Elasticsearch: Distributed Search
Bài đăng này đã không được cập nhật trong 4 năm

Elasticsearch là gì
Ngày nay, Elasticsearch không còn là khái niệm xa lạ với lập trình viên về web. Elasticsearch thực chất là một server chạy trên nền tàng Apache Lucene, cung cấp API cho công việc lưu trữ tìm kiếm dữ liệu một cách rất nhanh chóng. Điểm mạnh của Elasticsearch chính là tính phân tán cũng như khả năng mở rộng rất tốt của nó.
Nếu bạn băn khoăn Elasticsearch khác gì Apache Lucene thì có một phép so sánh rất đơn giản. Hãy coi Elasticsearch như cái xe ô tô của bạn và Apache Lucene là động cơ. Không có động cơ thì không có xe, cũng như không có Apache Lucence thì không có Elasticsearch. Tuy nhiên, về cơ bản, bạn chỉ cần lái xe, và không cần biết động cơ hoạt động như thế nào. Cũng như với Elasticsearch, bạn chỉ cần tìm hiểu và sử dụng nó, không cần quan tâm Apache Lucene. Mặc dù vậy, nếu xe hỏng thì có kiến thức về động cơ vẫn tốt hơn, tương tự với Elasticsearch và Apache Lucene.
Đã có khá nhiều bài viết ở viblo nói về khả năng tìm kiếm của Elasticsearch, chủ yếu xoay quay inverted index, analyzer, tf/idf... bạn đọc có thể tham khảo để có cái nhìn rõ hơn về thuật toán. Bài việt này sẽ không nhằm tới thuật toán bên trong Elasticsearch hay Apache Lucene mà về kiến trúc của Elasticsearch.
Kiến trúc của Elasticsearch
Như trên đã nói, một trong những điểm mạnh của Elasticsearch nằm ở tính phân tán và khả năng mở rộng tuyệt vời của nó. Cụ thể hơn, Elasticsearch cho phép bạn mở rộng server theo chiều ngang một cách đơn giản, không có bất cứ thay đổi gì ở phía ứng dụng, cũng gần như không tốn chút nỗ lực nào. Hãy thử so sánh với MySQL khi việc đổi từ 1 server thành 2 server chạy master-slave cũng có thể khiến code của bạn thay đổi như thế nào và tốn công sức thiết lập ra sao.
Vậy điều gì làm cho Elasticsearch có thể mở rộng dễ dàng như vậy? Trước tiên, chúng ta cùng tìm hiểu kiến trúc của Elasticsearch.
Node
Một server Elasticsearch, trung tâm hoạt động của Elasticsearch. Lưu trữ toàn bộ dữ liệu để có thể thực hiện công việc lưu trữ và tìm kiếm.
Cluster
Tập hợp các nodes hoạt động cùng với nhau, chia sẽ cùng thuộc tính cluster.name. Mỗi cluster có một node chính (master), được lựa chọn một cách tự động và có thể thay thế nếu sự cố xảy ra. Một cluster có thể gồm 1 hoặc nhiều nodes. Các nodes có thể hoạt động trên cùng 1 server với mục đích test. Tuy nhiên trong thực tế vận hành, một cluster sẽ gồm nhiều nodes hoạt động trên các server khác nhau để đảm bảo nếu 1 server gặp sự cố thì server khác (node khác) có thể hoạt động đầy đủ chức năng so với khi có 2 servers. Các node có thể tìm thấy nhau để hoạt động trên cùng 1 cluster qua giao thức unicast. Bạn có thể tham khảo config ở đây.
Shard
Mỗi node sẽ gồm nhiều shard là các đối tượng của Lucene. Shard hoạt động ở mức thấp nhất, đóng vai trò lưu trữ dữ liệu. Chúng ta gần như không bao giờ làm việc trực tiếp với shard, Elasticsearch quản lý toàn bộ giao tiếp với shard, tự động thay đổi khi cần thiết. Shard có hai loại là primary shard và replica shard.
Primary Shard
Nếu hình dung quan hệ master-slave như MySQL thì primary shard là master. Dữ liệu được lưu tại 1 primary shard, được đánh index ở đây trước khi chuyển đến replica shard. Mặc định của Elasticsearch là 5 primary shard cho một index (một index trong Elasticsearch tương đương với một database trong MySQL). Một khi đã khởi tạo index thì bạn không thể thay đổi số lượng primary shard cho nó. (Lý do sẽ được giải thích ở sau).
