Thiết kế API Rate Limiting
Bài đăng này đã không được cập nhật trong 7 năm
Làm việc nhiều với API chắc hẳn ai cũng đã từng nghe thấy từ API Rate Limiting. Ví dụ như với Github API thì Rate Limiting của nó như sau:
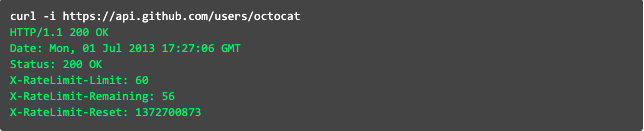
Nhìn vào hình trên có thể thấy Rate Limiting của nó 60 request/min. Nếu mà trong vòng 1 phút gửi quá 60 request thì sẽ không gửi tiếp được nữa. Mà phải đợi đến phút tiếp theo mới gửi được.
Hiện tại hầu hết các hệ thống lớn trên thế giới đều cung cấp Rate Liming cả. Nhưng mà ít ai để ý đến công nghệ đằng sau nó như thế nào.
Hôm nay mình viết bài này để hướng dẫn mọi người cách thiết kế Rate Limiting như thế nào.
Rate Limiting là gì?
Giả sử như hệ thống của chúng ta nhận được hàng nghìn request nhưng mà trong số đó chỉ xử lí được trăm request/s chẳng hạn, và số request còn lại thì bị lỗi (do CPU hệ thống đang quá tải không thể xử lí được).
Để giải quyết được vấn đề này thì cơ chế Rate Limiting đã ra đời. Mục đích của nó chỉ cho phép nhận 1 số lượng request nhất định trong 1 đơn vị thời gian. Nếu quá sẽ trả về response lỗi.
1 số ví dụ hay gặp trong Rate Limiting như:
- Mỗi người dùng chúng ta chỉ cho phép gửi 100request/s. Nếu vượt quá thì sẽ trả về response lỗi.
- Mỗi người dùng chỉ cho phép nhập sai thẻ credit 3 lần trong 1 ngày
- Mỗi địa chỉ IP chỉ có thể tạo được 2 account trong 1 ngày.
Về cơ bản thì rate limiter sẽ cho phép gửi bao nhiêu request trong 1 khoảng thời gian nào đó. Nếu vượt quá sẽ bị block lại.
Tại sao API cần phải có Rate Limiting?
Rate Limiting sẽ giúp chúng ta hạn chế được 1 số việc sau:
- Tấn công DOS (Denial of Service) đến hệ thống
- Brute force password trong hệ thống (quyét kiểu vét cạn)
- Brute force thông tin thẻ credit card (quyét kiểu vét cạn)
Những cuộc tấn công này nhìn có vẻ như đến từ người dùng thực, nhưng thực tế nó được tạo ra bởi bot. Do vậy mà nó rất khó bị phát hiện và dễ dàng làm service của chúng ta bị sập.
Ngoài ra, Rate Limiting cũng mang lại cho chúng ta 1 số lợi ích sau:
- Bảo mật: Không cho phép nhập sai password quá nhiều lần
- Doanh thu: Với mỗi plan sẽ có rate limit khác nhau. Nếu muốn dùng nhiều hơn thì cần mua lên plan đắt tiền hơn.
Yêu cầu hệ thống
Yêu cầu chức năng:
- Giới hạn số lượng request được gửi trong 1 đơn vị thời gian. Ví dụ 15 request/s
Yêu cầu phi chức năng:
- Hệ thống chịu tải cao. Bởi vì rate limiter luôn luôn phải hoạt động để bảo vệ hệ thống từ các cuộc tấn công bên ngoài vào.
- Rate limiting cần có latency thấp nhất để giúp trải nghiệm người dùng tốt hơn.
Rate Limiting hoạt động như thế nào?
Rate Limiting có 1 process tên là Throttling dùng để kiểm soát tình trạng sử dụng API của người dùng trong 1 khoảng thời gian nhất định.
Khi vượt quá giới hạn, nó sẽ trả về response với HTTP Status là 429 – Too many requests.
