KeyBERT: Trích xuất từ khóa một cách dễ dàng
Phát hiện những từ khóa quan trọng nhất từ văn bản của bạn một cách dễ dàng
Giới thiệu
Trong quá trình phát triển hệ thống RAG, mình nhận thấy người dùng thường đưa ra các câu hỏi mơ hồ thay vì những câu hỏi cụ thể. Điều này khiến LLM khó hiểu và khiến việc tìm kiếm trong cơ sở dữ liệu vector trở nên khó khăn hơn. Do đó, cần có những phương pháp để giải quyết vấn đề này.

Từ khóa là yếu tố quan trọng đối với mọi nội dung thành công, dù đó là một cuộc thảo luận, một bài viết hay bất kỳ thứ gì khác. Chiến lược này bao gồm việc tìm kiếm từ khóa trong các truy vấn của người dùng, giúp bộ thu thập tập trung vào các thuật ngữ đó để xác định các cụm từ tương tự, làm cho việc thu được kết quả gần đúng trở nên đơn giản hơn.
KeyBERT là một công cụ trích xuất từ khóa dựa trên LLM. Nó sử dụng các embedding BERT và độ tương tự cosine cơ bản để xác định các cụm từ con trong một tài liệu nào đó có độ tương tự cao nhất với chính tài liệu đó. Cách thức hoạt động của nó được mô tả như sau:
- Trích xuất các embedding tài liệu bằng BERT để có được biểu diễn cấp tài liệu.
- Sử dụng các embedding từ để trích xuất các từ/cụm từ N-gram.
- KeyBERT sử dụng độ tương tự cosine để xác định các từ/cụm từ nào có độ tương tự cao nhất với tài liệu. Các cụm từ tương ứng nhất được chọn là những cụm từ mô tả tốt nhất toàn bộ tài liệu.
Dưới đây là repo Github của KeyBERT: https://github.com/MaartenGr/KeyBERT.git
Lưu ý: Mình khuyến khích các bạn truy cập repo KeyBERT vì nó giới thiệu cách tích hợp với sentence_transformers và LLMs một cách cụ thể, cho phép KeyBERT cập nhật theo kịp những đổi mới mới nhất trong lĩnh vực này.
Thực thi code
Trước tiên, tôi cài đặt và gọi các thư viện cần thiết:
# Install necessary packages
!pip install -q keybert pypdf
# Our sample
!wget https://arxiv.org/pdf/1706.03762.pdf
# Import libraries
import re
from keybert import KeyBERT
from pypdf import PdfReader
Sau đó, tôi phân tích tệp .pdf bằng PdfReader. Chúng ta có thể xem số trang và nội dung của mỗi trang:
reader = PdfReader("/content/1706.03762.pdf")
print(len(reader.pages)) # 15 pages
page_no = 0
page = reader.pages[page_no]
text = page.extract_text()
print(text)
"""
...
The dominant sequence transduction models are based on complex recurrent or
convolutional neural networks that include an encoder and a decoder. The best
performing models also connect the encoder and decoder through an attention
mechanism. We propose a new simple network architecture, the Transformer,
based solely on attention mechanisms, dispensing with recurrence and convolutions
entirely. Experiments on two machine translation tasks show these models to
be superior in quality while being more parallelizable and requiring significantly
less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-
to-German translation task, improving over the existing best results, including
ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task,
our model establishes a new single-model state-of-the-art BLEU score of 41.8 after
training for 3.5 days on eight GPUs, a small fraction of the training costs of the
best models from the literature. We show that the Transformer generalizes well to
other tasks by applying it successfully to English constituency parsing both with
large and limited training data.
....
"""
Tôi sử dụng KeyBERT để trích xuất từ khóa:
# You can un-note the remove \n if you want.
# text = text.replace("\n", " ")
kw_model = KeyBERT()
keywords = kw_model.extract_keywords(text, keyphrase_ngram_range=(1, 3), highlight=True, stop_words='english', use_maxsum=True, top_n=10)
Dưới đây là một số giải thích về mã:
- Để chỉ định độ dài của các từ khóa/cụm từ khóa được tạo, bạn có thể sử dụng tham số keyphrase_ngram_range. Ví dụ: đặt
keyphrase_ngram_rangethành (1, 2) hoặc cao hơn, tùy thuộc vào số lượng từ bạn muốn trong các cụm từ khóa được tạo. - Hàm
use_maxsumtrong KeyBERT chọn 2 xtop_ntừ/cụm từ tương tự nhất trong tài liệu. Sau đó, nó lấy tất cảtop_nkhả năng từ 2 xtop_ntừ và trích xuất sự kết hợp có độ tương tự cosine nhỏ nhất. top_nchỉ ra số lượng từ khóa phản hồi mà bạn muốn.
Dưới đây là kết quả:
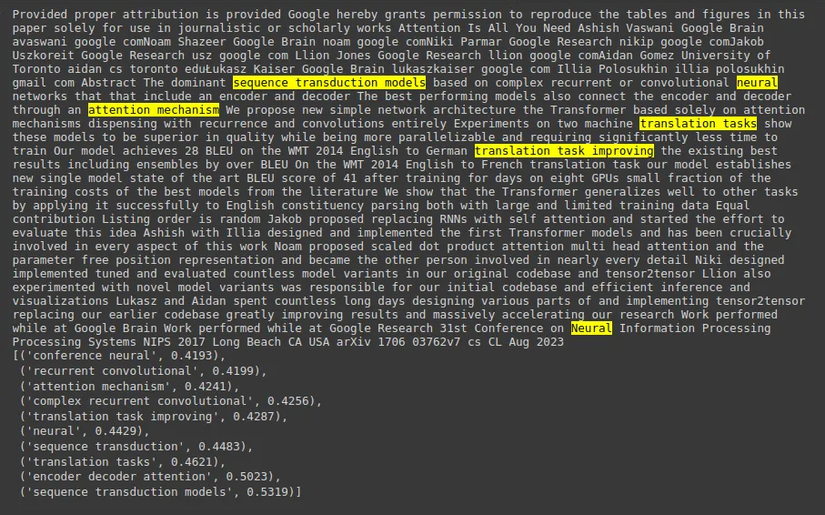
Kết luận
Trong bài đăng này, tôi đã giới thiệu KeyBERT, một công cụ trích xuất từ khóa sử dụng các embedding BERT và độ tương tự cosine cơ bản để xác định các cụm từ con trong một văn bản có độ tương tự cao nhất với chính nội dung đó. Theo quan điểm của tôi, công cụ này nhẹ nhàng và dễ sử dụng. Hơn nữa, nó hỗ trợ nhiều mô hình và LLM thay thế khác nhau, giúp dễ dàng kết hợp với các hệ thống khác.
All rights reserved
