Deep Learning in Python
Bài đăng này đã không được cập nhật trong 4 năm
Forward Propagation
Ví dụ về việc giao dịch ngân hàng
Thực hiện việc dự đoán dựa trên các tiêu chí sa
. Số lượng con cái
. Số lượng tài khoản hiện có
Chúng ta sẽ có sơ đồ đầu vào như sau
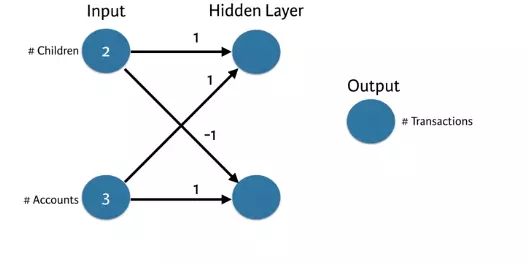 Chúng ta sẽ áp dụng việc tính giá trị cho từng node tiếp theo bằng việc tổng tích của mỗi input đầu vào với trọng số của các điểm input đến node tiếp theo. Và lần lượt chúng ta sẽ có kết quả sau
Chúng ta sẽ áp dụng việc tính giá trị cho từng node tiếp theo bằng việc tổng tích của mỗi input đầu vào với trọng số của các điểm input đến node tiếp theo. Và lần lượt chúng ta sẽ có kết quả sau
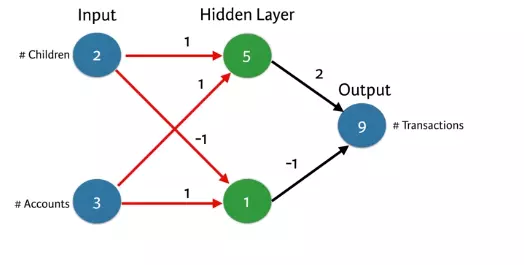 Chúng ta sẽ note lại 4 bước để thực hiện như sau:
. Nhân và cộng các giá trị mỗi output
. Tính tích vô hướng của từng điểm
. Tại một thời điểm chỉ tạo dữ liệu lan truyền cho một điểm
. Kết quả output là điểm dự đoán của điểm dữ liệu
Ta sẽ thực hiện điều này với python như sau:
Chúng ta sẽ note lại 4 bước để thực hiện như sau:
. Nhân và cộng các giá trị mỗi output
. Tính tích vô hướng của từng điểm
. Tại một thời điểm chỉ tạo dữ liệu lan truyền cho một điểm
. Kết quả output là điểm dự đoán của điểm dữ liệu
Ta sẽ thực hiện điều này với python như sau:
import numpy as np
input_data = np.array([2,3])
weights = {"node_0": np.array([1,1]),
"node_1":np.array([-1,1]),
"output":np.array([2,-1])}
node_0_value = (input_data * weights["node_0"]).sum()
node_1_value = (input_data * weights["node_1"]).sum()
hiden_layer_outputs = np.array([node_0_value,node_1_value])
print(hiden_layer_outputs)
output = (hiden_layer_outputs * weights["output"]).sum()
print(output)
Activation functions
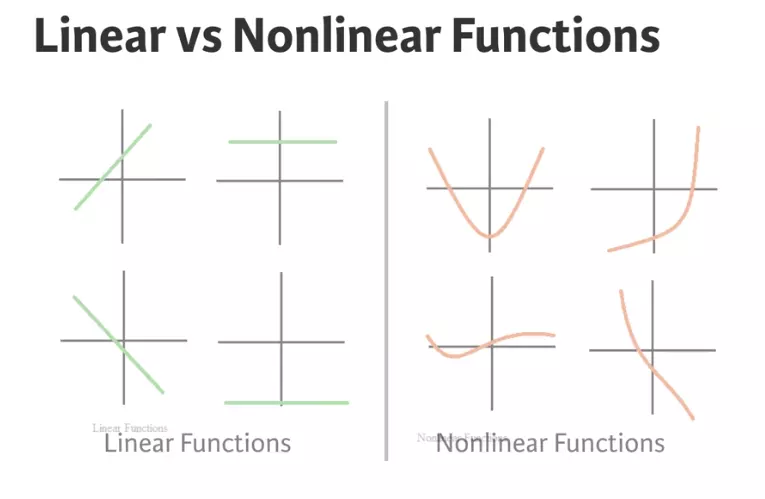
Đây là hàm nhận vector đầu vào, sau đó biến đổi để trả về vector đầu ra. Có nhiều hàm activation như tanh, sigmoid function, hay ReLUs.
Activation function cho phép ghi nhận được kết quả của dạng linear và nonlinear functions.
 Trong bài toán này chúng ta sẽ dùng Relu (Rectified Linear Activation) để cải thiện tiếp về code trước.
Trong bài toán này chúng ta sẽ dùng Relu (Rectified Linear Activation) để cải thiện tiếp về code trước.
