
Tản mạn về Self Attention
Bài đăng này đã không được cập nhật trong 5 năm
Self attention hay intra-attention - cụm từ chắc hẳn đã được đồng đạo trong giới Machine Learning biết đến nhiều qua một bài báo rất nổi tiếng Attention is All You Need đề cập đến mô hình Transfomer đã và đang làm mưa làm gió trong nhiều lĩnh vực từ xử lý ngôn ngữ tự nhiên đến xử lý ảnh ... Self Attention chính là một trong những phần cốt yếu đóng góp nên sự thành công trong mô hình này. Tuy nhiên, đây không phải là lần đầu tiên khái niệm Self Attention xuất hiện. Trước đó khái niệm này tồn tại dưới một cái tên khác đã được giới thiệu trong bài báo Long Short-Term Memory-Networks for Machine Reading nhằm cải tiến những nhược điểm cách xử lý tuần tự của các mô hình như LSTM hay GRU.
Hôm nay mình cùng các bạn cùng phân tích hành trình của Self Attention cho đến bây giờ nhé. Let's go
 Màu đỏ miêu tả từ đang xét hiện tại. Màu tím thể hiện mức độ liên quan giữa từ hiện tại với các từ đằng trước nó.
Màu đỏ miêu tả từ đang xét hiện tại. Màu tím thể hiện mức độ liên quan giữa từ hiện tại với các từ đằng trước nó.
I. Sứ mệnh của Self Attention
Thuở khai sơ, các mô hình xử lý ngôn ngữ dùng mạng recurrent neural networks hay còn gọi là RNN để có thể mô phỏng như cách con người đọc được đề cập tại paper Insensitivity of the Human Sentence-Processing System to Hierarchical Structure đã tạo được những đột phá nhất định. RNN sẽ coi mỗi một câu đầu vào như là một chuỗi của rất nhiều từ. Chúng sẽ mã hóa các đặc trưng của chuỗi đầu vào thành một vector chứa ngữ cảnh rồi sau đó giải mã dự đoán các từ dựa trên những từ trước đó.
Tuy nhiên, có 3 vấn đề lâu lẩu lầu lâu trong các mô hình xử lý ngôn ngữ dùng RNN như sau:
- Vanishing gradient: Nói nôm na là hiện tượng gradient sẽ bị nhỏ lại tới mức gần như biến mất ở những hidden state cuối khi input là một chuỗi dài như đoạn văn....
- Exploding gradient: Cảm ơn anh Học Hiếu đã góp ý phần này. Đây là hiện tượng gradient quá lớn do tích tụ gradient ở những lớp cuối đặc biệt hay xảy rađối với câu dài.
- Nén bộ nhớ (Memory Compression): Do việc nén chuỗi đầu vào thành một vector có kích thước cố định, thực nghiệm đã chứng minh những mô hình này khả năng ghi nhớ đối với câu dài rất kém, trong khi lại lãng phí bộ nhớ đối với những câu ngắn hơn. Nhược điểm này vẫn tồn tại trong LSTM hay GRU.
- Không tương thích với dữ liệu có cấu trúc: Ví dụ ta có câu "She is eating a green apple". Rõ ràng "apple" có quan hệ với "eating" nhiều hơn các từ khác. Tuy nhiên cơ chế của RNN là học tuần tự từ trái sang phải (inductive bias) thiếu đi mất những cơ chế để mô hình học được những thứ thực sự liên quan. (structural bias)
Hiện tại, vấn đề về Vanishing gradient và Memory Compression đã được giải quyết một phần bởi các mô hình như LSTM hay GRU. Trong khi vấn đề Không tương thích với dữ liệu có cấu trúc cũng đã được giải quyết một phần nhờ việc sử dụng một cơ chế attention học mối quan hệ mềm (soft alignment) giữa bộ nhớ phần encoder (memori encoder) và các trạng thái của phần decoder (Bahdanau 2014 hay Luong attention) ở phần decoder trong kiến trúc encoder-decoder. Tuy nhiên inductive bias vẫn còn tồn tại giữa các hidden ở encoder và decoder.
Để giải quyết vấn đề này, Self attention đã ra đời. Vì để tăng cường thông tin giữa chính các hidden state ở encoder hoặc decoder với nhau nên cái tên Self (Chính nó ) đã được gắn vào tên cơ chế này.
II. Hành trình của Self Attention.
Self Attention lần lượt được ứng dụng trong hai kiến trúc Long Short-Term Memory-Network (LSTMN) và Transformer trong nỗ lực khắc phục những nhược điểm của mô hình họ RNN. Chúng ta cùng lần lượt xem Self Attention trong từng kiến trúc được sử dụng như thế nào nhé  ))
))
A. Self-attention trong LSTMN
Ở phần này, chúng ta cùng nhắc lại một số kiến thức về mạng LSTM chuẩn sau đó mới tới ứng dụng của self attention trong mô hình LSTMN mới này.