Thuật toán sử dụng trong Rate Limiting
Có 2 loại thuật toán hay được dùng để giải quyết bài toán này:
Thuật toán Fixed Window
Thuật toán này sẽ được tính từ đầu đơn vị thời gian cho đến hết đơn vị thời gian.

Ví dụ như trong ví dụ bên trên ta có thể thấy, trong khoảng thời gian từ giây thứ 0 cho đến giây thứ 1 có 2 request được gửi, đó là m1 và m2.
Trong khoảng thời gian từ giây thứ 1 đến giây thứ 2 có 3 request là m3, m4, m5.
Nếu như rate limiting đang được cài đặt là 2 thì trong ví dụ bên trên thì thằng m5 sẽ bị block lại.
Thuật toán Sliding Window (Rolling Window)
Trong thuật toán này thì thời gian sẽ được tính từ phần tử thời gian mà yêu cầu được thực hiện cộng với độ dài của time window.
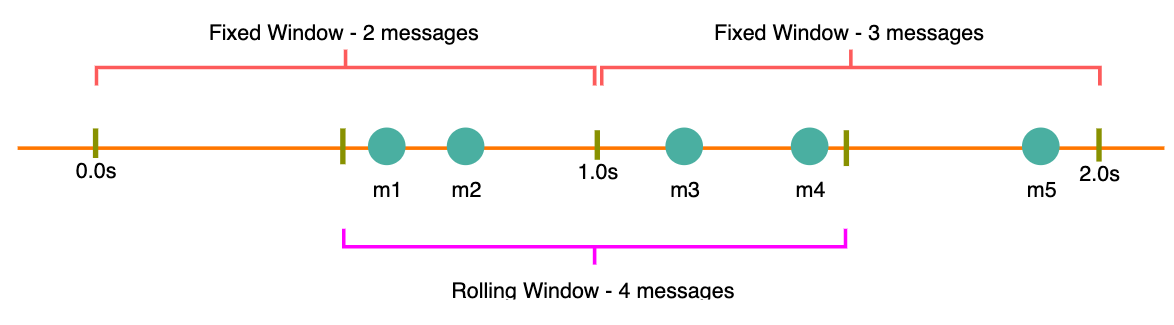
Như trong ví dụ bên trên, giả sử như m1 và m2 được gửi từ giây thứ 0.3s. Khi đó từ 0.3s này sẽ bắt đầu tính.
Trong khoảng 0.3s tiếp theo chúng ta thấy có 2 request tiếp theo được gửi đến đó là m3 và m4.
Như vậy trong khoảng thời gian 0.6s này đã có 4 request được gửi là m1,m2,m3,m4.
Nếu Rate Limiting đang cài đặt là 2 thì khi đó m3,m4 sẽ bị block lại.
Giả sử như thời điểm gửi m5 là lúc 1.1s chẳng hạn. Thì khi đó lúc này rate limiting sẽ reset lại thành từ 0. Và lại lặp lại quá trình đó, và m5 sẽ được tính thành 1 lần.
Kiến trúc Rate Limiting
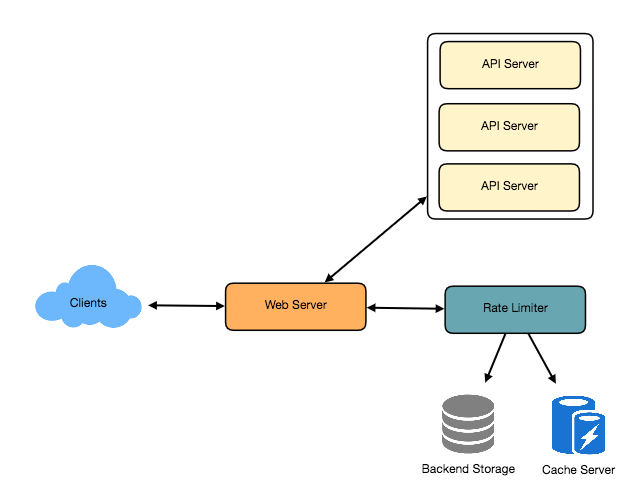
Rate Limiting sẽ đảm nhiệm việc quyết định xem request nào sẽ được gửi đến API Server, request nào sẽ bị block.
