Phần 1: Những khái niệm cơ bản trong Elasticsearch
Bài đăng này đã không được cập nhật trong 4 năm
Bài viết này với mục đích giới thiệu về những kiến thức, khái niệm cơ bản về ES để bắt đầu cho chuỗi bài viết về ES mà tôi sẽ giới thiệu tới đây.
1. Indexing
Elasticsearch cho phép trả về kết quả cực nhanh bởi thay vì tìm kiếm bởi text, ES tìm kiếm bởi inverted index. Hơi khó hiểu phải không, lấy một ví giả sử khi đọc một quyển sách. Để giúp độc giả tìm kiếm nội dung của quyển sách nhanh hơn thông thường một quyển sách sẽ có 2 phần phụ lục: phần trước và phần sau. Thông thường phần phụ lục trước sẽ lưu content giống như dưới đây:
Chapter 1: Refactoring, a First Example ...........................1
The Starting Point.........................................................3
The first step in refactoring..........................................6
...
Phần sau:
A: Algorithm(page139-140), Association(page125-167)
B: Back pointer defined(page197), Bugs(page123)
Việc làm phụ lục bản chất giống như việc đánh index vậy. Cách làm phụ lục như phần trước gọi là forward index còn phần sau là inverted index.
- Forward Index: Đánh index theo nội dung, page: page -> words
- Inverted Index: Đánh index theo keyword: words -> pages
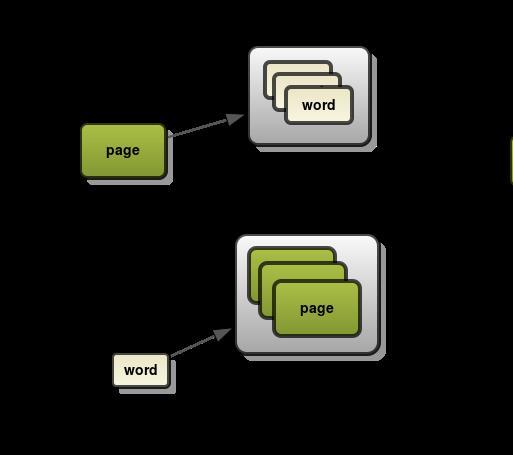
Như vậy với việc dùng inverted index với các keywords, Thay vì đọc từng page để tìm kiếm, ES sẽ tìm kiếm keyword trong index nên kết quả trả về sẽ rất nhanh. Elasticsearch sử dụng search engine Apache Lucence để tạo và quản lý inverted index
2. ES lưu dữ liệu như thế nào?
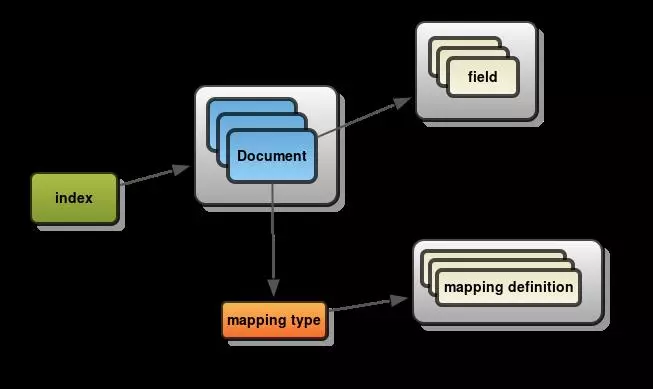
Với ES, Document là đơn vị tìm kiếm và đánh index. Một index có thể bao gồm một hay nhiều Document, và một Document có thể chứa một hay nhiều Fields.
Trong thuật ngữ về Database, thì một Document có thể hiểu như một table row và một Field tương ứng với một table column.
Không giống như Solr, ES có đặc điểm schema-free. Điều này có nghĩa là bạn không cần phải chỉ rõ ra cấu trúc của schema trước khi đánh index cho các documents.
Một schema sẽ bao gồm các thông tin:
- Các fields
- Các ràng buộc: unique/primary key
- Các required fields
- Đánh index và search mỗi field như thế nào.
