
Deep Learning và bài toán ước lượng mức độ thiệt hại sau thảm họa dựa trên ảnh vệ tinh
Bài đăng này đã không được cập nhật trong 6 năm
Hiện nay, việc biến đổi khí hậu đang dần có nhiều tác động tiêu cực hơn, gây ra những ảnh hưởng và thiệt hại to lớn. Chúng ta đã chứng kiến nhiều sự kiện thời tiết cực đoan ở hầu hết mọi nơi trên thế giới trong thời gian gần đây: bão Idai ở Mozambique, bão Hagibis ở Japan, nóng kỷ lục ở châu Âu, cháy rừng ở California, lũ lụt ở Venice, Ý… và nhiều thiên tai khác. Gần đây nhất có thể kể đến thảm họa cháy rừng ở miền đông nước Úc, thiêu rụi 10.7 triệu hecta, phá hủy trên 5 900 công trình xây dựng (bao gồm trên 2 204 ngôi nhà), ….

Câu hỏi đặt ra là chúng ta có thể làm gì để làm giảm tình trạng biến đồi khí hậu hiện nay, để những ảnh hưởng tiêu cực mà nó gây ra sẽ để lại thiệt hại nhỏ nhất có thể. Bạn có thể lên google search với một câu hỏi quen thuộc : Chúng ta cần làm gì để làm giảm biến đổi khí hậu ?
Các câu trả lời sẽ là những việc đơn giản sau:
- Hạn chế sử dụng nhiên liệu hóa thạch
- Bảo vệ tài nguyên rừng
- Tiết kiệm điện, nước
- Làm việc gần nhà
- Ăn uống thông minh, tăng cường rau, hoa quả
- ...
Chỉ những việc làm nhỏ nhặt, chúng ta đã góp phần chung tay bảo vệ môi trường, bảo vệ các sinh vật cũng như chính bản thân chúng ta.
NHƯNG ...
Đây không phải chủ đề chính mà bài viết này nhắm đến. Đứng từ góc nhìn của một người tìm hiểu về các thuật toán, về logic, mong muốn ứng dụng machine learning vào thực tế, chúng ta cần thực hiện một công việc giá trị hơn : Ước lượng mức độ thiệt hại sau thảm họa dựa trên ảnh vệ tinh. Bài viết dưới đây sẽ trình bày về cách tiếp cận bài toán, các kiến trúc mạng học sâu được sử dụng, đánh giá chất lượng mô hình, cũng như có những thông tin tổng quan về các bài toán trong image segmentation.
Let's go
1. Mô tả bài toán
Thực trạng
Ứng phó thảm họa tự nhiên đòi hỏi một sự hiểu biết chính xác về các công trình xây dựng bị hư hại trong một khu vực bị ảnh hưởng. Các chiến lược ứng phó hiện tại yêu cầu đánh giá thiệt hại trực tiếp trong vòng 24-48 giờ sau thảm họa, từ đó đưa ra những hành động kịp thời và hiệu quả. Tuy nhiên, việc ước tính thiệt hại, lập kế hoạch về các tài nguyên cần thiết lại vô cùng khó khăn, tốn kém nhiều công sức và chi phí.

Bài toán ước lượng mức độ thiệt hại do thảm họa gây ra dựa trên ảnh vệ tinh là quá trình cố gắng phân tích, đánh giá, xác định vị trí của các công trình xây dựng trong khu vực, dựa vào hình ảnh trước và sau khi xảy ra thảm họa để đưa ra mức độ thiệt hại của các công trình xây dựng đó, từ đó đưa ra ước tính thiệt hại trên toàn khu vực.
Tuy nhiên việc xem xét những hình ảnh lại này rất tốn thời gian vì nó vẫn thực hiện bằng phương pháp thủ công. Chúng ta cần một nguồn dữ liệu tốt để tối đa hóa hiệu quả của những nỗ lực đó, đặc biệt là ở các nước đang phát triển bị hạn chế về tài nguyên. Hiện tại, quá trình ước lượng này đang rất tốn công do cần có những chuyên gia để tiến hành phân tích dữ liệu từ hình ảnh được cung cấp từ vệ tinh của chính phủ, các tổ chức thương mại để tiến hành đánh giá thiệt hại. Bên cạnh đó, một vấn đề nữa là dữ liệu thu thập được thường bị phân tán, thiếu sót hoặc không đầy đủ.
Đó là khi chúng ta cần nghĩ đến các kiến trúc Deep Learning với mong muốn tự động hóa quá trình này với độ chính xác cao nhất có thể.
Phân tích bài toán
Bây giờ, để ứng dụng được Deep Learning, chúng ta hãy nhìn theo góc nhìn của Deep Learning. Việc bóc tách vấn đề này là vô cùng cần thiết để giải quyết bài toán nào và có một hướng đi rõ ràng cụ thể.
Trước tiên, việc ước lượng mức độ thiệt hại dựa trên ảnh vệ tinh có thể chia nhỏ thành 2 bài toán nhỏ như sau:
- Xác định được vị trí các công trình xây dựng
- So sánh hình ảnh các công trình xây dựng trước và sau khi xảy ra thảm họa, ước tính mức độ thiệt hại

Xác định được vị trí các công trình xây dựng : Trong computer vision, tác vụ này có thể được hiểu như việc phát hiện vật thể (object detection) hoặc phân đoạn hình ảnh (image segmentation). Tuy nhiên, các công trình xây dựng thường có hình dạng khá đa dạng, nên việc áp dụng object detection để tìm ra các khung giới hạn (bounding box) cho các công trình xây dựng có thể sẽ không thực sự đem lại kết quả tốt trong tác vụ này. Vì vậy, chúng ta có một bài toán instance segmentation cần giải quyết ở đây,
So sánh hình ảnh các công trình xây dựng trước và sau khi xảy ra thảm họa, ước tính mức độ thiệt hại : Tác vụ nghe có vẻ giống như phân lớp hình ảnh (image classification), tuy nhiên việc tách ra các hình ảnh về công trình xây dựng sau đó tiến hành phân lớp rất khó để triển khai, cũng như khó để khôi phục hình ảnh ban đầu. Một vấn đề nữa là để có thể tận dụng được bộ trọng số đã “học” được từ tác vụ 1, tác vụ này cũng sẽ được coi như một bài toán instance segmentation. Điểm khác biệt so với bài toán instance segmentation trong tác vụ trước, là trong tác vụ 1, các pixel sẽ được phân lớp nhị phân, còn tác vụ 2, các pixel sẽ được phân lớp đa lớp.
Done, có vẻ mọi thứ đã sáng sủa hơn khá nhiều rồi. Tất cả mọi vấn đề quy về một bài toán duy nhất : IMAGE SEGMENTATION (Nếu chưa biết gì về image segmentation, các bạn có thể đọc một bài viết tổng quan sau đây của tác giả Phạm Đình Khánh trước khi kéo xuống đọc phần tiếp theo: Bài 40 - Image Segmentation ).
2. Dữ liệu
Bộ dữ liệu chúng ta sẽ sử dụng là bộ dữ liệu được cung cấp trong một challenge khá gần đây (nhớ đăng kí thông tin user để có thể download được bộ dữ liệu nha):
xView2: Computer Vision for Building Damage Assessment using satellite imagery of natural disasters
Đây là một challenge khá hay, và thật ra mong muốn output của challenge này chính là output mà mình trình bày trong bài viết này, nên có thể coi đây như một bài trình bày giải pháp cũng được 
Mô tả dữ liệu
Chi tiết về phần mô tả bộ dữ liệu đã được cung cấp trong bài báo: xBD: A Dataset for Assessing Building Damage from Satellite Imagery, nhưng mình sẽ tóm tắt một số điểm đáng chú ý sau:
- Bộ dữ liệu lấy nguồn từ Maxar/DigitalGlobe Open Data Program, một chương trình cung cấp hình ảnh về các sự kiện khủng hoảng lớn.
