
Xây dựng mô hình không gian vector cho Tiếng Việt
Bài đăng này đã không được cập nhật trong 5 năm
Trong xử lý ngôn ngữ tự nhiên, việc biểu diễn một từ thành một vector đóng một vai trò cực kỳ quan trọng. Nó lợi ích rất nhiều trong việc thể hiện sự tương đồng, đối lập về ngữ nghĩa giữa các từ, giúp mô hình hóa vector cho 1 câu hay đoạn văn, tìm các câu có nghĩa tương đồng,...
Trong bài viết này, mình sẽ trình bày một cách sơ lược về cách mô hình hóa không gian vector cho Tiếng Việt.
Bài viết gồm 2 phần:
- Trình bày sơ lược về Word embedding. Tại sao word embedding lại quan trọng trong xử lý ngôn ngữ? Các kỹ thuật sử dụng trong word embedding.
- Xây dựng mô hình không gian vector cho Tiếng Việt với VietNam Wikipedia.
Word embedding là gì? Tại sao word embedding lại quan trọng trong xử lý ngôn ngữ?
Word embedding là một nhóm các kỹ thuật đặc biệt trong xử lý ngôn ngữ tự nhiên, có nhiệm vụ ánh xạ một từ hoặc một cụm từ trong bộ từ vựng tới một vector số thực. Từ không gian một chiều cho mỗi từ tới không gian các vector liên tục. Các vector từ được biểu diễn theo phương pháp word embedding thể hiện được ngữ nghĩa của các từ, từ đó ta có thể nhận ra được mối quan hệ giữa các từ với nhau(tương đồng, trái nghịch,...).
Các phương pháp thường được sử dụng trong word embedding bao gồm:
- Giảm kích thước của ma trận đồng xuất hiện.
- Neural network(Word2vec, GloVe,...)
- Sử dụng các mô hình xác suất,…
Vậy tại sao word embedding lại quan trọng?
Trong các ứng dụng về xử lý ngôn ngữ tự nhiên, học máy,... các thuật toán không thể nhận được đầu vào là chữ với dạng biểu diễn thông thường. Để máy tính có thể hiểu được, ta cần chuyển các từ trong ngôn ngữ tự nhiên về dạng mà các thuật toán có thể hiểu được(dạng số). Một kỹ thuật đơn giản nhất được sử dụng là One hot vector(1-of-N).
Để chuyển đổi ngôn ngữ tự nhiên về dạng 1-of-N, ta thực hiện các bước như sau:
- Xây dựng một bộ từ vựng.
- Mỗi vector đại diện cho một từ có số chiều bằng số từ trong bộ từ vựng. Trong đó, mỗi vector chỉ có một phần tử duy nhất khác 0(bằng 1) tại vị trí tương ứng với vị trí từ đó trong bộ từ vựng.
Ví dụ: Giả sử bộ từ vựng của chúng ta chỉ có 5 từ: Vua, Hoàng hậu, Phụ nữ, Đàn ông và Trẻ con. Ta sẽ mã hóa cho từ Hoàng Hậu như sau:
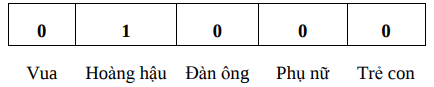
Tuy nhiên, phương pháp này lại để lộ ra những điểm hạn chế vô cùng lớn.
- Thứ nhất là độ dài của vector là quá lớn(vietwiki: Corpus Size(74M), Vocabulary size(10K))
- Đặc biệt phương pháp này không xác định được sự tương quan ý nghĩa giữa các từ do tích vô hướng của 2 từ bất kì đều bằng 0 dẫn đến độ tương đồng cosin giữa 2 từ bất kì luôn bằng 0.
Do đó, việc tìm một phương pháp biểu diễn từ mà vẫn thể hiện được một cách tốt nhất ngữ nghĩa của từ là một vấn đề cực kỳ quan trọng.
Vậy làm thế nào để thể hiện ý nghĩa của 1 từ?
Câu trả lời thường gặp là sử dụng wordnet.
Với những ai chưa biết, wordnet là một cơ sở dữ liệu về từ, trong đó các từ được nhóm lại thành các loạt từ đồng nghĩa, các loạt từ đồng nghĩa này được gắn kết với nhau nhờ các quan hệ ngữ nghĩa.
from Viwordnet import viwordnet
synset = viwordnet('V', 'cố_gắng')
for word in synset:
print word
Kết quả thu được là:
dốc_sức, gắng_sức, nỗ_lực, gắng, gắng_mình, dốc_hết_mình, phấn_đấu, gắng_hết_sức_mình, ráng_sức, đối_phó, dốc_hết_nghị_lực, dồn_sức, cố_gắng
Tuy nhiên, wordnet vẫn ẩn chứa vấn đề của nó:
- Thiếu sắc thái, ví dụ như các từ đồng nghĩa: Cố, cố gắng, gắng, lỗ lực được xem là có mức độ như nhau.
