Performance Optimization 102: Scalability và câu chuyện về ảo tưởng distributed
Bài đăng này đã không được cập nhật trong 5 năm
Performance, scalability cùng câu chuyện nỗi ám ảnh và những ảo tưởng của một developer về cái gọi là hệ thống distributed.
Đó... là một câu chuyện buồn (tiếng thở dài...) về nguồn tài nguyên con người.

First things first
Chào mừng các bạn đã trở lại với series Performance Optimization Guideline, cẩm nang gối đầu giường dành cho những Performance Engineer bất đắc dĩ.
Tại sao mình lại nói là bất đắc dĩ? Là bởi vì phần đông chúng ta ngồi đây, những người đọc bài viết này không phải là những người đi theo hướng Performance Engineer từ đầu, cũng chưa chắc đã là những người có tình yêu tình báo gì với lại tối ưu performance đâu (just kidding =))).
Chuyện là đến một ngày đẹp trời, thứ chúng ta làm ra bỗng trở nên già nua, yếu đuối trước sự đổi thay của công nghệ và sự phát triển của việc kinh doanh (trộm vía nhiều người dùng thích nhé). Có chăng chỉ có lên núi tìm được thứ tiên dược cải lão hoàn đồng thì những cỗ máy kiếm tiền già nua và chậm chạp của chúng ta mới xuân sắc trở lại.
Nhưng lạ chưa, giữa cái xã hội mù quáng và nguy hiểm này, tiên dược hóa ra lại được bày bán nhan nhản ngoài chợ dưới cái mác distributed system. Công nhận là mọi người xung quanh nhạy bén thật. Chẳng mấy chốc mà làng trên xóm dưới ai ai cũng đều có vài lọ distributed system với cả micro services trong tay. Bỗng nhiên distributed system trở thành 1 món trang sức mà ai ai cũng muốn có, ai ai cũng muốn đeo. Nhưng thực hư liệu loại tiên dược được bày bán nhan nhản này có tốt như lời đồn, hay nó có giúp chữa được căn bệnh yếu performance của chúng ta không? Hãy cùng tìm hiểu trong Performance Optimization Guideline chapter 2 lần này.
Nhưng trước hết, hãy cùng đánh dấu vị trí của chúng ta kẻo lạc trôi trong câu chuyện dài kỳ này nhé:
-
Chap 2: Scalability và câu chuyện về ảo tưởng distributed <~ YOU ARE HERE
-
Chap 4: Trinh sát ứng dụng với monitoring / profiling
-
Chap 5: Database optimization - Đuổi bắt kẻ tội đồ
-
Chap 6: Caching optimization - Con đường lắm chông gai
-
Chap 7: Buffering optimization - Bước đệm cần thiết
-
Chap 8: Connection optimization - Những cái chết đau thương
-
Chap 9: Coding optimization - Liệu có đáng không?
-
Chap 10: System optimization - Khi nhịp tim ở 3GHz
-
Chap 11: Architect optimization - Trở lại vạch xuất phát
Mình là Minh Monmen, người dẫn đường sẽ tiếp tục đồng hành cùng các bạn trong bài viết này. Hy vọng các bạn sẽ tiếp tục ủng hộ mình bằng việc upvote và clip lại bài viết về đọc dần nha.
Okay, let't dive in.
Why should I care?
Ô gượm gượm chút đã, tại sao câu chuyện scalability và distributed system lại tự dưng xuất hiện trong series về performance này thế?
