[Elasticsearch Series] P1: Giới thiệu về Elasticsearch
Bài đăng này đã không được cập nhật trong 6 năm
Phần 1 sẽ đưa đến một cái nhìn tổng quát về Search engine nói chung và các tính năng của Elasticsearch nói riêng. Nội dung mà bài viết cover:
- Hiểu về search engines và vấn đề mà nó giải quyết
- Elasticsearch vs search engines
- Các tính năng mà Elasticsearch cung cấp
I. Sợt (Search) ở mọi nơi
Ngày nay, chúng ta sử dụng các phương thức tìm kiếm ở bất kì ở đâu, bất kì lúc nào hằng ngày. Ok, tốt thôi, vì nó giúp chúng ta hoàn thành công việc nhanh chóng và dễ dàng. Đơn giản như việc đầu tiên sau khi bạn khởi động máy tính gần như sẽ là mở trình duyệt và lập tức truy cập Facebook hay Google để tìm kiếm bất kì thứ gì bạn muốn, hay là khi bạn shopping online, đọc báo, bạn luôn mong rằng sẽ có một cái seach box (search input) ở đâu đấy để giúp bạn tìm kiếm nhanh chóng thứ bạn cần thay cho việc phải lướt hết từ trang này đến trang khác một cách "crazy". Hoặc là bản thân mình, mỗi lúc ngủ dậy sau một đêm dài thức khuya, mình chỉ muốn có một ô search để tìm ra nhanh chóng bộ quần áo mà mình cần tìm đang ở kinh độ vĩ độ bao nhiêu (yaoming), hoặc ít ra là highlight nó để tìm nó dễ dàng hơn chẳng hạn.

Được rồi, ở trên chúng ta biết được trong cuộc sống hằng ngày, chúng ta không thể thiếu "sợt", nhưng có "sợt" thôi chưa đủ, phải là "quick and smart searching". Mình cần mua một chiếc máy pha cà phê "Espresso" nhưng vì vốn Tiếng Anh hơi hạn hẹp nên mình chỉ nhớ được nó bắt đầu bằng "Esp" phiên bản Việt hóa của nó là cái gì gì "Ích sờ pờ rét sô", lúc này mình muốn search box ngoài chức năng search sẽ có thể đưa ra suggestion cho mình đúng cụm từ phổ biến là "Espresso", ngoài ra mình cũng không muốn kết quả đưa ra được sắp xếp một cách ngẫu nhiên, hi vọng nó sẽ thông minh và đưa ra những kết quả "có liên quan nhất" đầu tiên nếu có thể.
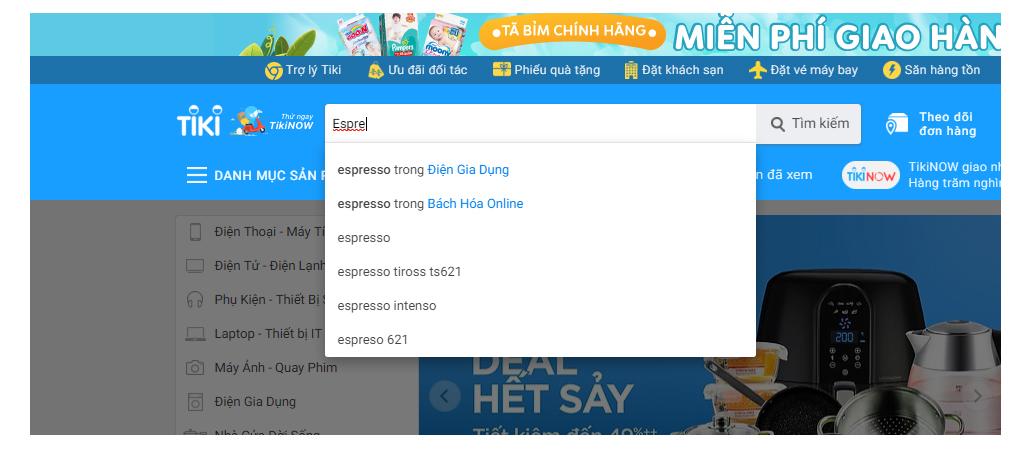
Nhưng thông minh thôi chưa đủ, chúng ta còn quan tâm đến hiệu năng của công cụ search, hay cụ thể là độ "nhanh" của quá trình search, chờ đợi chưa bao giờ là hạnh phúc, có chăng "chờ đợi là hạnh phúc" nó chỉ là một cái gì đó xàm xí trong tình yêu, và chắc chẳng ai muốn phải chờ đợi quá lâu cả(trừ một số thứ đặc biệt  )
Tóm lại, nếu bạn muốn xây dựng một phương thức tìm kiếm, bạn sẽ phải đối mặt với tất cả những vấn đề sau: xây dựng cách tìm kiếm thông minh, trả về những kết quả tìm kiếm liên quan kèm thống kê, và tất nhiên mọi thứ phải được thực hiện thật nhanh, đó cũng là khi Elasticsearch cần được ra đời để giải quyết những vấn đề được đặt ra.
