
Xây dựng mô hình Transformer cơ bản dịch tiếng Nhật sang tiếng Việt
Bài đăng này đã không được cập nhật trong 4 năm
I. Mở đầu
Trong bài viết này, mình sẽ hướng dẫn mọi người xây dựng mô hình transformer cơ bản cho dịch ngôn ngữ Nhật-Việt, trong bài viết trước đó của mình về Neural Machine Translation mình đã nêu ra một số khái niệm cơ bản của Seq2Seq(link ở phần tài liệu tham khảo), bởi vì trên Viblo đã có khá nhiều bài viết về Transformer cũng như Self-Attention hay, nên mình sẽ tiến hành hướng dẫn mọi người thực hiện code from scratch(một số bài viết về Transformer mình có để bên dưới tại mục tài liệu tham khảo).
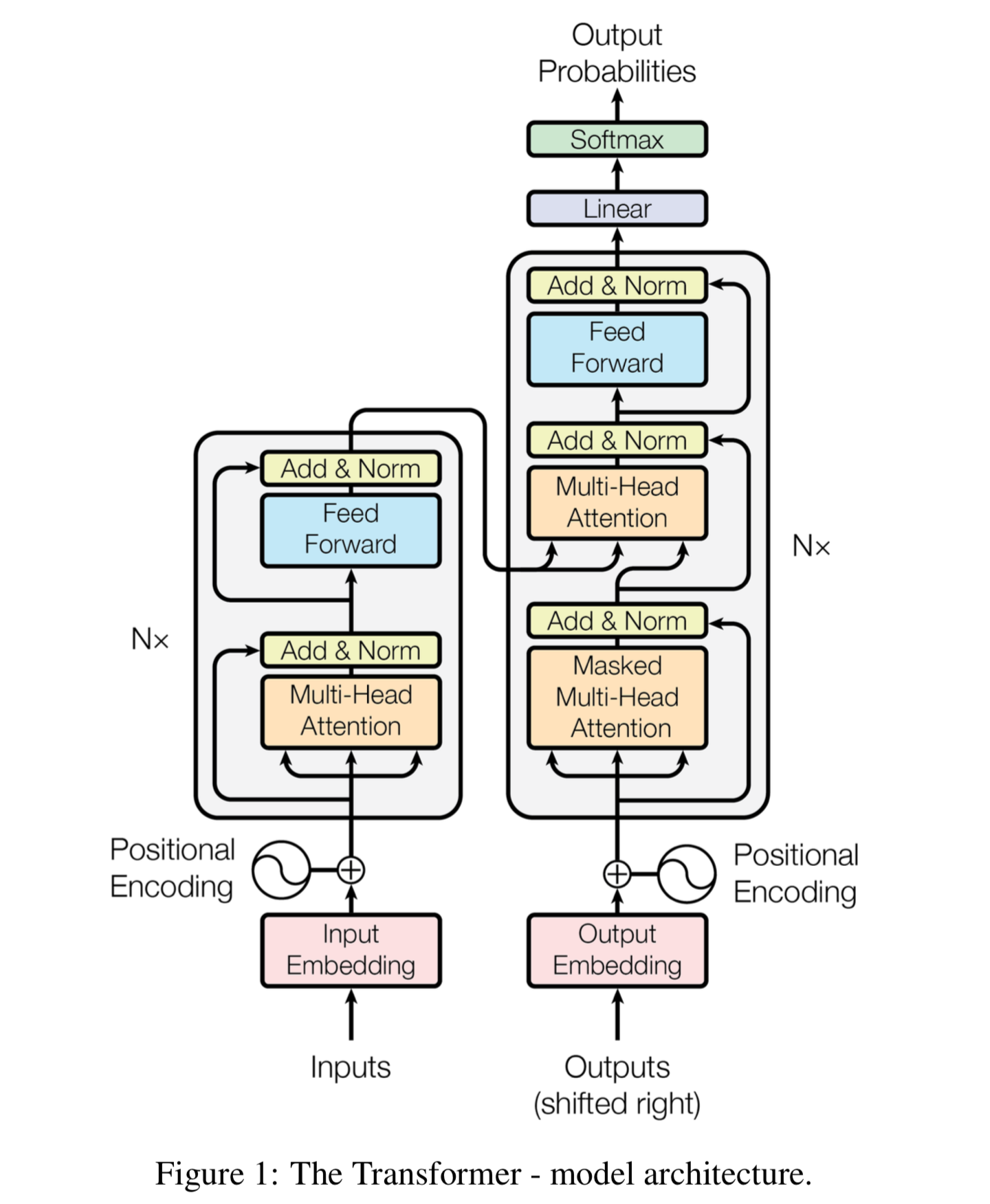
II. Tiến hành
Cài đặt số thư viện cần thiết
Mình sẽ không hướng dẫn cài PyTorch vì do hardware của mỗi người là khác nhau.
