Thuật toán đánh giá _score trong Elasticsearch
Bài đăng này đã không được cập nhật trong 4 năm
Elasticsearch là một search engine đã quá nổi tiếng rồi!

Trên Viblo cũng đã có rất nhiều bài viết về ES, các bạn có thể tham khảo thêm bài viết này của bạn @dinhhoanglong91 về kiến trúc cũng như series này về cách hoạt động của anh @nguyen.van.ngoc
Mục đích chính để dùng Elasicsearch là gì ? - Tìm kiếm, dĩ nhiên là ES có thể làm được nhiều điều hơn thế, nhưng cái quan trọng nhất vẫn là tìm kiếm. Và theo mình thì khi dùng bất cứ công cụ gì, ngoài việc biết cách sử dụng nó, thì việc tìm hiểu xem nó hoạt động ra sao cũng quan trọng và thú vị không hề kém.
Khi tìm kiếm, Elascticsearch (ES) trả về cho mình ngoài các kết quả tìm được, còn có đánh giá relevance (độ liên quan) của kết quả dựa trên giá trị thực dương _score. ES sẽ sắp xếp các kết quả trả về của các query theo thứ tự _score giảm dần. Đây là điểm mà mình thấy rất thú vị trong ES, và mình sẽ dành bài viết này để nói về cách làm thế nào người ta tính toán và đưa ra được giá trị _score đó.
Note:
- Elasticsearch là tên của search engine, không phải là tên thuật toán!
- Một số thuật ngữ rất hay được sử dụng trong Elasticsearch, mình sẽ giữ nguyên để giữ gìn sự trong sáng của thuật ngữ, đồng thời cũng tiện cho việc tra cứu. Các thuật ngữ mình nhắc tới ở đây là: relevance (độ liên quan), index (tương đương với database trong mysql), type (tương đương với table trong mysql), document (tương ứng với record trong mysql), term (từ, từ khóa), field (có thể gọi là trường - nhưng mình không thích lắm vì nó có cấu trúc, nên quyết định giữ nguyên)
TF/IDF
Thuật toán đánh giá được sử dụng rất phổ biến trong Elasticsearch có tên gọi là term frequency/inverse document frequency, gọi tắt là TF/IDF, bao gồm các yếu tố đánh giá: Term frequency, Inverse document frequency, Field-length norm.
Term frequency
Yếu tố này đánh giá tần suất xuất hiện của term trong field. Càng xuất hiện nhiều, relevance càng cao. Dĩ nhiên rồi, một field mà từ khoá xuất hiện 5 lần sẽ cho relevance cao hơn là field mà từ khoá chỉ xuất hiện 1 lần.
Ví dụ: nếu bạn search với từ khoá "quick", thì rõ ràng field bên trên sẽ cho TF cao hơn (xuất hiện 2 lần) filed bên dưới (xuất hiện 1 lần):
{ "title": "The quick brown fox jumps over the quick dog" }
{ "title": "The quick brown fox" }
TF được tính theo công thức sau:
tf(t, d) = √frequency
Giải thích: term frequency (tf) của t trong document d được tính bằng căn bậc hai của số lần t xuất hiện trong d.
Inverse document frequency
Yếu tố này đánh giá tần suất xuất hiện của term trên toàn bộ index. Điều đáng chú ý ở đây là càng xuất hiện nhiều, càng ít thích hợp!
 Tại sao lại như vậy ? nghe chừng hơi khó hiểu nhưng thực sự nó rất hợp lý.
Tại sao lại như vậy ? nghe chừng hơi khó hiểu nhưng thực sự nó rất hợp lý.
Ví dụ thế này, bạn muốn tìm kiếm thông tin về Framgia. Khi bạn search google với từ khoá "công ty", thì nhận được khoảng 170,000,000 kết quả, nhưng với 170,000,000 kết quả đó, rất khó để biết được kết quả nào là kết quả chúng ta thực sự muốn tìm, suy ra rằng từ khoá "công ty" sẽ có giá trị rất thấp. Tuy nhiên, nếu bạn search với từ khoá "công ty Framgia", số lượng kết quả thu gọn lại chỉ còn khoảng 3,000,000 kết quả, và bạn thấy rõ ràng rằng các kết quả này rất sát với kết quả bạn mong muốn. Vì thế từ khoá ít xuất hiện hơn ("công ty Framgia") sẽ cho relevance cao hơn là từ khoá xuất hiện nhiều hơn ("công ty") trên toàn bộ index.