- Thiếu từ mới hoặc ý nghĩa mới(không thể cập nhật): Sống thử, lầy, thả thính, trẻ trâu, gấu,…
- Chủ quan, phụ thuộc vào người tạo
- Yêu cầu nhiều công sức tạo ra và cập nhật để thích ứng
- Khó đo chính xác khoảng cách về nghĩa giữa các từ.
Chưa kể đến việc wordnet cho Tiếng Việt còn nhiều hạn chế về chất lượng và cấu trúc lưu trữ.
Một điều khá đặc biệt trong việc hiểu ngôn ngữ của chúng ta là chúng ta còn có thể lấy được rất nhiều giá trị đại diện cho một từ thông qua ý nghĩa của các từ lân cận nó.
Ví dụ: Sau một vài thành công trong lĩnh vực âm nhạc, Sơn Tùng M-TP được người hâm mộ gọi với cái biệt danh thân mật là sếp. Mọi người có thể đứng ngoài trời cả ngày trời chỉ để mua vé nghe sếp hát.
Trong trường hợp này, từ sếp đã được đại diện cho từ Sơn Tùng M-TP thông qua các ngữ cảnh xung quanh nó.
Vậy làm thế nào để lấy các lân cận đại diện cho một từ? Có một cách đơn giản mà hiệu quả là xây dựng 1 ma trận đồng xuất hiện X dựa vào cửa sổ quanh mỗi từ. Việc này giúp ta nắm bắt được cả ngữ pháp của câu cũng như ngữ nghĩa của từ. Người ta gọi phương pháp này là Windows based cooccurence matrix. Chúng ta cùng tìm hiểu về nó trong phần tiếp theo.
Windows based cooccurence matrix
Ví dụ: Windows based cooccurence matrix với Window length 1( thường 5-10), đối xứng(không liên quan tới trái hoặc phải).
Corpus:
- tôi yêu công_việc .
- tôi thích NLP .
- tôi ghét ở một_mình
Ta có ma trận đồng xuất hiện sau:
| tôi | yêu | công_việc | thích | NLP | ghét | ở | một_mình | . | |
|---|---|---|---|---|---|---|---|---|---|
| tôi | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| yêu | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| công_việc | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| thích | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| NLP | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| ghét | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| ở | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| một_mình | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| . | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
Tuy nhiên, vấn đề ở đây là khi tăng kích thước của bộ từ vựng, số chiều của ma trận sẽ rất lớn: đòi hỏi nhiều không gian lưu trữ hơn, không những thế ma trận lưu trữ còn là ma trận thưa, rất kém hiệu quả.
Giải pháp khắc phục cho vấn đề này là : Giảm chiều vector
Ý tưởng: Giảm số chiều của vector ban đầu xuống một số cố định mà vẫn đảm bảo lưu trữ được hầu hết các thông tin quan trọng. Vector thu được là một dense vector. Số chiều thường lấy trong khoảng từ 300-1000 chiều.
Phương pháp: Giảm kích thước với X sử dụng Singular Value Decomposition.
Ý tưởng cốt lõi của phương pháp Singular Value Decomposition là phân tích ma trận ban đầu thành tích của 3 ma trận đặc biệt, sử dụng chéo hóa ma trận.
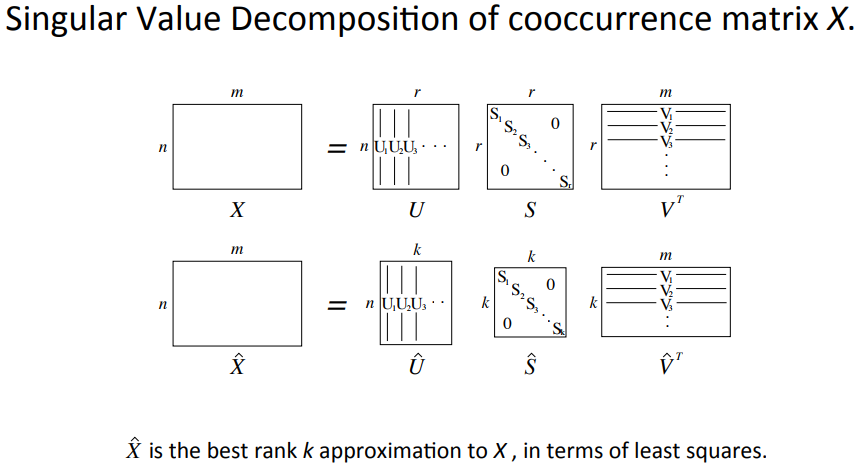
Trong bài viết này mình sẽ không nói rõ chi tiết về phương pháp. Bạn có thể tham khảo qua phương pháp SVD ở đây.
Vẫn với corpus như trên, ta thực hiện chương trình thử nghiệm. Đầu tiên, ta import 2 thư viện cần thiết là numpy để hỗ trợ tính toán và matplotlib để hiện thị kết quả.
