Elasticsearch - phần 1
Bài đăng này đã không được cập nhật trong 4 năm
Tôi tin là ít nhất một lần bạn đã nghe đến công cụ phổ biến hỗ trợ cho việc tìm kiếm và đánh Index được sử dụng bởi các ông lớn như Wikipedia, Linkedin. Vâng, cái mà tôi đang nói đến chính là Elasticsearch. Ở bài viết này tôi tìm hiểu và giới thiệu những kiến thức cơ bản đầu tiên về Elasticsearch. Khái niệm Elasticsearch, những ích lợi của Elasticsearch, cách cài đặt Elasticsearch, và cách đánh index cho document để sử dụng Elasticsearch.
Elasticsearch là gì
Elasticsearch là một công cụ tìm kiếm mã nguồn mở, mạnh mẽ. Nó được phát triển với nền tảng là Apache Lucene (Java full-text search library), cung cấp API cho việc tìm kiếm lưu trữ dữ liệu một cách nhanh chóng. Elasticsearch được ví như chiếc xe hơi, xe hơi thì rất hữu dụng, tiện lợi, dễ sử dụng. Nhưng động cơ của xe hơi thì có cấu tạo và nguyên lý hoạt động phức tạp, nó được lấy làm ví dụ cho Apache Lucene. Điểm mạnh của Elasticsearch là tính phân tán và khả năng mở rộng.
Lợi thế của Elasticsearch
- Xây dựng trên Lucene: Vì được xây dựng trên Lucene nên Elasticesearch cung cấp khả năng tìm kiếm toàn văn bản (full-text) mạnh mẽ nhất.
- Hướng văn bản: Nó lưu trữ các thực thể phức tạp dưới dạng JSON và đánh index tất cả các field theo cách mặc định, do vậy đạt hiệu suất cao hơn.
- Giản đồ tự do: Nó lưu trữ số lượng lớn dữ liệu dưới dạng JSON theo cách phân tán. Nó cũng cố gắng phát hiện cấu trúc của dữ liệu và đánh index của dữ liệu hiện tại, làm cho dữ liệu trở nên thân thiện với việc tìm kiếm.
- Full-tex search: Elasticsearch thực hiện tìm kiếm ngôn ngữ với văn bản và trả về kết quả phù hợp với điều kiện tìm kiếm. Kết quả phù hợp được trả về từ truy vấn tìm kiếm được tính toán theo thuật toán TF/IDF.
- Restful - API: Elasticsearch hỗ trợ REST API là giao thức light-weight. Chúng ta có thể thực hiện truy vấn Elasticsearch bằng cách sử dụng REST API với plug-in Sense của Chrome. Sene cung cấp giao diện người dùng đơn giản, thân thiện, có các tính năng gợi nhớ cú pháp truy vấn, hay copy query như lệnh cURL.
Những thuật ngữ cơ bản trong Elasticsearch
- Node: Là một server Elasticsearch đơn lẻ. Là nơi chứa dữ liệu và có khả năng tham gia lập index và tìm kiếm của cả cluster.
- Cluster: Là một tập hợp (Collection) các Node chia sẻ dữ liệu. Mỗi Cluster có một Node chính (master), được lựa chọn tự động và có thể bị thay thế nếu có sự cố xảy ra.
- Index: Là một tập hợp của những tài liệu có những đặc điểm tương tự nhau. Một chỉ mục tương đương với một schema của Hệ quản trị CSDL quan hệ.
- Type: Có thể có nhiều Type trong cùng một Index. Ví dụ, một ứng dụng thương mại điện tử có thể sử dụng các sản phẩm cũ trong một Type và những sản phẩm mới trong một Type khác của cùng Index. Một Index có thẻ có nhiều Type, giống như có nhiều Table trong một Database.
- Document: Là một đơn vị thông tin cơ bản có thể đánh index. Document giống như row của table.