Mỗi khi Client gửi request đến Web Server, Web Server sẽ gọi đến Rate Limiter để check xem ngươi dùng này đã vượt quá số Rate Limiting hay chưa? Nếu chưa thì sẽ gửi request đó đến API Server. Nếu đã vượt quá rồi thì sẽ block lại và trả về http status 429 (Too many requests).
Cài đặt thuật toán
1. Thuật toán Fixed Window
Khi người dùng gửi request đến hệ thống, chúng ta sẽ lưu số request đã gửi vào 1 biến count cùng với thời điểm start_time gửi request.
Sau đó sẽ lưu count vs timestamp vào 1 hash table (Có thể là Redis, memcached …). Trong đó key sẽ là user_id và value sẽ chứa json bao gồm số lượng request đã gửi, cùng với thời điểm timestamp.
Tại sao nên dùng Redis mà không nên dùng mysql?
Dùng mysql để lưu trữ dữ liệu là 1 ý tưởng khá tồi. Bởi vì thời gian đọc ghi dữ liệu ở mysql sẽ lâu hơn rất nhiều so với việc dùng redis (memory).
Ví dụ như chúng ta mất 1ms để lưu 1 record vào mysql thì khi đó 1s chúng ta sẽ xử lí được 1000 request.
Thế nhưng với hệ thống như Redis nó không sử dụng disk mà sử dụng memory để lưu nên tốc độ đọc ghi sẽ khá là nhanh. Ví dụ nó mất 100 nanosec để lưu 1 record thì 1s nó sẽ xử lí được tầm 10 triệu request.
Mà hệ thống Rate Limiting này cần phải tối đa tốc độ query để lấy count nên Redis sẽ hợp lí hơn rất nhiều.
Về cấu trúc dữ liệu lưu trong hash table sẽ như sau:
user_id: {count, start_time}
Ví dụ:
12: {3, 1560580210}
5: {2, 1560520442}
Giả sử như rate limiter sẽ cho phép 3 request/min. Khi đó flow thực hiện sẽ như sau:
- Nếu user_id không có trong hash table, khi đó sẽ insert user_id vào trong hash table cùng với thời điểm gửi (dạng epoch time)
- Nếu user_id có nằm trong hash table, khi đó sẽ tìm value tương ứng với user_id đó và tính toán xem current_time – start_time >= 1 min hay không?
- Nếu có lớn hơn thì khi đó set start_time bằng current_time và count = 1 và cho phép request gửi đến API Server.
- Nếu nhỏ hơn thì kiểm tra xem count có lớn hơn 3 hay không. Nếu lớn hơn thì sẽ block request đó lại. Nếu nhỏ hơn thì sẽ count = count + 1 và cho phép request gửi đến API Server.
