Mạng Neural Network
Bài đăng này đã không được cập nhật trong 6 năm
Tổng quan về Neural Network
Mạng neural được xây dựng dựa trên mạng neural sinh học. Nó gồm các neural (nút) nối với nhau và xử lý thông tin bằng cách truyền theo các kết nối và tính giá trị tại các nút.
Mạng neuron với mỗi nút sẽ có những dữ liệu đầu vào, biến đổi những dữ liệu đầu vào này bằng cách tính tổng các input với weight tương ứng trên các đầu vào, sau đó áp dụng một hàm biến đổi phi tuyến tính cho phép biến đổi này để tính toán trạng thái trung gian. 3 bước trên tạo thành 1 lớp và hàm biến đổi còn được gọi là activation funtion. Các output của layer này sẽ là input của layer phía sau.
Thông qua việc lặp lại các bước trên, neural-network học thông qua nhiều layer và các nút phi tuyến tính rồi sau đó kết hợp lại ở layer cuối cùng để cho ra 1 dự đoán.
Neural-network học bằng cách tạo ra các tín hiệu lỗi đo lường sự khác biệt giữa các dự đoán của mạng và giá trị mong muốn, sau đó sử dụng tín hiệu lỗi này để cập nhật lại weight và bias trong activation function để việc dự đoán sau đó chính xác hơn.
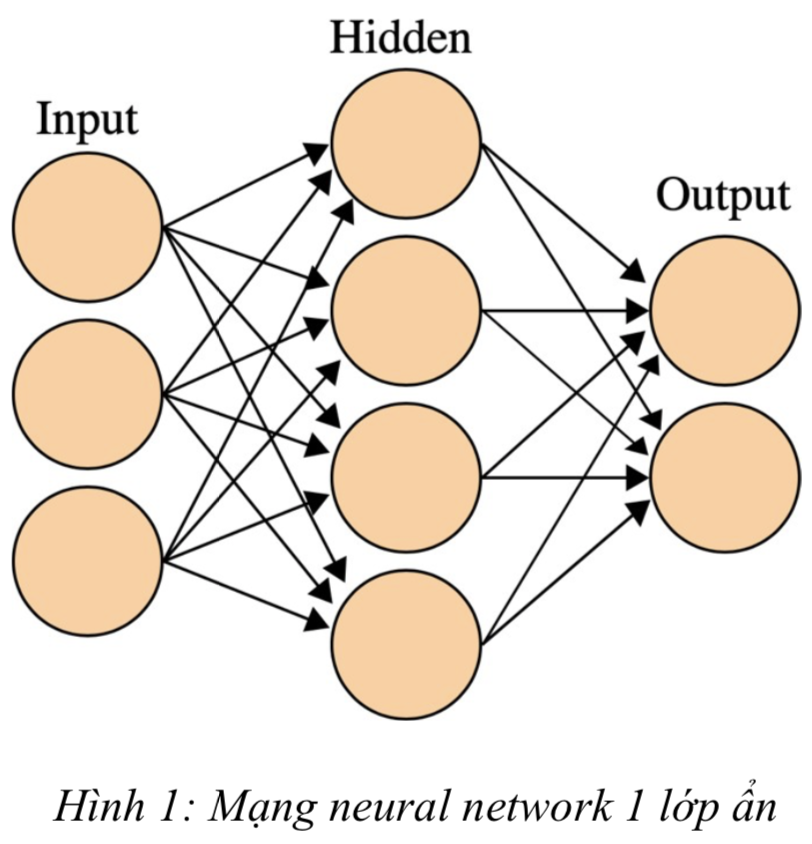
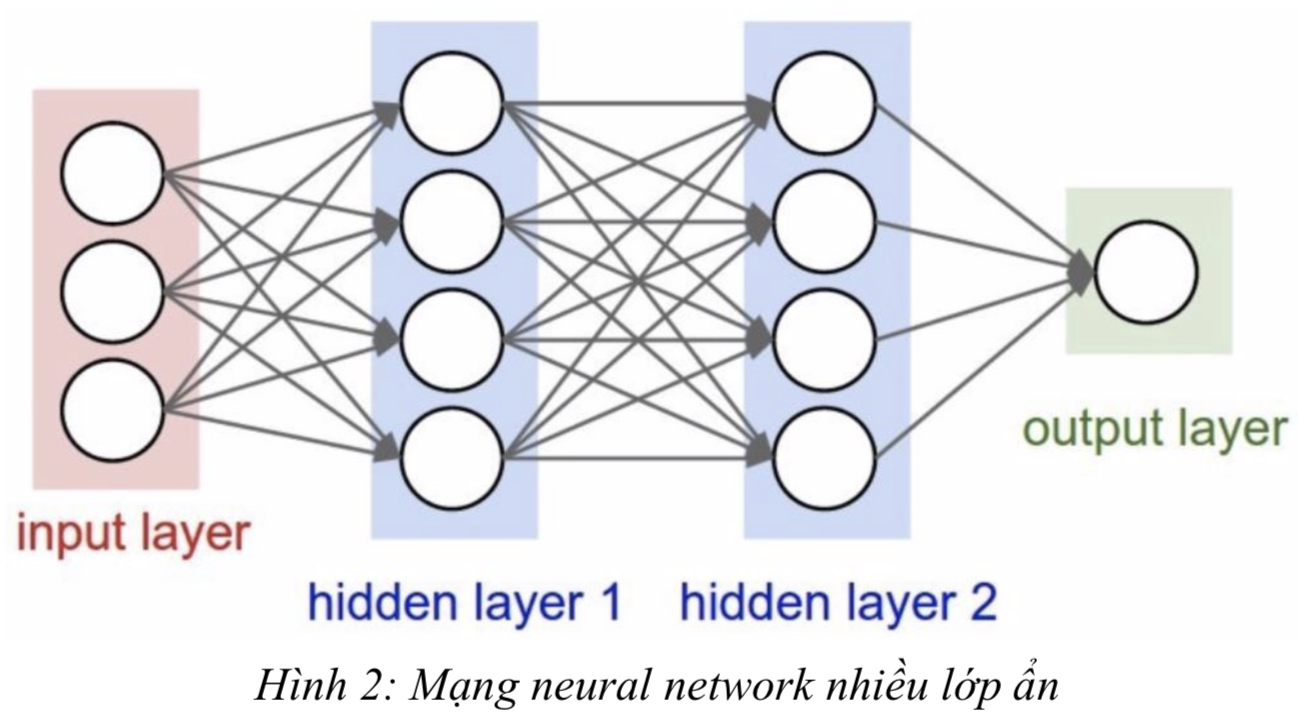