1. Long Short-Term Memory
 Mô hình LSTM (nguồn https://medium.com/@saurabh.rathor092/simple-rnn-vs-gru-vs-lstm-difference-lies-in-more-flexible-control-5f33e07b1e57)
Mô hình LSTM (nguồn https://medium.com/@saurabh.rathor092/simple-rnn-vs-gru-vs-lstm-difference-lies-in-more-flexible-control-5f33e07b1e57)
Mô hình LSTM nhận vào dữ liệu đầu vào dạng chuỗi x=(x1, x2, ... , xn). LSTM sử dụng một vector bộ nhớ để lưu lại các giá trị đặc trưng khi đi qua mỗi timestep. Các giá trị đặc trưng sẽ lưu lại này sẽ được quyết định bởi ba cổng: forget gate (), output gate () và input gate () theo công thức dưới đây:
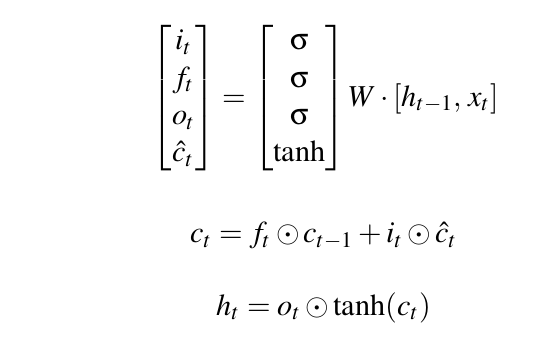
Chú thích:
- : giá trị cell state ở timestep t
- : giá trị hidden state ở timestep t
- : giá trị input của timestep t
Theo công thức trên ta có thể thấy, cell state ở timestep t được tính dựa trên forget gate quyết định lấy bao nhiêu cell state trước và input gate sẽ quyết định lấy bao nhiêu từ input của state và hidden layer của layer trước. Và output gate quyết định xem cần lấy bao nhiêu từ cell state để trở thành output của hidden state. Các bạn có thể tham khảo chi tiết kiến thức mô hình LSTM tại blog của anh Tuấn Nguyễn nhé.
2. Self Attention trong LSTMN
LSTMN là một phiên bản cải tiến của mô hình LSTM truyền thống. LSTMN đã thay thế việc sử dụng một vector bộ nhớ duy nhất (memory cell) trong LSTM bằng một mạng thần kinh bộ nhớ (memory network). LSTMN có hai băng tải chứa tập hợp các vectors là hidden state tape và memory tape.
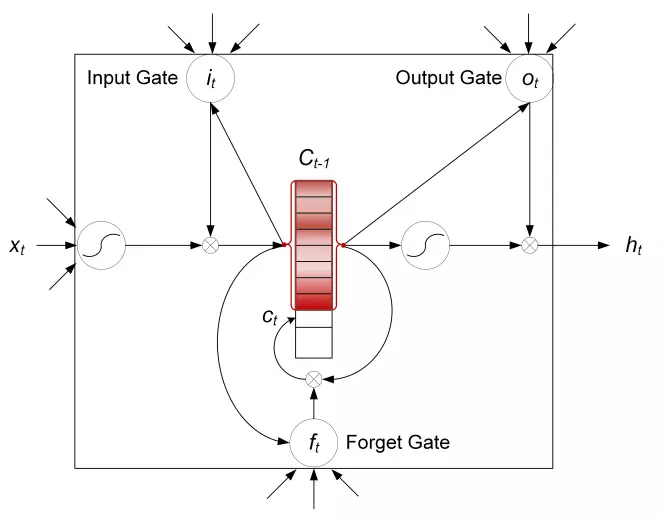 Long Short-Term Memory Network
Long Short-Term Memory Network
Vậy Self Attention ở đâu trong mô hình này ?
LSTMN nhìn tổng thể vẫn giống như mô hình LSTM truyền thống tuy nhiên để tăng cường thông tin giữa các hidden state nhờ việc đánh trọng số dựa trên mối liên quan các hidden state, cell state trước và input timestep hiện tại. Đây chính là self attention. Mỗi một token ở đây sẽ có một vector hidden và một memory hidden tương ứng với các token trước đó.