Một chút về Elasticsearch, Elasticsearch là chương trình mã nguồn mở và được xây dựng dựa trên Apache Lucene, một thư viện search engine mã nguồn mở cho phép bạn có thể triển khai xây dựng các chức năng tìm kiếm trong các ứng dụng Java của bạn. Elasticsearch thừa hưởng những chức năng sẵn có từ Lucene và mở rộng thêm để lưu trữ, indexing, tìm kiếm nhanh, dễ dàng hơn và đúng như cái tên nó - "elastic".
Ồ, ứng dụng Java ư, bạn đừng lo vì ứng dụng của bạn không cần bắt buộc phải viết bằng java để có thể tương thích được với Elasticsearch, bạn chỉ cần gửi data qua HTTP dưới dạng JSON để index, tìm kiếm, và quản lí Elasticsearch cluster.
)
Tóm lại, nếu bạn muốn xây dựng một phương thức tìm kiếm, bạn sẽ phải đối mặt với tất cả những vấn đề sau: xây dựng cách tìm kiếm thông minh, trả về những kết quả tìm kiếm liên quan kèm thống kê, và tất nhiên mọi thứ phải được thực hiện thật nhanh, đó cũng là khi Elasticsearch cần được ra đời để giải quyết những vấn đề được đặt ra.
Một chút về Elasticsearch, Elasticsearch là chương trình mã nguồn mở và được xây dựng dựa trên Apache Lucene, một thư viện search engine mã nguồn mở cho phép bạn có thể triển khai xây dựng các chức năng tìm kiếm trong các ứng dụng Java của bạn. Elasticsearch thừa hưởng những chức năng sẵn có từ Lucene và mở rộng thêm để lưu trữ, indexing, tìm kiếm nhanh, dễ dàng hơn và đúng như cái tên nó - "elastic".
Ồ, ứng dụng Java ư, bạn đừng lo vì ứng dụng của bạn không cần bắt buộc phải viết bằng java để có thể tương thích được với Elasticsearch, bạn chỉ cần gửi data qua HTTP dưới dạng JSON để index, tìm kiếm, và quản lí Elasticsearch cluster.
II. Get your hand dirty - Giải quyết vấn đề tìm kiếm với Elasticsearch
Để tiếp cận một cách dễ dàng hơn với cách mà Elasticsearch làm việc, thay vì tìm kiểu những dòng định nghĩa vô hồn khó hiểu gây buồn ngủ, chúng ta sẽ áp dụng nó vào những ví dụ thực tế. OK, Tưởng tưởng bạn là chủ của một blog quản lí các bài viết (post). Đầu tiên, từ cơ bản nhất nhé, việc của bạn là xây dựng tính năng tìm kiếm theo từ khóa. Ví dụ, nếu người dùng tìm kiếm từ "cà phê", điều mà hệ thống của bạn nên làm là show ra tất cả các bài viết (post) có bao gồm từ trên. Tất nhiên điều này quá đỗi cơ bản, nhưng một feature tìm kiếm mạnh mẽ không thể dùng lại ở đó, bạn cần nhiều hơn đó, rằng bạn phải: hiển thị kết quả nhanh chóng và theo thứ tự liên quan, ví dụ như những bài viết có số lượng từ "cà phê" chứa trong đó nhiều nhất thì phải được show ở đầu tiên trong danh sách kết quả chẳng hạn,etc. Và thêm nữa, thật tuyệt nếu có thể suggest user nếu họ không biết chính xác từ mà họ muốn tìm kiếm, hoặc là có thể nhận biết được lỗi sai chính tả, cung cấp các gợi ý hay phân loại kết quả theo từng loại.
1. Tìm kiếm nhanh chóng
Nếu số lượng bài viết trên blog của bạn tăng một cách nhanh chóng và số lượng bài viết trở nên rất lớn, tìm kiếm các bài viết có chứa cụm từ "cà phê" trong số lượng lớn bài viết có thể tốn thời gian, và tất nhiên bạn muốn người dùng có trải nghiệm tốt khi không phải chờ đợi. Đấy là lí do Elasticsearch sẽ là lựa chọn tốt cho bạn, bởi Elasticsearch sử dụng Luence, một thư viện search engine hiệu năng cao, để mặc định đánh index tất cả dữ liệu.
