Đánh giá hiệu năng học máy
Bài đăng này đã không được cập nhật trong 7 năm
Tập dữ liệu dùng để học máy:
- Tập huấn luyện: Được dùng để huấn luyện hệ thống.
- Tập tối ưu: Tùy chọn và được dùng để tối ưu các tham số của hệ thống.
- Tập kiểm thử: Được dùng để đánh gúa hệ thống đã được huấn luyện.
=> Tập huấn luyện càng lớn(*) thì hiệu năng của hệ thống học càng tốt.
=> Tập kiểm thử càng lớn thì việc đánh giá càng chính xác.
Rất khó (ít khi) có thể có được các tập dữ liệu (rất) lớn.
Hiệu năng của hệ thống không chỉ phụ thuộc vào giải thuật học máy mà còn phụ thuộc:
- Class distribution (phân bố lớp)
- Cost of misclassification
- Size of the training set (kích thước của tập huấn luyện)
- Size of the testing set (kích thước tập kiểm thử)
Các phương pháp đánh giá hiệu năng học máy:
- Hold-out
- Stratified sampling
- Repeated hold-out
- Cross validation (k-fold, leave-one-out)
- Bootstrap sampling
1. Hold-out
Toàn bộ tập dữ liệu (data) sẽ được chia thành 2 tập con datatrain và datatest không giao nhau (|datatrain| >>|datatest|).
- Tập huấn luyện datatrain: để huấn luyện hệ thống
- Tập kiểm thử datatest: để đánh giá hiệu năng của hệ thống sau khi đã được huấn luyện Yêu cầu:
- Dữ liệu thuộc tập kiểm thử datatest không được sử dụng trong quá trình huấn luyện hệ thống.
- Dữ liệu thuộc tập huấn luyện datatrain không được sử dụng trong quá trình đánh giá hệ thống sau khi huấn luyện.
Ví dụ: Ta có thể chọn |datatrain| = (2/3).|data| và |data test | = (1/3).|data|
=> Cách đánh giá này phù hợp khi ta bộ dữ liệu (data) có kích thước lớn.
2. Stratified sampling
Được sử dụng khi các tập ví dụ có kích thước nhỏ hoặc không cân xứng (unbalanced datasets).
Ví dụ: có ít, hoặc không có các ví dụ với một số lớp
Mục tiêu: Phân bố lớp (Class distribution) trong tập huấn luyện và tập kiểm thử phải xấp xỉ như trong tập toàn bộ các ví dụ (data)
- Stratified sampling là một phương pháp để cân xứng về phân bố lớp
- Đảm bảo tỉ lệ phân bố lớp trong tập huấn luyện và tập kiểm thử sẽ là xấp xỉ nhau
=> Phương pháp này không áp dụng được cho bài toán học máy dự đoán/hồi quy (vì giá trị đầu ra của hệ thống là một giá trị số, không phải là một nhãn lớp)
3. Repeated hold-out
Đây là phương pháp sẽ áp dụng phương pháp đánh giá Hold-out nhiều lần, để sinh ra các tập huấn luyện và thử nghiệm khác nhau.
Trong mỗi lần lặp, một tỉ lệ nhất định của tập dữ liệu (data) được chọn ngẫu nhiên nhằm tạo nên tập huấn luyện (có thể kết hợp với phương pháp Stratified sampling).
Đối với các giá trị lỗi (hoặc giá trị với các tiêu chí đánh giá khác) ghi nhận trong các bước lặp này được lấy trung bình công để xác định lỗi tổng thể.
=> Tuy nhiên phương pháp này chưa được tốt vì
- Mỗi bước lặp ta lại có một tập kiểm thử khác nhau
- Có một số dữ liệu sẽ được dùng nhiều lần (trùng lặp) trong các tập kiểm thử
4. Cross validation
4.1. k-fold
- Tập dữ liệu (data) được chia thành k tập con không giao nhau (gọi là “fold”) có kích thước xấp xỉ nhau.
- Mỗi lần lặp, một tập con trong k tập sẽ được dùng để làm tập kiểm thử, (k-1) tập còn lại sẽ được sử dụng làm tập huấn luyện.
- k giá trị lỗi (mỗi giá trị tương ứng với mỗi “fold”) sẽ được tính trung bình cộng để thu được giá trị lỗi tổng thể.
Ví dụ: ta có thể chia data thành 10 hoặc 5 folds (k = 10 hoặc k = 5)
Thông thường mỗi tập con (fold) được lấy mẫu phân tầng (xấp xỉ phân bố lớp) trước khi áp dụng quá trình đánh giá Cross validation
=> Phù hợp khi ta có tập dữ liệu data vừa và nhỏ.
4.2. leave-one-out
- Số lượng các nhóm folds bằng kích thước của tập dữ liệu (k = |data|)
- Mỗi nhóm fold chỉ bao gồm 1 ví dụ
- Khai thác tối đa tập dữ liệu ban đầu
- Không có bước lấy mẫu ngẫu nhiên
- Chi phí tính toán cao => Phù hợp khi ta có tập dữ liệu data (rất) nhỏ.
