Thuật toán xếp hạng bài viết đang hot, thịnh hành như Reddit và Hacker News hoạt động thế nào?
This post hasn't been updated for 6 years
Có bao giờ bạn tự hỏi, người ta làm thế nào để sắp xếp các bài viết tại trang chủ, mục "hot" của các trang tin như Reddit, Hacker News, các trang giải trí như mục thịnh hành của Youtube, 9GaG, Hài Vờ Lờ, Có Ai Biết,... Hay gần gũi nhất đối với chúng ta là như mục Trending của Viblo?
Khoan hãy nghĩ đến việc cá nhân hóa nội dung cho từng người dùng hay áp dụng machine learning vào việc xếp hạng. Trong bài viết lần này, mình xin được cùng các bạn tìm hiểu, phân tích về việc tính điểm, xếp hạng bài viết đang "hot" qua sử dụng thuật toán tính điểm một cách đơn giản, thuần túy nhất.
Tổng quan
Trước hết, bạn cần xác định xem đặc thù của hệ thống/trang web của bạn là gì, cần việc xếp hạng các bài viết tại trang chủ như thế nào:
- Nếu hệ thống của bạn cung cấp kiến thức, giải đáp như Quora, StackOverFlow: bạn cần ưu tiên việc cung cấp thông tin hữu ích nhất cho người dùng trước tiên, nội dung cũ hay mới ít quan trọng hơn. Quora và StackOverFlow đều xếp hạng những câu trả lời có lượt upvote - downvote cao nhất lên trên đầu. Xếp hạng theo độ "hot" sẽ không hữu dụng lắm trong trường hợp này.
- Nếu hệ thống của bạn là một dạng mạng xã hội tin tức, giải trí: ở trên trang chủ, bạn sẽ cần cung cấp những thông tin mới mẻ, hấp dẫn với số đông, hạn chế các thông tin cũ, nhàm chán. Như vậy bạn cần một dạng thuật toán ranking tính điểm để sắp xếp bài viết cho hợp lý. Đây là phần mình sẽ nhắm đến chủ yếu trong bài viết này.
Còn dưới đây là một số yếu tố mà bạn có thể dùng để tính điểm cho bài viết:
- Lượt thích/vote: Đây là yếu tố đáng tin cậy nhất, do thường chỉ dành cho người dùng đã đăng ký tài khoản, cần người dùng thực hiện hành động cụ thể là bấm vào nút Like/(+) và mỗi người thường chỉ vote/like được một lần. Tùy nơi mà bạn chỉ có thể được thả tim/like, hay còn có thể dislike, hay downvote các bài viết. Lượt thích/vote càng cao, đương nhiên điểm phải càng cao.
- Thời gian bài viết được đăng: Đây là nhân tố rất quan trọng, thứ giúp bạn xác định những bài viết mới mẻ, hợp "trend" để đưa cho người dùng. Như vậy, các bài viết cũ, lỗi thời cần phải bị trừ nhiều điểm hơn, và các bài viết mới, gần đây cần phải bị trừ ít điểm hơn. Đôi khi có hệ thống cũng tính điểm theo kiểu: "bài viết càng viết gần đây thì càng được cộng nhiều điểm", ví dụ như Reddit, cũng tương tự nhau cả thôi.
- Số lượng bình luận/lượng người bình luận: Cái này không quan trọng bằng 2 cái ở trên, vì ta chẳng biết người ta bình luận để khen hay chửi, nhưng cũng có ích. Nhận được nhiều bình luận chứng tỏ chủ đề này đang sôi nổi và được quan tâm.
- Lượt xem/thời gian xem: Cái này là yếu tố thiếu chắc chắn nhất, bạn nên hạn chế dùng nó để xếp hạng. Tuy nhiên vẫn có trường hợp, như Google rõ ràng là có theo dõi lượng click/bounce rate để xác định xếp hạng của trang Web trên kết quả tìm kiếm.
Công thức tổng quan
Mình xin tạm đưa ra công thức tính điểm cho bài viết đơn giản nhất như sau:
Với là điểm bị trừ theo thời gian trôi qua. Bạn có thể tự định nghĩa điểm sẽ bị trừ như thế nào. Ví dụ, mình có thể đặt rằng cứ 4 giờ trôi qua, bài viết sẽ bị trừ 1 điểm.
Ví dụ một vài trường hợp:
- Bài viết đăng cách đây 6 giờ trước, có 5 upvote, 1 downvote, sẽ có số điểm là điểm.
- Bài viết đăng cách đây 12 giờ trước, có 25 upvote, 4 downvote, sẽ có số điểm là điểm.
- Bài viết đăng cách đây 30 ngày trước, có 32 upvote, 2 downvote, sẽ có số điểm là điểm.
Nhìn qua ví dụ, ta có thể thấy công thức trên trông có vẻ "tạm" đúng, vì bài có lượng upvote càng cao sẽ càng ở trên đầu, nhưng vẫn lại có số điểm càng ngày càng giảm theo thời gian.