Nói ra thì nó lại là cái duyên nợ kinh khủng lắm các bạn ạ. Hãy xem chiếc hình sau:
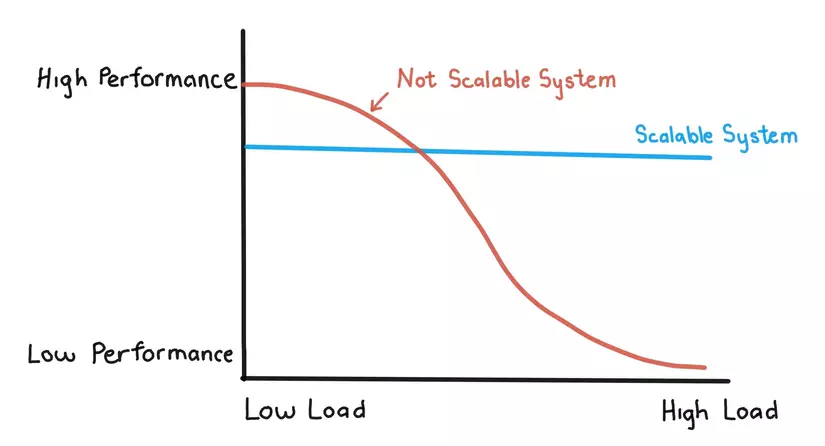
Nhìn hình là các bạn cũng hiểu tại sao chúng ta ở đây rồi đúng không? Con đường tối ưu performance của chúng ta không phải chỉ là làm sao cho cái app của chúng ta nhanh như flash, lên đỉnh nhanh rồi lại xìu nhanh mà là cả một sự cố gắng để duy trì phong độ cái performance đó trong cả cuộc chơi dài.
Sau chap trước mang đầy hơi hướng học thuật rồi thì chúng ta sẽ đổi phong cách 1 chút sang nói về y học nhé. Chapter này sẽ mang tới cho các bạn câu chuyện về những vị kỹ sư phần mềm kiêm lang băm lang vườn sử dụng tiên dược distributed như thế nào.
Và vì đây là 1 câu chuyện buồn, nên mình sẽ kể luôn trước tất cả những thứ hay ho khác, ngay khi các bạn mới chân ướt chân ráo bước chân vào con đường tối ưu performance này để các bạn có thể giữ mindset của bản thân luôn đi đúng hướng, đừng vì dăm ba cái công ty tỷ đô khoe khoang hệ thống thành công mà adua học theo thì sẽ nhận trái đắng đấy.

Scalability và parallel system
Thông thường để scale 1 hệ thống thì có 2 cách cơ bản là: Horizontal scaling và Vertical scaling. Nếu các bạn đã nghe được tới 2 khái niệm trên, thì mình lại chắc thêm 1 điều nữa đó là ai cũng biết tư tưởng horizontal scaling mới là con đường scale hệ thống chân chính, là chánh đạo. Còn vertical scaling chỉ là cách làm của lũ nhà giàu lười biếng. =))
Với mindset đó, bạn lao vào con đường tìm kiếm vinh quang từ sự chia rẽ nội bộ (code). Đi theo con đường horizontal scaling bạn sẽ bắt gặp khái niệm parallel system và distributed system:
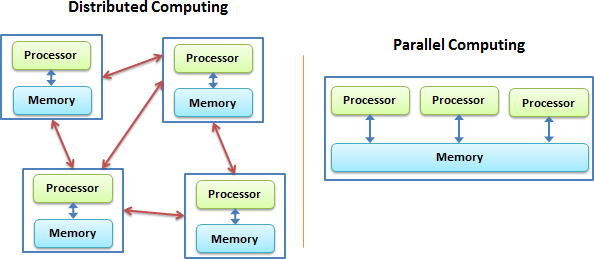
Parallel system là multiple compute component (có thể là thread, hoặc cả app, cả service) cùng share nhau 1 memory component. Distributed system là mỗi compute component sẽ đi cùng memory component riêng.
Tới đây, các bạn sẽ được trải nghiệm triệu chứng đầu tiên của căn bệnh: parallel system. Mọi người muốn tăng performance, tăng khả năng scalability bằng việc chạy nhiều instance app hơn, rồi hì hục đọc nào là stateless application, rồi parallel processing, rồi multi threading các thứ các thứ. Xong lại hì hục hì hục implement vào code, rồi refactor các kiểu. Xong.
Lúc này bạn vui mừng khôn xiết, đưa hệ thống lên chạy. Chạy được luôn. Ôi mình thật là giỏi. Bạn benchmark 1 chút, thấy hệ thống cũng có vẻ ngon đó, performance cứ phải gọi là căng đét, thế là chạy liền luôn mấy chục instance cho nó máu, hệ thống của mình giờ có khả năng serve được triệu user luôn chứ chẳng chơi.
