
Crawl truyện Conan để copy vào máy đọc sách 😫
Bài đăng này đã không được cập nhật trong 3 năm
Mình là một người thích đọc, sau một thời gian đọc những truyện voz buồn cứ phải gọi là ... như Ranh Giới của rain8x, hay Ngày Hôm Qua Đã Từng của Nguyễn Mon, ..v.v. và hằng hà sa số truyện chữ khác thì mình quyết định chuyển sang đọc truyện tranh (người đời gọi như vậy chứ toàn thấy ae gọi là đọc manga). Thật tình cờ mình cũng có cái máy kindle để đọc sách (ngựa ngựa mua về để đọc sách chứ toàn đọc truyện tranh là chính), down mấy truyện Conan trên mạng (người ta gọi đó là sách lậu) copy vào Kindle ppw4 thì cảm thấy hơi mờ + bị kéo giãn hình ra trông xấu mù, đầu Conan hình tròn nó kéo thành hình cái bánh mì luôn. Là một người thích giữ những gì bản nguyên nhất của truyện, mình đã quyết định đi tìm nguồn truyện Thần chết Conan - à nhầm, Thám tử lừng danh Conan phải vừa đẹp vừa nét vừa bản nguyên như những gì đáng ra nó phải như thế.
Sau một thời gian tìm kiếm thì mình cũng tìm được trang https://thamtu-conan.blogspot.com/ có đầy đủ những gì mình mong muốn. Đọc truyện trên máy tính thì đau mắt nên mình quyết định viết 1 script crawl truyện từ trang này về và đóng gói lại để đọc trên máy Kindle. Và bên dưới đây là câu chuyện mà mình đi ngồi crawl truyện nè.
Viết script
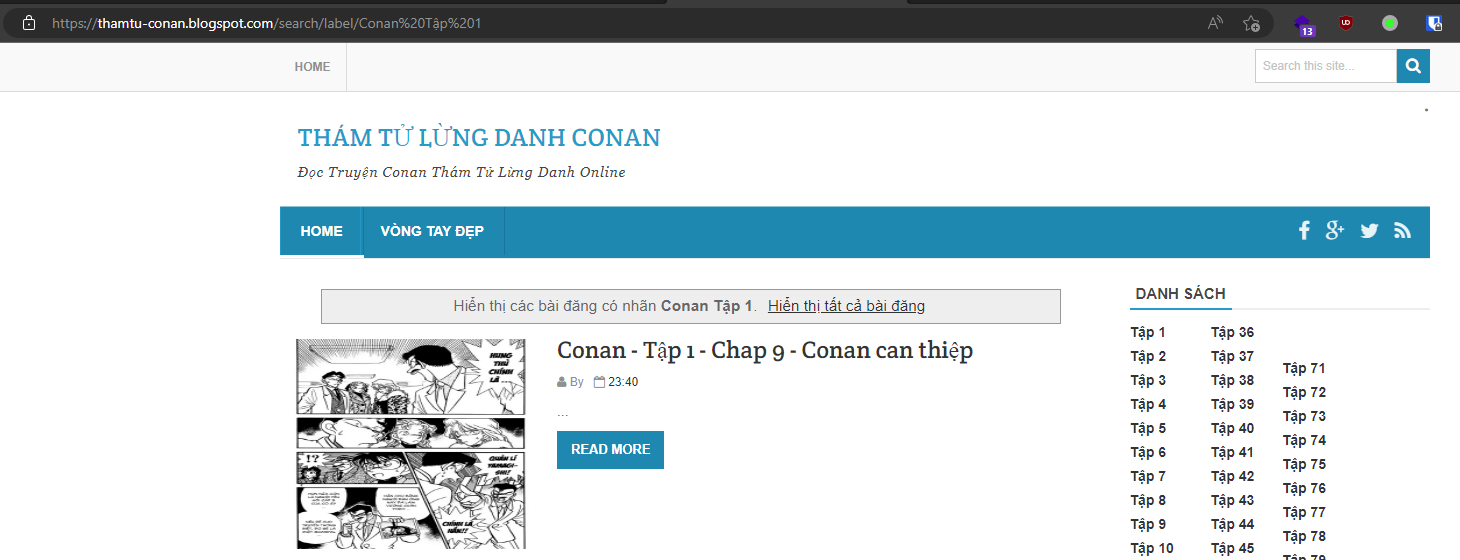
Đầu tiên là phải ngồi phân tích cấu trúc trang web này đã, trang này được cái là phân tích cũng dễ 
get_chapter(chapter):
Có các label để chia ra các tập, mỗi tập có nhiều chapter, đầu tiên là mình viết script để get toàn bộ chapter của một tập về đã
def get_chapter(chapter):
links = []
response = requests.get(
"https://thamtu-conan.blogspot.com/search/label/Conan%20T%E1%BA%ADp%20"+str(chapter))
response = BeautifulSoup(response.text, "html.parser")
response = response.find_all("h2", class_="post-title") # get all link
for i in response:
links.append(i.find("a").get("href"))
return links
Ở đây mình sử dụng bs4 để phân tách code html, lấy code từ đoạn h2 với class post-title vì bên trong nó có cái link chapter 
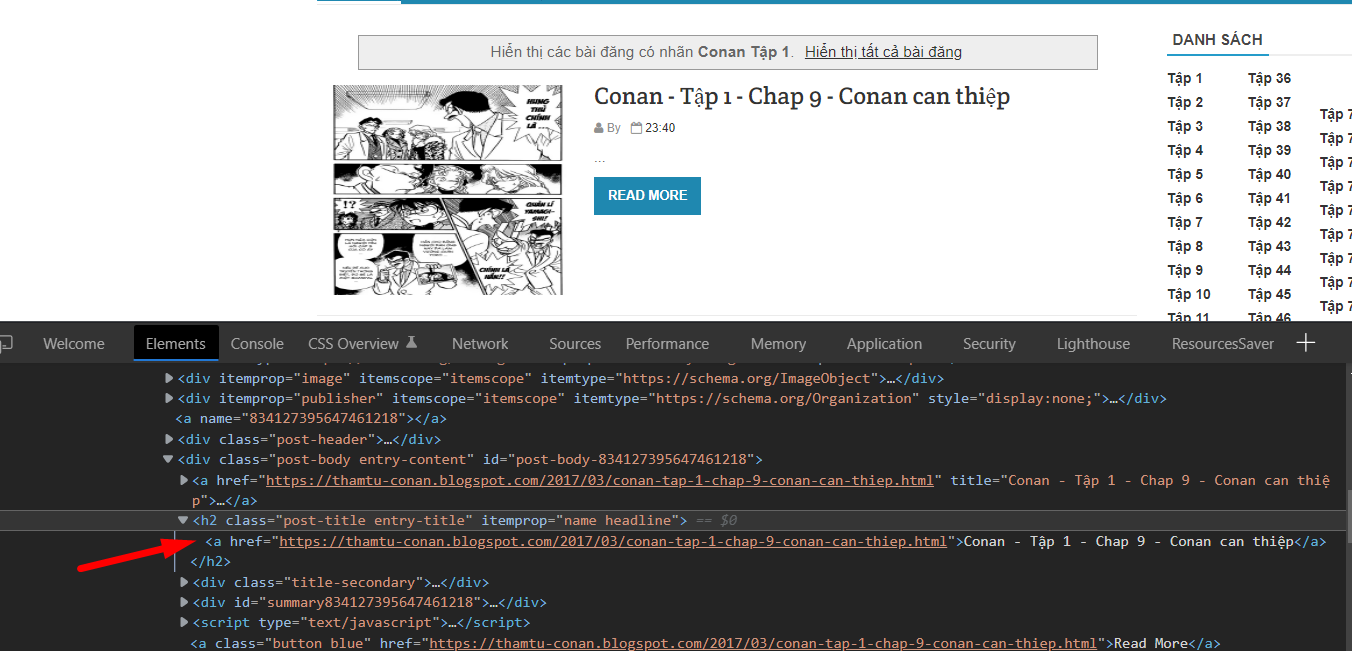
Sau đó lấy toàn bộ link trong kết quả trả về là chúng ta có 1 danh sách links chapter cmnr.