- Shard và Replica: Mỗi node sẽ gồm nhiều shard là các đối tượng của Lucene. Shard hoạt động ở mức thấp nhất, đóng vai trò lưu trữ dữ liệu. Chúng ta gần như không bao giờ làm việc trực tiếp với shard, Elasticsearch quản lý toàn bộ giao tiếp với shard, tự động thay đổi khi cần thiết. Shard có hai loại là primary shard và replica shard. Primary shard và Replica shard được hình dung như Master và Slave trong MySQL. Dữ liệu được lưu tại 1 Primary Shard, được đánh index ở đây trước khi chuyển đến Replica Shard. Mặc định của Elasticsearch là 5 Primary Shard cho một Index. Một Primary Shard có thể không có, hoặc có Replica Shard. Mặc định Elasticsearch là 1 Replica Shard trên một Primary Shard. Vai trò của Replica Shard cũng giống như Slave trong MySQL, đảm bảo khi Primary Shard có sự cố thì dữ liệu vẫn toàn vẹn và thay thế được Primary Shard, đồng thời tăng tốc độ đọc vì Replica Shard có thể là nhiều hơn 1 (Mặc định là 1). Trong quá trình hoạt động, bạn được thay thế số lượng Replica Shard một cách thoải mái.
Cài đặt
Hệ điều hàn Lunux - Ubuntu. Java JDK 8. Ta download file zip Elasticsearch bản 5.4 bằng lệnh sau: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.4.0.tar.gz Tiếp theo ta giải nén. tar -zxvf elasticsearch-5.4.0.tar.gz Đến thư mục elasticsearch cd elasticsearch-5.4.0 Khởi động Elasticsearch server bin/elasticsearch Để kiểm tra hoạt động của elasticsearch server ta truy cập từ brownser: http://localhost:9200 Kết quả như sau
{
“name” : “j4LkZ7h”,
“cluster_name” : “elasticsearch”,
“cluster_uuid” : “e6t_hv6eQCi280elcktrUQ”,
“version” : {
“number” : “5.4.0”,
“build_hash” : “780f8c4”,
“build_date” : “2017-04-28T17:43:27.229Z”,
“build_snapshot” : false,
“lucene_version” : “6.5.0”
},
“tagline” : “You Know, for Search”
}
Đánh index Document
Elasticsearch sử dụng các index Lucene để lưu trữ và truy xuất dữ liệu. Thêm dữ liệu vào Elasticsearch được hiểu là đánh index. Trong khi thực hiện đánh index, Elasticsearch biến đổi dữ liệu thô thành document của nó. Mỗi một document là một tập các key và value tương ứng. Key có kiểu String, còn value có thể kiểu String, Number, Date, List... Ta có thể thực hiện truy vấn Elasticsearch bằng các phương pháp sau:
- Lệnh cURL
- Các phương thức HTTP client: GET, POST, PUT, và DELETE
- JSON DSL
Giờ chúng ta thử đánh index cho document như sau (Bạn nên sử dụng Elasticsearch extendsion cho Chrome).
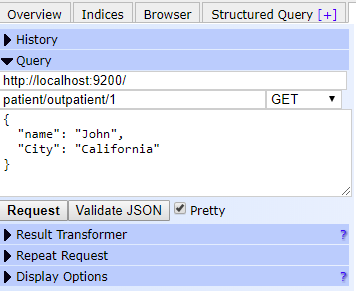
Click Request button để thực hiện đánh index. Truy xuất một Document Thự hiện truy xuất với lệnh GET ta có kết quả sau.
{
"_index": "patient",
"_type": "outpatient",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"name": "John",
"City": "California"
}
}
Xóa một Document
Để xóa một Document (ID = 1) ta chỉ việc gọi lệnh curl DELETE
curl -XDELETE ‘localhost:9200/patient/outpatient/1?pretty’
Giờ ta truy xuất lại tại Document đã xóa bằng lệnh GET
{
"_index": "patient",
"_type": "outpatient",
"_id": "1",
"found": false
}
Ta thấy Document có ID = 1 đã bị xóa. Vậy là chúng ta vừa tìm hiểu những khái niệm ban đầu về Elasticsearch, cách đánh index cho Document, truy xuất và xóa một Document. Tài liệu tham khảo
All rights reserved