Chú thích:
- : input ở timestep t
- : hidden ở timestep t
- : cell state ở timestep t
- : giá trị attention tại timestep t
- : giá trị xác suất của từng timestep trước đối với timestep hiện tại (t)
Ví dụ ở time step t, chúng ta tính độ tương quan giữa và thông qua
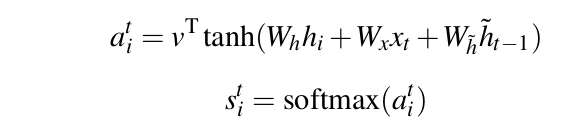
Tiếp theo chúng ta tính các vector hidden và memory tạm thời được đánh trọng số lại bằng độ tương quan ta tính bên trên :
 Sau đó ta tính các giá trị cell state và hidden state ở timestep t tương tự như mô hình LSTM chuẩn. Điều tạo nên sự khác biệt ở đây là thay vì đầu vào nhận cell state và hidden state thông thường trước đó thì bây giờ LSTMN đã nhận đầu vào là các cell state, hidden state "xịn xò" hơn mang nhiều thông tin hơn.
Sau đó ta tính các giá trị cell state và hidden state ở timestep t tương tự như mô hình LSTM chuẩn. Điều tạo nên sự khác biệt ở đây là thay vì đầu vào nhận cell state và hidden state thông thường trước đó thì bây giờ LSTMN đã nhận đầu vào là các cell state, hidden state "xịn xò" hơn mang nhiều thông tin hơn.
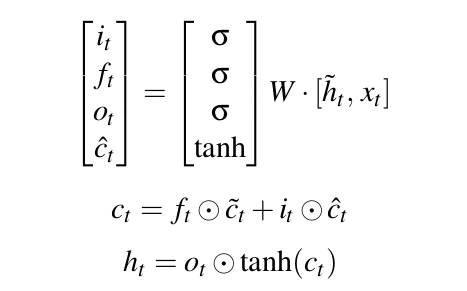
B. Self Attention trong Transformer.
LSTMN đã giải quyết được bài toán inductive bias trong các mô hình tuần tự truyền thống bằng self attention. Tuy nhiên tính tuần tự ở LSTMN cản trở việc song song hóa, tăng tốc tính toán vẫn là một vấn đề nan giải. Do đó Transformer ra đời kế thừa ý tưởng từ self attention từ LSTMN, loại bỏ hoàn toàn tính tuần tự phụ thuộc hoàn toàn vào cơ chế attention để tính toán ra được mối tương quan giữa input và output.
Transformer là một kiến trúc hết sức tuyệt vời tuy nhiên hôm nay mình không đề cập chi tiết quá nhiều mà tập trung vào phần self attention - nội dung bài hôm nay. Các bạn có thể tìm hiểu thêm tại các bài phân tích khác như: Nhận dạng tiếng Việt cùng với Transformer OCR hay Transformers - "Người máy biến hình" biến đổi thế giới NLP
1. Scaled Dot-Product Attention
Trong mô hình Transformer đã loại bỏ đi hoàn toàn khái niệm các vector hidden, memori và thay thế chúng bằng ba vector query, keys, values. Kết quả đầu ra bây giờ được tính bằng tổng các giá trị values đã được đánh trọng số. Trọng số này chính là hàm softmax tính dựa trên query và key tương ứng. Công thức tính attention weight có tên là Scaled Dot-Product Attention.
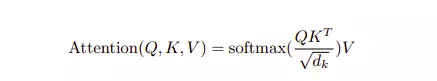 Scaled Dot-Product Attention
Scaled Dot-Product Attention
Có một điều chúng ta cần để ý một chút, chúng ta không dùng trực tiếp key, value hay query để tính trực tiếp trọng số attention. Mà các giá trị key, value, query có kích thước tương ứng sẽ được biến đổi tuyến tính thành có kích thước trước khi được sử dụng. Việc sử dụng phép biến đổi tuyến tính như này sẽ tạo ra đa dạng biểu diễn dữ liệu đầu vào nhờ đó việc tính attention sẽ hiệu quả hơn.