get_images(link):
Lấy được toàn bộ link chapter rồi thì download toàn bộ image trong đó về thôi
def get_images(link):
fnames = []
response = requests.get(link)
response = BeautifulSoup(response.text, "html.parser")
response = response.find_all("div", class_="post-body")
for i in response:
images = i.find_all("img")
for j in range(len(images)):
try:
with requests.get(images[j].get("src"), timeout=10) as r:
with open("images/"+str(j)+".jpg", "wb") as f:
f.write(r.content)
fnames.append(str(j)+".jpg")
print("Saved "+str(j)+".jpg")
except:
print("requests error")
return fnames # return list of filenames
Tiếp tục sử dụng bs4 để lấy toàn bộ code ở thẻ div, class post-body (vì trong đó có chứa toàn bộ ảnh), sau đó tìm kiếm toàn bộ thẻ img rồi download về theo thứ tự. Ở đây mình có return lại toàn bộ filenames để dùng cho chức năng về sau
save_pdf(fnames, chapter):
def save_pdf(fnames, chapter):
with open(chapter, "wb") as f:
fnames = [os.path.join("images", i) for i in fnames]
f.write(img2pdf.convert(fnames))
print("Saved "+chapter)
try:
for i in fnames:
os.remove(i)
except:
print("Cannot remove file")
Lấy được toàn bộ ảnh rồi thì mình sẽ ghép toàn bộ ảnh của 1 chapter vào 1 file pdf. Mình dùng img2pdf để ghép toàn bộ ảnh thành 1 file pdf cho lẹ. Ở đây mình cần phải có list filenames mình nói bên trên để ép vào code cho nó ngắn gọn, các bạn cũng có thể đọc toàn bộ file trong folder rồi ghép lại cũng được, cũng là một cách.
Mình có thêm code xoá luôn cái ảnh đi để đỡ tốn bộ nhớ, ghép vào lấy mỗi file pdf thôi.
get_chapter_full():
def get_chapter_full():
links = []
response = requests.get("https://thamtu-conan.blogspot.com/")
response = BeautifulSoup(response.text, "html.parser")
response = response.find_all(
"div", class_="widget-content") # get all link
response = response[1].find_all("a")
for i in response:
if i.get("href").endswith(".html"):
links.append(i.get("href"))
return links
Đoạn này mình viết thêm để lấy toàn bộ links của các tập hiện có trên web (links danh sách bên dưới nè), còn nếu muốn download từng tập thì có thể dùng hàm get_chapter(chapter) để chỉ định cụ thể tập nào.

main:
Mọi thứ xong rồi, giờ đến lúc chạy script thôi 
- Với những ai muốn download từ tập 1 đến tập cuối luôn thì dùng main như này
if __name__ == "__main__":
links = get_chapter_full()
for i in links:
save_pdf(get_images(i), i.split("/")[-1].split(".")[0]+".pdf")
- Với những ai muốn download tập cụ thể thì có thể dùng như này
if __name__ == "__main__":
for chapter in range(66, 67):
links = get_chapter(chapter)
for i in links:
save_pdf(get_images(i), i.split("/")[-1].split(".")[0]+".pdf")
Nhớ import thư viện của python vào để dùng nữa nhé
import requests
from bs4 import BeautifulSoup
import re
import img2pdf
from PIL import Image
import os
Chú ý
Code bên trên chỉ dùng để download các chapter, để ghép các chapter thành các tập thì phải viết thêm code nữa để merge vào
from PyPDF2 import PdfFileMerger
import os
# Create a list with file name
list_pdf_files = os.listdir()
pdf_files = [i for i in list_pdf_files if i.endswith(".pdf")]
for i in range(66, 67):
merger = PdfFileMerger()
try:
for files in pdf_files:
if files.startswith("conan-tap-"+str(i)+"-"):
merger.append(files)
merger.write("ebooks/conan-tap-"+str(i)+".pdf")
print("Saved conan-tap-"+str(i)+".pdf")
merger.close()
except:
print("Cannot merge file")
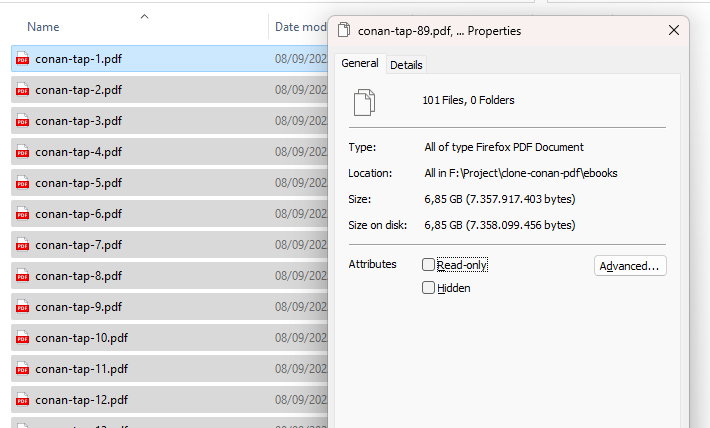
Vậy là xong, quá trình đi kéo sách lậu cũng không phải dễ dàng gì mà ...
All rights reserved