Một chút về index, index là dạng cấu trúc dữ liệu được tạo cùng data để cho phép bạn tìm kiếm nhanh hơn. Bạn có thể thêm index vào các trường trong hầu hết các loại cơ sở dữ liệu bằng nhiều cách. Lucene làm việc đó bằng phương pháp inverted indexing. Cụ thể thế nào chúng ta có thể xem rõ hơn ở ví dụ sau:
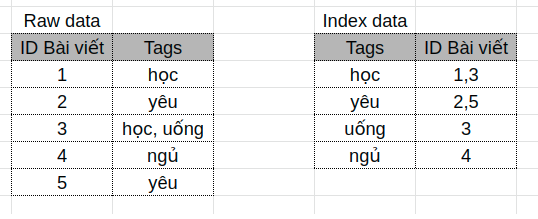
Nếu như bạn cần search những bài viết có chưa từ học chẳng hạn, việc tìm kiếm sẽ dễ dàng và nhanh chóng hơn rất nhiều nếu có index
2. Đảm bảo được kết quả tìm liên quan nhất
Vậy, thế nào là "liên quan". Xét trên keyword là "ngủ", giả sử bạn có 2 bài viết: bài viết thứ nhất về chủ đề "Bí Mật Phương Pháp Ngủ 3h/Ngày Của Donal Trump", còn một bài viết tuy cũng chứa từ khóa "ngủ" nhưng với một chủ đề hết sức không liên quan "Bí mật để duy trì lối sống lành mạnh", rõ ràng trong ví dụ trên, thứ mà người dùng muốn tìm chắc chắn là bài viết thứ nhất, vấn đề đặt ra bây giờ là bằng cách nào để ưu tiên hiển thị bài viết có độ liên quan cao hơn trước những bài viết có độ liên quan thấp hơn. Theo mặc định, thuật toán được sử dụng để tính toán điểm liên quan cho một tài liệu là thuật toán TF-IDF, chúng ta sẽ đi sâu hơn về nó trong những bài viết trong những bài viết sau, ở bài viết này chúng ta sẽ chỉ dừng lại ở định nghĩa cơ bản nó là gì và ý tưởng chủ đạo của thuật toán là gì: TF-IDF là viết tắt của term frequency–inverse document frequency, đó cũng chính là hai yếu tố ảnh hưởng đến điểm liên quan:
- Tần suất xuất hiện (Term frequency): Tần suất xuất hiện càng nhiều, điểm số liên quan càng cao.
- Tần số tài liệu nghịch đảo (Inverse document frequency): Tần số nghịch của 1 từ trong tập văn bản, chỉ số này giúp đánh giá tầm quan trọng của một từ . Khi tính toán TF , tất cả các từ được coi như có độ quan trọng bằng nhau. Nhưng một số từ như “is”, “of” và “that” thường xuất hiện rất nhiều lần nhưng độ quan trọng là không cao. Như thế chúng ta cần giảm độ quan trọng của những từ này xuống. Bạn cũng có thể tùy biến điểm liên quan phù hợp với thứ mà bạn cần nhờ vào việc Elasticsearch cung cấp rất nhiều tính năng dựng sẵn.
3. Tìm kiếm thông minh và linh hoạt
Với việc sử dụng Elasticsearch, bạn có các tùy chọn để làm cho việc tìm kiếm linh hoạt và thông minh hơn. Các tùy chọn này xử lí khi người dùng nhập sai lỗi chính tả hoặc sử dụng từ đồng nghĩa/gần nghĩa với những gì mà bạn lưu trữ.
- Xử lí lỗi nhập keywword sai chính tả: Bạn có thể cài đặt Elasticsearch để có thể xử lí tìm kiếm các biến thể thay vì chỉ tìm kiểm các kết quả khớp chính xác. Một câu truy vấn mờ có thể được sử dụng để tìm kiếm từ "yêi" sẽ cho ra kết quả các bài viết về tình yêu. Chúng ta sẽ tìm hiểu sâu hơn về nó ở các bài viết sau.
- Hỗ trợ tìm kiếm các từ họ hàng, từ đồng nghĩa
- Suggest cho các keyword: Khi người dùng bắt đầu nhập, bạn có thể giúp suggest cho họ các tìm kiếm phổ biến và kết quả phổ biến. Bạn có thể sử dụng các đề xuất để dự đoán các tìm kiếm của họ khi họ nhập, giống như hầu hết các công cụ tìm kiếm trên web. Bạn cũng có thể hiển thị kết quả phổ biến khi họ nhập, sử dụng các loại truy vấn đặc biệt khớp với tiền tố hoặc biểu thức thông thường.
Bài viết tham khảo từ cuốn sách Elasticsearch In Action (Matthew Lee Hinman and Radu Gheorghe)
All rights reserved