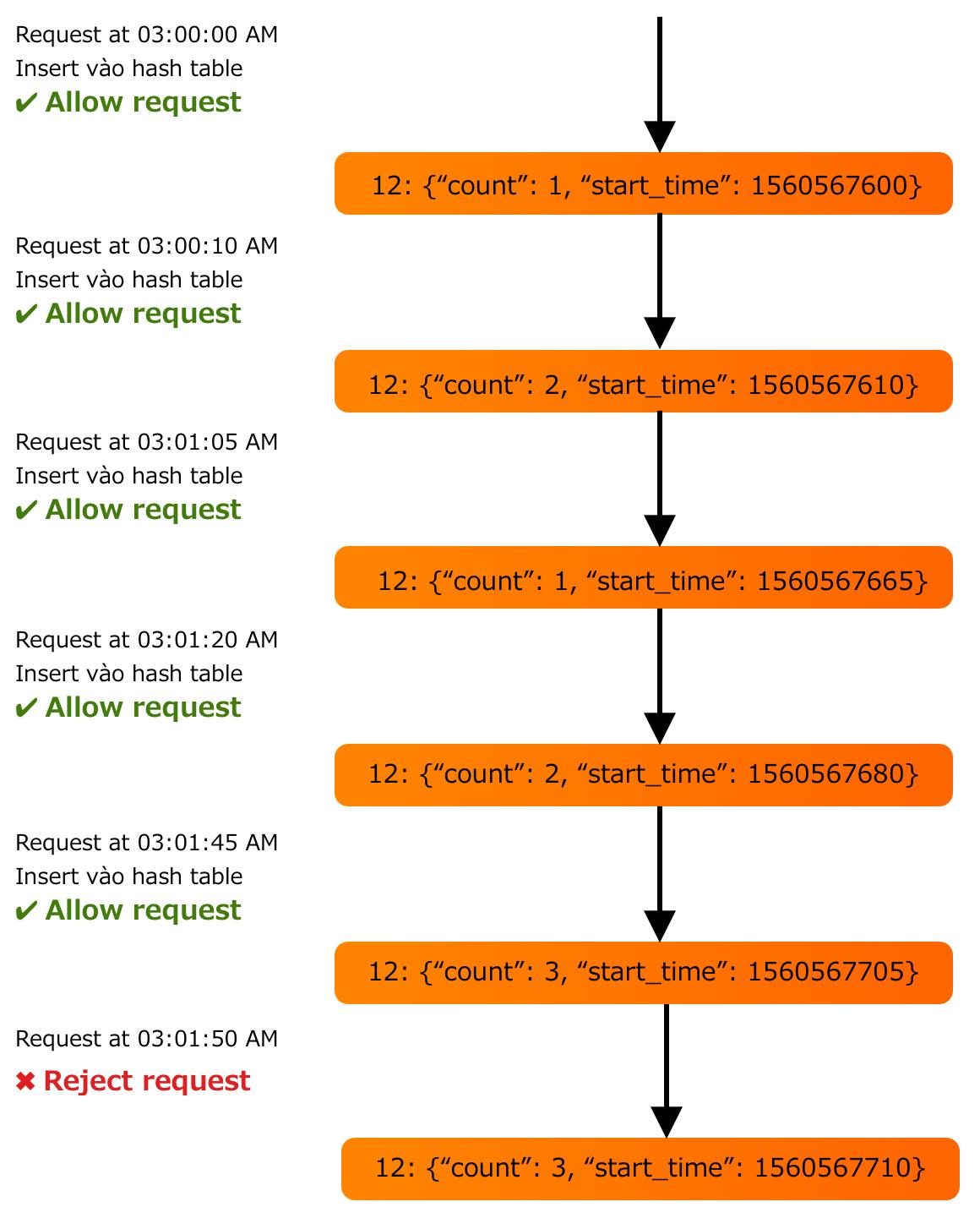
Vấn đề với thuật toán này là gì?
Bởi vì count sẽ bị reset tại thời điểm cuối cùng của mỗi phút. Do đó sẽ dẫn đến tình trạng có thể gửi nhiều hơn 3 request/min.
Ví dụ như tại giây thứ 59.01 người dùng gửi 3 request. Tại thời điểm này count trong hash table bằng 0. Trong khi chuẩn bị update count vào hash table thì người dùng đó lại tiếp tục gửi 10 request nữa. Khi đó lúc này count lấy được vẫn bằng 0 chứ không phải bằng 3 nên nó đã bypass được cái rate limiter này 1 cách dễ dàng.
Nói là như vậy nhưng để thực hiện được cũng rất khó. Phải thao tác cực nhanh và độ trễ chỉ tính bằng mili giây hoặc nano giây thôi. Còn không sẽ vẫn bị block.
Để giải quyết được vấn đề này thì chúng ta có thể dùng Redis lock để lock lại count trước khi update (tức là phải update xong mới cho select).
Tuy nhiên điều này có thể sẽ làm cho logic của chúng ta bị chậm khi nhiều request được gửi đồng thời từ 1 người dùng. Bởi vì khi select sẽ lock lại count của người dùng đó lại. Sau khi update count xong mới giải phóng lock để cho request tiếp theo dùng.
