Sử dụng Index trong Database như thế nào cho hiệu quả?
This post hasn't been updated for 3 years
Câu này slow query, hệ thống response chậm quá,... tìm nguyên nhân đi em, cải thiện tốc độ truy vấn này đi... Đó là những gì tôi nhận được văng vẳng bên tai của a PM. Việc đầu tiên là explain câu query đó ra xem như thế nào đã, và giải pháp đầu tiên tôi nghĩ đến là đánh index. Hãy nói mind set của bạn giống tôi đi. Ok, chủ đề hôm nay là Index trong Database, let's go!...
Đặt vấn đề
Giả sử bây giờ tôi có 1 table "ex" chứa thông tin người yêu cũ bao gồm: tên, tuổi, quê quán, sđt, facebook, số đo ba vòng... và bảng này cỡ khoảng triệu records đi =))) Đến một ngày đẹp trời, tự dưng muốn tìm lại info em Xoan chẳng hạn.
Select * from ex where name = "Xoan"
Lúc này hệ thống phải đọc ra từng row trong bảng "ex", so sánh từ đầu đến cuối, quả là một cách làm tệ và chậm chạp nhất. Vậy làm sao để tăng tốc độ tìm kiếm em Xoan, đi thẳng vào vấn đề đó chính là làm thế nào để giảm được số lượng bản ghi khi truy vấn. Xong, index chắc rồi, vậy....
Index là gì
index là việc cấu trúc dữ liệu, lưu trữ theo một cơ chế chuyên biệt để tìm ra các record một cách nhanh chóng. Ví Index đơn giản như là mục lục của một quyển sách, khi cần tìm một chủ đề, bài viết nào đó thì thay vì phải xem, tìm kiếm toàn bộ quyển sách ta chỉ cần xem chỉ mục tìm đúng bài viết đó rồi từ số trang được đính kèm là ta có thể đến chính xác nội dung bài viết mong muốn.

Mysql hỗ trợ 3 loại index khác nhau cho database: B-tree, Hash, R-tree. Tuy nhiên R-tree chỉ được sử dụng cho các loại dữ liệu không gian spacial data, ví dụ như vị trí nhà hàng hoặc đa giác mà bản đồ điển hình được tạo ra: đường phố, tòa nhà... R-tree thường ít khi gặp phải nên tạm thời mình sẽ bỏ qua, nếu có dịp thì hẹn mọi người tại một bài viết khác.
Hash index
Hash index thì sao, nó được tổ chức dưới dạng key-value với key là kết quả hash value của column được đánh index và value sẽ chứa 1 con trỏ đến chính xác row tương ứng. Chính vì vậy, hash index tỏ ra mạnh mẽ khi thực hiện các phép truy vấn với toán tử = hay <> (IN, NOT IN). Tuy nhiên lại vô dụng khi gặp các trường truy vấn với điều kiện như >, <, like
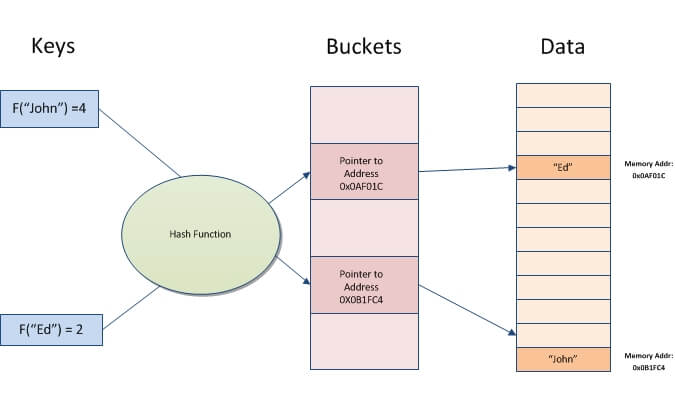
Ngoài ra, Không thể tối ưu hóa toán tử ORDER BY bằng việc sử dụng Hash index bởi vì nó không thể tìm kiếm được phần từ tiếp theo trong Order. Chính vì vậy tùy từng trường hợp chúng ta nên cân nhắc trước khi sử dụng, với bài toán chỉ cần truy vấn với sự chính xác tuyệt đối (= or <>) thì chúng ta nên sử dụng Hash index với tốc độ truy vấn vô đối, còn nhanh hơn cả B-tree index - loại index được sử dụng phổ biến nhất hiện nay mà tôi sắp nói đến.
B-tree index
Dữ liệu index trong B-Tree được tổ chức và lưu trữ theo dạng cây(tree):
- Root node – node đầu tiên đứng vị trí cao nhất trong cây
- Child nodes – nodes con được trỏ từ Parent nodes (vị trí cao hơn)
- Parent nodes – nodes cha trong cây mà có trỏ sang các Child nodes
- Leaf nodes – nodes lá, không trỏ đến bất kì nodes nào khác, có vị trí thấp nhất trong nhánh của cây.