Nhưng không, sau khi chạy thật và sau 1 lần peak traffic bình thường (mà mọi lần vẫn xử lý ngon) thì hệ thống của bạn lăn ra chết. Not responding luôn.
Sự thật là parallel system sẽ đi kèm với chiếc bottleneck siêu to khổng lồ về performance chính là phần được share chung giữa các instance (database, memory, file system,...). Lúc này khi hệ thống bắt đầu cao tải thì càng nhiều instance sẽ càng làm phần share này chịu gánh nặng và nhanh chóng chết hơn hoặc kéo performance của toàn hệ thống đi xuống.
Bọn mình đã từng mắc phải sai lầm này trong những ngày đầu ra mắt sản phẩm, quá tin tưởng vào hệ thống xử lý song song dẫn tới toàn bộ ứng dụng trở nên chậm chạp và down hẳn. Sự việc này xảy ra ở cả phần API cho user cũng như internal queue để chạy background job:
- Chạy 100 instance app monolith nhưng dùng chung 1 server database và gặp những vấn đề về số lượng connection, quá tải database do concurrent query,...
- Share database giữa nhiều service khác nhau (thay vì có db riêng và gọi API để giao tiếp thì dùng chung luôn DB), và kết quả là gặp vấn đề service không quan trọng giết database của service quan trọng, data bị lệch lung tung, deploy lỗi nhiều lần do migration script ở nhiều db khác nhau.
- Tăng concurrent job lấy ra từ queue và làm thời gian xử lý 1 job tăng lên nhiều hơn và throughput của hệ thống lại bị giảm xuống nhanh hơn.
Sau đó bọn mình đã phải trau dồi thêm kiến thức về performance optimization theo hướng phân tích resource (đã giới thiệu trong bài trước) để biết được các điểm tới hạn cũng như bottleneck của hệ thống thật sự nằm ở đâu.
TIPs: Với parallel system, hãy chấp nhận performance của hệ thống ở mức vừa phải để có sự chống chịu traffic cao hơn. Tìm hiểu về các giải pháp giảm lượng request concurrent như throttling và circuit breaker cho hệ thống này.
Scalability và distributed system
Tiếp tục tiến hoá từ hệ thống parallel monolith =)), bọn mình dấn thân vào những hệ thống distributed thật sự với việc triển khai micro-services và các giải pháp distributed database với hy vọng hệ thống tỷ đô của google, facebook, netflix,... sẽ được tái hiện ở phiên bản Việt Nam. Nhưng mọi chuyện lại chẳng hề đơn giản như chúng ta suy nghĩ.
Distributed database
Distributed database nôm na là các loại database có khả năng scale out, tức là horizontal scaling.
Có 1 dạo Solution Architect bên mình bị hâm mộ các loại distributed database quá đà và tưởng tượng rằng chỉ cần thay database là bài toán về performance, bottleneck, scaling,... sẽ tự nó được giải quyết. Team devops bọn mình thường nói vui với nhau là:
Giàu đổi bạn, sang đổi vợ, vỡ app đổi db
Cassandra, Riak, FoundationDB, TiDB,... lần lượt được gọi hồn lên và được áp dụng vào sản phẩm với kỳ vọng sẽ nhảy 1 phát tới hệ thống mấy chục triệu user. Chỉ tiếc là sau những khoảng thời gian rất dài development, mấy chục triệu đâu thì chưa tới, chỉ mấy trăm nghìn với mấy triệu user thôi cũng đã gây không ít khó dễ với tụi mình này rồi. Tất nhiên là không phải vì cái database, mà bởi vì người làm sản phẩm không hề để tâm tới cái nguồn lực hữu hạn của hệ thống là con người và thời gian. Nó giống như việc bạn đưa 1 cái engine xe công thức 1 cho 1 tay đua xe đạp và bảo anh ta đua với mỗi mình cái động cơ đó vậy.

