[Word embedding] Giới thiệu ý tưởng mô hình nhúng từ mới - một mô hình mới hỗ trợ xử lý các bài toán NLP với NodeJS
Bài đăng này đã không được cập nhật trong 3 năm
Giới thiệu ý tưởng mô hình nhúng từ mới
Máy tính không hiểu những mặt chữ tự nhiên thông thường như cách con người hiểu, nó chỉ hiểu những dãy số và các từ dù ở trong bất cứ ngôn ngữ giao tiếp nào trên thế giới đều tồn tại một dãy số đặc trưng riêng. Dãy số ấy là vector đặc trưng của từ, việc tạo ra vector cho từ gọi là word to vec (chuyển đổi từ ngữ sang vector).
Hiện tại có các mô hình nhúng từ như Skip-gram; CBOW; Glove;...Nhưng chúng tồn tại một vấn đề là sử dụng các phép toán khá phức tạp, khiến một học sinh THPT có trình độ về toán hạn chế như mình khó có thể hiểu được tường tận khi tự học về NLU, NLP, Machine Learning tại gia và đặc biệt hơn khi mình muốn triển khai thuật toán word to vec trên Javascript để phục vụ dự án đi thi khoa học kỹ thuật cấp quốc gia (Visef 2020) (Đa số các mô hình word to vec trên npm đều trục trặc khi cài đặt trên máy mình, còn việc dùng python để triển khai là điều khó nhọc khi dự án được triển khai trên server miễn phí với cấu hình yếu). Vậy nên mô hình NK-VEC được ra đời nhằm đáp ứng một mục tiêu là sử dụng các phép toán đơn giản để xây dựng mô hình chuyển đổi từ ngữ sang vector, viết được trên javasript, server yếu vẫn chạy được.
Lưu ý nho nhỏ: Chúng ta thống nhất với nhau về cụm từ "ngữ nghĩa" là sự tương đồng hoặc có liên quan với nhau giữa từ với từ nhé
Update
Hiện đã có thư viện tích hợp sẵn NK-VEC model và hàng loạt tính năng hỗ trợ giải quyết các bài toán NLP với Javascript đã được publish trên npm tại đây
Tổng quát mô hình
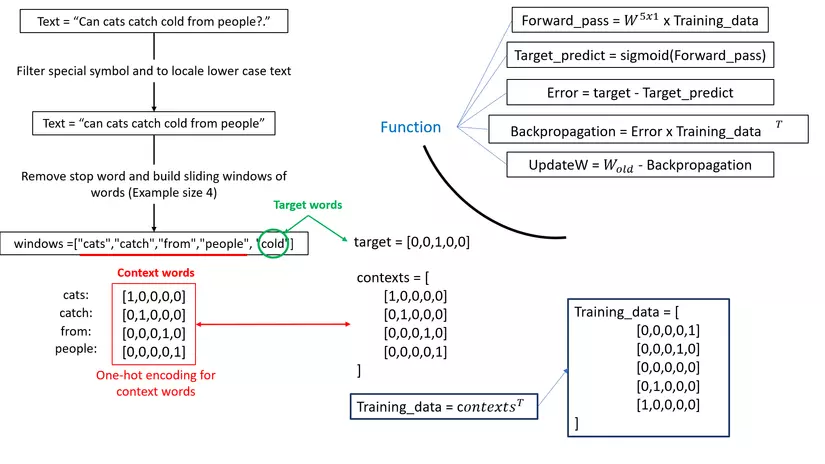
Các bước tiến hành
Tạo one-hot vector cho các từ:
Đây là bước khởi đầu cơ bản và nhẹ nhàng
- Số chiều one-hot của một từ được quyết định bởi số lượng từ (kể cả lặp lại) có trong văn bản (Gọi là D)
- Khởi tạo zero vector có D chiều
- Tại các vị trí từ xuất hiện trong văn bản sẽ được thay đổi thành 1 tại vị trí tương ứng trong zero vector (VD: Theo mô tả trong hình)
Giảm chiều vector:
Sau một thời gian nghiên cứu các thuật toán giảm chiều tiêu biểu như SVD hoặc PCA thì mình nhận ra 3 điều sau:
-
- Chúng phức tạp về toán học nên dẫn đến điều thứ 2.
