Cơ chế đánh index trong SQL
Bài đăng này đã không được cập nhật trong 2 năm
Chúng ta thường biết rằng trong SQL đánh index giúp tăng tốc độ truy vấn, vậy mọi người đã biết cơ chế của đánh index là gì ? tại sao nó lại giúp tăng tốc độ truy vấn và nhược điểm của nó là gì chưa ? Hôm nay mình xin phép đc chém gió về chủ đề này.
1. Bài toán thực tế
Chắc hẳn các bạn làm web đều biết về I18n rồi đúng không ? Giả sử bạn có 2 file biên dịch là en.yml và vi.yml. Mỗi dòng bên en.yml tương ứng với vi.yml và ngược lại. Ví dụ:
en.yml:
table: "table"
vi.yml:
table: "cái bàn"
có nghĩa là mỗi từ dịch bằng tiếng anh thì phải dịch bằng Tiếng Việt, vậy số dòng trong file en.yml phải bằng vi.yml. Tuy nhiên một ngày đẹp trời bạn nhận ra en.yml có 1000 dòng mà vi.yml chỉ có 999 dòng, có nghĩa là bạn đã bỏ sót ko dịch 1 từ nào đó sang tiếng Việt. Bạn cần tìm ra dòng còn thiếu trong vi.yml để cập nhật, vậy bạn làm cách nào để tìm ra dòng đó nhanh nhất ?
Nếu dò từ trên xuống dưới giữa 2 file với nhau, xui xẻo bạn có thể phải dò tới 999 lần, quá nhiều lần truy vấn. Tuy nhiên có cách để dò tối đa 10 lần là chắc chắn bạn sẽ tìm ra dòng đó. Cách đó như sau: Lần 1 bạn dò ở dòng thứ 500 và so sánh 2 file, nếu khớp từ khóa chứng tỏ 500 dòng đầu tiên không bị miss value (dòng còn thiếu nằm ở nửa còn lại), còn nếu không khớp (bị lệch 1 dòng) thì chứng tỏ 500 dòng đầu tiên có chứa dòng bị miss. Vậy là chỉ 1 lần test bạn đã "cưa đôi" được phạm vi tìm kiếm, và bạn tiếp tục "cưa đôi" thêm tối đa 10 lần nữa bạn sẽ tìm ra dòng còn thiếu. Tại sao lại 10 lần ? Bởi vì 2^10 =1024 >1000.
Cơ chế đánh index cũng dựa vào phương pháp cưa đôi như vậy.
2. Cơ chế đánh index
Giả sử bạn có 1 bảng 1000 record chứa tên người: "Phong", "Dung", "Hải", ... Bạn cần tìm ra người có tên là "Nam". Vậy cơ chế đánh index sẽ hoạt động ntn trong trường hợp này.
Đầu tiên khi bạn thực hiện đánh index cho trường :name, index sẽ được đánh từ 0 tăng dần tới 999 ( có 1000 record ), đánh theo thứ tự alphabet. Ví dụ: "An" sẽ có index = 0, "Anh" sẽ có index = 1, "Ánh" sẽ có index =2,... lúc này bạn có thể hiểu rằng, vô hình chung, các record của mình đã được sắp xếp lại theo trật tự alphabet tăng dần.
Khi bạn thực hiện câu truy vấn Select ... where name = "Nam" lúc này nó sẽ dùng phương pháp cưa đôi mà mình nói ở trên, đầu tiên lấy :name ở index thứ 500 ra so sánh với "Nam", tuy nhiên ko phải so sánh bằng mà là so sánh xem lớn hơn hay bé hơn, ví dụ record index 500 có :name là "Hoàng" thì khi so sánh sẽ nhận đc kết quả "Hoàng" < "Nam" (theo alphabet) vì vậy có thể xác định "Nam" nằm ở nửa sau, có index lớn hơn 500. Lại cưa đôi và tìm tiếp. Sau tối đa 10 lần so sánh thì sẽ tìm ra được record có :name là "Nam".
Khi số lượng record càng nhiều thì phương pháp đánh index càng thể hiện rõ công dụng của mình. Giả sử bạn có 1 triệu record thì bạn cũng chỉ cần so sánh 20 lần là đủ bởi vì 2^20 = 1024^2 > 1000 ^2 = 1000000. Trong khi phương pháp truy vấn thông thường phải so sánh tối đa 999999 lần.
3. Đánh index cho nhiều trường ( B tree)
Đánh index cho nhiều trường hay còn gọi là phương pháp B tree.