Mặc dù vậy, kết quả trên không có nghĩa là từ khoá "công ty Framgia" tốt hơn từ khoá "công ty" gần 60 lần. IDF được đánh giá theo công thức sau:
idf(t) = 1 + log ( numDocs / (docFreq + 1))
Giải thích: inverse document frequency (idf) của t là logarit cơ số e (logarit tự nhiên) của thương giữa tổng số documents trong index và số documents xuất hiện t (giá trị công thêm 1 ở đây để tránh xảy ra lỗi Division by zero).
Theo đó thì kết quả đã được lấy logarit đi nên con số 60 bên trên đã giảm kha khá rồi.
Field-length norm
Yếu tố này đánh giá độ dài của field. Field càng ngắn, thì term sẽ có giá trị càng cao; và ngược lại. Điều này hoàn toàn dễ hiểu, bạn có thể thấy một từ xuất hiện trong title sẽ có giá trị hơn rất nhiều cũng từ đó nhưng xuất hiện trong content.
Công thức:
norm(d) = 1 / √numTerms
Giải thích: field-length norm (norm) là nghịch đảo của căn bậc hai số lượng term trong field. (có thể hiểu là số lượng chữ của field đó)
Putting it together
_score cuối cùng sẽ là tích của 3 giá trị trên:
IDF score * TF score * fieldNorms
hay
log(numDocs / (docFreq + 1)) * √frequency * (1 / √numTerms)
Note:
numDocschính làmaxDocs, đôi khi bao gồm cả những document đã bị delete- fieldNorm được tính toán và lưu trữ dưới dạng 8 bit floating point number. Nên khi tính toán, hệ thống sẽ encode và decode giá trị của fieldNorm về 8 bit, và theo đó, bạn sẽ thấy giá trị filedNorm đôi khi hơi khác so với tính toán một chút xíu xíu thôi. Nếu muốn hiểu thêm bạn có thể tham khảo tại đây
Expert: Default scoring implementation which encodes norm values as a single byte before being stored. At search time, the norm byte value is read from the index directory and decoded back to a float norm value. This encoding/decoding, while reducing index size, comes with the price of precision loss - it is not guaranteed that decode(encode(x)) = x. For instance, decode(encode(0.89)) = 0.875.
Time for action
Ta tạo và test thử với dữ liệu như sau:
PUT /my_index/doc/1
{ "text" : "quick brown fox" }
GET /my_index/doc/_search?explain
{
"query": {
"term": {
"text": "fox"
}
}
}
Expected kết quả:
tf: có 1 kết quả/1 doc, vậytf = 1.0idf: tính toán theo công thức1 + log((numDocs)/(docFreqs+1)) = 1 + log(1/2.) = 0.306852fieldNorm: field "quick brown fox" có độ dài 3, vậyfiledNorm = 1/sqrt(3) =0.577350
Actual:
weight(text:fox in 0) [PerFieldSimilarity]: 0.15342641
result of:
fieldWeight in 0 0.15342641
product of:
tf(freq=1.0), with freq of 1: 1.0
idf(docFreq=1, maxDocs=1): 0.30685282
fieldNorm(doc=0): 0.5
Yeah, kết quả giống với mong đợi (về fieldNorm thì đã có giải thích phía bên trên).
Everything is not so simple
Cảm ơn bạn đã đọc đến đây, nhưng trên thực tế, kể từ bản 5.0, TF/IDF đã không còn được sử dụng như thuật toán default cho similarity trong Elasticsearch nữa rồi. Nghĩa là bạn không cần đọc từ đầu tới giờ cũng không sao!
 Mình nhận ra được điều này khi chạy thực tế đoạn code mình viết bên trên kia (yaoming again =))).
Mình nhận ra được điều này khi chạy thực tế đoạn code mình viết bên trên kia (yaoming again =))).