- Chúng phức tạp về toán học nên dẫn đến điều thứ 2.
-
- Chúng khó triển khai lên Javascript.
- Chúng khó triển khai lên Javascript.
-
- Đòi hỏi tính toán lớn nên không thể áp dụng lên một server miễn phí mà Heroku cung cấp (cốt lõi của NK-VEC là phục vụ cho mình xây dựng sản phẩm và triển khai trên các server yếu như server miễn phí mà Heroku cung cấp).
Nên mình nghĩ ra một cách thay thế SVD, PCA hoặc các thuật toán tương tự, mình đặt tên phương pháp này là Auto Focus.
Ý tưởng như sau:
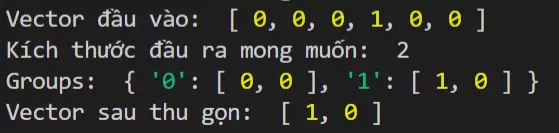
Bạn đưa đầu vào là một vector có D chiều (giả sử D rất lớn - như trong bài này thì con số này gần 9 nghìn, lớn hơn số chiều mà bạn muốn thu gọn xuống) và bạn mong muốn đầu ra là vector có D' chiều (D' là số chiều mong muốn rút gọn xuống) thì Auto Focus sẽ tạo ra một bộ trượt tương tự với words windows có step là 1, sẽ trượt trên toàn bộ vector đầu vào D chiều ban đầu đồng thời trong lúc này nó sẽ gom nhóm D' phần tử - ứng với D' chiều mong muốn đầu ra và tính tổng của các phần tử vừa gom được (điều này sẽ giúp định xem nhóm vừa gom có thưa không - vì đầu vào là một onehot) sau đó lưu vào một list theo định dạng Json như sau (Lưu ý: cách này có thể sẽ tạo ra việc trùng key - tức cùng tổng nhưng vẫn không ảnh hưởng vì cả tập dữ liệu đều chịu ảnh hưởng chung):
{"<tổng của các phần tử trong nhóm gom được>":[<nhóm được gom>]}
Cuối cùng chỉ cần sort key tổng lớn nhất (lưu ý chuyển về kiểu int) và truy vấn lấy nhóm tương ứng => nhóm tương ứng này sẽ là vector đầu ra của Auto Focus. Hãy xem ví dụ sau:
- Đòi hỏi tính toán lớn nên không thể áp dụng lên một server miễn phí mà Heroku cung cấp (cốt lõi của NK-VEC là phục vụ cho mình xây dựng sản phẩm và triển khai trên các server yếu như server miễn phí mà Heroku cung cấp).
Cách làm thế này sẽ đảm bảo vector đầu vào không bị thưa và vẫn giữ được một số đặc trưng cơ bản vậy nên chất lượng không bị thay đổi mà còn tiết kiếm thời gian training, thời gian search word similarity.
Tạo dữ liệu đào tạo:
Nhìn chung mô hình NK-VEC giống với CBOW ở ý tưởng đó là sử dụng các từ ngữ cảnh xung quanh (context words) để tạo ra vector cho từ mục tiêu (target word), thế nên NK-VEC cũng sử dụng cửa sổ trượt (sliding windows) giống với CBOW để tạo dữ liệu đào tạo.