!pip install pyvi
!pip install -U pip setuptools wheel
!pip install -U spacy
!python -m spacy download ja_core_news_sm
!pip install torchtext
Dataset
Trong bài này, mình sẽ dùng bộ data: Tatoeba 2K để demo mô hình, các bạn có xem thêm data trong repo này: https://github.com/ngovinhtn/JaViCorpus/.
Chúng ta sẽ dùng những thao tác đọc file cơ bản để đưa dữ liệu vào trong code (lưu ý nhớ sửa file path)
vi_input = []
with open(f"data_vi.txt") as f:
for line in f:
line = line.replace(' ', ' ').lower()
vi_input.append(line.strip())
jp_input = []
with open(f"data_ja.txt") as f:
for line in f:
jp_input.append(line.strip())
Tokenzie data
Chúng ta sẽ import 2 thư viện là ViTokenizer và Spacy để phục vụ cho việc tokenize data
from pyvi import ViTokenizer
import spacy
vi_tokenized = [ViTokenizer.tokenize(i).split() for i in vi_input]
jp_tokenizer = spacy.load('ja_core_news_sm')
jp_tokenized = [[] for i in range(len(jp_input))]
for idx, data in enumerate(jp_input):
tokenized = jp_tokenizer(data)
for token in tokenized:
jp_tokenized[idx].append(str(token))
Build Vocab
Ở đây, mình dùng Torchtext để đơn giản hóa việc xây dựng vocab cho cả source language(Tiếng Nhật) và target language(Tiếng Việt). Ta sẽ phải thêm 1 số special symbols. Những special symbols có những nhiệm vụ sau:
- <unk> để đại diện cho những từ không tồn tại trong vocab
để cân bằng độ dài giữa các câu khi training theo batch(vì các câu trong 1 batch cần có độ dài bằng nhau mà các câu trong bộ data hầu hết là khác độ dài nên cần thêm padding)
- <bos> để đánh dấu bắt đầu câu
- <eos> để đánh dấu kết thúc câu
Lưu ý: các bạn nên tra cứu khi sử build_vocab_from_iterator để hiểu rõ hơn về hàm này.
from torchtext.vocab import build_vocab_from_iterator
SRC_LANGUAGE = 'jp'
TGT_LANGUAGE = 'vn'
vocab_transform = {}
special_symbols = ['<unk>', '<pad>', '<bos>', '<eos>']
UNK_IDX, PAD_IDX, BOS_IDX, EOS_IDX = 0, 1, 2, 3
def yield_tokens(lang_tokenized):
for i in lang_tokenized:
yield i
vocab_transform[SRC_LANGUAGE] = build_vocab_from_iterator(yield_tokens(jp_tokenized), min_freq=1, specials=special_symbols, special_first=True)
vocab_transform[TGT_LANGUAGE] = build_vocab_from_iterator(yield_tokens(vi_tokenized), min_freq=1, specials=special_symbols, special_first=True)
Ta sẽ set default cho những từ không xuất hiện trong vocab với index là UNK_IDX.