Giả sử bạn có 1 triệu record tên người, và một người ở một tỉnh/thành nhất định. Bạn cần tìm ra người ở tỉnh "Ninh Bình" có tên là "Nam". Cơ chế index lúc này sẽ hoạt động như thế nào.
Đầu tiên bạn sẽ cần đánh index cho cả trường :province và cả trường :name, lúc này 1 triệu record sẽ đc nhóm lại theo province trước, các province này sẽ được sắp xếp theo thứ tự alphabet, ví dụ "An Giang" có index là 0, "Bà Rịa Vũng Tàu" có index là 1, "Bắc Giang" có index là 2, ... Trong nhóm tỉnh/thành, các trường :name lại được đánh index 1 lần nữa. Ví dụ: "An" : 0, "Anh": 1, "Ánh": 2, ... Việc đánh index trong index như thế này tạo nên các nhánh, nên người ta gọi là B tree.
Khi thực hiện câu truy vấn Select ...where province = "Ninh Bình" and name = "Nam". Đầu tiên sẽ lọc ra những người ở tỉnh "Ninh Bình". Cơ chế như sau, mỗi tỉnh lấy ra record đầu tiên và đem so sánh với "Ninh Bình" theo phương pháp đánh index, Việt Nam có 64 tỉnh nên chỉ cần tối đa 6 lần so sánh là sẽ tìm đc người nào thuộc tỉnh "Ninh Bình", từ người đó sẽ lấy ra toàn bộ nhóm đó, sau đó từ nhóm người đó lại dùng phương pháp index lọc ra người tên "Nam" một lần nữa.
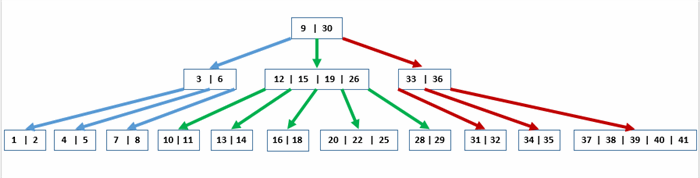
Hình minh họa về B tree
Câu hỏi được đặt ra là chúng ta nên đánh index cho trường nào trước để tối ưu truy vấn, :province hay :name. Câu trả lời là trường nào ít record hơn thì nên đánh trước. Ở trong bài toán này, thì :province có 64 tỉnh, còn :name thì có hàng trăm ngàn kiểu đặt tên, vì vậy nhóm theo trường :province trước là hợp lý hơn, vì khi lọc ra trường :proivince thì bạn đã lọc đc 63/64 tỉnh thành ko cần quan tâm tới, tương đương với 1 lượng record cực lớn. Còn nếu bạn đánh theo trường :name, thì hầu như record nào bạn cũng phải đụng tới ít nhất 1 lần.
Khi đánh index theo thứ tự nào thì khi truy vấn bạn phải áp dụng đúng thứ tự đó nhé, nếu không thì đánh index sẽ không có tác dụng, ví dụ bạn đánh index cho :province trước rồi mới tới :name thì khi dùng câu SQL "Select ... where name = 'Nam' and province = 'Ninh Binh'" thì đánh index là vô dụng .
4. Nhược điểm của phương pháp đánh index.
Đánh index giúp tăng tốc độ truy vấn, tuy nhiên sau mỗi lần insert hoặc update hoặc delete (thay đổi db), chúng ta cần thực hiện lại việc đánh index vì vậy tốc độ khi thực hiện 3 việc này sẽ giảm đi. Ví dụ ban đầu "An" có index là 0, "Anh" có index là 1, "Ánh" có index là 2, khi xóa "An" đi, thì lúc này "Anh" sẽ có index là 0, "Ánh" sẽ có index là 1, các trường phía sau cũng phải thay đổi tương tự. Vậy nhược điểm của phương pháp đánh index chính là giảm tốc độ Insert, update, delete. Nói là giảm nhưng thực tế khi update hoặc delete record chúng ta cũng cần truy vấn tới record đó nên tăng cái này giảm kia, nhưng việc giảm từ 999999 lần so sánh xuống còn 20 lần so sánh thì quá xứng đáng để đánh đổi.
5. Lúc nào thì không nên dùng đánh index ?
Khi quá ít record, cụ thể là dưới 10, lúc này đánh index ko phát huy tác dụng vì so sánh bằng dù là 10 lần thực hiện vẫn nhanh hơn so với so sánh kiểm tra xem lớn hơn hay nhỏ hơn thực hiện 3,4 lần.
Mywebsite: https://www.websitegiare.co https://3000vocab.com https://zreview.vn
All rights reserved
