
Làm thế nào để xây dựng một Recommender System (RS) - Phần 1
Bài đăng này đã không được cập nhật trong 4 năm
Bạn đã bao giờ gặp phải những trường hợp như sau:
-
Bố mẹ bạn mới sử dụng Facebook và mới chỉ kết bạn với một vài người thân trong gia đình bạn. Tuy nhiên vài hôm sau, Facebook đã tự gợi ý cho hai cụ những người họ hàng hang hốc của bạn mà thậm chí ngay cả bạn cũng không biết ???
-
Bạn đang dạo chơi trên một trang thương mại điện tử với mục đích ban đầu là tìm một chiếc quần bò nam. Sau đó một loạt các sản phẩm liên quan đến thời trang nam được gợi ý cho bạn nào là balo, túi xách, thắt lưng.... và sau một hồi lang thang trên đó bạn nhận ra rằng mình đã bị cuốn theo những sản phẩm hay ho kia mà đôi khi còn quên mất luôn mục đích mình vào đây để làm gì ???
-
Một buổi chiều cuối tuần ảm đạm, bạn muốn thư giãn hơn bằng cách nghe một bản nhạc bolero cho đúng với tâm trạng, và bạn mở Youtube và tìm kiếm một bản nhạc vàng, nằm xuống giường và thưởng thức âm nhạc, những bài hát tiếp theo sẽ được Youtube thân yêu tự động gợi ý và tất nhiên rất hiểm khi nó gợi ý một bản nhạc rock cho bạn trong khi bạn đang nghe nhạc vàng phải không nào ???
Tất cả những điều bạn vừa thấy dều có một điểm chung đó là hệ thống của chúng ta có khả năng tự tìm kiếm và gợi ý những thứ mà có thể chúng ta rất thích nhưng chưa nghĩ đến, hoặc chưa biết đến nó trong thời diểm hiện tại. Đó chính là công việc của Hệ gợi ý - một trong những bài toán khá hay áp dụng trong lĩnh vực Trí tuệ nhân tạo. Và nếu bạn đang tò mò với những câu hỏi trên thì bài viết này sẽ dành cho bạn.

Hệ thống gợi ý là gì???
Về bản chất chúng ta có thể coi một hệ thống gợi ý giống như một người mai mối. Nó dự đoán sở thích của chúng ta và tìm kiếm các đối tượng tiềm năng phù hợp với sở thích đó để gợi ý cho chúng ta. Giả sử bạn là một gã độc thân vui tính, bạn rất thích những cô gái xinh xắn và năng động, hoạt bát. Nhưng thử tưởng tượng mà xem, sức người có hạn và bạn thì hoàn toàn không thể nào biết hết mặt ngang mũi dọc các mỹ nhân trong thiên hạ. Lúc này bạn rất cần đến một hệ gợi ý như thể một bà mối cho bạn vậy. Dễ hiểu hơn một chút rồi phải không, bây giờ chúng ta sẽ trở lại một ví dụ áp dụng trong một lĩnh vực khá gần gũi với dân IT chúng ta đó là thương mại điện tử.

Hình ảnh trên giúp bạn phần nào hình dung ra vấn đề rồi chứ. Khi bạn mua một sản phẩm, hệ gợi ý sẽ làm công việc là đưa ra các sản phẩm tương tự mà bạn có thể thích mua chúng. Điều này thực sự trở thành một trợ thủ đặc lực cho người tiêu dùng cũng như người bán hàng. Cụ thể cách mà Amazon - trang thương mại điện tử nổi tiếng của thế giới đã làm như sau:
-
Quan tâm đến việc khách hàng yêu thích những sản phẩm nào dựa vào dữ liệu trên quá khứ của họ như điểm đánh giá trên từng sản phẩm, thời gian duyệt trên từng sản phẩm, số lần click vào sản phẩm...
-
Từ đó có thể dự đoán được người dùng có thể sẽ thích những sản phẩm nào khác và đưa ra gợi ý phù hợp cho họ
Cũng khá dễ hiểu phải không nào. Vậy một hệ gợi ý sẽ bao gồm những thành phần cơ bản nào, và làm cách nào để xây dựng một hệ gợi ý. Chúng ta sẽ tiếp tục tìm hiểu nhé
Các thành phần cơ bản của một hệ gợi ý.