Đây là thứ bọn mình đã rút ra về 1 số distributed database trên:
- Cassandra có performance write rất tốt, nhưng chỉ phù hợp với data dạng history, log. Bạn phải LƯU Ý KỸ điều này: nếu bạn vẫn là tay mơ trong design database, hãy lưu metadata (những data kiểu info hay thay đổi chứ không có tính lịch sử) ra chỗ khác. Bọn mình đã từng phải thay DB 1 lần vì điều này đấy.
- FoundationDB nói chung có read write performance rất tốt, nhưng chi phí nguồn lực về mặt con người, thiết kế, hạ tầng, vận hành rất lớn. Nó phù hợp với những bài toán có dữ liệu lớn nhưng logic đơn giản, ĐỪNG DÙNG NÓ CHO NHỮNG BÀI TOÁN DỮ LIỆU NHỎ HAY LOGIC PHỨC TẠP.
- Mình chưa đủ to để chạy được mấy thằng Distributed Key-value như riak, fdb hay Distributed SQL như Percona, TiDB,... Thử nghiệm rồi lại thử nghiệm rồi cũng phải chấp nhận distributed thường mang lại khả năng scale nhưng thời gian phát triển tăng lên cấp số mũ hoặc performance sẽ giảm đi kha khá, do đó cần có thêm nhiều giải pháp đi kèm để có thể khắc phục vấn đề này. Cái này có thêm 1 usecase từ GHTK cũng là bên đã từng nghiên cứu áp dụng Percona cluster nhưng từ bỏ và quay về MySQL replica truyền thống để giữ được performance và mô hình hệ thống đơn giản.
- Những bài toán của bọn mình sau đó đã có thể giải quyết 1 cách đơn giản hơn bằng việc sử dụng những loại DB thông thường phục vụ nhiều mục đích như MySQL, MongoDB, PostgreSQL,... Chú trọng vào việc tối ưu performance trên những thứ mình đã quen thuộc thì dễ dàng và hiệu quả hơn rất nhiều so với việc bắt đầu một thứ hoàn toàn mới mẻ và fancy của bè lũ tỷ đô.
Cuối cùng, điều quan trọng nhất mà mình nhận ra là: Performance của ứng dụng không hề tăng lên khi đổi DB mà không đổi mindset code.
TIPs: Nếu muốn sử dụng distributed database, hãy đảm bảo các bạn đã chuẩn bị tâm lý chấp nhận performance drop và các giải pháp đi kèm một cách đồng bộ. Đừng như bọn mình thay mỗi cái DB rồi nghĩ là xong nhé.
Micro services
Micro services là dạng distributed system điển hình nhất mà chắc hẳn các bạn sẽ nghĩ tới ngay khi nghe tới khái niệm này. Trend làm micro services đã bắt đầu từ vài năm trước, khi hệ sinh thái container bắt đầu phát triển và việc quản lý số lượng lớn service và các vấn đề về service discovery, load balancing, circuit breaker,... trở nên dễ dàng hơn. Đúng là nó đem lại cho các bạn rất nhiều lợi ích cho performance hệ thống. Đơn cử 1 vụ nhỏ nhỏ bọn mình đã thực hiện là: Tách luồng read / write 1 resource ra 2 service khác nhau.
- Service write thì sử dụng nodejs để phục vụ việc phát triển nhanh và logic phức tạp, có sử dụng queue để đảm bảo performance.
- Service read thì được viết bằng ngôn ngữ khác như Go và được áp dụng thêm nhiều thứ như hệ thống caching, streaming,... để tối ưu việc read siêu nhanh và lượng throughput lớn.

Thế nhưng sau 1 thời gian triển khai micro services, bọn mình nhận ra mặc dù được sinh ra để việc tối ưu từng service có thể dễ dàng hơn, nhưng chính nó cũng là nguyên nhân khiến cho hệ thống của bạn gặp nhiều các vấn đề về performance hơn. Trong đó mình sẽ kể đến vài case điển hình như này:
- Connection loop. Trong những ngày đầu do việc tách monolith thành micro services chưa được tính toán kỹ càng, dẫn tới xảy ra tình trạng kết nối vòng tròn, well, sau đó thì... không có sau đó nữa.