- xBD là bộ dữ liệu đánh giá thiệt hại cho công trình xây dựng lớn nhất cho đến nay, cung cấp dữ liệu về 8 loại thảm họa khác nhau trải rộng trên lãnh thổ của 15 quốc gia và có diện tích trên 45.362 km2.
- xBD đồng thời giới thiệu một thang đo thiệt hại chung để dán nhãn cho thiệt hại của 850.736 công trình xây dựng dựa trên ảnh vệ tinh.
- xBD được tạo ra để đáp ứng nhu cầu cần thiết về các vấn đề liên quan đến Ứng phó thảm họa và hỗ trợ nhân đạo (humanitarian assistance and disaster response - HADR).
- Một số đặc điểm của xBD :
- Phân tách cách mức độ thiệt hại theo từng cấp độ (không đơn giản là thiệt hại - không thiệt hại).
- Độ phân giải đủ cao và độ chân thực để đảm bảo tốt nhất cho các tác vụ phân tích hình ảnh.
- Dữ liệu chứa thông tin về nhiều loại thảm họa khác nhau. Sự đa dạng này giúp các tác vụ phân tích đánh giá sát với thực tế hơn.
- Bên cạnh tính đa dạng về thảm họa, bộ dữ liệu còn đa dạng về các công trình xây dựng được annotate: từ kích cỡ, mật độ xây dựng, ...
- ...
 Xem xét một chút về nhãn được annotated,
Label được cung cấp dưới dạng file json, bao gồm thông tin về 2 phần chính :
Xem xét một chút về nhãn được annotated,
Label được cung cấp dưới dạng file json, bao gồm thông tin về 2 phần chính :
- feature : chứa thông tin về vị trí các công trình xây dựng và các mức độ thiệt hại, vị trí được cung cấp dưới 2 hình thức : dựa trên kinh độ - vĩ độ và dựa trên tọa độ x-y ứng với các điểm ảnh.
- metadata : bổ sung thêm một số thông tin mô tả về dữ liệu, bao gồm : sensor - cảm biến sử dụng, capture date - ngày chụp, disaster - tên thảm họa, disaster type - loại thảm họa, ...
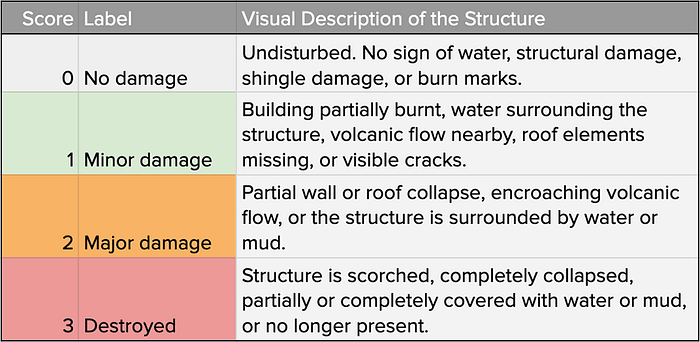
Các bạn có thể quan sát hình bên dưới để hiểu thêm về label. Với mỗi màu sắc khác nhau, đại diện cho một cấp độ bị phá hủy khác nhau sau khi thảm họa xảy ra.
Code để visualize
import json
from PIL import Image, ImageDraw
from IPython.display import display
from shapely import wkt
def show_polygons(img_path, json_path):
with open(json_path, 'r', encoding='utf-8') as image_json_file:
image_json = json.load(image_json_file)
coords = image_json['features']['xy']
polygons = []
if(len(coords) != 0):
for coord in coords:
if 'subtype' in coord['properties']:
damage = coord['properties']['subtype']
else:
damage = 'no-damage'
polygons.append((damage, wkt.loads(coord['wkt'])))
img = Image.open(img_path)
draw = ImageDraw.Draw(img, 'RGBA')
damage_dict = {
"no-damage": (0, 255, 0, 125),
"minor-damage": (255, 255, 0, 125),
"major-damage": (255, 128, 0, 125),
"destroyed": (255, 0, 0, 125),
"un-classified": (0, 255, 0, 125)
}
for damage, polygon in polygons:
x,y = polygon.exterior.coords.xy
coords = list(zip(x,y))
draw.polygon(coords, damage_dict[damage])
del draw
return img

Ngoài lề một chút, khi các bạn vào trang download của xView2 để down bộ dữ liệu về, các bạn sẽ thấy, bên cạnh 2 bộ train, test khá lớn (bộ train với 8.4 GB data và bộ test với 2.7 GB), thì còn một bộ dữ liệu nữa được cung cấp là bộ dữ liệu Tier3. Mặc dù là bộ dữ liệu cung cấp thêm, nhưng, Tier3 là có dung lượng gấp đôi cả train - test gộp lại với 18.6 GB  .
.
Vậy chúng ta sử dụng bộ dữ liệu Tier3 như thể nào. Trên mặt lí thuyết, bộ dữ liệu này được cung cấp thêm để được gộp với tập train giúp cung cấp thêm dữ liệu cho huấn luyện mô hình, tuy nhiên, trong trường hợp của mình, với 1 cái GPU đơn lẻ, có thể coi là khá yếu để train toàn bộ lượng dữ liệu này. Do đó, ở đây, mình sẽ thay tập tier3 thay cho tập Test, để đánh giá kết quả mô hình. Vì tập "test" không có nhãn + challenge đã kết thúc, nên có đánh giá được trên tập "test" đâu 
EDA
Tiến hành khảo sát qua một chút về dữ liệu, chúng ta có một vài nhận xét như sau (thực tế việc khảo sát này cũng đã được nhắc đến trong paper mô tả bộ dữ liệu)
- Tập train chứa 5598 hình ảnh RGBA, trong đó có 2799 hình ảnh trước khi xảy ra thảm họa và 2799 hình ảnh sau khi xảy ra thảm họa
- Tương ứng là 2799 nhãn của hình ảnh trước thảm họa và 2799 nhãn của hình ảnh sau thảm họa
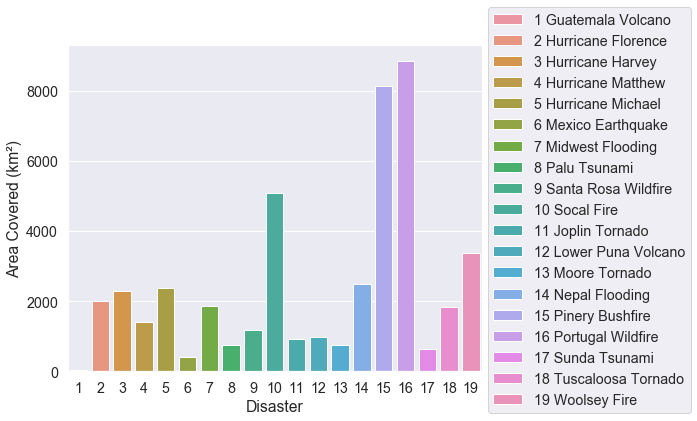
- Thống kê tổng diện tích ảnh hưởng của từng thảm họa, ta có thể thấy các thảm họa khác nhau gây ra độ ảnh hưởng trên từng khu vực cũng là khác nhau. Ảnh hưởng diện tích lớn nhất có thể kể đến cháy rừng ở Bồ Đào Nha và cháy rừng ở Pinery (cháy rừng luôn gây ra những ảnh hưởng trên khu vực lớn nhỉ, vụ cháy ở Úc cũng vậy - pray for Australia). Trong khi đó, có những thảm họa ảnh hưởng khu vực nhỏ hơn nhiều (chỉ bằng 1/20 so với các thảm họa khác) như động đất ở Mexico và sóng thần ở Palu.