Replica Shard
Một primary shard có thể không có, hoặc có replica shard. Mặc định Elasticsearch là 1 replica shard trên một primary shard. Vai trò của replica shard cũng giống như slave trong MySQL, đảm bảo khi primary shard có sự cố thì dữ liệu vẫn toàn vẹn và thay thế được primary shard, đồng thời tăng tốc độ đọc vì replica shard có thể là nhiều hơn 1. Trong quá trình hoạt động, bạn được thay thế số lượng replica shard một cách thoải mái (không như primary shard).
Dưới đây là một mô hình đơn giản cho kiến trúc: cluster-node-shard của Elasticsearch.
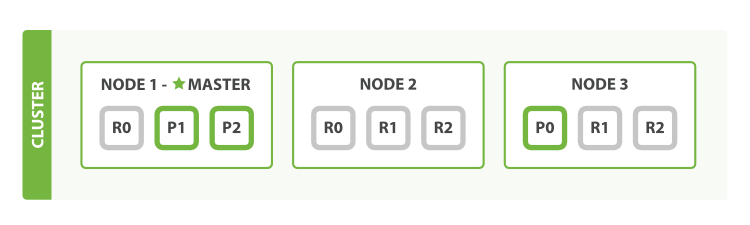
Nguồn: elastic.co
Nhìn vào hình trên chúng ta có thể thấy, dữ liệu được lưu trữ ở cluster với 3 nodes trong đó node 1 là master. Có 3 primary shards, 2 trong số đó được đặt ở node 1, còn lại ở node 3. Mỗi primary shard có 2 replica shard (ví dụ primary shard P0 ở Nod3 thì có replica shard R0 ở node 1 và một shard nữa ở Node 2). Việc sắp đặt vị trí primary shard là ngẫu nhiên, còn các replica shard luôn được đảm bảo là nó không nằm cùng node với primary shard (Tại sao? Tưởng tượng node ngưng hoạt động mà toàn bộ shard ở node đó thì sẽ mất hết sạch dữ liệu @@). Thêm nữa là không bắt buộc primary shard đều nằm ở node master, vì việc phân tán các primary shard giúp phân tán công đoạn ghi dữ liệu, giúp giảm tải cho một node. Việc lựa chọn node cho các thao tác đọc được thực hiện bởi thuật toán Round-robin.
** Lưu ý về cluster health **
Trong Elasticsearch có khái niệm cluster health (tạm gọi là "sức khỏe" của cluster). Có thể kiểm tra dễ dàng với câu lệnh.
GET _cluster/health?pretty
Kết qủa trả về là một chuỗi json có trường status, đây chính là cluster health. Trường này nhận 1 trong 3 gía trị:
RedVẫn còn primary shard chưa hoạt động.YellowTất cả primary shard đã hoạt động, nhưng vẫn còn replica shard chưa hoạt động.GrênTất cả primary shard và replica shard đều hoạt động.
Một thông số khá quan trọng, cho thấy "sức khỏe" của cluster. Tuy nhiên đôi khi hay bị xem thường và mọi người không quan tâm tới nó. Red là trạng thái khá hiếm gặp và tôi chỉ thấy nó trong giai đoạn khởi động, tắt bật node, còn Yellow lại khá phổ biến. Nguyên nhân tại sao? Tại sao primary shard hoạt động nhưng replica shard lại chưa hoạt động?
Thiết lập mặc định của Elasticsearch là 5 primary shards và 1 replica shard/1 primary shard. Điều đó có nghĩa nếu bạn khởi động Elasticsearch lên từ 1 node, thì bạn chỉ có một nơi lưu trữ data. Do nguyên lý cơ bản là replica shard phải nằm khác node với primary shard, Elasticsearch sẽ không biết đặt replica shard ở đâu, và tất cả shard ở node đó sẽ là primary shard.