- Internal nodes – tất cả các nodes không phải là nodes lá
- External nodes – tên gọi khác của nodes lá.
Đến đây mọi người có nhớ đến thuật toán tìm kiếm cây nhị phân (Binary Search Trees - BST) không ạ.
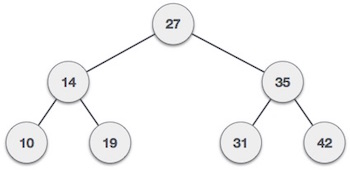
thì cấu trúc B-tree index cũng tương tự như vậy, tuy nhiên một node có thể có nhiều hơn 1 value, kích thước của node được xác định bởi bậc (order) trong BTree là một constant định nghĩa trước. Các value trong 1 node cũng được sắp xếp theo thứ tự tăng dần.Child nodes sẽ nằm bên trái value X khi values của node nhỏ hơn X, ngược lại sẽ nằm bên phải nếu có values lớn hơn.
Trong mỗi node, sẽ chứa các values, con trỏ đến các values, con trỏ đến các Child nodes
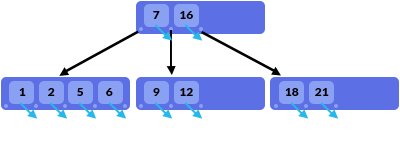
Khi truy vấn dữ liệu thì việc tìm kiếm trong B-Tree là 1 quá trình đệ quy, bắt đầu từ Root node và tìm kiếm tới Child nodes và Leaf nodes, đến khi tìm được tất cả dữ liệu - thỏa mãn với điều kiện truy vấn thì mới dùng lại.
Để dễ hình dung cơ chế đánh index thì mình sẽ ví dụ như sau:
-
TH1: đánh index cho 1 trường - ví dụ trường “name”: Đầu tiên, cần sắp xếp các value của column này theo thứ tự từ a-z để được gán index tương ứng từ 0, 1, 2, … tăng dần. Fill vào cây nhị phân, khi truy vấn với điều kiện WHERE name = ‘quanlx’ chẳng hạn, thì sẽ đi so sánh từ root, nếu root có value = ‘quanlx’ thì xong luôn rồi. trỏ ngược lại vị trí của row trong DB, nếu root có value < ‘quanlx’ thì sẽ tìm kiếm tiếp các child node bên trái và bỏ qua child node bên phải. nếu root có value > ‘quanlx’ thì ngược lại. … tìm kiếm nhị phân cho đến khi ra kết quả.
-
TH2: đánh index cho nhiều trường - ví dụ (country, name, email) Vẫn như trên, nhưng có điều, column
countrysẽ được chọn lấy làm value chính để sắp xếp index trước, sau đó mới đếnnamevàemail.
Tức là trong truy vấn, mặc định B-tree index sẽ đi tìm kiếm theo country trước, khi tìm được chính xáccountrythì mới tìm kiếm đếnnamethuộccountryđó, và cuối cùng làemail. Chính vì vậy, vị trí column để đánh index là hết sức quan trọng.
Nếu bạn nhảy cóc bỏ qua việc tìm kiếmcountrytrước để tìm kiếm trực tiếp name thì index sẽ không có tác dụng. Vì nó k thể biết được trước đó,namecần tìm thuộccountrynào.
Ngoài việc có thể tăng tốc các câu truy vấn với toán tử = thì B-tree index còn có thể đối ứng với các toán tử như >, <, LIKE, IN, tăng tốc với các phép truy vấn ORDER BY. Chính vì vậy nên B-tree mới được đặt làm mặc định khi đánh index trong MYSQL.
Trong các phần tiếp theo, mình sẽ đi tìm hiểu kĩ hơn vê B-tree index, thứ mà được mọi người dùng phổ biến nhất.
Sử dụng index như thế nào?
Index mạnh như vậy, tại sao chúng ta không auto sử dụng ở tất cả các bảng, tất cả các cột? Câu trả lời là không nên, cái gì cũng có 2 mặt của nó, tốc độ tăng lên đi kèm với một cái giá: việc tạo index sẽ yêu cầu dung lượng ổ đĩa và có thể làm chậm các hoạt động khác. Đặc biệt, khi insert hay update column sử dụng index, index cần được điều chỉnh (reindex) sẽ tiêu tốn một khoảng thời gian. Việc đánh index bừa bãi, lộn xộn, không những không tăng tốc độ truy vấn mà còn làm giảm performance. Vậy, bạn đã hiểu rõ về cách sử dụng index chưa, đánh index như thế nào cho hiệu quả, hãy cùng theo dõi tiếp nhé!