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
Sau khi đã import 2 thư viện trên, ta thực hiện việc xây dựng corpus và tính ma trận đồng xuất hiện.
corpus = ["tôi yêu công_việc .",
"tôi thích NLP .",
"tôi ghét ở một_mình"]
words = []
for sentences in corpus:
words.extend(sentences.split())
words = list(set(words))
words.sort()
X = np.zeros([len(words), len(words)])
for sentences in corpus:
tokens = sentences.split()
for i, token in enumerate(tokens):
if(i == 0):
X[words.index(token), words.index(tokens[i + 1])] += 1
elif(i == len(tokens) - 1):
X[words.index(token), words.index(tokens[i - 1])] += 1
else:
X[words.index(token), words.index(tokens[i + 1])] += 1
X[words.index(token), words.index(tokens[i - 1])] += 1
print X
Cuối cùng, ta giảm chiều cho ma trận đồng xuất hiện X theo phương pháp SVD với sự hỗ trợ của thư viện numpy.
la = np.linalg
U, s, Vh = la.svd(X, full_matrices=False)
plt.xlim(-1, 1)
plt.ylim(-1, 1)
for i in xrange(len(words)):
plt.text(U[i, 0], U[i, 1], words[i].decode('utf-8'))
plt.show()
Chúng ta cùng phân tích kết quả.
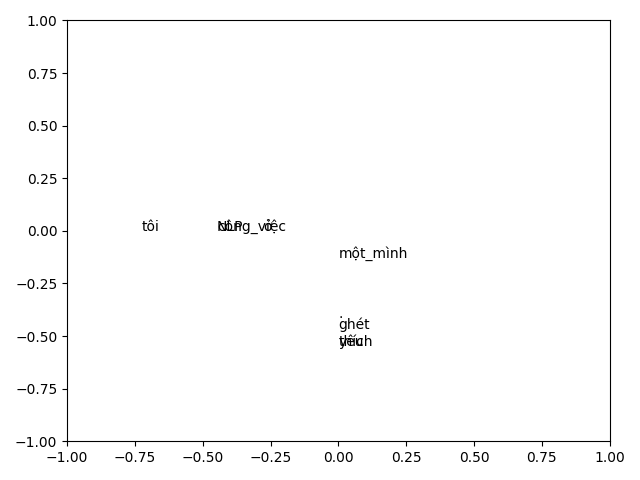
Như trên hình vẽ, từ "NLP" và từ "công_việc", từ "yêu" và từ "thích" ghi đè lên nhau. Lý do là các cặp từ này đều cùng 1 tính chất, từ "ghét" ở gần từ "yêu" và "thích" hơn các từ khác vì chúng đều là tính từ. Đây là 1 ví dụ siêu nhỏ nhưng cũng mong nó sẽ giúp bạn hình dung rõ hơn về ứng dụng của word embedding.

Hình ảnh ở trên là một ví dụ khác sử dụng ma trận đồng xuất hiện cho biểu diễn từ lên không gian vector. Như chúng ta đã thấy, kết quả khá tốt khi mối quan hệ giữa các danh từ và động từ được tách biệt 1 cách khá rõ ràng.
Tuy nhiên, vấn đề của SVD là chi phí tính toán khá lớn, tỉ lệ với bậc hai của độ lớn bộ từ vựng với độ phức tạp .
Không những thế, nó còn khó kết hợp khi có từ mới hoặc tài liệu mới.
Trong năm 2013, một ý tưởng được đưa ra bởi Tomas Mikolov- một kỹ sư đang làm tại Google đã giải quyết được các vấn đề trên bằng một mô hình hoàn toàn khác. Mô hình được sử dụng tốt cho đến ngày nay và được gọi là mô hình word2vec.
Word2vec
Thay vì đếm và xây dựng ma trận đồng xuất hiện, word2vec học trực tiếp word vector có số chiều thấp trong quá trình dự đoán các từ xung quanh mỗi từ. Đặc điểm của phương pháp này là nhanh hơn và có thể dễ dàng kết hợp một câu một văn bản mới hoặc thêm vào từ vựng.
Word2vec là một mạng neural 2 lớp với duy nhất 1 tầng ẩn, lấy đầu vào là một corpus lớn và sinh ra không gian vector(với số chiều khoảng vài trăm), với mỗi từ duy nhất trong corpus được gắn với một vector tương ứng trong không gian.
Các word vectors được xác định trong không gian vector sao cho những từ có chung ngữ cảnh trong corpus được đặt gần nhau trong không gian. Dự đoán chính xác cao về ý nghĩa của một từ dựa trên những lần xuất hiện trước đây.
