh vực xử lý ngôn ngữ tự nhiên. Gemma, một dòng mô hình mở, nhẹ, hiện đại, được xây dựng từ nghiên cứu và công nghệ được sử dụng để tạo ra các mô hình Gemini. Các mô hình Gemma thể hiện hiệu suất mạnh mẽ qua các tiêu chuẩn học thuật về khả năng hiểu, lý luận và an toàn ngôn ngữ.

Google phát hành hai kích cỡ mô hình (2 tỷ và 7 tỷ tham số), đồng thời cung cấp cả điểm kiểm tra được huấn luyện trước và tinh chỉnh (pretrained and fine-tuned checkpoints). Gemma vượt trội hơn các mô hình mở có kích thước tương tự ở 11 trong số 18 nhiệm vụ dựa trên văn bản và chúng tôi trình bày các đánh giá toàn diện về các khía cạnh an toàn và trách nhiệm của các mô hình, cùng với mô tả chi tiết về quá trình phát triển mô hình.
Theo tài liệu được Google công bố, họ đã đào tạo các mô hình Gemma trên tối đa 6 tỷ mã thông báo văn bản, sử dụng cùng kiến trúc, dữ liệu và công thức đào tạo như dòng mô hình Gemini. Những mô hình này, giống như Gemini, có khả năng tổng quát đáng kể trong lĩnh vực văn bản, cũng như kỹ năng hiểu và suy luận nâng cao trên quy mô lớn. Với nỗ lực này, chúng tôi cung cấp cả các điểm kiểm tra được đào tạo trước và tinh chỉnh, cũng như cơ sở mã nguồn mở để suy luận và phân phát.
Về mô hình
Kiến trúc mô hình Gemma dựa trên bộ giải mã biến áp với các cải tiến bao gồm multi-query attention (được sử dụng bởi mô hình 2B), multi-head attention (được sử dụng bởi mô hình 7B), nhúng RoPE (RoPE embeddings), kích hoạt GeGLU (GeGLU activations) và vị trí bộ chuẩn hóa (normalizer location).
Điều chỉnh hướng dẫn (Instruction Tuning)
Google điều chỉnh Gemma 2B và 7B:
- Có hướng dẫn: trên sự kết hợp của các cặp phản hồi nhanh chóng tổng hợp chỉ bằng văn bản, chỉ bằng tiếng Anh và do con người tạo ra.
- Học tập tăng cường từ phản hồi của con người (RLHF): mô hình khen thưởng (the reward model) được đào tạo dựa trên dữ liệu ưu tiên chỉ có tiếng Anh được gắn nhãn và chính sách dựa trên một bộ lời nhắc.
Định dạng Prompt
Google tinh chỉnh các mô hình này với một bộ định dạng chú thích tất cả các ví dụ điều chỉnh lệnh với thông tin bổ sung. Nó có hai mục đích:
- chỉ ra các vai trò trong cuộc trò chuyện, chẳng hạn như Vai trò của người dùng
- phân định các lượt trong cuộc trò chuyện, đặc biệt là trong cuộc trò chuyện nhiều lượt.
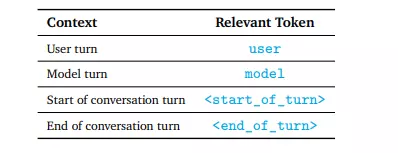
Một ví dụ về quá trình trò chuyện giữa mô hình và người dùng:

Để prompt Gemma 7B một cách hiệu quả, trước tiên ta phải hiểu cách sử dụng mẫu lời nhắc. Ví dụ như Zero-shot learning, ta chỉ cần tạo 1 prompt như sau:
<start_of_turn>user
Explain why the leaf is green<end_of_turn>
<start_of_turn>model
Ngoài ra, ta có thể thêm 1 vài chỉ đạo để mô hình có thể tạo ra kết quả phù hợp với mong muốn của ta (Xem thêm tại [2]):
<start_of_turn>user
Answer the following question in a concise and informative manner:
Explain why the leaf is green<end_of_turn>
<start_of_turn>model
Kết quả
Khả năng hiểu ngôn ngữ và hiệu suất tạo của Gemma 7B dựa trên những khả năng khác nhau (hỏi đáp, lý luận, toán học/khoa học, code) khi đối chiếu với các mô hình khác cùng kích cỡ cho thấy sự ưu việt của mô hình này. Rõ ràng, Gemma 7B dẫn đầu với cả 3 lĩnh vực sau và chỉ thua mô hình 13B của LLaMa2 với khoảng cách rất ngắn.
