Series Elasticsearch - Elasticsearch là gì? Các khái niệm trong Elasticsearch.
Bài đăng này đã không được cập nhật trong 7 năm
References: https://stackjava.com/elasticsearch/elasticsearch-la-gi-cac-khai-niem-trong-elasticsearch.html
(Xem thêm: Hướng dẫn toàn bộ Elasticsearch)
Elasticsearch là gì?
- Elasticsearch là một search engine (công cụ tìm kiếm) rất mạnh mẽ.
- Elasticsearch cũng có thể coi là một document oriented database, nó chứa dữ liệu giống như một database và thực hiện tìm kiếm trên những dữ liệu đó.
- Đại khái là thay vì bạn tìm kiếm trên file, trên các database như MySQL, Oracle, MongoDB… thì bạn chuyển dữ liệu đó sang Elasticsearch và thực hiện tìm kiếm trên Elasticsearch sẽ mang lại hiệu quả rất lớn, đặc biệt là trong những trường hợp dữ liệu lớn.
Một số đặc điểm, tính năng của Elasticsearch
- Elasticsearch được viết bằng ngôn ngữ lập trình Java.
- Elasticsearch hoạt động như một cloud server theo cơ chế RestFUL, tức là bạn có thể thêm/sửa/xóa/tìm kiếm dữ liệu trên Elasticsearch với các api http (POST,PUT,DELETE,GET) như gửi request tới một service vậy.
- Tất cả dữ liệu được lưu vào Elasticsearch đều được đánh index (đánh chỉ mục), đây là lý do tại sao hiệu năng tìm kiếm của Elasticsearch rất cao.
- Việc đánh index của Elasticsearch khá giống với MongoDB tuy nhiên đó đánh index một cách chi tiết hơn, ví dụ bạn có 1 đoạn text ‘tran van b’ khi đánh index trong MongoDB nó sẽ tách ra làm 3 từ là [‘tran’, ‘van’, ‘b’] nếu bạn search từ ‘a’ thì nó sẽ không tìm thấy. Ngược lại Elasticsearch vẫn tìm thấy trong trường hợp này.
Chính nhờ cơ chế đánh index và lưu dữ liệu dạng document oriented nên Elasticsearch rất thích hợp trong các trường hợp:
- Tìm kiếm text thông thường, query like, sử dụng cho trương hợp autocomplete
- Tìm kiếm text và dữ liệu có cấu trúc
- Tổng hợp dữ liệu
- Tìm kiếm theo tọa độ
- Tìm kiếm với big data.
Cơ chế làm việc với Elasticsearch
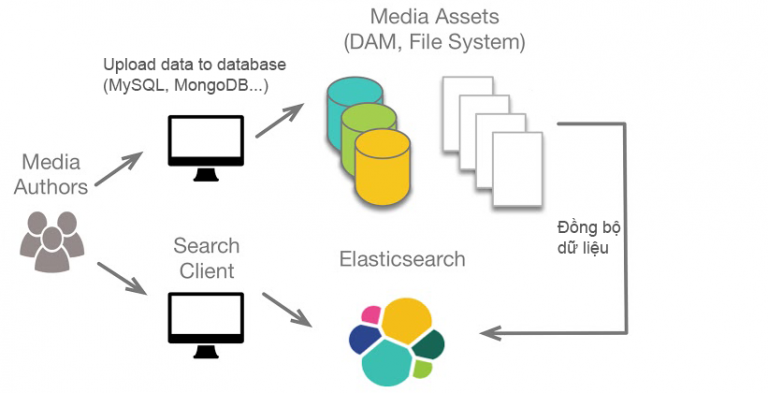 Các dữ liệu tổng hợp, dữ liệu được người dùng tải lên sẽ lưu vào database sau đấy đồng bộ hóa sang Elasticsearch.
Các dữ liệu tổng hợp, dữ liệu được người dùng tải lên sẽ lưu vào database sau đấy đồng bộ hóa sang Elasticsearch.
Khi người dùng tìm kiếm thì sẽ tìm kiếm trên Elasticsearch, tốc độ vừa nhanh, vừa giảm tải cho database.
Các khái nhiệm trong Elasticsearch
-
Cluster: Một tập hợp Nodes (servers) chứa tất cả các dữ liệu nhằm đảm bảo tính tin cậy và sẵn dùng
-
Node: Một server duy nhất chứa một số dữ liệu và tham gia vào cluster’s indexing and querying.
-
Index: Index ở đây không phải là chỉ số mà là một tập hợp các documents, nó tương đương với khái niệm một database
-
Type: hay còn gọi là Mapping Type: là 1 tập các document cùng loại (tương đương với khái niệm collection trong MongoDB hay khái niệm table trong database SQL)
-
Document: Một JSON object với một số dữ liệu, đây là một đơn vị thông tin trong Elasticsearch (tương đương với khái niệm document trong MongoDB hay khái niệm row trong table của database SQL)
-
Shards: Tập con các documents của 1 Index. Một Index có thể được chia thành nhiều shard, mỗi shard cũng có thể coi là một index có thể được truy cập trực tiếp giúp tính toán, tìm kiếm 1 cách song song.
Hiểu nôm na thì 1 hệ thống có thể sử dụng kết hợp nhiều server Elasticsearch, mỗi server Elasticsearch là 1 node.
Mỗi Node chứa nhiều Index, trong Index lại có thể chứa nhiều type khác nhau. Dữ liệu thực tế sẽ được lưu vào trong các type.
(Có thể hiểu là 1 Node sẽ chứa nhiều database, trong 1 database có thể chứa nhiều table. Trong table chứa các row là dữ liệu được thêm vào)
__ Okay, Done!
(Xem thêm: Hướng dẫn cài đặt Elasticsearch trên Ubuntu)
(Xem thêm: Hướng dẫn cài đặt Elasticsearch trên Windows)
References:
https://stackjava.com/elasticsearch/elasticsearch-la-gi-cac-khai-niem-trong-elasticsearch.html
All rights reserved