Nếu ta gán nhãn các thuộc tính cho một vector từ giả thiết, thì các vector được biểu diễn theo word2vec sẽ có dạng như sau:
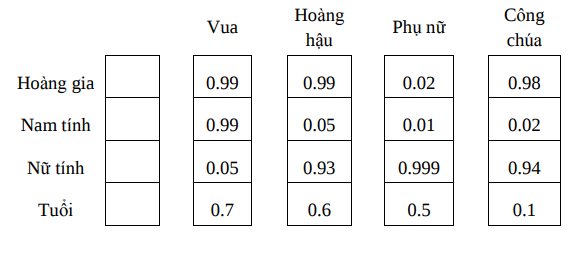
Có 2 cách xây dựng word2vec:
- Sử dụng ngữ cảnh để dự đoán mục tiêu(CBOW).
- Sử dụng một từ để dự đoán ngữ cảnh mục tiêu(skip-gram)(cho kết quả tốt hơn với dữ liệu lớn).
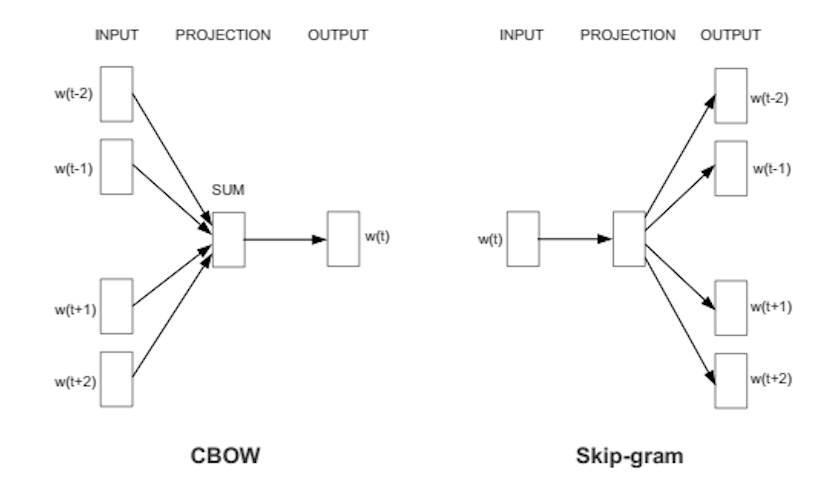
Do những ưu điểm của Skip-gram Model vượt trội hơn người anh em của nó, nên trong bài viết này, mình chỉ đi trọng tâm vào mô hình này.
Skip-gram Model
Mục tiêu: Học trọng số các lớp ẩn, các trọng số này là các words vector
Cách thức: Cho một từ cụ thể ở giữa câu(input word), nhìn vào những từ ở gần và chọn ngẫu nhiên. Mạng neural sẽ cho chúng ta biết xác suất của mỗi từ trong từ vựng về việc trở thành từ gần đó mà chúng ta chọn.
Dưới đây là mô hình kiến trúc của mạng Skip-gram và cách xây dựng training data.
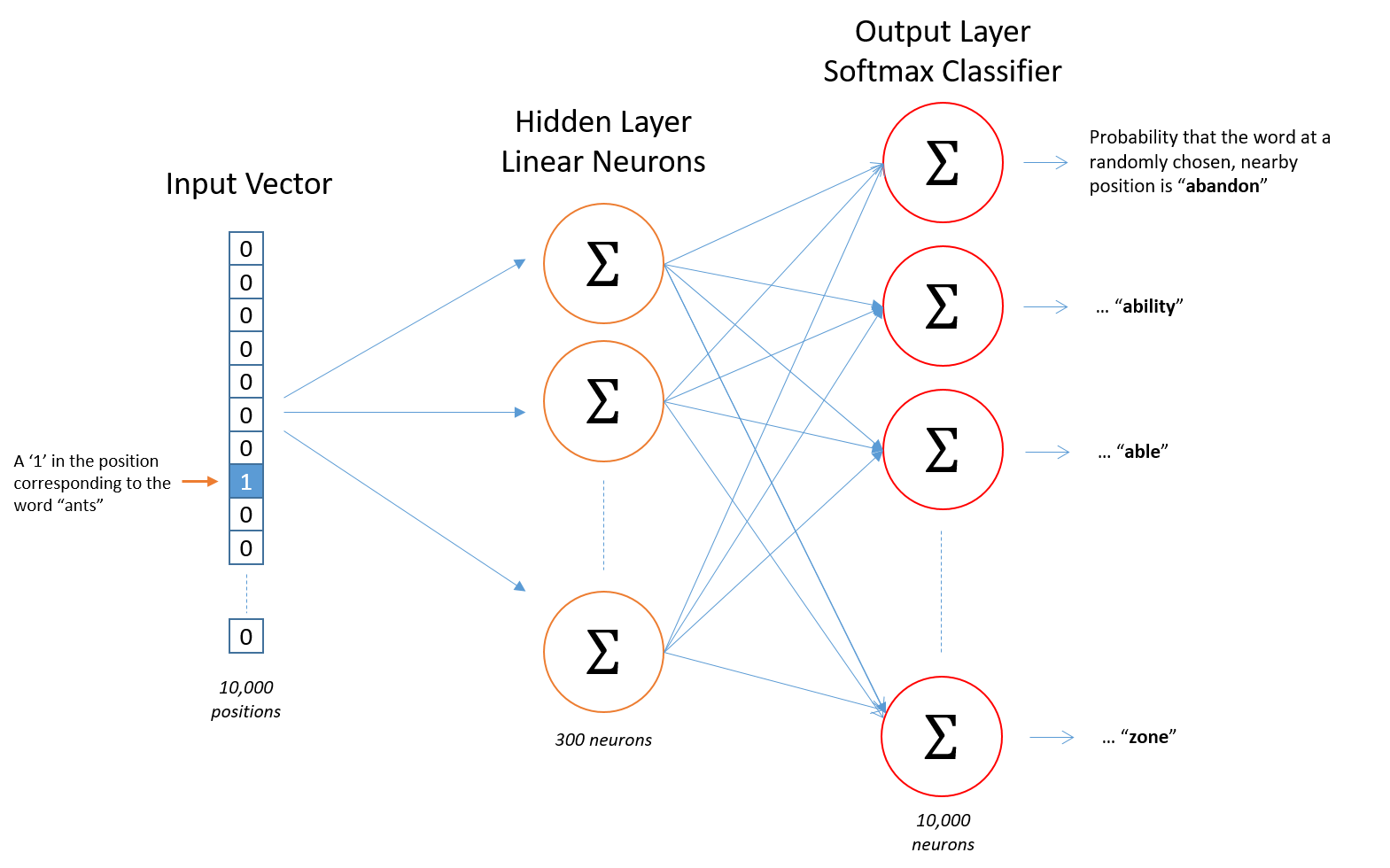
Ví dụ: Xây dựng training data với windows size = 2. Ở đây windows được hiểu như một cửa sổ trượt qua mỗi từ. Windows size = 2 tức là lấy 2 từ bên trái và bên phải mỗi từ trung tâm.
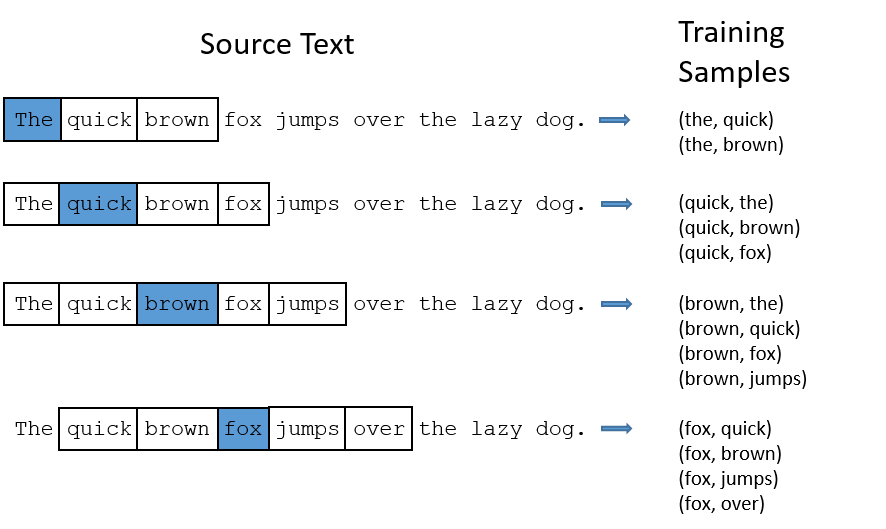