-
Connection giữa các component. Hệ thống giao tiếp với nhau thông qua HTTP và không quản lý connection pool hay keep alive. Tới lúc user gọi nhiều là request từ ngoài chỉ có 1 thôi nhưng connection giữa các service trong hệ thống lên tới 3-4. Lúc này chỉ cần 1 service phụ quá tải và hang connection là dẫn tới chết cả service chính.
-
Latency tăng mạnh. Yeah, các bạn nghĩ mỗi micro services sẽ được thiết kế nhanh chóng gọn gàng, mỗi request chắc là chỉ mất <10ms để phản hồi, thì giờ có gọi chéo nhau vài cái thì tổng latency cũng chỉ tới 50 -> 100ms đúng không? You wrong!!! Nó lại thành 1->5s cho 1 request chứa gọi chéo luôn các bạn ạ. Đừng đùa với latency cộng dồn.
TIPs: Đây mới chỉ là những cái vấn đề dễ thấy nhất của hệ thống micro services thôi đó. Bọn mình đã phải refactor toàn bộ hệ thống để quy hoạch lại luồng dữ liệu sau khi gặp quá nhiều vấn đề về mặt quản lý và performance. Khuyến cáo các bạn có thể đọc thêm 1 số bài trên blog của Tiki để có thêm kinh nghiệm về vấn đề quy hoạch này.
Distributed cache
Đây là thằng mà để sử dụng hiệu quả thì các bạn phải có kinh nghiệm về monitoring (mà mình sẽ hướng dẫn trong các bài viết tiếp theo) và hiểu biết sâu về cách dữ liệu được tiếp cận trong hệ thống của bạn. Có 2 cái vấn đề mình đã gặp với thằng distributed cache này:
- Bài toán cố hữu chính là bài toán của distributed system khi muốn thao tác với multiple data bị rải rác trên các node khác nhau. Một hệ thống của bọn mình sau khi sử dụng Redis để làm database trung gian đã trở thành performance bottleneck khi không thể sử dụng Redis Cluster (sharded data) vì thao tác trên multiple key.
- Cache không hiệu quả (tỷ lệ hit/miss thấp) vì load balancer không chia tải được theo nội dung request mà chỉ chia đều, do đó xảy ra trường hợp hy hữu là bạn càng có nhiều instance cache thì performance của hệ thống càng giảm do data bị duplicate trên nhiều server cache. Cái phần monitor này nhiều người sẽ không để ý theo dõi nếu tự code cache trên application (không dùng redis hay memcache)
- Hot/cold instance do không để ý Redis cluster được sharding dựa vào key level nên đã thiết kế 1 key dạng HASH để lưu metadata cho toàn bộ data trong app. Mà cái metadata này được access cực kỳ nhiều, dẫn tới có instance thì ngồi chơi, có instance thì quá tải dẫn tới performance cả ứng dụng giảm.
TIPs: Caching sẽ là 1 kỹ thuật rất lớn và loằng ngoằng mà mình sẽ nhắc tới cụ thể hơn trong những bài viết sau.
Vài lời sau cuối
Nghiện distributed là một căn bệnh tốn kém và khó cai. Nó thể hiện tham vọng của giới backend trong quá trình làm việc với mong muốn một ngày mình sẽ trở thành ông lớn trong làng công nghệ. Thế nhưng cái gì cũng có 2 mặt rõ ràng và để bước đi trên con đường đầy chông gai này một cách tự tin thì không những yêu cầu kiến thức uyên thâm mà còn cả sự kiên định để tránh khỏi cám dỗ nữa. Đừng nghiện nhé, khổ lắm.
Rất hy vọng rằng các bạn sẽ đón đọc những chap tiếp theo của mình về công cuộc tối ưu performance. Hẹn gặp lại các bạn ở Chap 3: Nghệ thuật tìm kiếm bottleneck.
P/s: Hãy upvote và clip bài viết để ủng hộ tác giả nha.
All rights reserved