Cách xử lý vấn đề này khá đơn giản, một là bạn sửa thiết lập mặc định của Elasticsearch đưa số shard về 0 (cách này không hay ho lắm). Hai là bạn bật thêm 1 nodes nữa. Tuy nhiên thêm node trên 1 server thì dễ (không có nhiều ý nghĩa lắm), còn trên nhiều server thì bạn phải động tay config thêm một tẹo. Sau khi config thành công, bạn sẽ có danh sách shard phân chia theo nodes có kiểu như sau (2 nodes, 2 primary shards, 1 replica / 1 primary shard, 1 index tên là blogs)
$ curl -XGET 192.168.33.10:9200/_cat/shards
blogs 1 p STARTED 2 9.4kb 192.168.33.10 node-vagrant
blogs 1 r STARTED 2 6.4kb 192.168.33.20 node-vagrant-2
blogs 0 p STARTED 0 3.2kb 192.168.33.10 node-vagrant
blogs 0 r STARTED 0 3.2kb 192.168.33.20 node-vagrant-2
Elasticsearch lưu trữ dữ liệu phân tán như thế nào
Lưu dữ liệu ở đâu
Gỉa sử chúng ta đã có một sơ đồ cluster như hình trên, với vị trí primary shard, replica shard đã cố định. Vậy với một bản ghi (document) mới, chúng ta sẽ lưu nó ở shard nào ?
Elasticsearch sử dụng công thức sau để chọn shard cho việc lưu trữ.
shard = hash(routing) % number_of_primary_shards
hash là một hàm tính toán cố định của Elasticsearch, routing là 1 đoạn text duy nhất theo document, thường là _id của document đó. number_of_primary_shards là số lượng primary shard của cluster. Gía trị shard này là đi kèm với document, nó được dùng để xác định shard nào sẽ lưu document và cũng dùng để cho routing, vì bạn sẽ tìm document theo id của nó. Đó là lý do chúng ta không thể thay đổi số lượng primary shard, nếu không công thức trên sẽ không cho kết qủa giống như lúc ban đầu.
Qúa trình lưu dữ liệu
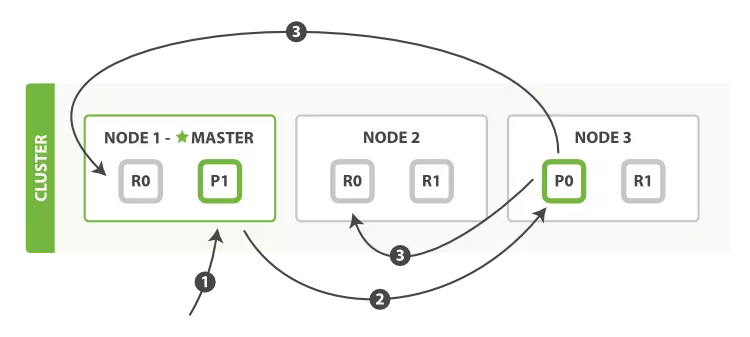
Nguồn: elastic.co
Hình trên đây mô phỏng qúa trình lưu trữ, xóa dữ liệu của Elasticsearch. Có thể chia thành 3 bước.
-
Request được gửi đến node master (Node 1). Tại đây thực hiện tính toán với công thức ở trên để tìm ra primary shard của document sẽ là 0.
-
Sau khi xác định được primary shard là 0, request sẽ được gửi đến node 3, nơi chứa P0.
-
Node 3 thực hiện request và xử lý dữ liệu. Sau khi thành công, nó gửi tiếp request đến các replica shard ở Node 1 và Node 2 để đảm bảo dữ liệu thống nhất giữa các node.
Qúa trình lấy dữ liệu
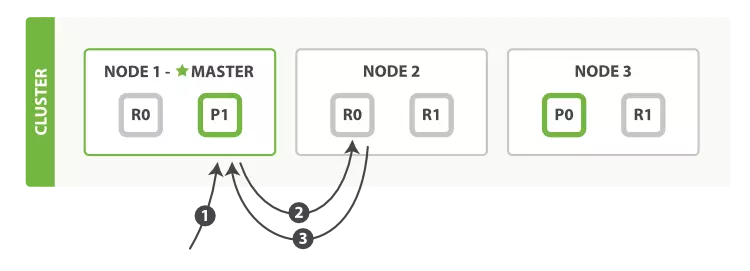
Nguồn: elastic.co
Hình trên mô phỏng qúa trình lấy dữ liệu theo id của document. Có thể chia thành 3 bước.
-
Request được gửi đến node master (Node 1). Tại đây xác định primary shard cho document sẽ là 0.
-
Do tất cả node đều lưu dữ liệu, nên master node sẽ chọn ra 1 node và lấy dữ liệu ở shard số 0. Việc chọn này giúp giảm tập trung vào một node. Thuật toán Round-robin được sử dụng để các shard được chọn khác nhau ở mỗi request. Trong trường hợp này Node 2 được chọn.