Một số trường hợp Index được tạo tự động
Bạn có bao giờ thắc mắc cùng 1 table có hơn triệu records, và bạn cũng không hề đánh index cho bất cứ column nào, nhưng khi truy vấn với điều kiện column là id thì tốc độ cực nhanh so với các column khác không?
Lý do là vì, index sẽ được tạo tự động với primary key, điều này cũng tương tự với các foreign key.
Cũng giống như primary key. khi sử dụng thuộc tính UNIQUE, một index cũng sẽ tự động được tạo cho columns unique đó.
Khi nào nên sử dụng index
- Chỉ nên thêm index với những bảng có dữ liệu vừa và lớn (theo mình cỡ khoảng 100k trở lên) + thường xuyên query trên bảng đó.
- Chỉ đánh index cho các column thường xuyên sử dụng trong mệnh đề
WHEREhayORDER BY: quay lại ví dụem Xoantrên thì chúng ta nên đánh index cho columnname - Ở một diễn biến khác, giả sử chúng ta thường xuyên truy vấn sử dụng column
descriptiontypetextchẳng hạn. đừng có dại mà đánh index cho column này nhé, điều này sẽ khiến tăng dung lượng store mà performance từ con rùa thành con rùa què đấy Trong trường hợp này, bạn có thể nghĩ đến việc đánh index cho column
Trong trường hợp này, bạn có thể nghĩ đến việc đánh index cho column descriptionnhưng thay vì toàn bộ value thì chúng ta chỉ nên sử dụng 5-10 kí tự đầu tiên thôi (description(10)) - Không nên đánh index cho column có quá nhiều value trùng lặp, hay NULL: ví dụ column
gendergiới tính chỉ cómalevàfemaleđừng thấy nó được query suốt mà đánh index, chăng có mấy tác dụng đâu. - Trường hợp sử dụng nhiều columns trong một index thì cần chú ý đến thứ tự các column, nó sẽ ảnh hưởng khá nhiều nếu chúng ta không hiểu rõ (mình sẽ giải thích rõ hơn ở phần
example)
Một số điều thú vị khi sử dụng index
- Khi đánh index cho column có kiểu dữ liệu là
stringthì cẩn thận với toán tửlike: ví dụ với index cho columnnametrong bảngex, nếu truy vấn dạng nhưWHERE name LIKE 'Xo%' hoặc 'X%n'thì index sẽ vẫn hoạt động, Nhưng, nếu với kiểu truy vấnWHERE name LIKE '%n'thì index bó tay rồi.
Nếu muốn sử dụng index trong toán tử LIKE thì tuyệt đối không được để % đứng trước.
- Index sẽ không có nhiều tác dụng trong các trường hợp còn lại với toán tử
<> (!=)hayNOT IN - Không nên sử dụng các toán tử đối với các trường đánh index: ví dụ
SELECT * FROM ex WHERE age + 1 = 18(lấy ra tất cả các em nyc mà năm sau 18 tuổi) lúc này index sẽ không được apply, vì nó không đủ thông minh để hiểu được là cần phải tìm kiếm các records vớiage = 17 - Như đã nói để trên, khi insert cần mất thêm thời gian cho việc reIndex thế nên trong một vài trường hợp, bạn có thể bỏ index --> insert data --> sau khi insert hoàn thành thì chúng ta tạo lại index, đây cũng là một solution tốt trong một vài trường hợp nhất định.
Một số cách tạo index đơn giản
Ở trên tôi có đề cập là index sẽ được tạo tự động một số trường hợp như khi tạo Primarykey
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list)
hay UNIQUE
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list)
Còn đây là cú pháp khi muốn tạo INDEX riêng:
ALTER TABLE tbl_name ADD INDEX index_name (column_list)
hoặc:
CREATE UNIQUE INDEX index_name ON table_name (column_list);
và UNIQUE INDEX (có ý nghĩa như khi tạo UNIQUE)
ALTER TABLE tbl_name ADD UNIQUE INDEX index_name (column_list)
ví dụ tạo index multiple columns:
CREATE TABLE `wallets` (
`id` int not null AUTO_INCREMENT, primary key (`id`),
`user_id` int(10) unsigned NOT NULL,
`bank_id` int(10) unsigned NOT NULL,
`account_id` int(10) unsigned NOT NULL,
`amount` int(11) NOT NULL DEFAULT 0,
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
UNIQUE INDEX multiple_index (user_id, bank_id, account_id)
);
UNIQUE INDEX với 3 columns : user_id, bank_id, account_id sẽ tăng tốc độ với những truy vấn có điều kiện như:
WHERE user_id = 2 and bank_id = 3 and account_id = 4;
WHERE user_id = 2 and banker_id = 3;
WHERE user_id = 2;
WHERE user_id = 2 and account_id = 4; (do không có column bank_id ở giữa, mất thứ tự columns trong index nên index trong trường hợp này sẽ apply cho column user_id, tương tự như khi chỉ truy vấn với user_id)
và sẽ vô dụng với các kiểu truy vấn như:
WHERE bank_id = 3 and account_id = 4;
WHERE banker_id = 3;
WHERE account_id = 4;
Nếu bạn để ý một chút thì index sẽ chỉ apply với những trường hợp có điều kiện user_id đầu tiên, đó là lý do bạn phải hết sức chú ý về thứ tự columns khi tạo index.