- Thống kê tổng số tổng số công trình xây dựng bị ảnh hưởng trong từng thảm họa. Tiếp tục là những ảnh hưởng khác nhau. Một điểm đáng chú ý ở đây là 2 thảm họa có diện tích ảnh hưởng nhỏ nhất theo thống kê trước, thì ở thống kê này, số lượng các công trình mà nó thảm họa là đứng top đầu, khi lần lượt đều ảnh hưởng đến hơn 100000 công trình xây dựng.
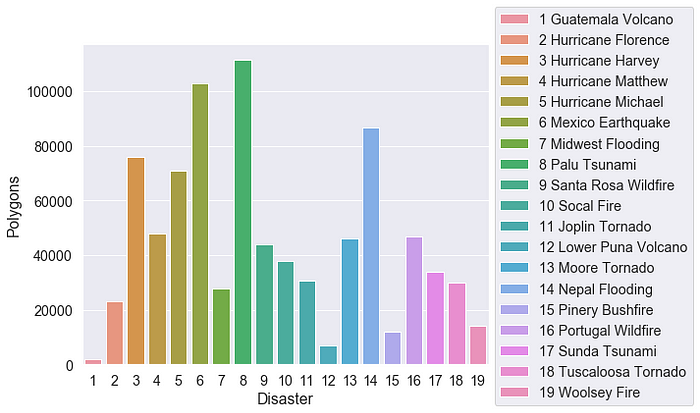
- Thổng kê tổng số công trình bị xây dựng theo từng cấp độ thiệt hại. Ta có thể thấy, có một sự imbalance khá lớn ở đây. Hầu hết các công trình xây dựng đều không bị ảnh hưởng sau thảm họa. Xét về mặt nhân đạo, đây là tin vui vì thiệt hại sau thảm họa là không đáng kể. Thế nhưng, việc của chúng ta là xử lí dữ liệu, tìm ra các mức độ thiệt hại nặng hơn để kịp thời xử lí mới là mục tiêu hàng đầu. Nên là, việc imbalance data này lại gây ra một khó khăn không nhỏ trong quá trình xử lí.

- Một số khó khăn khác trong quá trình xử lí có thể kể đến như sau:
- Các hình ảnh trước và sau thảm họa được chụp ở các góc khác nhau, khiến cho việc xử lí bài toán trở nên khó khăn hơn.
- Một số công trình xây dựng nằm trong khu vực đông dân cư, trong khi những công trình khác lại đứng tự do. Chúng cũng có kích thước khác nhau, từ những túp lều đơn giản cho đến các trung tâm mua sắm lớn, rất khó để tìm ra được điểm tương đồng giữa những công trình này.
Tiền xử lí
Trước tiên, để áp dụng Image Segmentation thì label không thể cứ để ở dạng json được rồi. Do đó, chúng ta tiến hành tạo ra các ảnh mask tương ứng với từng file json, với quy ước sau
Với các điểm ảnh trong ảnh mask được sinh ra, có các giá trị ứng với các điều kiện sau :
- "no-damage": 1,
- "minor-damage": 2,
- "major-damage": 3,
- "destroyed": 4,
- "un-classified": 1
- "background ": 0
Code sinh ảnh mask đổi với ảnh trước thảm họa
import cv2
from cv2 import fillPoly
from shapely import wkt
import numpy as np
from shapely.geometry import mapping
def generate_localization_polygon(json_path, out_dir):
os.makedirs(out_dir, exist_ok=True)
with open(json_path, "r") as f:
annotations = json.load(f)
h = annotations["metadata"]["height"]
w = annotations["metadata"]["width"]
mask_img = np.zeros((h, w), np.uint8)
out_filename = os.path.splitext(os.path.basename(json_path))[0] + ".png"
for feat in annotations['features']['xy']:
feat_shape = wkt.loads(feat['wkt'])
coords = list(mapping(feat_shape)['coordinates'][0])
fillPoly(mask_img, [np.array(coords, np.int32)], (1))
cv2.imwrite(os.path.join(out_dir, out_filename), mask_img)
def generate_damage_polygon(json_path, out_dir):
os.makedirs(out_dir, exist_ok=True)
with open(json_path, "r") as f:
annotations = json.load(f)
h = annotations["metadata"]["height"]
w = annotations["metadata"]["width"]
mask_img = np.zeros((h, w), np.uint8)
damage_dict = {
"no-damage": 1,
"minor-damage": 2,
"major-damage": 3,
"destroyed": 4,
"un-classified": 1
}
out_filename = os.path.splitext(os.path.basename(json_path))[0] + ".png"
for feat in annotations['features']['xy']:
feat_shape = wkt.loads(feat['wkt'])
coords = list(mapping(feat_shape)['coordinates'][0])
fillPoly(mask_img, [np.array(coords, np.int32)], damage_dict[feat['properties']['subtype']])
cv2.imwrite(os.path.join(out_dir, out_filename), mask_img)
View qua kết quả một chút nào

OK, có vẻ ổn rồi. Tuy nhiên, do có giới thiệu trước đó là mình chỉ có cái GPU không mạnh lắm để sử dụng thôi, thế nên, với mỗi ảnh có độ phân giải 1024*1024 kiểu này có vẻ hơi quá sức với khả năng của bản thân. Thế nên, chúng ta sẽ sử dụng thêm một khâu nhỏ nữa, cắt ảnh. Đúng vậy, là cắt ảnh (chứ không phải crop ảnh). Ở đây, mình tiến hành cắt hình ảnh 1024 * 1024 ban đầu thành 16 ảnh 256 * 256 nhỏ hơn. Tức là bộ dữ liệu train của mình sẽ không phải là 5598 ảnh ban đầu nữa, mà là 5598 * 16 = 89568 ảnh (nhỏ hơn).
Vậy, ý tưởng cắt ảnh ở đây là gì ? Đây là cách mà mình sử dụng
- Đầu tiên, duyệt lần lượt theo chiều ngang và chiều dọc để lấy các điểm mốc (Việc xác định điểm mốc tùy thuộc vào kích thước ảnh mà bạn muốn cắt, cũng như có thể cắt được cả các ảnh overlap nếu muốn - "overlap" )
- Tiếp theo, dựa vào các mốc đã tìm được, tiến hành copy phần ảnh ra và lưu lại vào 1 thư mục mới -- Đây sẽ là thư mục chứa data train chính sau này
- Chú ý : Việc cắt ảnh và lưu ảnh cần đảm bảo tiến hành trên cả ảnh và mask, đặc biệt vẫn phải giữ nguyên được mapping giữa ảnh-mask ban đầu nếu không tất cả sẽ công cốc hết.