-
Replica 0 ở Node 2 trả về kết qủa cho master node.
Elasticsearch tìm kiếm dữ liệu phân tán như thế nào
Ở phần trên chúng ta đã hiểu được cách Elasticserch lấy dữ liệu khi biết ID của document. Tiếp theo chúng ta đến với một qúa trình phức tạp hơn đó là tìm kiếm. Rõ ràng nếu tìm kiếm theo ID thì khỏi phải bàn, tuy nhiên hầu hết sẽ không tìm kiếm theo ID, do vậy qúa trình tổng quát sẽ được thể hiện dưới dạng sau đây.
Query Phase - Công đoạn truy vấn
Chúng ta bắt đầu bằng một query đơn giản, lấy 10 gía trị từ gía trị thứ 100.
GET /_search
{
"from": 100,
"size": 10
}
Elastic thực hiện các công việc sau cho công đoạn truy vấn.
-
Node nhận request (node trung gian) sẽ gửi broadcast request đó đến tất cả các node khác. Tại mỗi node này sẽ chỉ định shard thực hiện công việc tìm kiếm theo yêu cầu. Shard có thể là primary hoặc replica shard.
-
Mỗi shard sẽ thực hiện công việc tìm kiếm, trả về id và score của document. Trong đó score là gía trị dùng để sắp xếp. Danh sách gồm id, score này là một danh sách đã được sắp xếp, mang tính chất cục bộ.
-
Node trung gian sau khi nhận kết qủa trả về từ các node khác sẽ thực hiện công việc sắp xếp toàn cục tất cả các document, dựa theo id và score. Cuối cùng trả ra kết qủa về phía client.
Trường hợp trên, tại mỗi shard sẽ trả về 110 bản ghi (from + size). Nếu có 3 primary shard thì node trung gian sẽ nhận tổng cộng 330 bản ghi. Sau đó nó sẽ thực hiện sắp xếp lại để được 1 danh sách 330 bản ghi đã sắp xếp. Cuối cùng dựa theo yêu cầu mà sẽ trả về document có vị trí từ 100 đến 109.
Fetch phase - Công đoạn lấy dữ liệu
Sau công đoạn truy vấn, node trung gian đã có được danh sách id của bản ghi sắp xếp theo score. Tiếp theo, nó sẽ thực hiện lấy nội dung bản ghi dựa theo id đó. Công đoạn này về cơ bản là giống với Qúa trình lấy dữ liệu đã được nêu ra ở trên.
Nguy hiểm đến từ phân trang qúa sâu (deep pagination)
Công đoạn tìm kiếm của Elasticsearch nhìn chung là gói gọn trong hai bước query (truy vấn) và fetch (lấy dữ liệu). Tuy nhiên, từ cách truy vấn, chúng ta có thể thấy được nguy hiểm của việc phân trang qúa sâu.
Trong mọi trường hợp, Elasticsearch sẽ phải tính toán score cho from + size bản ghi TRÊN MỖI SHARD. Do vậy, số lượng bản ghi cần được cho vào sắp xếp là number_of_shards * (from + size). Gỉa sử bạn cho phép 20 bản ghi 1 trang (size = 20), và phân trang đến trang thứ 1000 (from = 999 * 20 = 19980), khi đó mỗi shard sẽ phải tính toán với 20.000 bản ghi. 5 shard tức là 100.000 bản ghi phải cho vào danh sách. Một con số qúa tốn kém. Do vậy, trong thực tế, chúng ta nên hạn chế việc cho phép người dùng tìm đến trang qúa sâu. Và xét cho cùng, người dùng cũng chỉ thường tìm 1,2 trang đầu là hết. Bổ sung thêm là Elasticsearch vẫn có biện pháp giải quyết cho việc phân trang sâu, sử dụng scroll. Bạn đọc quan tâm có thể tham khảo ở đây.
Tổng kết
Bài viết trên cung cấp cho bạn đọc cái nhìn tương đối chi tiết về kiến trúc phân tán của Elasticsearch, rõ ràng ngoài việc thừa hưởng lợi thế của cỗ máy tìm kiếm Apache Lucene, Elasticsearch cũng tự biến mình thành một công cụ có khả năng hoạt động phân tán rất tốt.
Tài liệu tham khảo
All rights reserved