Như chúng ta đã biết, để làm việc hay xây dựng một hệ thống thông tin mới thì chúng ta cần phải định hình được mình sẽ cần những thành phần gì để tạo ra chúng. Đơn giản là những điều vĩ đại đều được xây dựng từ những điều nhỏ bé phải không nào... Nếu đã nói đến một hệ thống gợi ý được tiếp cận theo phương pháp Machine Learning thì chúng ta cần phải xem xét đến ba đặc điểm cơ bản như sau
- Thứ nhất: Điều đầu tiên cần phải quan tâm đó chính là ***người dùng (user)***, hiển nhiên rồi, nếu không có user thì chúng ta biết gợi ý cho ai
- Thứ hai : Chúng ta cần phải quan tâm đến mục tin (items) các mục tin này có thể là sản phẩm trên các trang bán hàng, bài hát trên các trang nghe nhạc, một user khác như trên mạng xã hội hay một bài viết như trên Viblo cuả chúng ta chẳng hạn. Tại sao cần phải quan tâm đến mục tin bởi vì nếu không có mục tin thì chúng ta lấy cái gì mà gợi ý cho người dùng. Đúng không các bạn
- Thứ ba: Chúng ta cần phải quan tâm đến phản hồi (feedback) của mỗi user lên mục tin đó. Nó có thể là điểm đánh giá, có thể là một chỉ số thể hiện sự quan tâm của user lên item đó.... Đơn giản là vì chúng ta phải định lượng được các đại lượng này thì mới có thể có cơ sở gợi ý cho người dùng phải không nào
Biểu diễn thông tin bằng ma trận users - items
Sau khi chúng ta đã thu thập được các thông tin trên của hệ thống bằng một cách nào đó chúng ta cần phải biểu diễn các thông tin đó dưới dạng có thể tính toán được. Một ý tưởng tuyệt vời đó là sử dụng ma trận, một ma trân được tạo ra thể hiện độ thích của từng user lên các item tương ứng được biểu diễn như sau:
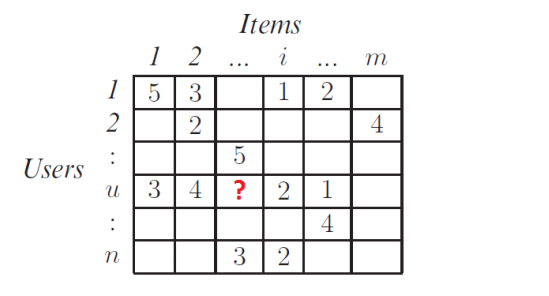 Trong ma trận có những ô có trọng số sẽ thể hiện được mức độ yêu thích của mỗi user lên các item. Mặt khác cũng có những ô còn trống thể hiện user chưa từng tiếp cận được với item. Chính điều này thể hiện vai trò của một hệ gợi ý, đó chính là dựa vào các thông tin được biết trong quá khứ của người dùng, hệ gợi ý sẽ gợi ý cho người dùng đó các thông tin mà người dùng chưa biết. Tức là dự đoán các giá trị tại các ô còn trống trong ma trận trên rồi sắp xếp theo thứ tự độ thích giảm dần để gợi ý cho người dùng
Trong ma trận có những ô có trọng số sẽ thể hiện được mức độ yêu thích của mỗi user lên các item. Mặt khác cũng có những ô còn trống thể hiện user chưa từng tiếp cận được với item. Chính điều này thể hiện vai trò của một hệ gợi ý, đó chính là dựa vào các thông tin được biết trong quá khứ của người dùng, hệ gợi ý sẽ gợi ý cho người dùng đó các thông tin mà người dùng chưa biết. Tức là dự đoán các giá trị tại các ô còn trống trong ma trận trên rồi sắp xếp theo thứ tự độ thích giảm dần để gợi ý cho người dùng
Phân loại hệ thống gợi ý
Chúng ta hãy tưởng tượng hai tình huống như sau:
Khi chúng ta đi mua hàng trên một trang thương mại điện tử, chúng ta đang tìm hiểu lựa chọn mặt hàng áo phông nam Quảng Châu, hệ thống sẽ có gợi ý cho chúng ta những mặt hàng áo phông nam tương tự như sản phẩm của chúng ta đang tìm. Sang một trang nghe nhạc, bạn tham gia vào một channel gồm những người yêu thích nhạc cách mạng và hệ thống sẽ gợi ý cho bạn những bài nhạc cách mạng mà thành viên của channel đố thường nghe
Hai tình huống trên chính là hai loại hệ thống gợi ý:
- Hệ thống gợi ý dựa trên nội dung - Content based recommender systems: tức là hệ thống sẽ quan tâm đến nội dung, đặc điểm của mục tin hiện tại và sau đó gợi ý cho người dùng các mục tin tương tự. Đó chính là trường hợp thứ nhất
- Hệ thống gợi ý dựa trên các user - lọc cộng tác - Collaborative filtering recommender systems: tức là hệ thống sẽ phân tích các user có cùng đánh giá, cùng mua mục tin hiện tại. Sau đó tìm ra danh sách các mục tin khác cũng được đánh gía bởi các user này, xếp hạng và gợi ý cho người dùng. Tư tưởng của phương pháp này chính là dựa trên sự tương đồng về sở thích giữa các người dùng để đưa ra các gợi ý.