import cv2
import os
from os import path, makedirs, listdir
from tqdm import tqd
def start_points(size, split_size, overlap=0):
points = [0]
stride = int(split_size * (1-overlap))
counter = 1
while True:
pt = stride * counter
if pt + split_size >= size:
points.append(size - split_size)
break
else:
points.append(pt)
counter += 1
return points
def split_image_for_train(img_path, out_dir, overlap=0):
out_image_dir = path.join(out_dir, 'images')
os.makedirs(out_image_dir, exist_ok=True)
img = cv2.imread(img_path, cv2.IMREAD_UNCHANGED)
img_h, img_w, _= img.shape
out_mask_dir = path.join(out_dir, 'masks')
os.makedirs(out_mask_dir, exist_ok=True)
mask_path = img_path.replace('images', 'masks')
msk = cv2.imread(mask_path, cv2.IMREAD_UNCHANGED)
msk_h, msk_w = msk.shape
img_name = img_path.split('/')[-1]
msk_name = mask_path.split('/')[-1]
split_width = 256
split_height = 256
X_points = start_points(img_w, split_width, overlap=overlap)
Y_points = start_points(img_h, split_height, overlap=overlap)
count = 0
for i in Y_points:
for j in X_points:
split_img = img[i:i+split_height, j:j+split_width]
# print(os.path.join(out_dir, img_name.replace('.png', '_split_{}.png'.format(count))))
cv2.imwrite(os.path.join(out_image_dir, img_name.replace('.png', '_split_{}.png'.format(count))), split_img, [cv2.IMWRITE_PNG_COMPRESSION, 9])
split_msk = msk[i:i+split_height, j:j+split_width]
cv2.imwrite(os.path.join(out_mask_dir, msk_name.replace('.png', '_split_{}.png'.format(count))), split_msk, [cv2.IMWRITE_PNG_COMPRESSION, 9])
count += 1
 Vậy là tạm xong việc với dữ liệu, chúng ta đến phần tiếp theo: **xây dựng model. **
Vậy là tạm xong việc với dữ liệu, chúng ta đến phần tiếp theo: **xây dựng model. **
3. Model
Mặc dù yêu cầu đưa ra kết quả nhanh để tiến hành các hành động kịp thời cứu chữa sau thảm họa, tuy nhiên, tác vụ mà chúng ta cần giải quyết không phải là yêu cầu real time => Ưu tiên vào chất lượng nhãn dự đoán. Do đó, mình sẽ sử dụng các kiến trúc mạng dựa trên các kiến trúc U-shape để giải quyết bài toán này. Một phần của việc lựa chọn kiến trúc cũng là từ việc tham khảo của 2 repo solution lần lượt đạt giải nhất và giải nhì của xView2 Challenge.
Localization Model
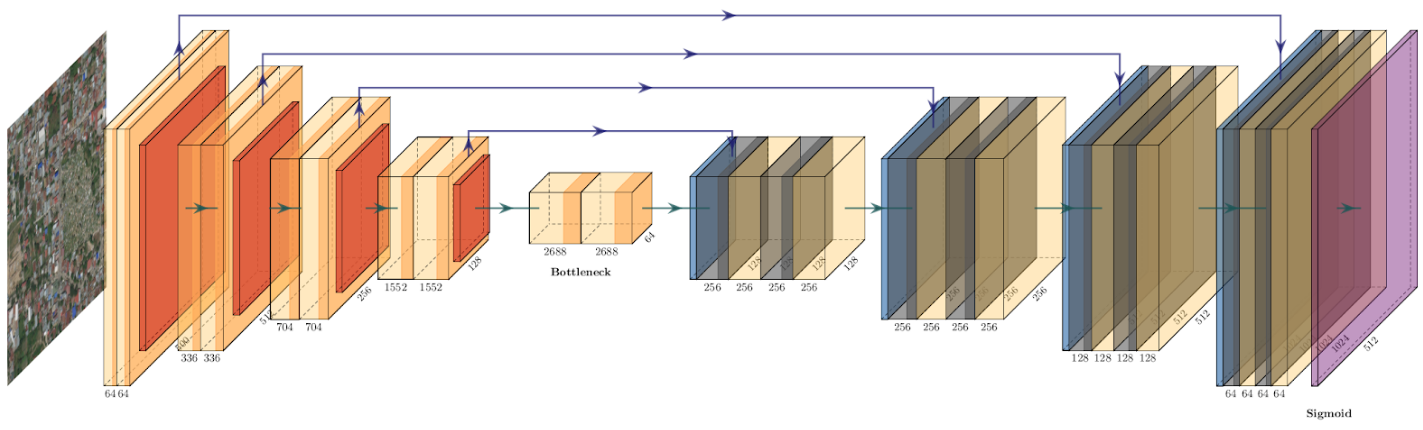
Phía trên là hình ảnh chung về mô hình mà mình sử dụng. Cụ thể, nó chính là mô hình U-net. Về cơ bản Unet là cái mô hình như thế nào thì đã có quá nhiều bài viết trình bày về mô hình này rồi, vậy nên các bạn có thể ghé bài viết sơ sài đầu tiên của mình : U-net : Kiến trúc mạnh mẽ cho Segmentation hoặc đọc lại chính paper U-Net: Convolutional Networks for Biomedical Image Segmentation
Ở đây, mình có tiến hành xây dựng 2 mô hình riêng biệt : U-net (theo đúng kiến trúc gốc trong paper của U-net) và U-net có phần encoder là mạng ResNet34. Có 2 lí do mà mình dùng mạng ResNet34 làm encoder là:
- Phần Encoder của Unet bản chất chính là một mạng Neural tích chập, vậy nên, chúng ta hoàn toàn có thể thay thế nó bằng 1 mạng tích chập khác mà ở đây mình chọn là ResNet - một mạng CNN đã đạt quá nhiều thành công và là được chọn làm backbone của rất nhiều mô hình khác.
- Chọn ResNet34 vì máy mình yếu
 , đơn giản vậy thôi, mình đã thử với nhiều kiến trúc sâu hơn cơ mà nó nặng quá nên thời gian train gây nản cho bản thân mình vì chờ đợi (mình cố gắng đợi để train thêm ResNet50 encoder là nản lắm rồi). Các bạn hoàn toàn có thể sử dụng các mạng CNN khác nha: VGG, DPN, DenseNet, ...
, đơn giản vậy thôi, mình đã thử với nhiều kiến trúc sâu hơn cơ mà nó nặng quá nên thời gian train gây nản cho bản thân mình vì chờ đợi (mình cố gắng đợi để train thêm ResNet50 encoder là nản lắm rồi). Các bạn hoàn toàn có thể sử dụng các mạng CNN khác nha: VGG, DPN, DenseNet, ...