Các thành phần của mạng Neural Network
1. Activation function
Activation function là 1 thành phần rất quan trọng của neural-network. Nó quyết định khi nào thì 1 neuron được kích hoạt hoặc không. Liệu thông tin mà neuron nhận được có liên quan đến thông tin được đưa ra hay nên bỏ qua.

Activation function là 1 phép biến đổi phi tuyến tính mà chúng ta thực hiện đối với tín hiệu đầu vào. Đầu ra được chuyển đổi này sẽ được sử dụng làm đầu vào của neuron ở layer tiếp theo.
Nếu không có activation function thì weight và bias chỉ đơn giản như 1 hàm biến đổi tuyến tính. Giải 1 hàm tuyến tính sẽ đơn giản hơn nhiều nhưng sẽ khó có thể mô hình hóa và giải được những vấn đề phức tạp. Một mạng neuron nếu không có activation function thì cơ bản chỉ là 1 model hồi quy tuyến tính. Activation function thực hiện việc biến đổi phi tuyến tính với đầu vào làm việc học hỏi và thực hiện những nhiệm vụ phức tạp hơn như dịch ngôn ngữ hoặc phân loại ảnh là khả thi.
Activation function hỗ trợ back-propagation (tuyên truyền ngược) với việc cung cấp các lỗi để có thể cập nhật lại các weight và bias, việc này giúp mô hình có khả năng tự hoàn thiện.