- Đầu vào có các vector của x (context words) và y (target word)
- Lấy các vector của x làm dữ liệu đào tạo (Training data = ) còn vector y là mục tiêu của mô hình
Tiến hành đào tạo:
Chúng ta sẽ thực hiện theo thứ tự sau:
- Khởi tạo ma trận W có chiều ứng với số cột của x (VD: Theo mô tả trong hình)
- Lan truyền tới sẽ dùng và tạo ra một y_pred (đầu ra dự đoán) thông qua sigmoid
- Lỗi là một vector (Error) được tính bằng cách y - y_pred
- Lan truyền ngược (Backpropagation) bằng cách lấy
- Cập nhật W bằng
Kết quả
-
- Với cấu hình máy của mình là CPU i7-4610m @3.00GHz, Ram 8Gb, win 10 64-bit lúc chạy mô hình đào tạo 3K từ thì CPU đạt 40 - 50%, Ram 4-5Gb. Vẫn dư dả để chơi game lúc chờ đợi mô hình chạy
Ưu điểm của mô hình:
- Với cấu hình máy của mình là CPU i7-4610m @3.00GHz, Ram 8Gb, win 10 64-bit lúc chạy mô hình đào tạo 3K từ thì CPU đạt 40 - 50%, Ram 4-5Gb. Vẫn dư dả để chơi game lúc chờ đợi mô hình chạy
-
- Đơn giản đến mức học sinh cấp 3 yếu toán như mình vẫn làm được và triển khai được trên Javascript