vocab_transform[SRC_LANGUAGE].set_default_index(UNK_IDX)
vocab_transform[TGT_LANGUAGE].set_default_index(UNK_IDX)
Import thư viện cần training và kiểm tra hardware
Vì hardware của mỗi máy là khác nhau cho nên mọi người cần để ý phần này, ở đây mình dùng cuda(Lưu ý khi cài torch)
import torch.nn as nn
import torch.nn.functional as F
import math
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Tính toán Attention
Tiếp theo ta sẽ xây dựng hàm tính attention, phần mask của mình tương đối khó hiểu(mình sẽ giải thích qua về nó trong phần dưới)
def attention(q, k, v, mask=None, dropout=None):
d_k = q.size(-1)
dot_product = torch.bmm(q, k.transpose(1, 2)) / math.sqrt(d_k)
if mask is not None:
for i in range(0, dot_product.size(0), mask.size(0)):
dot_product[i: i+mask.size(0)] = (dot_product[i: i+mask.size(0)]).masked_fill(mask == 0, -1e9)
scores = dot_product
else:
scores = dot_product
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.bmm(p_attn, v)
MultiHeadAttention
Để hiểu được phần này, các bạn nên đọc kỹ về những bài viết liên quan đến Transformer(mình có để ở phần tài liệu tham khảo) và cần nắm vững cách sử dụng những câu lệnh căn bản của torch.nn và torch.Tensor
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.linears = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(4)])
self.dropout = nn.Dropout(dropout)
self.d_k = d_model // num_heads
def forward(self, q, k, v, mask=None):
q = self.linears[0](q)
k = self.linears[1](k)
v = self.linears[2](v)
def _split_heads(tensor):
bsz, length, embed_dim = tensor.size()
tensor = tensor.reshape(bsz, length, self.num_heads, self.d_k).transpose(1, 2).reshape(bsz * self.num_heads, -1, self.d_k)
return tensor
q = _split_heads(q)
k = _split_heads(k)
v = _split_heads(v)
output = attention(q, k, v, mask=mask, dropout=self.dropout)
bsz_heads, length, d_k = output.size()
bsz = bsz_heads // num_heads
output = output.reshape(bsz, num_heads, length, self.d_k).transpose(1, 2).reshape(bsz, length, -1)
return self.linears[3](output)
Position-wise Feed-Forward
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(FeedForward, self).__init__()
self.d_model = d_model
self.d_ff = d_ff
self.dropout = nn.Dropout(dropout)
self.linear_in = nn.Linear(d_model, d_ff)
self.linear_out = nn.Linear(d_ff, d_model)
def forward(self, x):
y = F.relu(self.linear_in(x))
y = self.linear_out(self.dropout(y))
return y
LayerNorm
Ở đây theo mình đã thay đổi kiến trúc của Transformer một chút, giúp tránh đi vanishing gradient bằng việc tính toán LayerNorm trước rồi sau đó mới thực hiện Skip-Connection.(Điều này được trình bày trong paper thứ 2 ở phần tài liệu tham khảo).
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = nn.LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
Encoder BLock
class EncoderBlock(nn.Module):
def __init__(self, d_model, d_ff, num_heads, dropout=0.1):
super(EncoderBlock, self).__init__()
self.SelfMultiHeadAttention = MultiHeadAttention(d_model, num_heads, dropout)
self.FeedForward = FeedForward(d_model, d_ff, dropout)
self.sublayer = nn.ModuleList([SublayerConnection(d_model, dropout) for _ in range(2)])
self.d_model = d_model
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.SelfMultiHeadAttention(x, x, x, mask))
return self.sublayer[1](x, self.FeedForward)
Encoder
Xây dựng encoder dựa trên MultiEncoderBlock
class Encoder(nn.Module):
def __init__(self, d_model, d_ff, num_heads, num_layers, dropout=0.1):
super(Encoder, self).__init__()
self.layers = nn.ModuleList([EncoderBlock(d_model, d_ff, num_heads, dropout) for _ in range(num_layers)])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
DecoderBLock
class DecoderBlock(nn.Module):
def __init__(self, d_model, d_ff, num_heads, dropout=0.1):
super(DecoderBlock, self).__init__()
self.SelfMultiHeadAttention = MultiHeadAttention(d_model, num_heads, dropout)