Một số hàm activation phổ biến:

Cách lựa chọn activation function:
- Các hàm sigmoid và sự kết hợp của chúng thường phù hợp với những bài toán phân loại
- Sigmoid và tanh đôi khi nên tránh sử dụng đồng thời vì có thể khiến gradient biến mất
- ReLU là 1 activation function phổ biến và thường dùng nhất hiện nay o Nếu gặp những trường hợp có tế bào neuron chết trong mạng thì leaky thì ReLU là 1 lựa chọn hoàn hảo
- ReLU function chỉ có thể được sử dụng trong những hidden layer
2. Convolution
Bộ lọc với điểm ảnh để trích xuất các đặc tính từ ảnh đầu vào, duy trì mối liên kết giữa các pixel bằng cách tìm hiểu đặc tính của ảnh và sử dụng các ô nhỏ của dữ liệu đầu vào.
Convolution Layer : là một loạt feature map được trích xuất từ ảnh ban đầu.
Convolution Filter (kernel): sẽ có nhiều bộ lọc khác nhau như là: Phát hiện cạnh của ảnh, làm mờ, làm sắc nét,… chúng ta có thể áp dụng các bộ lọc trên trong các trường hợp cụ thể mà mình mong muốn.
Các bước thực hiện:
- Chúng ta sẽ chuyển ảnh ban đầu về ma trận có giá trị 0,1.
- Từ ma trận ảnh ban đầu đã có và ma trận bộ lọc (kernel) chúng ta tích chập hai ma trận thành một ma trận đặc điểm của ảnh (feature map).
- Ma trận đầu vào có kích thước là H1 x W1 x D (H = height, W = width, D = dimension) và bộ lọc (kernel) là H2 x W2 x D thì ma trận đặc điểm ảnh sẽ là:

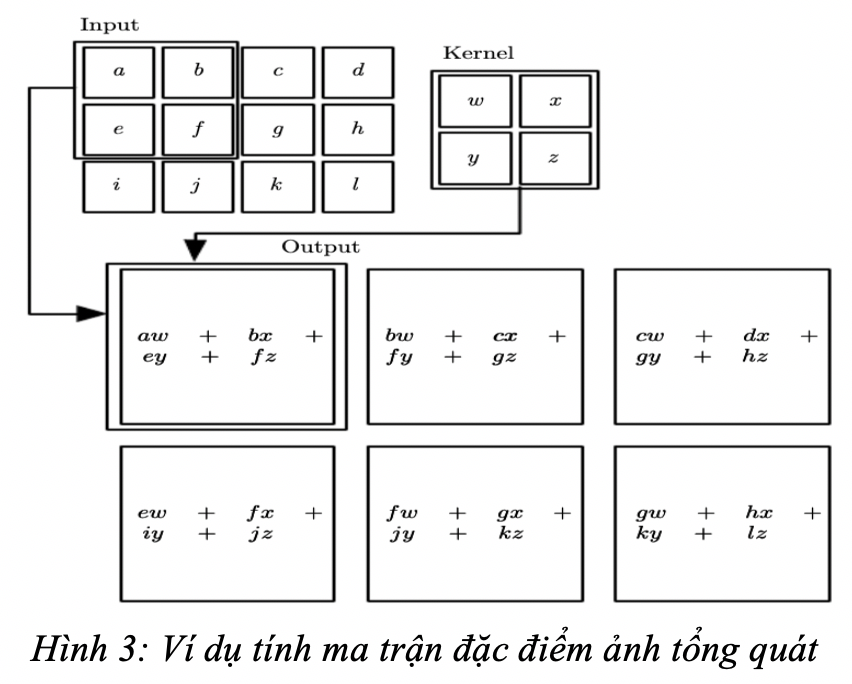