5. Bootstrap sampling
Phương pháp này sử dụng việc lấy mẫu lặp lại để tạo nên tập huấn luyện.
- Giả sử toàn bộ tập data bao gồm n ví dụ
- Lấy mẫu có lặp lại n lần đối với tập data để tạo nên tập huấn luyện datatrain gồm n ví dụ:
- Từ tập data, lấy ngẫu nhiên một ví dụ x (nhưng không loại bỏ x khỏi data)
- Đưa dữ liệu x vào trong tập huấn luyện
- Lặp lại các bước trên n lần, ta có n dữ liệu trong tập datatrain
=> Sử dụng dữ liệu tập datatrain để huấn luyện hệ thống.
=> Sử dụng tất cả các dữ liệu thuộc data nhưng không thuộc tập huấn luyện (datatrain) để tạo nên tập test.
- Xác suất để 1 ví dụ không được chọn vào tập huấn luyện là (1-1/n).
- Xác suất để một ví dụ (sau khi lấy mẫu lặp lại – bootstrap sampling) được đưa vào tập kiểm thử là: (1-1/n)^n => Phù hợp với tập dữ liệu có kích thước (rất) nhỏ
Tập tối ưu (Validation set)
Quá trình học máy (huấn luyện) sẽ được thực hiện gồm 2 giai đoạn:
- Giai đoạn 1: Huấn luyện hệ thống
- Giai đoạn 2: Tối ưu giá trị các tham số của hệ thống
- Tập tối ưu sẽ không có các dữ liệu trùng với tập kiểm thử và tập huấn luyện.
- Tối ưu giúp điều chỉnh tham số và hiệu năng cao hơn
Các tiêu chí để đánh giá
1. Tính chính xác (Accuracy)
Mức độ dự đoán (phân lớp) chính xác của hệ thống (đã được huấn luyện) đối với các ví dụ kiểm chứng (test instances)
2. Tính hiệu quả (Efficiency)
Chi phí về thời gian và tài nguyên (bộ nhớ) cần thiết cho việc huấn luyện và kiểm thử hệ thống
3. Khả năng xử lý nhiễu (Robustness)
Khả năng xử lý (chịu được) của hệ thống đối với các ví dụ nhiễu (lỗi) hoặc thiếu giá trị
4. Khả năng mở rộng (Scalability)
Hiệu năng của hệ thống (vd: tốc độ học/phân loại) thay đổi như thế nào đối với kích thước của tập dữ liệu
5. Khả năng diễn giải (Interpretability)
Mức độ dễ hiểu (đối với người sử dụng) của các kết quả và hoạt động của hệ thống
6. Mức độ phức tạp (Complexity)
Mức độ phức tạp của mô hình hệ thống (hàm mục tiêu) học được
Cách tính chính xác
1. Đối với bài toán phân loại
Giá trị đầu ra của bài toán là một giá trị định danh.
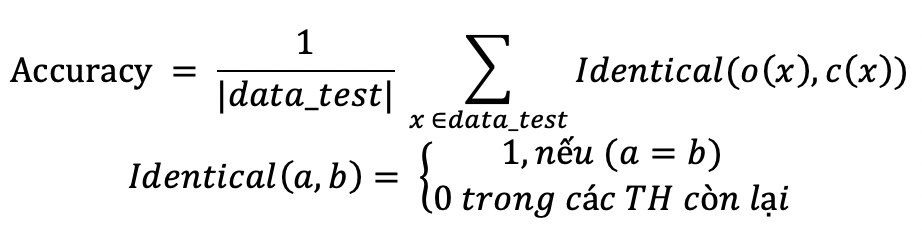
Trong đó:
- x: là một ví dụ trong tập kiểm thử datatest
- o(x): giá trị đầu ra (phân lớp) của hệ thống với dữ liệu x
- c(y): Phân lớp đúng với ví dụ x
2. Đối với bài toán hồi quy (dự đoán)
Giá trị đầu ra của hệ thống là một giá trị số
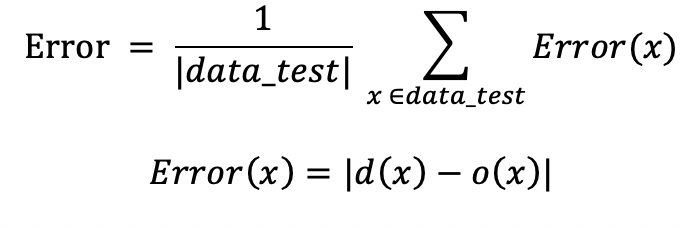
Trong đó:
- o(x) là giá trị đầu ra dự đoán bởi hệ thống với x
- d(x) là giá trị đúng của dữ liệu x
All rights reserved