- Đơn giản đến mức học sinh cấp 3 yếu toán như mình vẫn làm được và triển khai được trên Javascript
-
- Thời gian đạo tạo cho 3K từ rời vào khoảng 5h trên máy mình [Sau khi áp dụng Auto Focus thì thời gian training giảm xuống còn 50 phút]
Nhược điểm của mô hình:
- Thời gian đạo tạo cho 3K từ rời vào khoảng 5h trên máy mình [Sau khi áp dụng Auto Focus thì thời gian training giảm xuống còn 50 phút]
-
- Chiều vector lớn theo lượng từ vựng trong văn bản đưa vào (Nhưng mình nghĩ với các thuật toán giảm chiều vector như SVD, TSNE, PCA, product quantization...sẽ giải quyết được điều này, chỉ có khó ở chỗ khó sử dụng các thuật toán giảm chiều vector này trên Javascript) - Đã được fix với Auto Focus
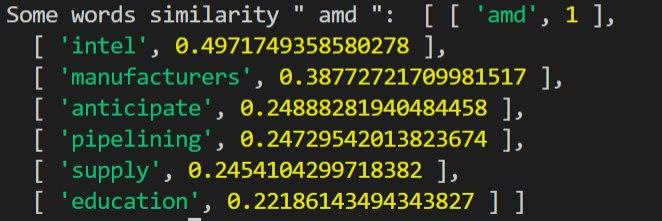
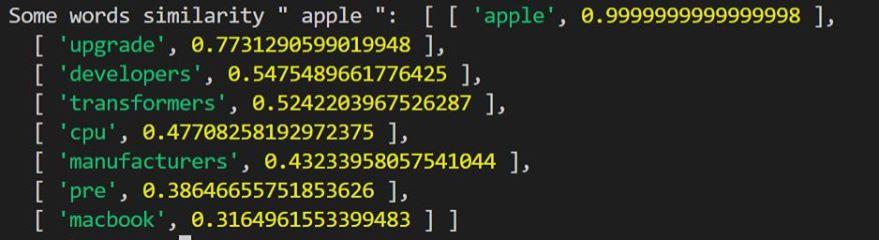
Một số hình ảnh truy vấn từ tương tự sau khi đào tạo:
- Chiều vector lớn theo lượng từ vựng trong văn bản đưa vào (Nhưng mình nghĩ với các thuật toán giảm chiều vector như SVD, TSNE, PCA, product quantization...sẽ giải quyết được điều này, chỉ có khó ở chỗ khó sử dụng các thuật toán giảm chiều vector này trên Javascript) - Đã được fix với Auto Focus
- Trước khi dùng Auto Focus:
![]()
![]()
- Sau khi dùng Auto Focus:
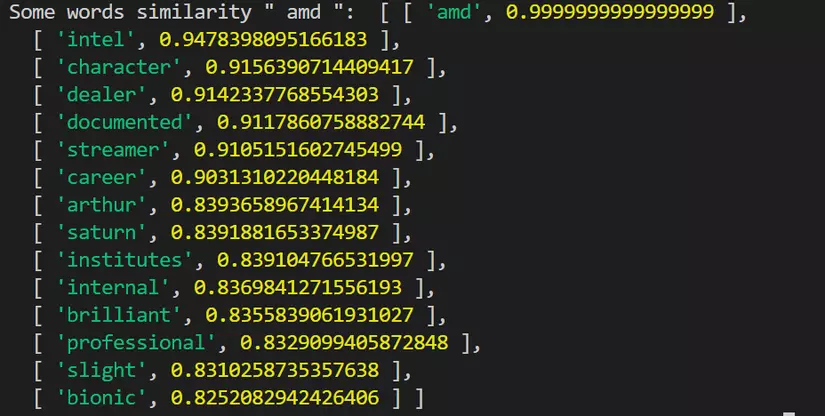
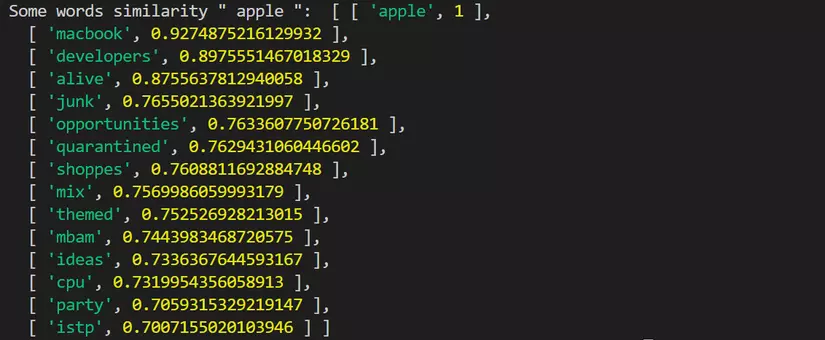
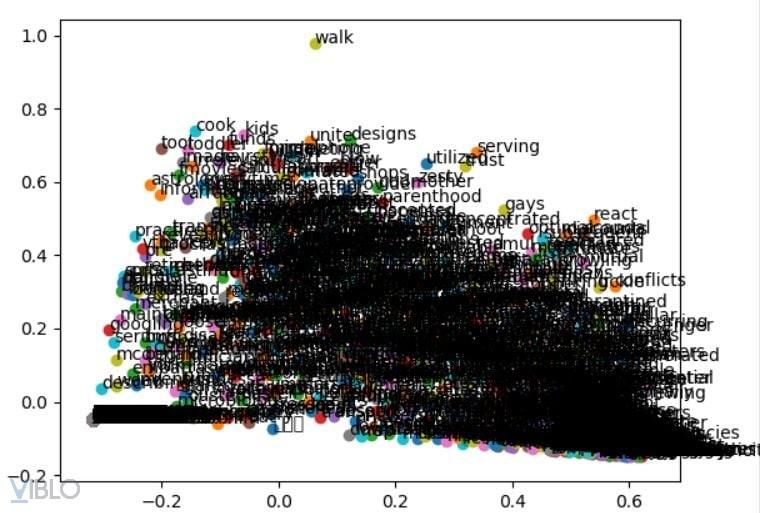
- Visual
![]()
![]()
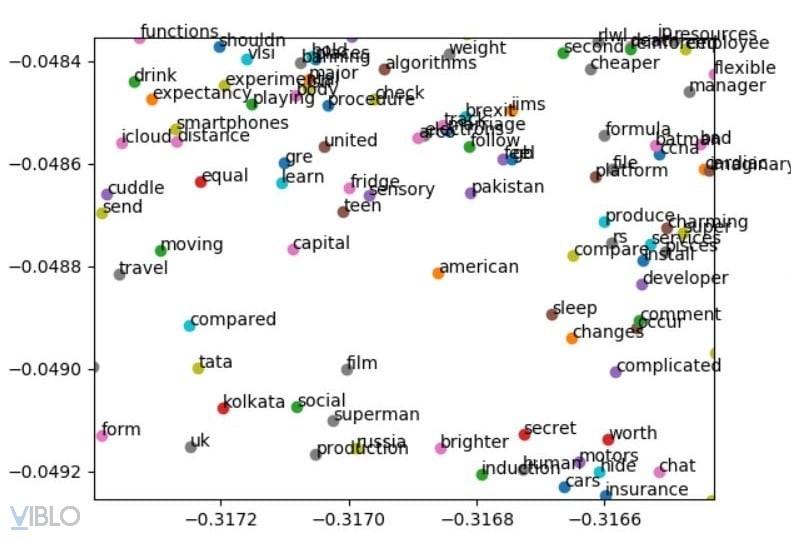
- Evaluation
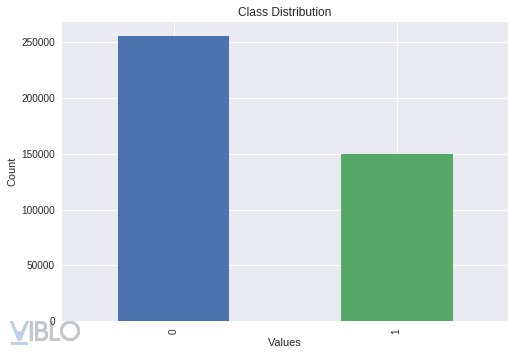
- Dữ liệu đánh giá là bộ Quora Question Pairs
- Tình trạng mẫu:
![]()
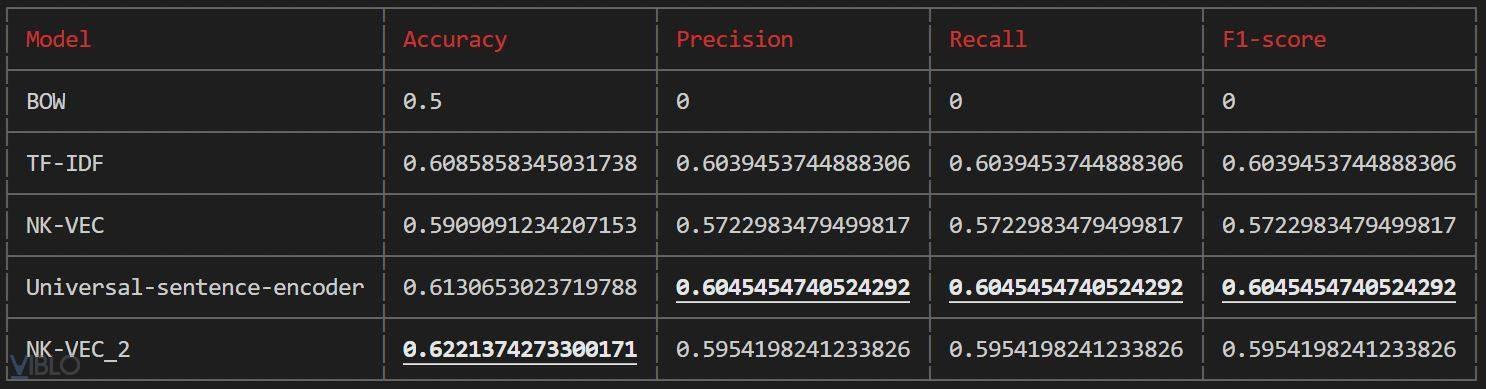
- Kết quả:
![]()
Note
Bài viết này nhằm giới thiệu ý tưởng và là bài viết đầu tiên của mình về mô hình mạng nên khó tránh sai sót hay nhầm tưởng thế nên mong mọi người góp ý chỉnh sửa. Mình xin cảm ơn mọi người rất nhiều 
Truy cập thư viện tích hợp NK-VEC model tại đây
Truy cập demo sản phảm mình đi thi tại đây. Mong mọi người test nhẹ thui  !
!
Link Facebook liên hệ mình tại đây
All rights reserved