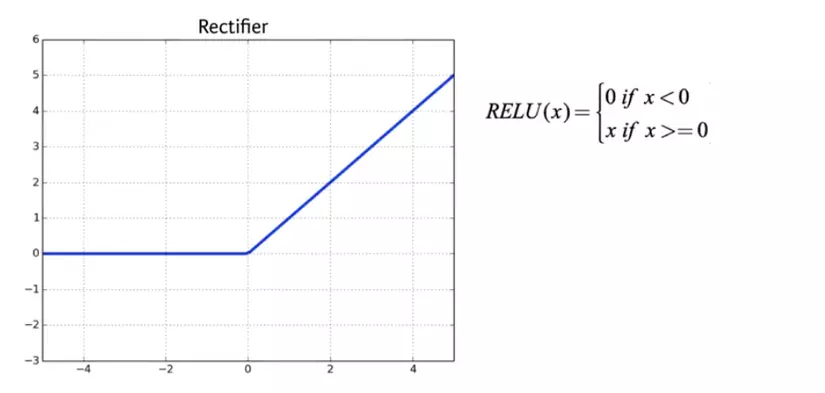 Nhìn hình thì chúng ta hiểu đơn giải RELU(x) nó sẽ trả về 0 khi x<0 và x nếu x>=0. Rất đơn giản
Nhìn hình thì chúng ta hiểu đơn giải RELU(x) nó sẽ trả về 0 khi x<0 và x nếu x>=0. Rất đơn giản
import numpy as np
input_data = np.array([-1,2])
weights = {'node_0': np.array([3,3]),
'node_1':np.array([1,5]),
'output':np.array([2,-1])}
def relu(input):
'''Define your relu activation function here'''
#Calculate the value for the output of the relu function: output
output = max(input, 0)
#Return the value just calculated
return(output)
#Calculate node 0 value: node_0_output
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = relu(node_0_input)
#Calculate node 1 value: node_1_output
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = relu(node_1_input)
#Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
#Calculate model output (do not apply relu)
model_output = (hidden_layer_outputs * weights['output']).sum()
#Print model output
print(model_output)
Applying the network to many observations/rows of data
Tiếp theo chúng ta sẽ viết một function gọi là predict_with_network(), nó sẽ sinh ra các dự đoán cho nhiều quan sát dữ liệu, nó sẽ load lại dữ liệu như là một input data. Cũng như trước đó, weights(trọng số) cũng sẽ được pre-loaded. Như dưới đây
#Define predict_with_network()
def predict_with_network(input_data_row, weights):
# Calculate node 0 value
node_0_input = (input_data_row * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value
node_1_input = (input_data_row * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output
input_to_final_layer = (hidden_layer_outputs * weights['output']).sum()
model_output = relu(input_to_final_layer)
# Return model output
return(model_output)
#Create empty list to store prediction results
results = []
for input_data_row in input_data:
#Append prediction to results
results.append(predict_with_network(input_data_row,weights))
#Print results
print(results)
Deeper Networks
Tiếp theo chúng ta sẽ đi đến việc sẽ có nhiều hơn 1 lớp hidden layers, như các bạn biết để việc phân tích ra dữ liệu thì chúng ta có thể phải xử lí qua nhiều tầng hidden layer trước khi có thể đưa ra dữ liệu output.
Vậy điều quan trọng ở đây là gì..khá đơn giản chúng ta cứ lần lượt tính toán input layer của từng lớp hidden layer sau đó lấy ra được out put của từng node trong hidden layer và xem chúng chính là input của tầng hidden layer tiếp theo
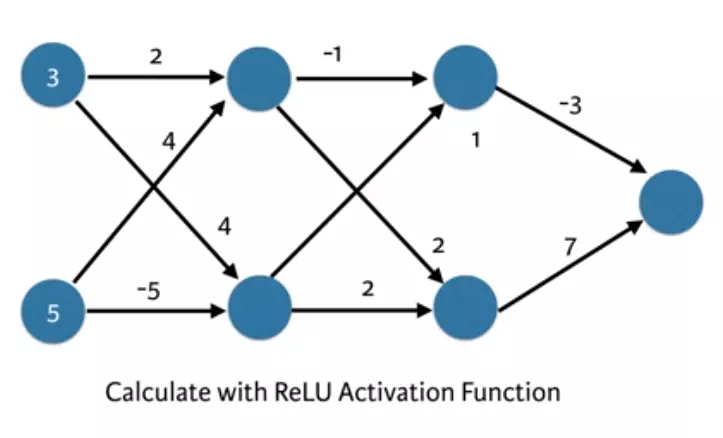 Chúng ta sẽ xử lí thử mô hình trên như thế nào để không phải làm thủ công?