Model details
- Xây dựng bộ từ vựng
- Biểu diễn mỗi từ thành các one-hot-vector
- Đầu ra là một vector duy nhất, có kích thước bằng kích thước của bộ từ vựng, thể hiện xác suất của mỗi từ được là lân cận của từ đầu vào.
- Không có hàm kích hoạt trên tầng ẩn
- Hàm kích hoạt trên tầng output là softmax
- Trong quá trình training, input là 1 one-hotvector, ouput cũng là 1 one-hot-vector
- Trong quá trình đánh giá sau khi training, đầu ra phải là 1 phân bố xác suất.
Vấn đề:
- Mạng Neural lớn: Giả sử words vector với 300 thuộc tính, và từ vựng là 10k từ. Mạng neural có ma trận trọng số lớn, kích thước của ma trận trọng số là 300*10000 bằng 3 triệu giá trị.
- Chạy Gradient Descent sẽ rất chậm.
Word2vec cải tiến
Có 3 cải tiến cơ bản cho mô hình word2vec truyền thống:
- Xử lý các cặp từ thông dụng hoặc cụm từ như là một từ đơn
- Loại bỏ các từ thường xuyên lặp lại để giảm số lượng các ví dụ huấn luyện
- Sửa đổi mục tiêu tối ưu hóa bằng một kỹ thuật gọi là “Negative Sampling”.
Cải tiến 1: Xử lý cụm từ như một từ đơn
Ví dụ các từ như “thành_phố_Cảng” có nghĩa khác nhau với từng từ “thành_phố” và “cảng”,...