self.MultiHeadAttention = MultiHeadAttention(d_model, num_heads, dropout)
self.FeedForward = FeedForward(d_model, d_ff, dropout)
self.sublayer = nn.ModuleList([SublayerConnection(d_model, dropout) for _ in range(3)])
self.d_model = d_model
def forward(self, x, memory, tgt_mask):
x = self.sublayer[0](x, lambda x: self.SelfMultiHeadAttention(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.MultiHeadAttention(x, memory, memory))
return self.sublayer[2](x, self.FeedForward)
Decoder
Tương tự như việc xây dựng Encoder
class Decoder(nn.Module):
def __init__(self, d_model, d_ff, num_heads, num_layers, dropout=0.1):
super(Decoder, self).__init__()
self.layers = nn.ModuleList([DecoderBlock(d_model, d_ff, num_heads, dropout) for _ in range(num_layers)])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, memory, tgt_mask):
for layer in self.layers:
x = layer(x, memory, tgt_mask)
return self.norm(x)
PositionalEncoding
Xây dựng mã hóa theo vị trí cho Embeded tokens và kết hợp với TokenEmbedding để tạo ra đầu vào cho encoder và decoder
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
den = torch.exp(- torch.arange(0, d_model, 2) * math.log(10000) / d_model)
pos = torch.arange(0, max_len).reshape(max_len, 1)
pos_embedding = torch.zeros((max_len, d_model))
pos_embedding[:, 0::2] = torch.sin(den * pos)
pos_embedding[:, 1::2] = torch.cos(den * pos)
self.register_buffer('pos_embedding', pos_embedding)
def forward(self, token_embedding):
return self.dropout(token_embedding + self.pos_embedding[:token_embedding.size(1), :])
TokenEmbedding
class TokenEmbedding(nn.Module):
def __init__(self, d_model, vocab_size):
super(TokenEmbedding, self).__init__()
self.token_embedding = nn.Embedding(vocab_size, d_model)
self.d_model = d_model
def forward(self, tokens):
return self.token_embedding(tokens.long()) * math.sqrt(self.d_model)
Model Transformer
class Seq2SeqTransformer(nn.Module):
def __init__(self,
num_encoder_layers,
num_decoder_layers,
d_model, d_ff,
src_vocab_size,
tgt_vocab_size,
num_heads, dropout):
super(Seq2SeqTransformer, self).__init__()
self.pos_encoding = PositionalEncoding(d_model, dropout)
self.src_tok_emb = TokenEmbedding(d_model, src_vocab_size)
self.tgt_tok_emb = TokenEmbedding(d_model, tgt_vocab_size)
self.encoder = Encoder(d_model, d_ff, num_heads, num_encoder_layers, dropout)
self.decoder = Decoder(d_model, d_ff, num_heads, num_decoder_layers, dropout)
self.generator = nn.Linear(d_model, tgt_vocab_size)
def forward(self, src_input_tensor, tgt_input_tensor, src_mask, tgt_mask, padding_mask=None):
src_emb = self.pos_encoding(self.src_tok_emb(src_input_tensor))
tgt_emb = self.pos_encoding(self.tgt_tok_emb(tgt_input_tensor))
output_encoder = self.encoder(src_emb, src_mask)
output_decoder = self.decoder(tgt_emb, output_encoder, tgt_mask, padding_mask)
return self.generator(output_decoder)
def encode(self, src_input_tensor, src_mask):
src_emb = self.pos_encoding(self.src_tok_emb(src_input_tensor))
output_encoder = self.encoder(src_emb, src_mask)
return output_encoder
def decode(self, tgt_input_tensor, tgt_mask, memory, padding_mask=None):
tgt_emb = self.pos_encoding(self.tgt_tok_emb(tgt_input_tensor))
output_decoder = self.decoder(tgt_emb, memory, tgt_mask, padding_mask)
return self.generator(output_decoder)
Mask Funtions
Như ở phần attention trên mình có nói về mask, thì mask ở đây có 2 nhiêm vụ:
- Tạo ra padding_mask giúp chúng ta biết phần nào là padding để có thể loại bỏ nó trong lúc tính Attention( cụ thể là sau khi tính scores xong thì bắt đầu cần padding_mask để nhận biết padding khi thực hiện torch.bmm(scores, V)
- Tạo ra mask_src và mask_tgt, vì source language không cần che đi bất cứ phần nào lúc tính toán scores cho attention nên chỉ đơn giản dùng torch.ones như bên dưới là xong, còn target language thì phức tạp hơn một chút khi cần che đi phần phía trước.