Vậy chúng ta nên sử dụng phương pháp nào???
Có một điều dễ nhận thấy thì phương pháp gợi ý dựa trên nội dung đòi hỏi chúng ta phải thu thập rất nhiều thông tin về các mục tin tương tự . Chính việc xác định xem một mục tin nào là tương tự với mục tin hiện tại đòi hỏi chúng ta phải thu thập và phần tích, xử lý toàn bộ các mục tin trong cơ sở dữ liệu. Tuy nhiên với phương pháp lọc công tác chúng ta không cần quá nhiều thông tin. Đơn giản chỉ là item_id của item hiện tại, các user_id và các feedback trên item đó mà thôi nên thực tế thì phương pháp lọc cộng tác được sử dụng phổ biến hơn để xây dựng các hệ thống gợi ý
Những bước cần làm để xây dựng một hệ thống gợi ý
Thu thập dữ liệu
Nếu chúng ta đơn giản chỉ quan tâm đến việc rating của user với item thì vấn đề trở nên khá đơn giản, dữ liệu của chúng ta đã có sẵn trong DB. Tuy nhiên tùy vào bài toán cụ thể mà không phải lúc nào những chỉ số của chúng ta là tường mình và có sẵn và chính vì thế chúng ta cần phải có một kế hoạch để thu thập các chỉ số thể hiện mối tương quan này trước khi chúng ta định xây dựng một hệ thống gợi ý. Một vài chỉ số có thể dùng để thay thế điểm rating như sau:
- Số lần click chuột vào item
- Thời gian trung bình thao tác với item
- ....
Sau quá trình thu thập chúng ta có rất nhiều dữ liệu ở các phiên làm việc khác nhau tương ứng với các thao tác khác nhau của một user đối với item. Sau khi xử lý bằng các xử lý toàn học không đi sâu ở đây, chúng ta sẽ thu được một chỉ số duy nhất giữa một cặp user-item. Việc cần làm tiếp theo đó là chuẩn hóa dữ liệu
Chuẩn hóa dữ liệu
 Ma trận dữ liệu của chúng ta chủ yếu là ma trận thưa tức là số lượng dữ liệu còn trống là rất nhiều, chính vì thế nên chúng ta cần phải chuẩn hóa đống dữ liệu này mới có thể áp dụng các thuật toán học máy trên đó được. Sau khi chuẩn hóa dữ liệu, chúng ta sẽ xây dựng mô hình học máy để tính toán độ tương tự giữa các user. Mình sẽ nói chi tiết phần này trong các bài viết tiếp theo
Ma trận dữ liệu của chúng ta chủ yếu là ma trận thưa tức là số lượng dữ liệu còn trống là rất nhiều, chính vì thế nên chúng ta cần phải chuẩn hóa đống dữ liệu này mới có thể áp dụng các thuật toán học máy trên đó được. Sau khi chuẩn hóa dữ liệu, chúng ta sẽ xây dựng mô hình học máy để tính toán độ tương tự giữa các user. Mình sẽ nói chi tiết phần này trong các bài viết tiếp theo
Chạy mô hình, lọc ra top N item phù hợp
Sau khi lựa chọn được mô hình phù hợp chúng ta sẽ tiến hành chạy mô hình đó và lựa chọn ra top N item sử dụng để gợi ý cho người dùng
Đánh giá mô hình
Cũng như các bài toán học máy khác, chúng ta cũng cần đánh giá mô hình dựa trên tập dữ liệu kiểm tra. Tuy nhiên do đặc thù của bài toán sẽ có những phương pháp đánh giá khác nhau. Do phạm vi bài viết quá dài nên hiện tại mình chưa trình bày kĩ ở đây. Hẹn gặp các bạn trong các bài viết tiếp theo
Kết luận
Qua bài viết này hi vọng chúng ta đã phần nào hiểu được một cách tổng quan nhất về hệ thống gợi ý. Khi triển khai mô hình trong thực tế cần phải chú ý một số đặc điểm nữa như sau:
- Cần bổ sung thêm một số luật để chọn ra được top N item phù hợp hơn với từng user.
- Không cho hiển thị những sản phẩm đã được mua trong danh sách gợi ý.
- Cần một kế hoạch cập nhật lại mô hình thông qua tập dữ liệu mới sinh ra hàng ngày.
To be continue...
All rights reserved