2. Self Attention được sử dụng như thế nào ?
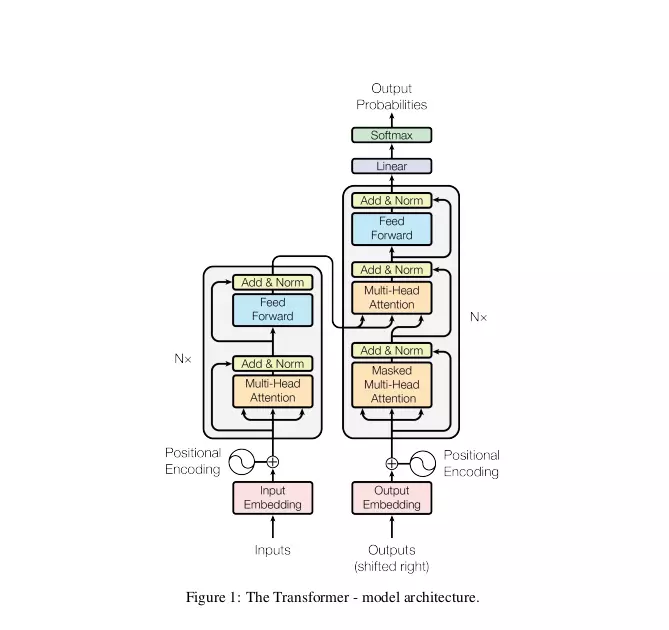 Mô hình Transformer
Mô hình Transformer
Nếu như coi mô hình Transformer như một kiểu mô hình encoder-decoder "biến hình". Ta có thể coi mô hình Transformer có N block. Mỗi block chứa ba phần: Encoder, Decoder, Encoder-Decoder Attention
- Encoder: Mỗi block chứa Multihead-attention, Add & Norm, Feed Forward, Add & Norm. Ở trong encoder chứa lớp self-attention. Self attention ở đây có trọng số được tính theo công thức Scaled Dot-Product Attention trong đó key, queries, value đều từ đầu ra của lớp phía trước ở decoder ==> do cả key, queries, value đều thể hiện giá trị biểu diễn khác nhau của lớp phía trước encoder nên có thể gọi là self-attention.
- Decoder: Mỗi block chứa Masked Multi-Head Attention, Add & Norm. Ở trong decoder cũng có self attention giống như encoder tuy nhiên có chút thay đổi trong việc tính weight attention để che đi một phần các vị trí của output không cho encoder nhìn thấy.
- Encoder-decoder attention: Mỗi block chứa Multihead-attention, Add & Norm, Feed Forward, Add & Norm. Attention được sử dụng ở đây không phải dạng self attention do queries nhận output của lớp decoder phía trước trong khi đó keys và values nhận cùng giá trị từ output của phần decoder.Attention ở đây tương tự như việc sử dụng attention trong mô hình encoder-decoder truyền thống vậy.
3. Tại sao phải là Self Attention ?
Trong bài báo Attention is all you need, tác giả đã đề cập tới ba lý do sử dụng self attention bằng cách so sánh việc sử dụng các lớp self attention, mạng tuần tự hay mạng tích chập - những phương pháp phổ biến để ánh xạ một chuỗi () thành một chuỗi () như trong các bài toán về OCR, Machine Translation, .... 3 tiêu chuẩn được đem ra đánh giá bao gồm :
- Độ phức tạp tính toán mỗi lớp
- Khối lượng tính toán được song song hóa hay số lượng tính toán tuần tự tối thiểu
- Khả năng học phụ thuộc xa: Một trong những yếu tố ảnh hưởng quyết định tới điều này là độ dài đường kết nối của các vị trí bất kì từ input sang output càng ngắn thì khả năng học phụ thuộc xa càng cao.
 Bảng so sánh
Bảng so sánh
Theo như bảng trên đây, ta có thể nhận xét:
-
Xét về số tính toán tuần tự (sequential operation) trong mô hình thì chắc chắc các mô hình tuần tự cao nhất so với các mô hình còn lại.
-
Xét về độ phức tạp mỗi lớp, với n nhỏ hơn d (n là chiều dài của chuỗi đầu vào ) thì self-attention nhanh hơn mạng tuần tự. Vì như đã nói bên trên thì self attention có khả năng tính toán song song hóa cao so mạng tuần tự đồng thời có độ phức tạp tính toán nhỏ hơn nên chắc chắn nhanh hơn. Tuy nhiên khi n lớn hơn d, thì điều này chưa chắc đã đúng. Tuy nhiên trong bài báo tác giả đã gợi ý về việc self attention chỉ quan tâm tới các hàng xóm của nó thôi, việc xác định hàng xóm được xác định bởi một kích thước r cố định. Nhờ đó độ phức tạp giảm còn O(r * n * d).
Còn khi sử dụng mạng tích chập có hạt nhân có kích thước k < n thì cần O(n / k) lần nhân mạng tích chập bình thường. Mỗi lần nhân tốn O() vậy sẽ cần O(n * k * ). Chắc chắn sẽ lớn hơn self attention trong khi đều có khả năng tính toán song song bằng nhau nên self attention sẽ nhanh hơn
-
Xét về khả năng phụ thuộc xa thì self attention cũng có đường kết nối từ input sang output ngắn nhắn (O(1)) do đó khả năng học phụ thuộc xa lớn nhất.
III. Lời kết
Self attention cùng với mô hình Transformer đã được ứng dụng trong nhiều bài toán ở nhiễu lĩnh vực và cũng đã chứng tỏ được sự hiệu quả của mình. Trên đây là một số kiến thức mình có tìm hiểu được tích lũy trong thời gian vừa qua, hy vọng có thể giúp ích nhiều cho mọi người. Cảm ơn các bạn đã đọc bài viết của mình 
Một số tài liệu tham khảo
All rights reserved