Chắc mô tả sơ thì các bạn cũng hiểu ý tưởng rồi, 2 mô hình mình xây dựng trên framework Pytorch
class Unet_Loc(nn.Module):
def __init__(self, n_channels=3, n_classes=1, bilinear=True):
super(Unet_Loc, self).__init__()
encoder_filters = [64, 128, 256, 512, 1024]
decoder_filters = [1024, 512, 256, 128, 64]
self.inc = DoubleConv(n_channels, encoder_filters[0])
self.down1 = Down(encoder_filters[0], encoder_filters[1])
self.down2 = Down(encoder_filters[1], encoder_filters[2])
self.down3 = Down(encoder_filters[2], encoder_filters[3])
self.down4 = Down(encoder_filters[3], encoder_filters[4])
self.up1 = Up(encoder_filters[3], decoder_filters[0], decoder_filters[1], bilinear)
self.up2 = Up(encoder_filters[2], decoder_filters[1], decoder_filters[2], bilinear)
self.up3 = Up(encoder_filters[1], decoder_filters[2], decoder_filters[3], bilinear)
self.up4 = Up(encoder_filters[0], decoder_filters[3], decoder_filters[4], bilinear)
self.outc = OutConv(decoder_filters[4], n_classes)
self._initialize_weights()
def forward(self, x):
x = self.inc(x)
down1 = self.down1(x)
down2 = self.down2(down1)
down3 = self.down3(down2)
down4 = self.down4(down3)
up1 = self.up1(down4, down3)
up2 = self.up2(up1, down2)
up3 = self.up3(up2, down1)
up4 = self.up4(up3, x)
out = self.outc(up4)
return out
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d) or isinstance(m, nn.Linear):
m.weight.data = nn.init.kaiming_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
Bên kiến trúc mạng U-net lấy ResNet34 làm encoder thì mình có tận dụng thêm pretrained weight của ResNet34 đã được train trước đó để làm tham số khởi tạo cho mô hình. Việc dùng pretrained có thể giúp quá trình train hội tụ nhanh hơn cũng như đạt được các kết quả chính xác hơn khi huấn luyện (Việc khởi tạo tham số luôn quan trọng mà  )
)
class ResNet34_Unet_Loc(nn.Module):
def __init__(self, n_channels=3, n_classes=1, bilinear=True, pretrained=False):
super(ResNet34_Unet_Loc, self).__init__()
encoder_filters = [64, 64, 128, 256, 512]
decoder_filters = [512, 256, 128, 64, 64]
self.inc = DoubleConv(n_channels, encoder_filters[0])
self.up1 = Up(encoder_filters[3], decoder_filters[0], decoder_filters[1], bilinear)
self.up2 = Up(encoder_filters[2], decoder_filters[1], decoder_filters[2], bilinear)
self.up3 = Up(encoder_filters[1], decoder_filters[2], decoder_filters[3], bilinear)
self.up4 = Up(encoder_filters[0], decoder_filters[3], decoder_filters[4], bilinear)
self.outc = OutConv(decoder_filters[4], n_classes)
self._initialize_weights()
encoder = torchvision.models.resnet34(pretrained=pretrained)
self.down1 = nn.Sequential(
encoder.maxpool,
encoder.layer1)
self.down2 = encoder.layer2
self.down3 = encoder.layer3
self.down4 = encoder.layer4
def forward(self, x):
x = self.inc(x)
down1 = self.down1(x)
down2 = self.down2(down1)
down3 = self.down3(down2)
down4 = self.down4(down3)
up1 = self.up1(down4, down3)
up2 = self.up2(up1, down2)
up3 = self.up3(up2, down1)
up4 = self.up4(up3, x)
out = self.outc(up4)
return out
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d) or isinstance(m, nn.Linear):
m.weight.data = nn.init.kaiming_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
Damage Classification Model
Việc ước lượng mức độ thiệt hại sau thảm họa (có thể hiểu là phân lớp mức độ thiệt hại) là tác vụ hơi phức tạp hơn một chút, chúng ta có thể chú ý một sô vấn đề như sau
- Đa lớp : Mỗi pixel sẽ không đơn giản là phân lớp nhị phân như tác vụ localization nữa, thay vào đó là 4 lớp tương ứng 4 cấp độ thảm họa
- Input : Input của kiến trúc mạng không đơn giản chỉ là hình ảnh sau thảm họa hay hình ảnh trước thảm họa mà cần cả 2 hình ảnh này. Nếu chỉ sử dụng hình ảnh sau thảm họa, kết quả thu được sẽ là rất thấp (Đây là lí do chính, trong quá trình xView2 Challenge còn đang diễn ra, rất nhiều kết quả submit đạt được f1-score của localization rất cao, tuy nhiên bên damage classification lại lẹt đẹt 0.1, 0.2 dẫn đến kết quả chung là thấp thảm hại). Để giải quyết vấn đề này, chúng ta có một kiến trúc mạng thường được dùng so sánh giữa 2 hoặc nhiều input: Siamese Network
Kết luận, mình sử dụng kiến trúc có cấu trúc chung như sau:
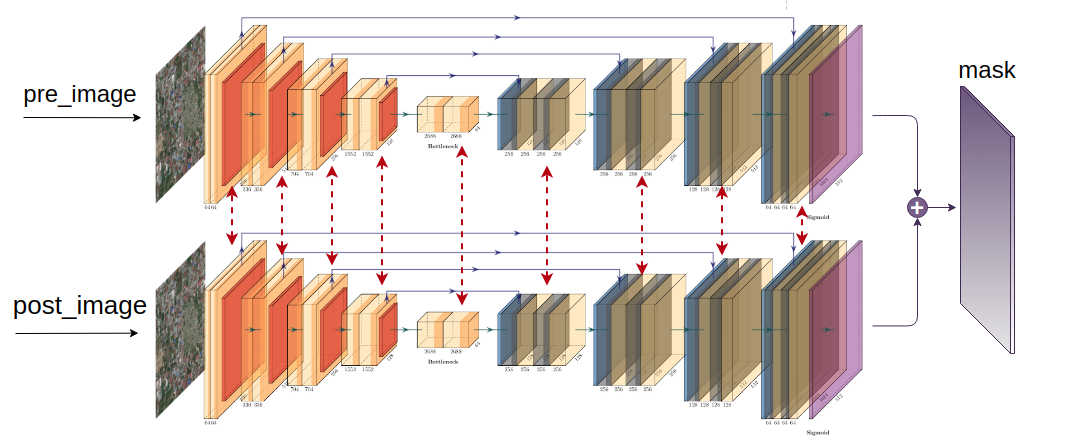
Tận dụng bộ trọng số học được từ tác vụ Localization trước đó, chúng ta xây dựng Siamese Network cho tác vụ Damage Classifiaction này
class UNet_Double(nn.Module):
def __init__(self, n_channels=3, n_classes=5, bilinear=True):
super(UNet_Double, self).__init__()
encoder_filters = [64, 128, 256, 512, 1024]
decoder_filters = [1024, 512, 256, 128, 64]
self.inc = DoubleConv(n_channels, encoder_filters[0])
self.down1 = Down(encoder_filters[0], encoder_filters[1])
self.down2 = Down(encoder_filters[1], encoder_filters[2])
self.down3 = Down(encoder_filters[2], encoder_filters[3])
self.down4 = Down(encoder_filters[3], encoder_filters[4])
self.up1 = Up(encoder_filters[3], decoder_filters[0], decoder_filters[1], bilinear)
self.up2 = Up(encoder_filters[2], decoder_filters[1], decoder_filters[2], bilinear)
self.up3 = Up(encoder_filters[1], decoder_filters[2], decoder_filters[3], bilinear)
self.up4 = Up(encoder_filters[0], decoder_filters[3], decoder_filters[4], bilinear)
self.outc = OutConv(decoder_filters[4]*2, n_classes)
self._initialize_weights()
def forward_1(self, x):
x = self.inc(x)
down1 = self.down1(x)
down2 = self.down2(down1)
down3 = self.down3(down2)
down4 = self.down4(down3)
up1 = self.up1(down4, down3)
up2 = self.up2(up1, down2)
up3 = self.up3(up2, down1)
up4 = self.up4(up3, x)
return up4
def forward(self, x):
x1 = self.forward_1(x[:, :3, :, :])
x2 = self.forward_1(x[:, 3:, :, :])
x = torch.cat([x1, x2], 1)
out = self.outc(x)
return out
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d) or isinstance(m, nn.Linear):
m.weight.data = nn.init.kaiming_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
Tất nhiên, đã có U-net với encoder là ResNet34 bên Localization thì không thể thiếu bên Damage Classification
class ResNet34_Unet_Double(nn.Module):
def __init__(self, n_channels=3, n_classes=5, bilinear=True, pretrained=False):
super(ResNet34_Unet_Double, self).__init__()
encoder_filters = [64, 64, 128, 256, 512]
decoder_filters = [512, 256, 128, 64, 64]
self.inc = DoubleConv(n_channels, encoder_filters[0])
self.up1 = Up(encoder_filters[3], decoder_filters[0], decoder_filters[1], bilinear)
self.up2 = Up(encoder_filters[2], decoder_filters[1], decoder_filters[2], bilinear)
self.up3 = Up(encoder_filters[1], decoder_filters[2], decoder_filters[3], bilinear)
self.up4 = Up(encoder_filters[0], decoder_filters[3], decoder_filters[4], bilinear)
self.outc = OutConv(decoder_filters[4] * 2, n_classes)
self._initialize_weights()
encoder = torchvision.models.resnet34(pretrained=pretrained)
self.down1 = nn.Sequential(
encoder.maxpool,
encoder.layer1)
self.down2 = encoder.layer2
self.down3 = encoder.layer3
self.down4 = encoder.layer4
def forward_1(self, x):
x = self.inc(x)
down1 = self.down1(x)
down2 = self.down2(down1)
down3 = self.down3(down2)
down4 = self.down4(down3)
up1 = self.up1(down4, down3)
up2 = self.up2(up1, down2)
up3 = self.up3(up2, down1)
up4 = self.up4(up3, x)
return up4
def forward(self, x):
x1 = self.forward_1(x[:, :3, :, :])
x2 = self.forward_1(x[:, 3:, :, :])
x = torch.cat([x1, x2], 1)
out = self.outc(x)
return out
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d) or isinstance(m, nn.Linear):
m.weight.data = nn.init.kaiming_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
4. Các kĩ thuật sử dụng
Như phần EDA trước đó, chúng ta đã thấy được sự imbalance khá mạnh trong dữ liệu, đặc biệt, dựa vào kinh nghiệm rút ra từ các kết quả submit trước đó, có vẻ f1_score của 2 lớp minor_damage và major_damage thường rất thấp, kéo theo kết qủa dự đoán chung là không khả quan. Do đó, mình tiến hành một số thao tác sau
Combine weighted loss function
Lí do mình để phần này lên đầu vì nó ảnh hưởng logic xử lí toàn bài toán (cụ thể hơn là phần Damage Classification): Vấn đề Damage Classification ban đầu được nhận định là bài toán Image Segmentation. Mặc dù, nếu nhìn nhận như vậy sẽ giúp việc xử lí bài toán dễ dàng hơn, nhưng đồng thời chúng ta đã coi như mỗi lớp trong từng cấp độ thảm họa là có sức ảnh hưởng như nhau. Nhận định này là sai lầm vì thực tế việc mất cân bằng dữ liệu và bản chất mỗi level khác nhau khiến sức ảnh hưởng của từng level lên kết quả sau cùng là khác nhau. Do đó, thay vì giải quyết 1 bài toán Segmentation với 4 lớp, mình tách ra thành 4 bài toán Segmentation nhị phân.