Đùa chút thôi, các bạn vẫn hoàn toàn có thể sử dụng thuật toán TF/IDF như cũ, chỉ cần thay đổi config của similarity thôi.
"similarity": {
"default": {
"type": "classic"
}
}
Note:
- Trong Elasticsearch có rất nhiều
similarity moduleimplement thuật toán đánh giá similarity giữa các kết quả, TF/IDF và BM25 là một trong số đó, các thuật toán khác các bạn có thể tham khảo thêm tại đây - Elasticsearch phiên bản 2.4 trở về trước thì sẽ mặc định similarity là
classic(tức TF/IDF) - Elasticsearch phiên bản 5.0 trở lên thì sẽ mặc định similarity là
BM25
BM25
Vì giới hạn bài viết, mình sẽ không đi sâu quá vào theory của BM25 mà sẽ show công thức luôn. Các bạn có thể tự tìm hiểu thêm trên google & wiki.
Thực chất, BM25 vẫn dựa trên nền tảng của TF/IDF, và cải tiến dựa trên lý thuyết probabilitistic information retrieval
IDF trong BM25
công thức của BM25 IDF là:
idf(t) = log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5))
Trong đó:
docCount: số lượng documentdocFreq: số lượng document chứa term
TF trong BM25
trong BM25 thì term frequency được tính theo công thức:
((k + 1) * freq) / (k + freq)
Trong đó:
k: hằng số (thường là 1.2)freq: frequency của term trong document
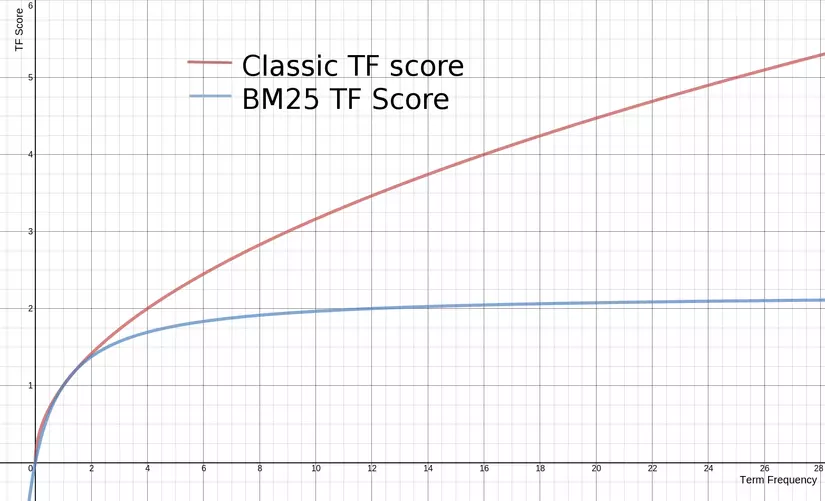
Như các bạn có thể nhìn thấy, đường BM25 TF score tiệm cận dần đến (k+1), trong trường hợp này là k=1.2 (mặc định). tf càng cao thì relevance càng cao. Với BM25 thì k thường được xét giá trị mặc định là 1.2. Tất nhiên bạn có thể điều chỉnh giá trị này để phù hợp với mô hình. Tuy nhiên chú ý một điều là set k càng lớn thì độ hội tụ sẽ càng lâu.
Document Length trong BM25
Thực ra công thức TF bên trên kia là chưa thực sự hoàn chỉnh, nó đúng với những document có độ dài trung bình trong toàn bộ index. Nếu độ dài document quá ngắn hoặc quá dài so với độ dài trung bình, thì công thức trên sẽ cho kết quả thiếu chính xác.
Vì thế người ta thêm vào trong công thức trên 2 tham số, một hằng số b và một giá trị độ dài L, công thức sẽ trở thành:
((k + 1) * freq) / (k * (1.0 - b + b * L) + freq)
trong đó b=0.75 (mặc định), L là tỉ lệ giữa độ dài của document so với độ dài trung bình của tất cả documents.
L = fieldLength / avgFieldLength
Cũng như k, bạn có thể điều chỉnh b để phù hợp với mô hình bạn xây dựng. b càng gần 0 thì độ ảnh hưởng của document length càng nhỏ, và ngược lại, b càng lớn thì độ ảnh hưởng của document length càng lớn.