Chúng ta sẽ coi như đó là một từ duy nhất, với word vector của riêng mình.
Điều này sẽ làm tăng kích thước từ vựng. (Tìm hiểu thêm về word2phrase)
Cải tiến 2: Loại bỏ các từ thường xuyên lặp lại
Các từ thường xuyên lặp lại như “các”, “những”,… không cho chúng ta biết thêm nhiều hơn về ý nghĩa của những từ đi kèm nó, và chúng cũng xuất hiện trong ngữ cảnh của khá nhiều từ.
Chúng ta sẽ xác định xác suất loại bỏ, giữ lại một từ trong từ vựng thông qua tần suất xuất hiện của nó.
Cải tiến 3: Negative Sampling
Mỗi mẫu huấn luyện chỉ thay đổi một tỷ lệ phần trăm nhỏ các trọng số, thay vì tất cả chúng.
Nhớ lại: Khi huấn luyện mạng với 1 cặp từ, đầu ra của mạng sẽ là 1 one-hot vector, neural đúng thì đưa ra 1 còn hàng ngàn neural khác thì đưa ra 0.
Chọn ngẫu nhiên 1 số lượng nhỏ các neural “negative” kết hợp với neural “positive” để cập nhật trọng số.(chọn là 5-20 hoạt động tốt với các bộ dữ liệu nhỏ, 2-5 với bộ dữ liệu lớn).
Kết quả thú vị của Word2Vec:
Chúng ta cùng phân tích qua một vài kết quả thú vị sử dụng mô hình word2vec. Ví dụ dưới đây là một ví dụ cực kỳ kinh điển của mô hình word2vec. Word vector học từ mô hình word2vec rất phù hợp để tìm ra quan hệ giữa các từ về mặt ngữ nghĩa. Chúng ta có thể tìm mối quan hệ giữa các từ thông qua các phép toán vector.
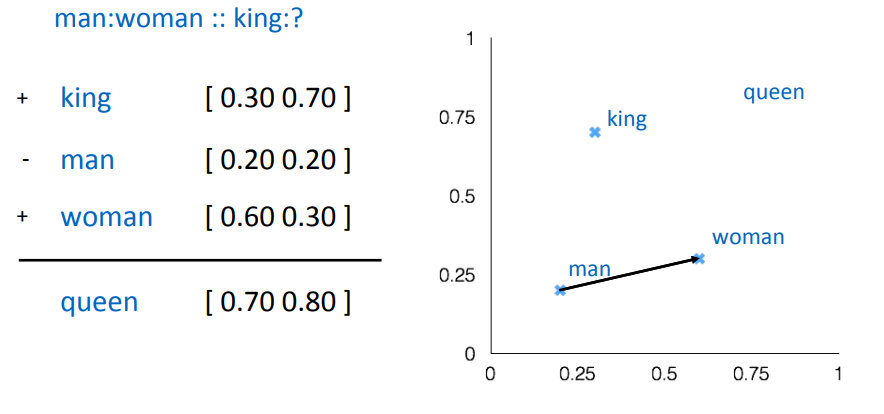
Word vector học từ mô hình word2vec rất phù hợp để trả lời cho câu hỏi:
Nếu A là B thì C là ...
Như ví dụ dưới đây, nếu thủ đô của China là Bắc Kinh thì thủ đô của Nga là thành phố Moscow,...
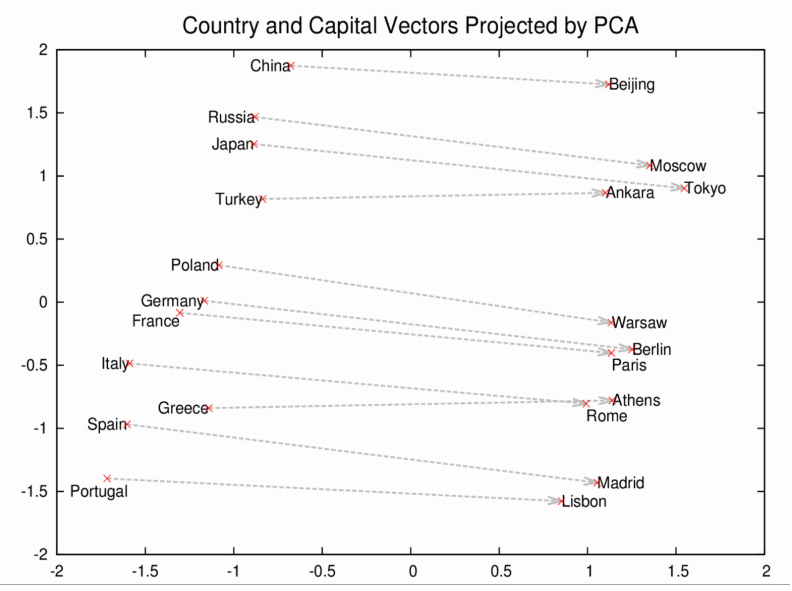
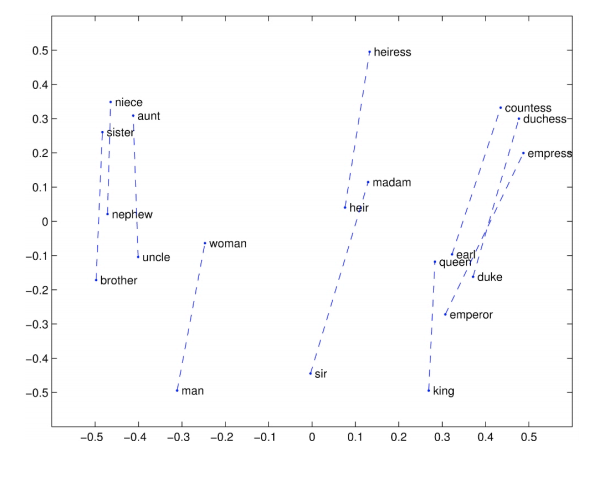
Hay như trong trường hợp này là mối quan hệ về giới tính. Các kết quả này hoàn toàn lấy từ mô hình word2vec.