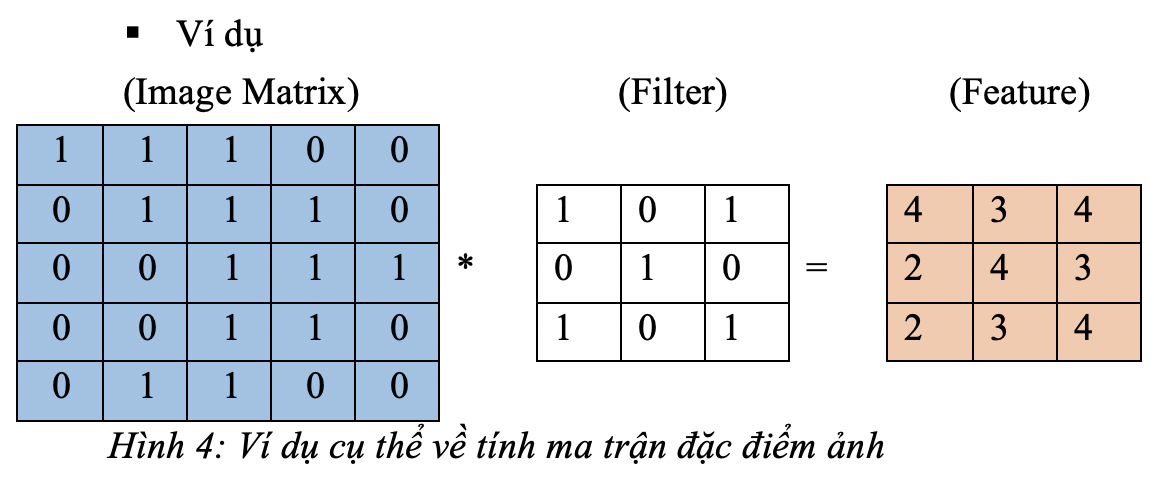
Stride
Stride là số lượng pixel dịch chuyển trên ma trận đầu vào. Khi stride = 1 thì chúng ta sẽ di chuyển các bộ lọc 1 pixel mỗi lần. Khi stride = 2 thì chúng ta di chuyển các bộ lọc 2 pixel cùng một lúc và cứ thế di chuyển bộ lọc vs stride tương ứng.
Chúng ta chọn stride và size của kernel càng lớn thì size của feature map càng nhỏ, một phần lý do đó là bởi kernel phải nằm hoàn toàn trong input.
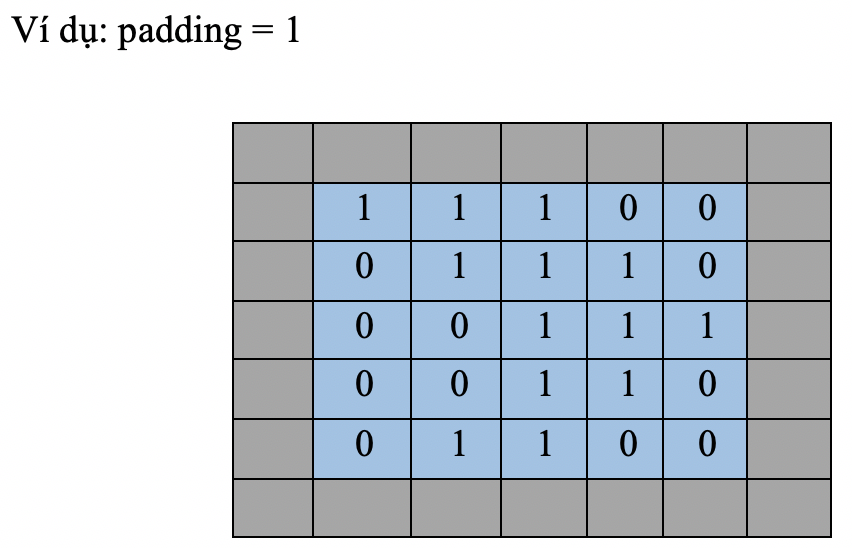
=> Đôi khi bộ lọc và stride sẽ không phù hợp ,Để giữ nguyên kích cỡ của feature map so với ban đầu , ta dùng "padding". Khi ta điều chỉnh padding = 1, tức là ta đã thêm 1 ô bọc xung quanh các cạnh của input, muốn phần bọc này càng dày thì ta cần phải tăng padding lên.
ReLU
Dùng dể sử lý các trọng số của các note
- F(x) = Max(0;x)
Đây là một hàm quan trọng và thường được sử dụng, ngoài ra có tanh hoặc sigmoid.
3. Pooling & Fully connected (Dense)
Pooling
Lớp pooling thường được sử dụng ngay sau lớp convulational để đơn giản hóa thông tin đầu ra để giảm bớt số lượng neuron.
Scale ảnh, giúp giảm số lượng tham số khi hình ảnh quá lớn. Ngoài ra còn giúp lấy mẫu và giảm các chiều của mỗi map nhưng vẫn giữ được thông tin quan trọng
Mục đích: nó làm giảm số hyperparameter mà ta cần phải tính toán, từ đó giảm thời gian tính toán, tránh overfitting.