Sau đó, tiến hành tính loss cho từng level và combine lại có trọng số. Việc này giúp phản ánh tốt hơn về bản chất dữ liệu
Loss = 0.1 * loss_loc + 0.1 * nodamage_loss + 0.3 * minordamage_loss + 0.3 * majordamage_loss + 0.2 * destroyed_loss + 11 * ce_loss
Bonus: Sẵn nói về hàm loss, bên cạnh đánh trọng số loss cho từng level trong damange classification thì trong mỗi hàm loss, mình cũng đồng thời sử dụng cả Dice Loss (đánh giá dựa trên sự chồng chéo ảnh) và Focal Loss (base trên Cross Entropy Loss, sử dụng thêm một hệ số phân rã để điều chỉnh)
Combo Loss = 1* Dice Loss + 10 * Focal Loss
Over sampling
Thao tác kinh điển cho xử lí Imbalance data rồi. Ở đây, do dữ liệu vốn ít rồi, nên áp dụng Under Sampling là không khả thi rồi. Thay vào đó sẽ là Over Sampling. Các bạn có thể hiển Over Sampling đơn giản như sau: Nếu dữ liệu A có 10 điểm dữ liệu, dữ liệu B có 2 điểm dữ liệu, vậy nếu ta lấy 2 điểm dữ liệu B, sau đó Ctr+C và Ctr-V 5 lần , vậy là ta có 10 điểm dữ liệu 2 rồi . Ý tưởng đơn giản vậy thôi. Cụ thể hơn, trong bài toán này, mình tiến hành lấy gấp 2 lần số lượng lớp "Destroyed" và gấp 3 lần số lượng lớp "Minor Damage", "Major Damage".
all_files = []
for train in train_dirs:
for f in listdir(path.join(train, 'images')):
if '_pre_disaster' in f:
all_files.append(path.join(train, 'images', f))
file_classes = []
for fn in all_files:
fl = np.zeros((4,), dtype=bool)
msk1 = cv2.imread(fn.replace('/images/', '/masks/').replace('_pre_disaster', '_post_disaster'), cv2.IMREAD_UNCHANGED)
for c in range(1, 5):
fl[c-1] = c in msk1
file_classes.append(fl)
file_classes = np.asarray(file_classes)
train_idxs = []
for i in train_idxs0:
train_idxs.append(i)
if file_classes[i, 1:].max():
train_idxs.append(i)
if file_classes[i, 1:3].max():
train_idxs.append(i)
train_idxs = np.asarray(train_idxs)
Data Augmentation
Data Augmentation hay tăng cường dữ liệu, phần này thì cũng đã khá là quen thuộc trong các pipe line xử lí rồi. Trong quá trình xử lí, mình có thêm một số augment sau:
import numpy as np
import cv2
#### Augmentations
def shift_image(img, shift_pnt):
M = np.float32([[1, 0, shift_pnt[0]], [0, 1, shift_pnt[1]]])
res = cv2.warpAffine(img, M, (img.shape[1], img.shape[0]), borderMode=cv2.BORDER_REFLECT_101)
return res
def rotate_image(image, angle, scale, rot_pnt):
rot_mat = cv2.getRotationMatrix2D(rot_pnt, angle, scale)
result = cv2.warpAffine(image, rot_mat, (image.shape[1], image.shape[0]), flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REFLECT_101) #INTER_NEAREST
return result
def gauss_noise(img, var=30):
row, col, ch = img.shape
mean = var
sigma = var**0.5
gauss = np.random.normal(mean,sigma,(row,col,ch))
gauss = gauss.reshape(row,col,ch)
gauss = (gauss - np.min(gauss)).astype(np.uint8)
return np.clip(img.astype(np.int32) + gauss, 0, 255).astype('uint8')
def clahe(img, clipLimit=2.0, tileGridSize=(5,5)):
img_yuv = cv2.cvtColor(img, cv2.COLOR_RGB2LAB)
clahe = cv2.createCLAHE(clipLimit=clipLimit, tileGridSize=tileGridSize)
img_yuv[:, :, 0] = clahe.apply(img_yuv[:, :, 0])
img_output = cv2.cvtColor(img_yuv, cv2.COLOR_LAB2RGB)
return img_output
def _blend(img1, img2, alpha):
return np.clip(img1 * alpha + (1 - alpha) * img2, 0, 255).astype('uint8')
_alpha = np.asarray([0.114, 0.587, 0.299]).reshape((1, 1, 3))
def _grayscale(img):
return np.sum(_alpha * img, axis=2, keepdims=True)
def saturation(img, alpha):
gs = _grayscale(img)
return _blend(img, gs, alpha)
def brightness(img, alpha):
gs = np.zeros_like(img)
return _blend(img, gs, alpha)
def contrast(img, alpha):
gs = _grayscale(img)
gs = np.repeat(gs.mean(), 3)
return _blend(img, gs, alpha)
def change_hsv(img, h, s, v):
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
hsv = hsv.astype(int)
hsv[:,:,0] += h
hsv[:,:,0] = np.clip(hsv[:,:,0], 0, 255)
hsv[:,:,1] += s
hsv[:,:,1] = np.clip(hsv[:,:,1], 0, 255)
hsv[:,:,2] += v
hsv[:,:,2] = np.clip(hsv[:,:,2], 0, 255)
hsv = hsv.astype('uint8')
img = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
return img
def shift_channels(img, b_shift, g_shift, r_shift):
img = img.astype(int)
img[:,:,0] += b_shift
img[:,:,0] = np.clip(img[:,:,0], 0, 255)
img[:,:,1] += g_shift
img[:,:,1] = np.clip(img[:,:,1], 0, 255)
img[:,:,2] += r_shift
img[:,:,2] = np.clip(img[:,:,2], 0, 255)
img = img.astype('uint8')
return img
def invert(img):
return 255 - img
def channel_shuffle(img):
ch_arr = [0, 1, 2]
np.random.shuffle(ch_arr)
img = img[..., ch_arr]
return img
Một vài kết quả thu được sau khi augment

Một vài thao tác nhỏ khác
Bên cạnh một số kĩ thuật improve trên, mình cũng đồng thời làm thêm số thao tác nhỏ khác
- Khởi tạo tham số model từ pretrained của ResNet (trong localization) và sử dụng pretrained từ Localization cho Damage Classification
- Đặt checkpoint để lưu lại model tốt nhất
- ...