Trong phần cuối của bài viết này, chắc hẳn các bạn đang nghĩ rằng tại sao chúng ta phải train lại mô hình trong khi đã có các mô hình có sẵn đúng không?
Đơn giản là trong nhiều bài toán, chúng ta train dữ liệu trong một miền cụ thể sẽ cho kết quả tốt hơn nhiều so với dùng mô hình train sẵn. Ví dụ trong bài toán tính độ tương đồng giữa các quốc gia, mình đã thử so sánh việc dùng pre-train model có sẵn của tác giả Trần Việt Trung và việc train dữ liệu chỉ từ các bài báo quốc tế. Kết quả là mô hình mình train lại tốt hơn do word vector được học từ dữ liệu phù hợp với bài toán hơn.
Xây dựng mô hình không gian vector cho Tiếng Việt với VietNam Wikipedia.
-
Chuẩn bị dữ liệu
Bạn có thể tải dữ liệu mới nhất của wikipedia tại đây viwiki. Sau khi có được dữ liệu, bạn thực hiện giải nén zip file. Cài đặt wikiextractor sau đó chạy file WikiExtractor.py theo hướng dẫn để lấy nội dung của wikipedia. Nội dung của dữ liệu đầu ra sẽ có dạng:
<doc id="" revid="" url="" title=""> Nội dung của trang wikipedia.... </doc>
-
Tiền xử lý dữ liệu
Các bước để tiền xử lý dữ liệu bao gồm:
- Loại bỏ thẻ html dư thừa
Sử dụng biểu thức chính quy để xóa bỏ các thẻ html trong dữ liệu.
def clean_text(text): text = re.sub('<.*?>', '', text).strip() text = re.sub('(\s)+', r'\1', text) return text- Tách câu: Do dữ liệu lấy từ wikipedia nên mình có thể đơn giản là tách câu dựa vào dấu câu.
def sentence_segment(text): sents = re.split("([.?!])?[\n]+|[.?!] ", text) return sents- Tách từ
def word_segment(sent): sent = tokenize(sent.decode('utf-8')) return sent- Chuẩn hóa dữ liệu: Xóa dấu(do mình chỉ quan tâm tới word)
def normalize_text(text): listpunctuation = string.punctuation.replace('_', '') for i in listpunctuation: text = text.replace(i, ' ') return text.lower()- Loại stopword
filename = './stopwords.csv' data = pd.read_csv(filename, sep="\t", encoding='utf-8') list_stopwords = data['stopwords'] def remove_stopword(text): pre_text = [] words = text.split() for word in words: if word not in list_stopwords: pre_text.append(word) text2 = ' '.join(pre_text) return text2 -
Train mô hình sử dụng word2vec và fastText
Word2vec
pathdata = './datatrain.txt' def read_data(path): traindata = [] sents = open(pathdata, 'r').readlines() for sent in sents: traindata.append(sent.split()) return traindata if __name__ == '__main__': train_data = read_data(pathdata) model = Word2Vec(train_data, size=150, window=10, min_count=2, workers=4, sg=0) model.wv.save("word2vec_skipgram.model")fastText
Đôi nét về fastText:
Một nhược điểm lớn của word2vec là nó chỉ sử dụng được những từ có trong dataset, để khắc phục được điều này chúng ta có FastText là mở rộng của Word2Vec, được xây dựng bởi facebook năm 2016. Thay vì training cho đơn vị word, nó chia text ra làm nhiều đoạn nhỏ được gọi là n-gram cho từ, ví dụ apple sẽ thành app, ppl, and ple, vector của từ apple sẽ bằng tổng của tất cả cái này. Do vậy, nó xử lý rất tốt cho những trường hợp từ hiếm gặp.