Chú ý là cái việc lock này chỉ lock lại record của người dùng đó thôi nhé. Còn không lock lại record của người dùng khác. Hay nói cách khác chỉ lock row chứ không lock cả table.
Cần bao nhiêu memory để lưu trữ tất cả dữ liệu của người dùng?
Vì hash table của chúng ta sẽ lưu (user_id, count, start_time) nên chúng ta sẽ cần:
- 8 bytes cho user_id
- 2 bytes cho count (vậy giá trị max của count sẽ là 2^16 = 65,536)
- 4 bytes cho start_time (lưu dạng epoch time)
Khi đó sẽ dùng tổng cộng 8 + 2 + 4 = 14 bytes để lưu dữ liệu người dùng.
Giả sử như chúng ta cần 20 bytes cho overhead của hash table. Khi đó với 1 triệu người dùng sẽ cần:
(14 + 20 ) bytes * 1 triệu = 32.42 MB
Giả sử chúng ta cần 4 bytes để khoá mỗi record của người dùng để giải quyết vấn đề bên trên thì tổng cộng chúng ta sẽ cần:
(14 + 20 + 4) bytes * 1 triệu = 36 MB
Với rate limiting là 3 request/min thì hoàn toàn có thể đặt redis trên 1 con server. Tuy nhiên nếu chúng ta tăng rate limiting thành 10 request/s thì khi đó redis sẽ phải chịu khoảng 10 triệu request/s. Khi đó 1 con redis sẽ không thể chịu được nhiệt.
Để giải quyết bài toán này thì chúng ta sẽ dùng nhiều con redis đặt phân tán. Khi update count vào trong redis thì rate limiter sẽ cần phải update trong tất cả những con Redis đó thì mới được.
2. Thuật toán Sliding Window
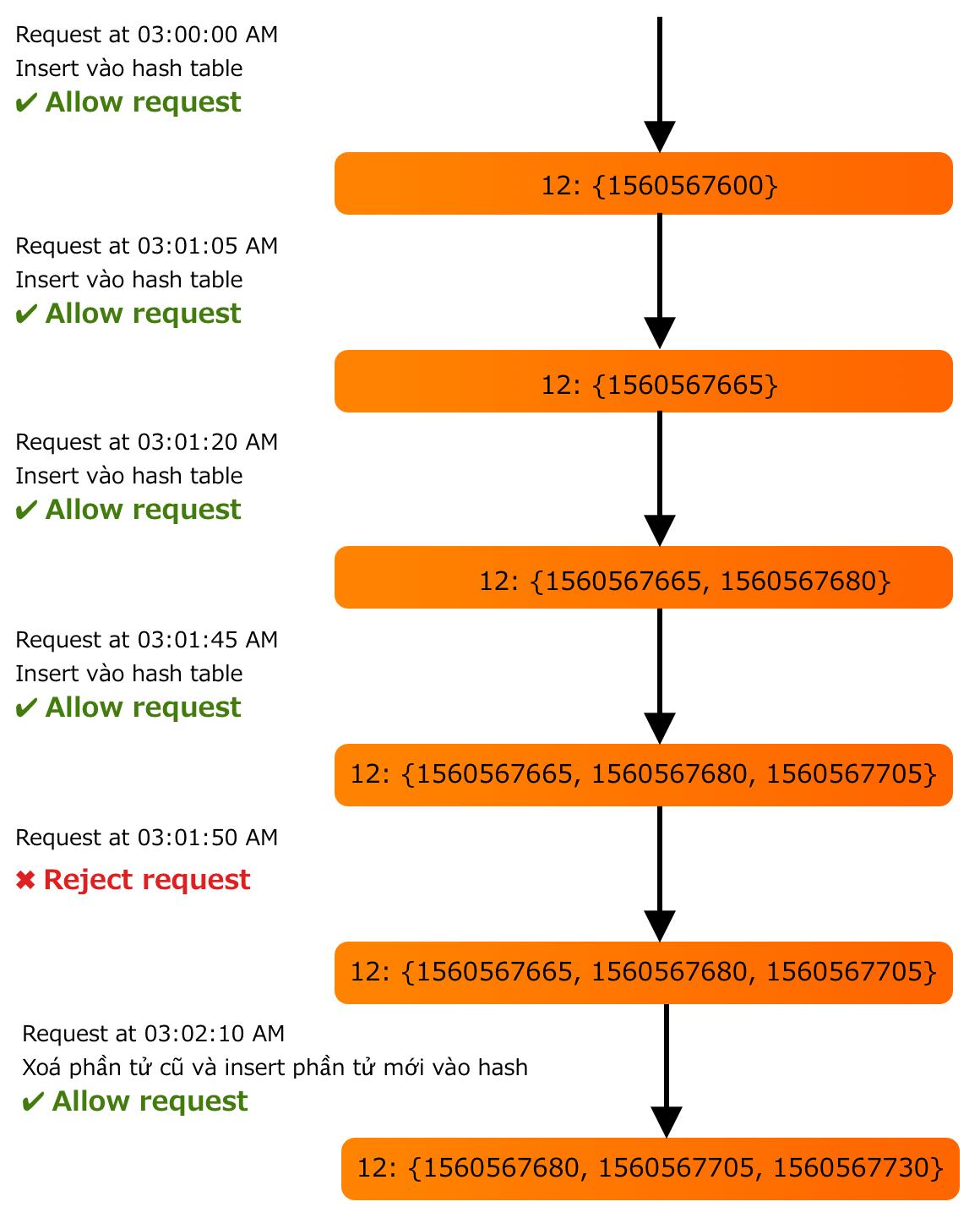
Để làm được thuật toán này thì chúng ta cần lưu thời gian gửi mỗi request lại, thay vì chỉ lưu giá trị gửi cuối cùng. Và sử dụng Redis Sorted Set.
user_id: {count, Sorted Set <start_time>}
Ví dụ:
12: {1560580210, 1560580212, 1560580213}
5: {1560520442}
Giả sử như rate limiter cho phép gửi 3 request/min. Khi đó flow sẽ như sau:
- Xoá tất cả các start_time trong Sorted Set mà có giá trị current_time – 1 min < 0
- Tính tổng số lượng phần tử trong Sorted Set. Nếu tổng này > 3 thì sẽ block request đó lại.
- Insert start_time đó vào trong Sorted Set và cho phép request gửi đến API Server.
Với thuật toán này thì cần bao nhiêu memory để lưu dữ liệu?
Cấu trúc dữ liệu của chúng ta sẽ như sau:
user_id: {start_time_1, start_time_2 ...., start_time_n}
Chúng ta sẽ cần 8 bytes để lưu user_id, 4 bytes để lưu epoch time.
Giả sử như overhead của Sorted Set là 20 bytes, overhead của hash table là 20 bytes. Rate Limiting là 500 request/hour. Khi đó chúng ta sẽ cần:
8 + (4 + 20 bytes Sorted Set overhead) * 500 + 20 bytes hash table overhead = 12KB
Nếu chúng ta có 1 triệu user thì khi đóng tổng dung lượng bộ nhớ cần sẽ là:
12 KB * 1 triệu = 12GB
So sánh với thuật toán Fixed Window thì thuật toán Sliding Window dùng khá nhiều memory để lưu trữ.
Kết luận
Các bạn thấy việc thiết kế Rate Limiting cho API thế nào? Cũng không quá khó phải không nào.
Hi vọng qua bài này sẽ giúp các bạn biết cách thiết kế Rate Limiting, giúp cho API của mình trở nên chuyên nghiệp hơn.
Nguồn: https://nghethuatcoding.com/2019/06/15/thiet-ke-api-rate-limiting/
==============
Để nhận thông báo khi có bài viết mới nhất thì các bạn có thể like fanpage của mình ở bên dưới nhé:
→→→ Nghệ thuật Coding Fanpage Facebook
Chúc các bạn 1 tuần thật vui vẻ.
All rights reserved