Có nhiều kiểu như là :
- Max Pooling: lấy phần tử lớn nhất
- Average Pooling; Lấy nhóm trung bình
- Sum Pooling: tổng của tất cả các node trong feature map.
=> Max Pooling thường được dùng nhiều nhất
Fully connected (Dense)
Fully-connected là cách kết nối các neural ở hai tầng với nhau trong đó tầng sau kết nối đẩy đủ với các neural ở tầng trước nó. Đây cũng là dạng kết nối thường thấy ở ANN, trong CNN tầng này thường được sử dụng ở các tầng phía cuối của kiến trúc mạng.
=> Sau các lớp Convolution và Pooling thì sẽ có 2 lớp Fully connected, đầy là 1 layer để tập hợp các feature layer mà ta đã tìm ra, chuyển đổi dữ liệu từ 3D, hoặc 2D thành 1D, tức chỉ còn là 1 vector. Còn 1 layer nữa là output, số neuron của layer này phụ thuộc vào số output mà ta muốn tìm ra.
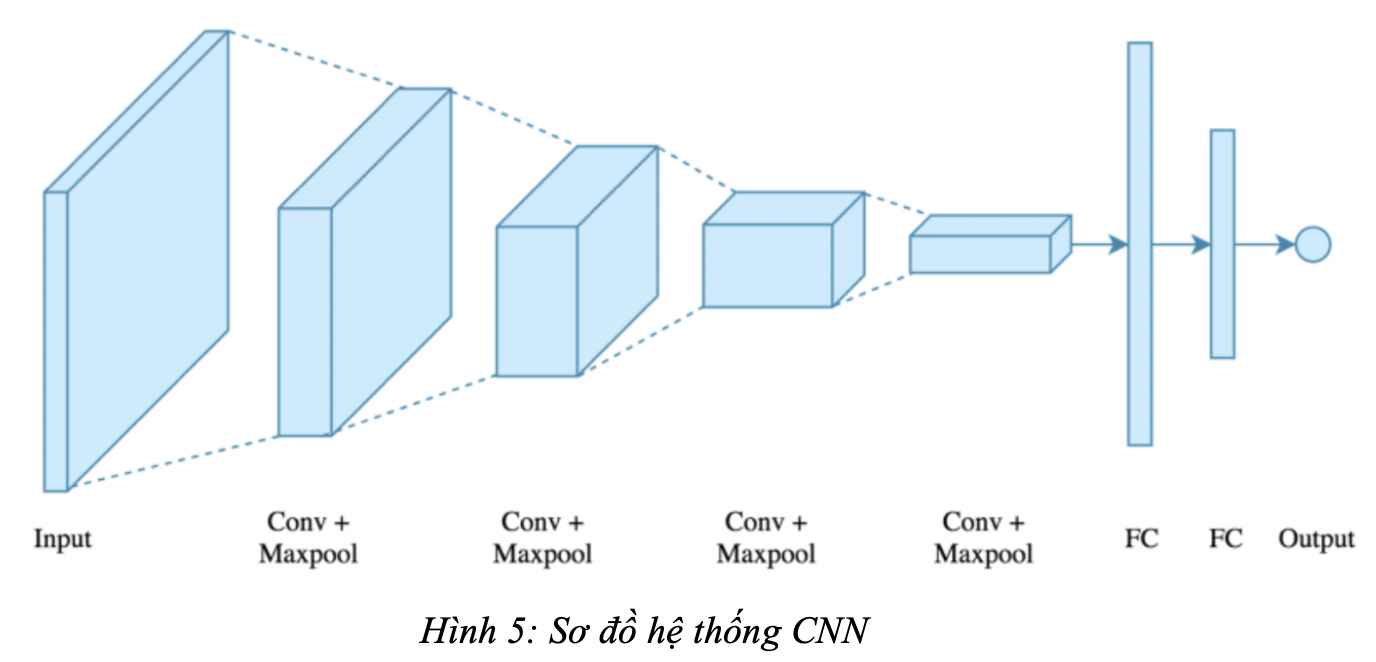
- Sơ đồ hệ thống CNN
All rights reserved