Tuy nhiên vẫn có trường hợp, một bài viết lên được vị trí đầu, rồi cứ mỗi ngày nó lại nhận được 6, 7 số lượt upvote hay nhiều hơn. Vì bài viết đang đứng đầu nên việc nó bị snowball (hiệu ứng lăn cầu tuyết, ae nào có chơi LOL chắc rõ nhất 😏), tức càng ngày lại càng nhiều upvote hơn cho nó là rất hay xảy ra nhé. Vậy hậu quả là sau... 2 năm sau bài viết này vẫn loanh quanh đâu đó top 10 trending của bạn(?)
Giờ chúng ta sẽ xem một vài các trang nổi tiếng áp dụng việc xếp hạng bài viết hot của họ, và phân tích xem họ khắc phục trường hợp bị "snowball" như trên như thế nào.
Thuật toán của Reddit (cũ)
Sở dĩ nói cũ vì Reddit từng mở mã nguồn hệ thống của họ, nhưng đã chuyển sang đóng mã nguồn của họ được một thời gian. Tuy nhiên mã nguồn của họ lúc còn mở mã nguồn vẫn được chia sẻ và đáng để ta học hỏi.
Mã nguồn
Phần tính điểm để xếp hạng bài viết đang hot của họ như thế này (GitHub):
cpdef long score(long ups, long downs):
return ups - downs
cpdef double hot(long ups, long downs, date):
return _hot(ups, downs, epoch_seconds(date))
cpdef double _hot(long ups, long downs, double date):
"""The hot formula. Should match the equivalent function in postgres."""
s = score(ups, downs)
order = log10(max(abs(s), 1))
if s > 0:
sign = 1
elif s < 0:
sign = -1
else:
sign = 0
seconds = date - 1134028003
return round(order + sign * seconds / 45000, 7)
Giải thích
Giải thích sơ qua về thuật toán trên như sau: Gọi:
- là thời gian bài viết được đăng theo dạng Unix Timestamp,
- là là một thời gian cố định (12/08/2005 @ 7:46am (UTC), có thể tạm hiểu là thời gian Reddit bắt đầu hoạt động), chính là thời gian dạng Unix Timestamp.
Ta được là khoảng thời gian giữa chúng (theo số giây):
Gọi là số chênh lệch upvote - downvote của bài viết:
Từ đó ta có chính là dấu của vừa rồi. Nói cách khác, biểu thị cho dấu của kết quả vote là âm hay dương:
- nếu
- nếu
- nếu .
Để đưa được vào hàm logarit, người ta phải đổi về dạng giá trị tuyệt đối, tức không thể âm; và bắt nó luôn lớn hơn 1. Mình tạm đặt số đấy là :
- nếu
- nếu
Cuối cùng, ta có thể tính ra điểm độ "hot" của bài viết:
Phân tích
Nhìn công thức của Reddit, ta cũng thấy ngay sự tương đồng với "công thức tổng quan" ở đầu bài của mình:
- Số hạng đầu tiên () để tính ra điểm từ lượng vote của bài
- Số hạng thứ hai () để tính ra điểm từ thời gian đăng bài
Tính tổng của hai số hạng này, ta sẽ ra điểm cuối cùng của bài viết. Nhưng có nhiều thứ khá "thú vị" ở đây: tại sao lại cần hàm logarit? tại sao lại chia cho số 45000? Giờ chúng ta sẽ đi tìm hiểu từ từ từng chút một.
Số hạng 2 (phần tính điểm từ thời gian đăng bài)
Phần này cũng chung mục đích là giúp cho bài viết đăng gần đây có điểm cao hơn bài viết đăng trước đó. Nhưng thay vì trừ điểm dựa theo thời gian trôi qua, Reddit lại chọn cách cộng thêm điểm cho bài viết viết gần đây.
Cụ thể hơn, họ đã làm thế bằng cách: trước tiên họ chọn một mốc thời gian cố định trong quá khứ, và tính hiệu giữa mốc thời gian đó với thời gian viết bài. Ví dụ (giả sử chưa tính đến lượng vote):
- Trang Web của mình được ra mắt vào đúng đêm Giáng Sinh, tức ngày 0:00 ngày 25/12/2019 theo giờ Việt Nam, và mình muốn chọn thời điểm này mốc thời gian này làm "mốc thời gian cố định". Nó có giá trị theo kiểu Unix Timestamp bằng 1577206800.
- Bài viết đầu tiên được đăng vào 6h sáng (6h sau đó), Unix Timestamp là 1577228400, hiệu thời gian là , vậy nó sẽ được cộng: điểm.
- Bài viết thứ 2 được đăng vào 12h30, hiệu thời gian là , vậy nó được cộng: điểm.
- Bài viết thứ 3 được đăng vào 1h sáng ngày tiếp theo (ngày 26), hiệu thời gian là , vậy nó được cộng: điểm.