Làm thế nào ta có thể tránh được việc xây dựng và rút trích đặc trưng một cách thủ công? Representation learning hay còn gọi là feature learning là hướng tiếp cận để tự động hóa qúa trình này.
Chúng ta sẽ xử lí thử mô hình trên như thế nào để không phải làm thủ công?
Làm thế nào ta có thể tránh được việc xây dựng và rút trích đặc trưng một cách thủ công? Representation learning hay còn gọi là feature learning là hướng tiếp cận để tự động hóa qúa trình này.
Các phương pháp deep learning hiện đại đã có nhiều thành công trong lĩnh vực này ví dụ như phương pháp autoencoders và restricted Boltzmann machines. Các phương pháp này hoàn toàn tự động hóa qúa trình feature engineering bằng cách unsupervised hay semi-supervised, nhờ vậy mà ta có thể biểu diễn các feature một cách trừu tượng nhất (dạng thu gọn). Đây là hướng tiếp cận tiên tiến nhất và đã có nhiều kết qủa đáng kể trong speech recognition, image classification, object recognition và các lĩnh vực khác.
Representation learning sẽ được hình dung với các điểm sau
. "Deep networks" nội tại xây dựng các đại điện dữ liệu mẫu
. Nó sẽ thay thế một nhu cầu về chức năng kỹ thuật nào đó
. Các lớp tiếp theo sẽ tạo ra các đại điện ngày càng tinh vi, phức tạp của dữ liệu thô ban đầu
Nó giống như khi ta có một input đầu vào là các điểm ảnh, các lớp hidden layer đầu với các thuộc tính ta có thể nhận biết ra được đâu là các đường chéo giao nhau... tiếp theo với các lớp hidden layer phía sau cùng với các thuộc tính như square, location. v.v. kết hợp với nhau chung ta lại có thể tách lọc ra được các node là Face Node hay Car node .v.v.
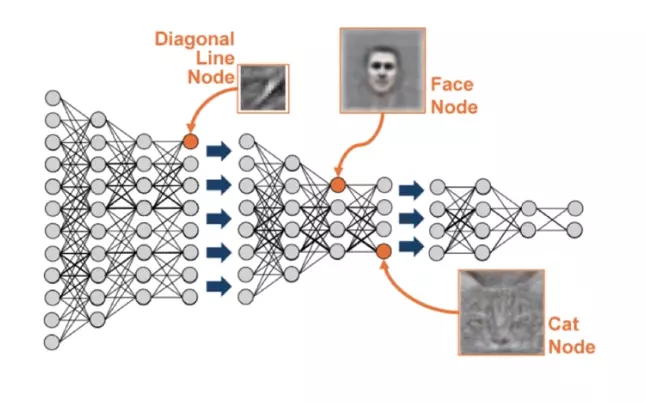 Và chúng ta cần nhớ
Deep learning:
Và chúng ta cần nhớ
Deep learning:
- Chúng ta không cần phải chỉ cho các modeler về cách tương tác. cũng giống như chúng ta không bao giờ phải nói "modeler hãy nhìn vào các đường giao nhau"
- Khi train các model, mạng nổn sẽ lấy các trọng số và tìm các mẫu liên quan để tạo ra các dự đoán tốt hơn.
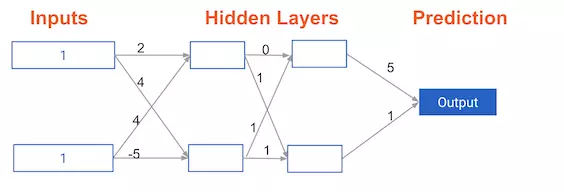 Chúng ta sẽ thử mô tả điều đó với một vài dòng code như sau
Chúng ta sẽ thử mô tả điều đó với một vài dòng code như sau
import numpy as np
input_data = np.array([1,1])
weights = { 'node_0_0': np.array([2,4]),
'node_0_1':np.array([4,-5]),
'node_1_0':np.array([0,1]),
'node_1_1':np.array([1,1]),
'output':np.array([5,1])}
def relu(input):
'''Define your relu activation function here'''
#Calculate the value for the output of the relu function: output
output = max(input, 0)
#Return the value just calculated
return(output)
def get_output(input_layer, layer, index):
node_intput = (input_layer * weights['node_'+str(layer)+'_'+str(index)]).sum()
return(relu(node_intput))
#Put node values into array: hidden_layer_outputs
hidden_layer_0_outputs = np.array([get_output(input_data,0,0), get_output(input_data,0,1)])
hidden_layer_1_outputs = np.array([get_output(hidden_layer_0_outputs,1,0), get_output(hidden_layer_0_outputs,1,1)])
#Calculate model output (do not apply relu)
model_output = (hidden_layer_1_outputs * weights['output']).sum()
#Print model output
print(model_output)
print(relu(model_output))
Bạn có thể thử để xem kết quả như thế nào
All rights reserved