def create_mask(batch, lang):
assert lang == 'src' or lang == 'tgt'
bsz, length = batch.size()
mask = torch.ones(bsz, length, length)
if lang == 'src':
return mask.to(DEVICE)
else:
return torch.triu(mask).transpose(1, 2).to(DEVICE)
def create_padding_mask(batch):
bsz, length = batch.size()
padding_mask = (batch != PAD_IDX).unsqueeze(-1)
return padding_mask.to(DEVICE)
def create_std_mask(padding_mask, mask, position):
assert position == 'encoder' or position == 'decoderI' or position == 'decoderII'
if position == 'encoder':
padding_mask = torch.bmm(padding_mask.float(), padding_mask.transpose(1, 2).float())
mask = padding_mask * mask
elif position == 'decoderI':
padding_mask = torch.bmm(padding_mask.float(), padding_mask.transpose(1, 2).float())
mask = padding_mask * mask
else:
mask = torch.bmm(mask.float(), padding_mask.transpose(1, 2).float())
return mask.long().to(DEVICE)
Tạo ra 1 instance cụ thể của Transformer
Ở đây chúng ta tạo instance và định nghĩa loss function cũng như việc sử dụng optimizer(Ở đây mình dùng Adam)
torch.manual_seed(0)
src_vocab_size = len(vocab_transform[SRC_LANGUAGE])
tgt_vocab_size = len(vocab_transform[TGT_LANGUAGE])
d_model = 512
num_heads = 8
d_ff = 512
batch_size = 64
num_encoder_layers = 3
num_decoder_layers = 3
dropout = 0.1
transformer = Seq2SeqTransformer(num_encoder_layers, num_decoder_layers, d_model, d_ff, src_vocab_size, tgt_vocab_size, num_heads, dropout)
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
transformer = transformer.to(DEVICE)
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimizer = torch.optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
Tạo padding cho câu và transform token sang dạng logits
Lưu ý rằng pad_sequence sẽ tự động chuyển chiều batch_size lên thứ 1 thay vì 0 như lúc đầu( batch_size, length -> lenght, batch_size)
from torch.nn.utils.rnn import pad_sequence
from typing import List
def sequential_transform(*transforms):
def func(tokens_input):
for transform in transforms:
tokens_input = transform(tokens_input)
return tokens_input
return func
def tensor_transform(tokens_ids: List[int]):
return torch.cat((torch.tensor([BOS_IDX]),
torch.tensor(tokens_ids),
torch.tensor([EOS_IDX])))
text_transform = {}
for ln in [SRC_LANGUAGE, TGT_LANGUAGE]:
text_transform[ln] = sequential_transform(vocab_transform[ln],
tensor_transform)
def collate_fn(batch):
src_batch, tgt_batch = [], []
for src_sample, tgt_sample in batch:
src_batch.append(text_transform[SRC_LANGUAGE](src_sample))
tgt_batch.append(text_transform[TGT_LANGUAGE](tgt_sample))
src_batch = pad_sequence(src_batch, padding_value=PAD_IDX)
tgt_batch = pad_sequence(tgt_batch, padding_value=PAD_IDX)
return src_batch, tgt_batch
Tạo hàm train theo epoch
from torch.utils.data import DataLoader
def greedy_decode(model, src, max_len, start_symbol, src_mask=None):
src = src.to(DEVICE)
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(DEVICE)
for i in range(max_len-1):
memory = memory.to(DEVICE)
tgt_mask = create_mask_tgt(ys.size(-1)).to(DEVICE)
out = model.decode(ys.reshape(1, -1), tgt_mask, memory)
prob = out[:, -1]
_, next_word = torch.max(prob, dim=-1)
next_word = next_word.item()
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)
if next_word == EOS_IDX:
break
return ys
def train_epoch(model, optimizer):
model.train()
losses = 0
train_iter = [i for i in zip(jp_tokenized, vi_tokenized)]
train_dataloader = DataLoader(train_iter, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