pathdata = './datatrain.txt' def read_data(path): traindata = [] sents = open(pathdata, 'r').readlines() for sent in sents: traindata.append(sent.decode('utf-8').split()) return traindata if __name__ == '__main__': train_data = read_data(pathdata) model_fasttext = FastText(size=150, window=10, min_count=2, workers=4, sg=1) model_fasttext.build_vocab(train_data) model_fasttext.train(train_data, total_examples=model_fasttext.corpus_count, epochs=model_fasttext.iter) model_fasttext.wv.save("../model/fasttext_gensim.model") -
Sử dụng mô hình với một vài ví dụ vui
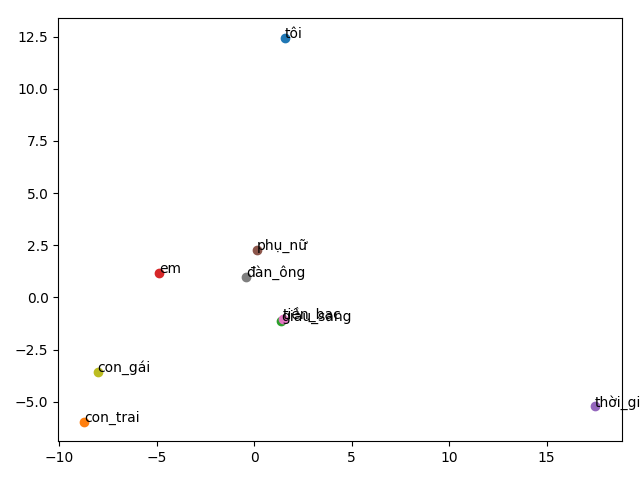
Để có cái hình dung dễ hơn về sự tương đồng ngữ nghía giữa các từ, ở đây mình load lại 2 mô hình vừa train ở trên là visualize lên không gian 2 chiều. Các từ được visualize bao gồm: tôi, phụ nữ, đàn ông, em, con gái, con trai, thời gian, tiền bạc.
![]()
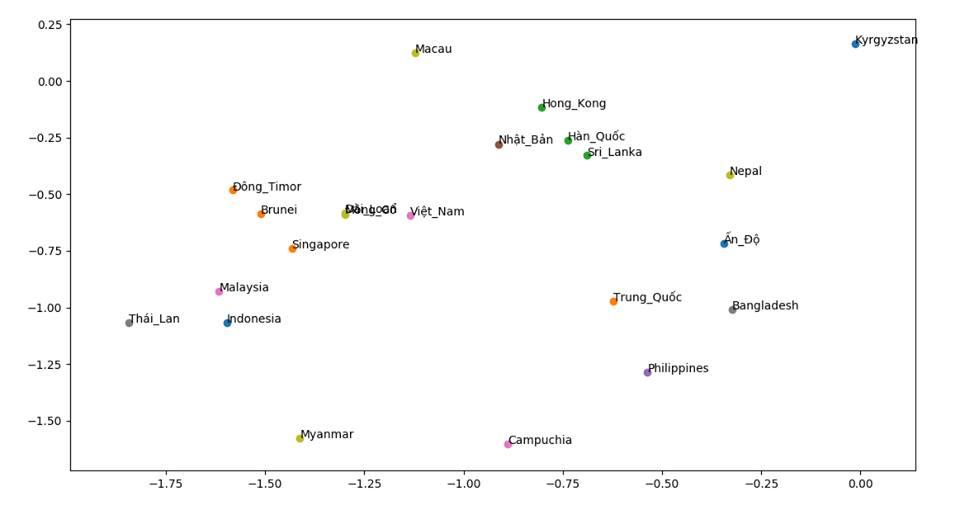
Một project vui khác mà mình thực hiện, để khám phá độ tương đồng về văn hóa các quốc gia trên thế giới. Dữ liệu training bao gồm 350.000 bài báo quốc tế được thu thập từ vnexpress. Kết quả cho thấy sự tương đồng về văn hóa giữa các quốc gia cũng được phân cụm gần tương tự với vị trí địa lý.
![]()
Ngoài ra, bạn cũng có thể tham khảo các phương thức dựng sẵn bở gemsim như tìm ra từ gần nghĩa với từ đầu vào nhất,...và rất nhiều hàm thú vị khác.
from gensim.models import KeyedVectors model = KeyedVectors.load('../model/word2vec_skipgram.model') for word in model.most_similar(u"công_nghệ"): print word[0]
Lời kết
Trong bài viết này, mình đã trình bày về các cách để có thể ánh xạ một từ sang một không gian vector mà vẫn giữ được ý nghĩa của từ thông qua ngữ cảnh của chúng.
Những word vector này là vô cùng quan trọng, là đầu vào cho các thuật toán Machine Learning, Deeplearning trong lĩnh vực xử lý ngôn ngữ tự nhiên sau này.
Cảm ơn các bạn đã quan tâm.
Các nguồn tham khảo:
Code demo:
Github: https://github.com/QuangPH1/FramgiaBlog/tree/master/Blog01_Word_embedding
All rights reserved