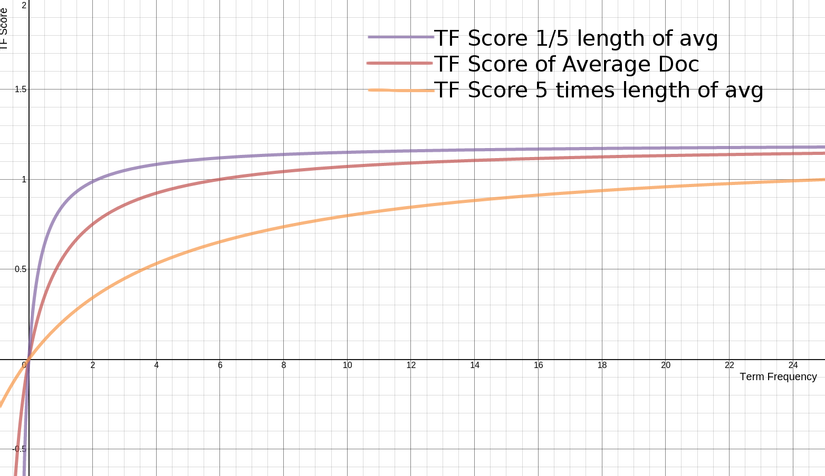
Đây là biểu đồ thể hiện giá trị của TF đối với các độ dài khác nhau của document:
All Together
Ta có công thức cuối cùng của BM25
IDF * (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * (fieldLength / avgFieldLength)))
Time for action - round 2
Chuẩn bị dữ liệu và test:
DELETE /my_index
PUT /my_index
{ "settings": { "number_of_shards": 1 }}
POST /my_index/my_type/_bulk
{ "index": { "_id": 1 }}
{ "title": "The quick brown fox" }
{ "index": { "_id": 2 }}
{ "title": "The quick brown fox jumps over the lazy dog" }
{ "index": { "_id": 3 }}
{ "title": "The quick brown fox jumps hahaha over the quick dog" }
{ "index": { "_id": 4 }}
{ "title": "Brown fox hahaha brown dog" }
GET /my_index/my_type/_search
{
"explain": true,
"query": {
"term": {
"title": "hahaha"
}
}
}
Expected: kết quả cho _id=3 (_id=4 các bạn có thể tự làm)
idf: docCount = 4, docFreq = 2
log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5))
= log(1 + (4-2 + 0.5) / (2+0.5))
= 0.6931471805599453
- TF with document Length: freq = 1 (trong doc chỉ có 1 "hahaha"), k = 1.25, b = 0.75, fieldLength = 10, agvLength = 7
(freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength))
= (1 * (1.25 + 1) / (1 + 1.25 * (1 - 0.75 + 0.75 * (10. / 7))))
= 0.8484848484848484
Vậy _score = 0.6931471805599453*0.8484848484848484 = 0.588124
Actual:
...
"_score": 0.58279467,
...
"value": 0.6931472,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
...
"value": 0.840795,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
Kết quả gần như chính xác hoàn toàn, tuy nhiên vẫn có sai số là do đâu ? Nhìn vào kết quả actual, ta nhận thấy một điểm lạ, đó là fieldLength = 10.24 chứ không phải là 10 ?
Tại sao lại như vậy? Câu trả lời cũng giống như field-Length norm ở bên trên, giá trị được lưu là 8 bit, nên trong quá trình encode với decode dữ liệu đã bị sai khác đi một chút. Tuy nhiên kết quả vẫn có thể chấp nhận được.
Conclusion
Vậy là chúng ta đã đi qua 2 thuật toán để tính toán _score trong Elasticsearch. Hi vọng các bạn có những trải nghiệm thú vị 
What's next?
Có rất nhiều topic liên quan tới chủ đề này mà mình nghĩ các bạn có thể tìm hiểu thêm như:
- Boost query
- analyzed or non_analyzed
- Vector space model
- Các vấn đề liên quan đến perfomance của Elasticsearch
- ...
Enjoy coding !
Tham khảo
All rights reserved