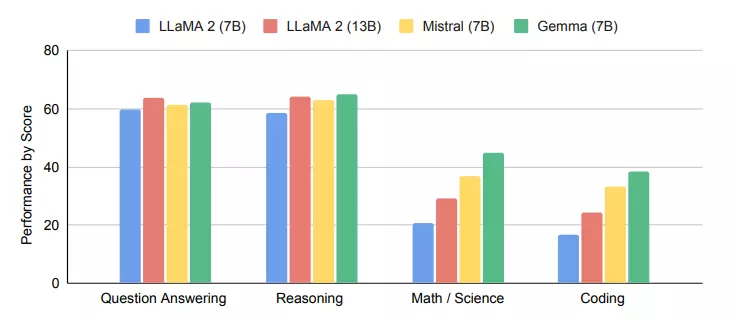
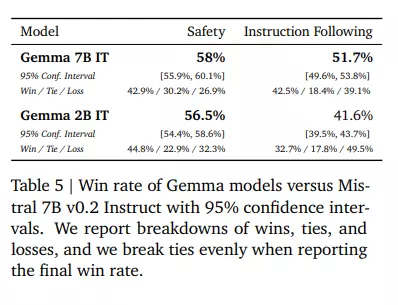
Đánh giá theo sự ưa thích của con người (Human Preference Evaluations)
Ngoài ra, nghiên cứu đã đánh giá các ứng cử viên phát hành cuối cùng dựa trên mô hình Hướng dẫn Mistral v0.2 7B. Kết quả cho thấy Gemma 7B IT có tỷ lệ thành công tích cực là 51,7% đối với các nhiệm vụ viết sáng tạo và mã hóa, đồng thời tỷ lệ thành công là 58% đối với các giao thức an toàn cơ bản, so với Mistral v0.2 7B Instruct.
Điểm chuẩn tự động (Automated Benchmarks)
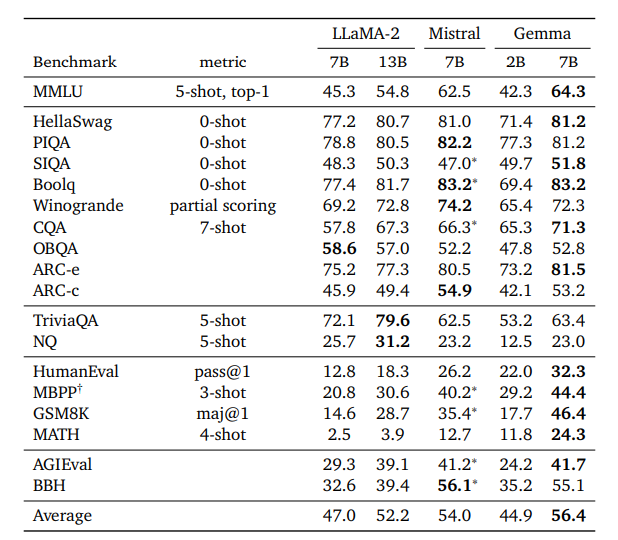
Các mô hình Gemma đã được đánh giá trên nhiều lĩnh vực khác nhau, bao gồm lý luận vật lý, lý luận xã hội, trả lời câu hỏi, mã hóa, toán học, lý luận thông thường, mô hình ngôn ngữ và đọc hiểu.
Các mô hình Gemma 2B và 7B được so sánh với một số LLM nguồn mở bên ngoài dựa trên các điểm chuẩn học thuật. Trên MMLU, Gemma 7B vượt trội hơn tất cả các lựa chọn thay thế về phần mềm nguồn mở và các mô hình lớn hơn, bao gồm cả LLaMA2 13B.
Tuy nhiên, vẫn còn chỗ cần cải tiến để đạt được hiệu suất ở cấp độ con người. Các mô hình Gemma vượt trội hơn các mô hình khác về các nhiệm vụ toán học và điểm chuẩn mã hóa, vượt qua hiệu suất của các mô hình CodeLLaMA-7B được tinh chỉnh mã trên MBPP.
Đánh giá về độ khi nhớ (Memorization evaluations)
Các phát hiện gần đây cho thấy rằng dễ bị tổn thương trước các cuộc tấn công thù địch ( adversarial attacks) mới (Xem thêm ở [3]). Lợi dụng khả năng nắm bắt dữ liệu của các mô hình lớn, bên tấn công có khả năng lấy các thông tin không an toàn, nhạy cảm từ bộ dữ liệu mà các mô hình đó được học.
Gemma không nắm bắt các thông tin cá nhân hoặc nhạy cảm. Để chứng minh, họ sử dụng công cụ Ngăn chặn mất dữ liệu trên đám mây của Google để xác định các trường hợp dữ liệu cá nhân có thể xảy ra. Công cụ đưa ra ba mức độ nghiêm trọng dựa trên nhiều loại dữ liệu cá nhân khác nhau, trong đó mức độ nghiêm trọng cao nhất là "nhạy cảm". Sau đó, chúng tôi đo lường lượng dữ liệu đầu ra được ghi nhớ chứa bất kỳ dữ liệu cá nhân hoặc nhạy cảm nào. Họ không quan sát thấy trường hợp nào ghi nhớ dữ liệu nhạy cảm.
Kết luận
Các mô hình Gemma cải thiện hiệu suất trên nhiều lĩnh vực, bao gồm đối thoại, lý luận, toán học và tạo mã.
Có thể thấy rằng, Gemma được hưởng lợi từ nhiều bài học từ chương trình mô hình Gemini, bao gồm mã, dữ liệu, điều chỉnh hướng dẫn, học tập tăng cường từ phản hồi của con người (RLHF), …
Tham khảo:
- Gemma: Open Models Based on Gemini Research and Technology - URL: https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
- Gemma - URL: https://www.promptingguide.ai/models/gemma#gemma-7b-prompt-format 3.Adversarial Attacks on LLMs - URL: https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/
- Measuring Massive Multitask Language Understanding - URL: https://arxiv.org/abs/2009.03300
Ghi chú
- MMLU: Massive Multi-task Language Understanding (Hiểu ngôn ngữ đa tác vụ lớn)
- MBPP: Micro-Benchmark for Programming Puzzles (Điểm chuẩn vi mô cho các câu đố lập trình.)
All rights reserved