Trong case này, bạn không cần tạo index cho column user_id hay (user_id, bank_id), nó sẽ là thừa và gây tốn dung lượng vì index multiple_index đã bao gồm chúng
Cùng xem lại kết quả qua trình truy vấn từ không đến có index nhé (ví dụ với bảng wallets có hơn 100K records)
Chưa có INDEX:
EXPLAIN SELECT * FROM wallets WHERE user_id = 253 AND bank_id = 759982 AND account_id = 47
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | wallets | ALL | 105908 | 100 | Using where |
Số rows cần phải duyệt là 105908 mới tìm thấy bản ghi tương ứng và không có possible_keys nào được sử dụng. Thử tưởng tượng nếu table có 1 triệu hay nhiều hơn thì sao nhỉ? Quá kinh khủng phải không nào. (Nếu mọi người chưa biết hiểu rõ các thống số khi explain thì có thể tham khảo tại đây)
Sau khi có UNIQUE INDEX multiple_index (user_id, bank_id, account_id):
EXPLAIN SELECT * FROM wallets WHERE user_id = 253 AND bank_id = 759982 AND account_id = 47
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | wallets | const | multiple_index | multiple_index | 12 | const,const,const | 1 | 100 |
Bạn thấy không, sau khi đánh INDEX việc tìm kiếm đã giảm xuống còn 1 row khi sử dụng index (key) là multiple_index. Xem tiếp vài ví dụ với index nhé.
EXPLAIN SELECT * FROM wallets WHERE user_id = 253 AND bank_id = 759982
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | wallets | ref | multiple_index | multiple_index | 8 | const,const | 41 | 100 |
SELECT count(*) FROM wallets WHERE user_id = 253 AND bank_id = 759982
| count |
|---|
| 41 |
Có 41 kết quả của câu truy vấn, trùng khớp với số rows cần duyệt để tìm kiếm.
EXPLAIN SELECT * FROM wallets WHERE user_id = 253
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | wallets | ref | multiple_index | multiple_index | 4 | const | 246 | 100 |
SELECT count(*) FROM wallets WHERE user_id = 253
| count |
|---|
| 246 |
Tương tự như trên, có 246 kết quả của cau truy vấn, trùng với số rows cầ duyệt để tìm kiếm, bạn đã thấy sức mình của index chưa nào?
EXPLAIN SELECT * FROM wallets WHERE user_id = 253 AND account_id = 47
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | wallets | ref | multiple_index | multiple_index | 4 | const | 246 | 100 |
SELECT count(*) FROM wallets WHERE user_id = 253 AND account_id = 47
| count |
|---|
| 6 |
Bạn thấy không, câu query chỉ có có 6 kết quả. tuy nhiên khi EXPLAIN thì cần duyệt qua 246 bản ghi, lý do là trong câu điều kiện truy vấn, đã bỏ mất column bank_id trong index, không còn giữ đúng thứ tự columns ban đầu (user_id, bank_id, account_id). Vì vậy explain có kết quả tương tự như khi WHERE user_id = 253
Tổng kết
Trên đây mình đã giới thiệu với tất cả mọi người về việc cách sử dụng INDEX làm sao cho hiệu quả nhất. Việc hiểu và vận dụng chúng là điều vô cùng quan trọng, hãy cẩn thận với con dao hai lưỡi này. Ngoài ra, để mài bóng con dao này, để performance tăng lên gấp bội lần khi gặp bài toán data cực lớn lên cỡ vài chục triệu records, hãy kết hợp sử dụng index với Partitions. Để tìm hiểu về partitions mọi người có thể xem bài viết của mình tại đây
Cám ơn mọi người đã dành thời gian đọc bài viết, nếu có bất cứ vấn đề gì, đừng ngại thắc mắc dưới phần bình luận, mình cùng nhau chia sẻ kiến thức, cùng nhau nâng cao trình độ, và nhớ tặng mình 1 vote up nhé. Tks!!!
Tài liệu tham khảo
https://www.vertabelo.com/blog/all-about-indexes-the-very-basics/
https://www.vertabelo.com/blog/all-about-indexes-part-2-mysql-index-structure-and-performance/
All Rights Reserved