Mapping là quá trình định nghĩa làm thế nào một document và các fields của nó được lưu trữ và đánh index. Ví dụ sử dụng mapping để định nghĩa:
- String fields nào được sử dụng như là full-text fields
- Fields nào chứa numbers, dates hay geolocations
- Liệu giá trị của tất cả các fields trong document được đánh index catch-all
- Format của các date field
- Các custom rules để điều khiển mapping
Mapping Type
Mỗi một index có một hoặc nhiều mapping type, chúng được sử dụng để chia các documents trong một index thành các logical groups. Ví dụ có index my_index dùng để lưu trữ cả thông tin user và blogpost.
User có thể được lưu trong user type nà blog posts trong một blogpost type
Ví dụ về một mapping:
PUT my_index
{
"mappings": {
"user": {
"_all": { "enabled": false },
"properties": {
"title": { "type": "text" },
"name": { "type": "text" },
"age": { "type": "integer" }
}
},
"blogpost": {
"_all": { "enabled": false },
"properties": {
"title": { "type": "text" },
"body": { "type": "text" },
"user_id": {
"type": "keyword"
},
"created": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
}
Để tạo mapping bạn sẽ cần PUT mapping API hay bạn có thể add multiple mapping khi đánh index.
3. Cluster
Clustering là một kiến trúc nhằm đảm bảo nâng cao khả năng sẵn sàng cho các hệ thống mạng máy tính. Clustering cho phép sử dụng nhiều máy chủ kết hợp với nhau tạo thành một cụm có khả năng chịu đựng hay chấp nhận sai sót (fault-tolerant) nhằm nâng cao độ sẵn sàng của hệ thống mạng. Cluster là một hệ thống bao gồm nhiều máy chủ được kết nối với nhau theo dạng song song hay phân tán và được sử dụng như một tài nguyên thống nhất.
Nếu một máy chủ ngừng hoạt động do bị sự cố hoặc để nâng cấp, bảo trì, thì toàn bộ công việc mà máy chủ này đảm nhận sẽ được tự động chuyển sang cho một máy chủ khác (trong cùng một cluster) mà không làm cho hoạt động của hệ thống bị ngắt hay gián đoạn. Quá trình này gọi là “fail-over”; và việc phục hồi tài nguyên của một máy chủ trong hệ thống (cluster) được gọi là “fail-back”.
Trong ES, mỗi một cluster là một tập các node(server), cluster chứa toàn bộ dữ liệu đồng thời cung cấp khả năng đánh index và tìm kiếm trên toàn bộ các node thuộc cluster đó. Mỗi cluster được định danh bởi một tên duy nhất, nếu không chỉ định cụ thể thì tên mặc định của nó là elasticsearch
4. Node
Một node là một single server, là một phần của cluster, tham gia vào quá trình đánh index và tìm kiếm của cluster. Cũng giống như cluster mỗi node được định danh bởi một tên và được sinh ngẫu nhiên tại thời điểm khởi động hệ thống. Tất nhiên chúng ta có thể chỉ định tên cho các node này cho mục đích quản lý. Mỗi node có thể join với một cluster mặc định là join với elasticsearch cluster nếu không được chỉ định.
5. Shards vs Replicas
Problem: Một index chứa quá nhiều dữ liệu mà hardware không đáp ứng được hoặc việc tìm kiếm trên một index có quá nhiều dữ liệu sẽ làm giảm hiệu năng
Solution: ES cung cấp cơ chế cho phép chia index thành nhiều phần nhỏ các phần này được gọi là shards. khi tạo một index có thể configure số lượng shards mà chúng ta muốn lưu trữ index này.
Mỗi shards, bản thân nó là một index đầy đủ chức năng và độc lập do đó chúng có thể được host bởi bất kỳ node (server) nào.
Sharding quan trọng vì 2 lý do chính sau:
- Cho phép horizontally scale
- Cho phép tính toán phân tán và song song đồng thời trên các shards => tăng hiệu năng
Cuối cùng, ES cũng cho phép bạn tạo một hay nhiều bản copy của một shards, gọi là replica shards ngắn gọn là replicas
Replication quan trọng vì 2 lý do chính:
- Tăng khả năng chịu lỗi của hệ thống, nếu một shard bị lỗi, thì bản copy của nó sẽ được dùng để thay thế
- Cho phép scale hệ thống vì việc tìm kiếm có thể tiến hành song song trên các
replicas
Ở các bài viết tiếp theo sẽ đi sâu hơn vào từng phần trong ES như cài đặt, đánh index như thế nào và query dữ liệu như thế nào. (to be continued)
All rights reserved