for src, tgt in train_dataloader:
src = src.transpose(0, 1).to(DEVICE)
tgt = tgt.transpose(0, 1).to(DEVICE)
tgt_input = tgt[:, :-1]
src_mask, tgt_mask = create_mask(src, 'src'), create_mask(tgt_input, 'tgt')
src_padding_mask, tgt_padding_mask = create_padding_mask(src), create_padding_mask(tgt_input)
src_mask = create_std_mask(src_padding_mask, src_mask, 'encoder').long()
tgt_mask = create_std_mask(tgt_padding_mask, tgt_mask, 'decoderI').long()
last_mask = create_std_mask(src_padding_mask, tgt_padding_mask, 'decoderII').long()
logits = model(src, tgt_input, src_mask , tgt_mask, last_mask)
optimizer.zero_grad()
tgt_out = tgt[:, 1:]
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
loss.backward()
optimizer.step()
losses += loss.item()
return losses / len(train_dataloader)
Training
from timeit import default_timer as timer
NUM_EPOCHS = 20
for epoch in range(1, NUM_EPOCHS+1):
start_time = timer()
train_loss = train_epoch(transformer, optimizer)
end_time = timer()
print((f"Epoch: {epoch}, Train loss: {train_loss:.3f}, "f"Epoch time = {(end_time - start_time):.3f}s"))
Greedy decode
def greedy_decode(model, src, src_mask, max_len, start_symbol):
src = src.to(DEVICE)
src_mask = src_mask.to(DEVICE)
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(DEVICE)
for i in range(max_len-1):
memory = memory.to(DEVICE)
tgt_mask = create_mask_tgt(ys.size(-1)).to(DEVICE)
out = model.decode(ys.reshape(1, -1), tgt_mask, memory)
prob = out[:, -1]
_, next_word = torch.max(prob, dim=-1)
next_word = next_word.item()
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)
if next_word == EOS_IDX:
break
return ys
Hàm translate thực hiện dịch Tiếng Nhật sang Tiếng việt
def translate(model: torch.nn.Module, src_sentence: str):
model.eval()
src_token = [str(i) for i in jp_tokenizer(src_sentence)]
src = text_transform[SRC_LANGUAGE](src_token).unsqueeze(0)
num_tokens = src.shape[-1]
tgt_tokens = greedy_decode(
model, src, max_len=num_tokens + 5, start_symbol=BOS_IDX)
return " ".join(vocab_transform[TGT_LANGUAGE].lookup_tokens(list(tgt_tokens.cpu().numpy()))).replace("<bos>", "").replace("<eos>", "")
Thử nghiệm 1 vài câu nào
print(translate(transformer, '今何時ですか'))
![]()
III. Tổng kết
- Do bộ dự liệu của mình khá ít và bài viết chỉ ở mức độ hiểu transformer nên mình không thực hiện đánh giá tổng quan model mà chỉ tiến hành training.
- Transformer cơ bản còn nhiều hạn chế, đặc biệt là việc dịch long dependencies cũng như positional encoding của nó là cố định.
- Transformer hiệu quả hơn LSTM khá nhiều nếu có lượng dữ liệu lớn.
- Do mình chưa thực hiện tách ngược lại ViTokenizer nên đầu ra có phần hơi đểu =))) mong mọi người thông cảm
IV. Tài liệu tham khảo
-
https://arxiv.org/abs/1706.03762 - paper về transformer
-
https://arxiv.org/abs/1910.05895 - paper cải thiện transformer sử dụng preNorm thay vì LayerNorm giúp tránh vanshing gradient
-
https://arxiv.org/abs/1901.02860 - paper về transformer XL giúp cải thiện khả năng dịch long dependencies và mã hóa tương đối dữ liệu thay vì tuyệt đối của transformer cơ bản
-
https://viblo.asia/p/tan-man-ve-self-attention-07LKXoq85V4 - blog về self-attention của anh Mạnh team mình.
-
https://viblo.asia/p/transformers-nguoi-may-bien-hinh-bien-doi-the-gioi-nlp-924lJPOXKPM - bài viết về transformer của anh Việt Anh
cũng team mình luôn )
)6.https://viblo.asia/p/tong-quan-ve-neural-machine-translation-E375zrMd5GW - bài viết tổng quan về NMT của mình
All rights reserved