5. Kết quả training
Dưới đây là một vài thông tin về kết quả lần lượt train 4 mô hình (vất vả ghê). Các bạn có thể tham khảo source code đầy đủ tại github của mình.
U-net
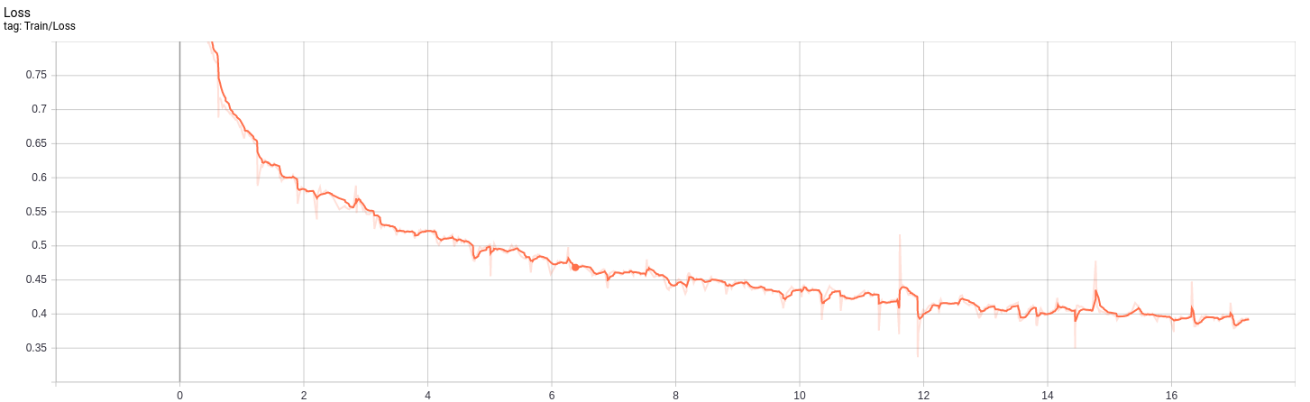
Localization
Lượng dữ liệu train: 35827 ảnh
Số lượng epoch: 55 epoch
Batch size: 16
Thời gian train 1 epoch: 18 phút
Tổng thời gian train: 1037 phút = 17h
Kết quả:
- Dice: Giá trị Dice đạt trung bình 0.7776 sau 55 epoch
- Loss đạt giá trị trung bình 0.3935 sau 55 epoch
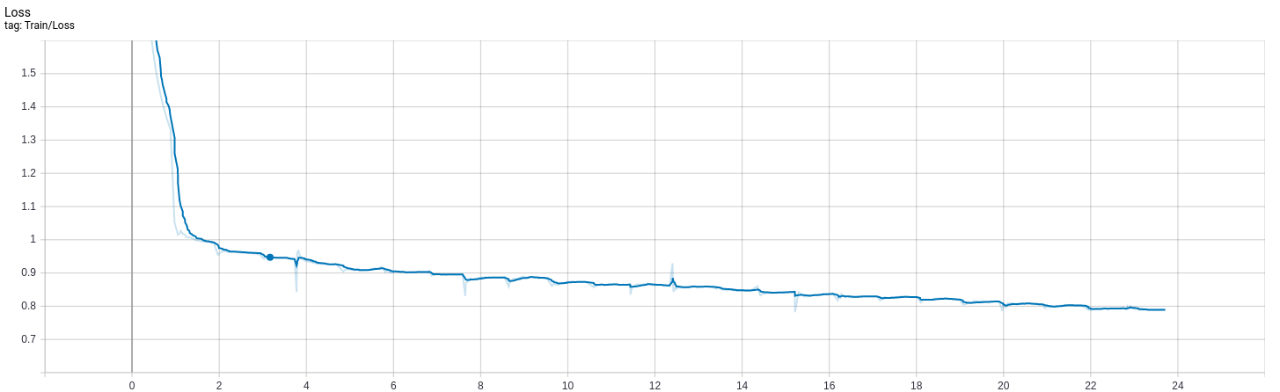
Damage Classification
Lượng dữ liệu train: 71654 ảnh
Số lượng epoch: 25 epoch
Batch size: 8
Thời gian train 1 epoch: 55 phút
Tổng thời gian train: 1427 phút = 24h
Kết quả:
- Dice: Dice đạt giá trị 0.7889 sau 25 epoch
- Loss: Giá trị loss đạt giá trị trung bình 0.7889 sau 25 epoch
U-net với encoder ResNet34
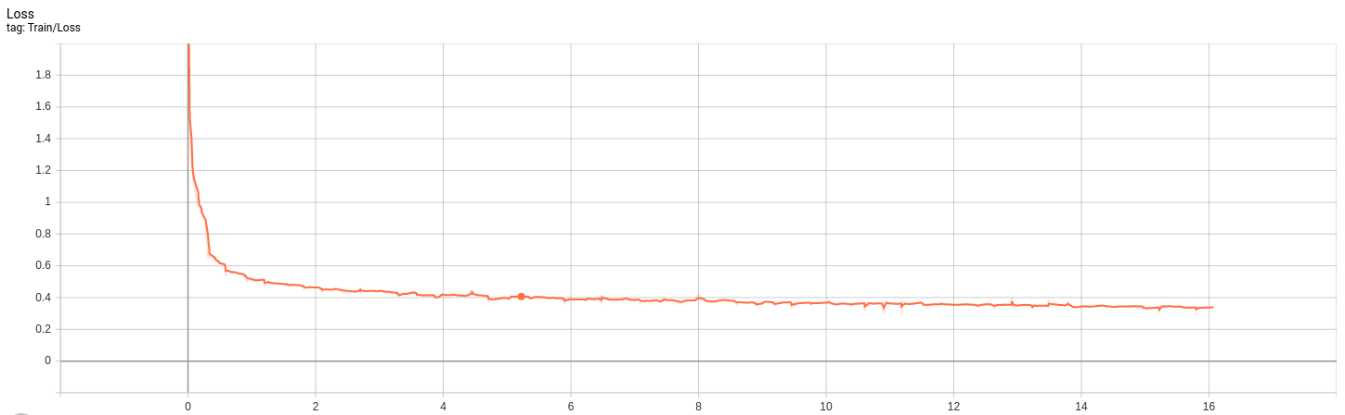
Localization
Lượng dữ liệu train: 35827 ảnh
Số lượng epoch: 55 epoch
Batch size: 16
Thời gian train 1 epoch: 16 phút
Tổng thời gian train: 966 phút = 16h
Kết quả:
- Dice: Giá trị Dice trung bình đạt 0.844 sau 55 epoch
- Loss: Giá trị loss trung bình đạt 0.338 sau 55 epoch
Damage Classification
Lượng dữ liệu train: 71654 ảnh
Số lượng epoch: 19 epoch
Batch size: 8
Thời gian train 1 epoch: 49 phút
Tổng thời gian train: 1015 phút = 17h
Kết quả:
- Dice: Giá trị Dice đạt trung bình là 0.8037 sau 25 epoch
- Loss: Giá trị Loss đạt trung bình 0.74 sau 25 epoch
6. Đánh giá
Sơ lược
Ở đây, chúng ta sẽ sử dụng luôn metric mà challenge đề xuất : F1-score. Một điểm nữa mình có nhắc đến ngay từ đầu là, tính đến thời điểm hiện tại, challenge đã khép lại, vậy nên việc sử dụng tập Test để đánh giá trên đó là bất khả thi. Chúng ta cần sử dụng một bộ dữ liệu khác để đánh giá. Đó chính là tập Tier3.