Từ ví dụ trên, ta thấy rằng, cứ với mỗi 12,5h sau mốc thời gian là đêm Giáng Sinh, bài viết mới đăng sẽ được cộng thêm 1 điểm. 45000 chính là số giây tương ứng với 12,5h. Người ta chọn cách này có thể là vì nếu đưa thời điểm hiện tại vào công thức sẽ khiến điểm bị thay đổi liên tục và hạn chế khả năng sử dụng cache hay thực thi tính điểm dưới nền.
Số hạng 1 (phần tính điểm từ số vote)
Trước hết, chắc hẳn nhiều bạn đọc bài cũng đã lâu không tiếp xúc với Toán cấp 3, nên mình xin mạn phép nhắc lại chút về hình thù của một hàm logarit cơ số 10:
 Để dễ hình dung hơn, mình xin đưa ra một vài trường hợp:
Để dễ hình dung hơn, mình xin đưa ra một vài trường hợp:
- Với bài viết có 10 vote (tức số upvote - downvote), bài đó sẽ được cộng hẳn điểm.
- Với bài viết có gấp đôi số vote trên, tức 20 vote, bài đó lại chỉ nhận được điểm.
- Một bài viết khác có số vote gấp 10 bài viết đầu, tức tận 100 vote, bài đó lại chỉ nhận được điểm.
Cũng một ví dụ khác, để bài viết đăng cách đây 3 ngày trước có hạng cao hơn một bài vừa mới đăng, nó cần phải có đến hơn điểm từ số vote, tức nó cần phải có đến gần 600000 lượt vote!
Như vậy, nhờ vào hàm logarit mà:
- Các lượt vote đầu có giá trị cao nhất
- Các lượt vote về sau càng ngày càng có ít giá trị hơn
- Để bài viết càng cũ giữ được trên trending thì càng phải nhận được lượng vote cực lớn
Tóm lại, đây chính là cách Reddit dùng để chống lại trường hợp "snowball" như mình đã đề cập ở phần Tổng quan, đồng thời giúp nội dung ở trên frontpage của Reddit luôn luôn tươi mới.
Thuật toán của HackerNews thì sao?
Khác với Reddit, HackerNews vẫn đang là open source đến thời điểm hiện tại. Hệ thống của HackerNews được viết bằng Arc, và mã nguồn của phần chức năng tính ranking các bài viết trên trang chủ như sau:
; Votes divided by the age in hours to the gravityth power.
; Would be interesting to scale gravity in a slider.
(= gravity* 1.8 timebase* 120 front-threshold* 1
nourl-factor* .4 lightweight-factor* .3 )
(def frontpage-rank (s (o scorefn realscore) (o gravity gravity*))
(* (/ (let base (- (scorefn s) 1)
(if (> base 0) (expt base .8) base))
(expt (/ (+ (item-age s) timebase*) 60) gravity))
(if (no (in s!type 'story 'poll)) 1
(blank s!url) nourl-factor*
(lightweight s) (min lightweight-factor*
(contro-factor s))
(contro-factor s))))
Với mình thì code dạng như Lisp hay Arc như trên trông khá đáng sợ. Đoạn code trên nếu viết lại bằng Python thì trông như sau:
def calculate_score(votes, item_hour_age, gravity=1.8):
return (votes - 1) / pow((item_hour_age+2), gravity)
Tóm gọn lại đoạn code trên là công thức khá đơn giản như dưới đây.
Công thức
Công thức của HackerNews có phần dễ hiểu và đơn giản hơn công thức của Reddit, cụ thể như sau:
Với:
- : Lượt upvote của bài viết (upvote-downvote). Lượt vote này cần trừ đi 1 để không tính upvote của người viết bài.
- : Thời gian giữa thời gian đăng bài và thời điểm hiện tại (theo giờ). Ví dụ như bài đăng 2 giờ trước sẽ có .
- Hằng số "trọng lực", mặc định là .
Giải thích
Thay vì dùng tính điểm theo lượt vote và tính điếm theo thời gian và tính tổng, HackerNews sử dụng phép chia giữa số vote và thời gian đăng (theo giờ) để tính ra điểm rank của bài viết.
Có thể đưa ra một vài nhận xét như sau:
- Thời gian viết bài càng lâu, số điểm sẽ càng giảm, vì số được đặt ở phần mẫu số.
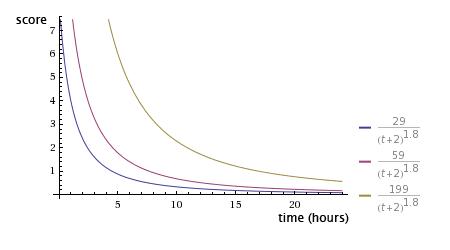
- Để điều khiển việc số điểm bị giảm nhanh hay giảm chậm theo thời gian, người ta sử dụng hằng số là số gravity. Nếu số gravity càng cao, điểm số sẽ càng giảm nhanh hơn theo thời gian.
Với thì sau 24h, điểm số của bài viết sẽ giảm rất nặng và càng về sau điểm số sẽ ngày càng gần với 0:
Tham khảo
This work
by
Trần Xuân Thắng
is licensed under
CC BY-NC-ND 4.0 ![]()
![]()
![]()