Tiến hành lấy random ra 1000 ảnh trước thảm hoạ và 1000 ảnh sau thảm họa tương ứng từ tập Tier3, chúng ta có một tập test mới để đánh giá (Nhớ đừng quên sinh ảnh mask)
Một vấn đề là hình ảnh trong tập test mới tạo có kích thước 1024 * 1024, nhưng model chúng ta vừa training lại nhận ảnh đầu vào có kích thước 256 * 256. Vậy nên, cần tạo thêm 1 function để cắt ảnh thành 16 phần, sau khi 16 phần này đi qua model sẽ predict ra 16 ảnh mask, cần thêm 1 function nữa để ghép 16 ảnh mask này với nhau để thu được ảnh mask 1024 * 1024 (Một pha xử lí khá lòng vòng)
### Split image and merge again
def start_points(size, split_size, overlap=0):
points = [0]
stride = int(split_size * (1-overlap))
counter = 1
while True:
pt = stride * counter
if pt + split_size >= size:
points.append(size - split_size)
break
else:
points.append(pt)
counter += 1
return points
def split_image(img, overlap=0):
img_h, img_w = img.shape[0], img.shape[1]
split_width = 256
split_height = 256
X_points = start_points(img_w, split_width, overlap=overlap)
Y_points = start_points(img_h, split_height, overlap=overlap)
count = 0
splited_imgs = []
for i in Y_points:
for j in X_points:
split_img = img[i:i+split_height, j:j+split_width]
splited_imgs.append(split_img)
count += 1
return splited_imgs
def merge_image(splited_imgs, new_img_w=1024, new_img_h=1024, overlap=0):
per_img = splited_imgs[0]
if len(per_img.shape) > 2:
size = [new_img_h, new_img_w, per_img.shape[2]]
else:
size = [new_img_h, new_img_w]
img = np.zeros(size, dtype=np.uint8)
X_points = start_points(new_img_w, per_img.shape[0], overlap=overlap)
Y_points = start_points(new_img_h, per_img.shape[1], overlap=overlap)
count = 0
for i in Y_points:
for j in X_points:
img[i:i+per_img.shape[1], j:j+per_img.shape[0]] = splited_imgs[count]
count += 1
return img
Tiếp theo là việc tận dụng 2 model vừa train U-net và U-net encoder ResNet34, chúng ta sẽ sử dụng kết quả của cả 2 model này, lấy trung bình và xét ngưỡng để quyết định tập submission cuối cùng
from os import path, makedirs, listdir
from multiprocessing import Pool
import numpy as np
from tqdm import tqdm
import timeit
import cv2
from skimage.morphology import square, dilation
pred_cls_folders = ['data/test/predict/pred34_cls', 'data/test/predict/pred-unet_cls']
cls_coefs = [1.0] * 2
pred_loc_folders = ['data/test/predict/pred34_loc', 'data/test/predict/pred-unet_loc']
loc_coefs = [1.0] * 2
sub_folder = 'data/test/predictions'
_thr = [0.38, 0.13, 0.14]
def post_process_image(f):
# localization
loc_preds = []
_i = -1
for d in pred_loc_folders:
_i += 1
msk = cv2.imread(path.join(d, f), cv2.IMREAD_UNCHANGED)
loc_preds.append(msk * loc_coefs[_i])
loc_preds = np.asarray(loc_preds).astype('float').sum(axis=0) / np.sum(loc_coefs) / 255
# classification
cls_preds = []
_i = -1
for d in pred_cls_folders:
_i += 1
msk1 = cv2.imread(path.join(d, f), cv2.IMREAD_UNCHANGED)
msk2 = cv2.imread(path.join(d, f.replace('_part1', '_part2')), cv2.IMREAD_UNCHANGED)
msk = np.concatenate([msk1, msk2[..., 1:]], axis=2)
cls_preds.append(msk * cls_coefs[_i])
cls_preds = np.asarray(cls_preds).astype('float').sum(axis=0) / np.sum(cls_coefs) / 255
msk_dmg = cls_preds[..., 1:].argmax(axis=2) + 1
msk_loc = (1 * ((loc_preds > _thr[0]) | ((loc_preds > _thr[1]) & (msk_dmg > 1) & (msk_dmg < 4)) | ((loc_preds > _thr[2]) & (msk_dmg > 1)))).astype('uint8')
msk_dmg = msk_dmg * msk_loc
_msk = (msk_dmg == 2)
if _msk.sum() > 0:
_msk = dilation(_msk, square(5))
msk_dmg[_msk & msk_dmg == 1] = 2
msk_dmg = msk_dmg.astype('uint8')
cv2.imwrite(path.join(sub_folder, f.replace('_part1.png', '.png')), msk_loc, [cv2.IMWRITE_PNG_COMPRESSION, 9])
cv2.imwrite(path.join(sub_folder, f.replace('_pre_', '_post_').replace('_part1.png', '.png')), msk_dmg, [cv2.IMWRITE_PNG_COMPRESSION, 9])
Kết quả
Chúng ta sẽ sử dụng file xView_scoring đã được cung cấp sẵn trong challenge để đánh giá trên tập test tự tạo (1 phần tập Tier3)
Score = 0.3 * localization_f1 + 0.7 * damage_f1
damage_f1 = hamonic_mean(damage_f1_no_damage, damage_f1_minor_damage, damage_f1_major_damage, damage_f1_destroyed)
Kết quả thu được sau cùng
{
"score": 0.5787483172244847,
"damage_f1": 0.5078617343567443,
"localization_f1": 0.7441503439158792,
"damage_f1_no_damage": 0.8600354976118818,
"damage_f1_minor_damage": 0.3349891820042884,
"damage_f1_major_damage": 0.39467169148504505,
"damage_f1_destroyed": 0.8371617373850139
}
Chúng ta có thể nhìn vào score: 0.58 khá thấp, tuy nhiên, xem xét kĩ một chút thì có thể thấy, các kết quả thành phần đều khá cao, ngoại trừ damage_f1_minor_damage và damage_f1_major_damage là khá thấp, cũng là nguyên nhân chính làm kéo giảm mọi thứ. Đã cố gắng vẫn chưa thể xử lí hoàn toàn vụ imbalance rồi 
6. Kết luận
Trong bài viết này, mình đã trình bày về
- Bài toán ước lượng mức độ thiệt hại sau thảm họa dựa trên ảnh vệ tinh
- xview2 challenge : Computer Vision for Building Damage Assessment using satellite imagery of natural disasters
- EDA dữ liệu + các hướng xử lí
- Giải pháp của bản thân
- Kết quả đạt được
Giải pháp của mình còn nhiều vấn đề liên quan đến cả việc xử lí cũng như mô hình giải quyết. Tuy nhiên đây là một bài toán thực sự hay, vậy nên nếu các bạn có đề xuất cải tiến gì cho mình, các bạn có thể comment dưới bài viết này để chúng ta cùng trao đổi thêm. Hãy like và share cho tác giả vì nó miễn phí
7. Tài liệu tham khảo
- https://github.com/TungBui-wolf/xView2-Building-Damage-Assessment-using-satellite-imagery-of-natural-disasters
- https://github.com/DIUx-xView/xView2_first_place
- https://github.com/DIUx-xView/xView2_second_place
- Image segmentation in 2020: Architectures, Losses, Datasets, and Frameworks
- Image Segmentation - Phạm Đình Khánh
- Losses for Image Segmentation
- và rất nhiều tài liệu tham khảo khác ...
All rights reserved
