Performance Optimization 103: Nghệ thuật tìm kiếm bottleneck
Bài đăng này đã không được cập nhật trong 4 năm
Những phương pháp thượng thừa để biến bạn trở thành bậc thầy bới lông tìm vết à bới hệ thống tìm bottleneck.
Đây cũng là những phương pháp được các cảnh sát performance bọn mình sử dụng hàng ngày để bắt bớ hội dev code láo và hội SA design lởm. Cái bạn cần lựa chọn là bạn sẽ về phe Terrorist hay Counter Terrorist.
Nếu là phe cảnh, bạn sẽ học được cách bắt bớ.
Nếu chọn phe cướp, bạn sẽ học được cách lẩn tránh.
Nếu bạn bê đuê không biết ở phe nào, thì có thể đóng vai chàng thư sinh đi ngang qua đường tiện tay lấy về dọa cho anh em đồng trang lứa sợ cũng được.

First things first
Xin chào các bạn, Minh Monmen đã lại trở lại trong bài viết số 3 của series Performance Optimization Guideline rồi đây. Trong 2 bài trước, chúng ta đã cùng khởi động với những câu hỏi cơ bản của Performance Optimization, thêm chút hồi hộp sợ hãi cùng những ảo tưởng về distributed cho nhịp tim tăng lên chút đỉnh rồi đúng không?
-
Chap 2: Performance Optimization 102: Scalability và câu chuyện về ảo tưởng distributed
-
Chap 3: Performance Optimization 103: Nghệ thuật tìm kiếm bottleneck <~ YOU ARE HERE
Nhiêu đó là đủ vui vẻ rồi, giờ làm việc nghiêm túc và khoa học nào. Hãy thể hiện mình là người trưởng thành và chuyên nghiệp thông qua việc thank và tín dụng cho tác giả bằng cách upvote và clip bài viết về ngâm cứu dần nhé.
Trong bài viết số 3 này, mình sẽ cùng các bạn thi triển các kỹ thuật: Bắt sâu trong lá, Dụ rắn khỏi hang để tìm kiếm các điểm nghẽn của hệ thống (hay còn gọi là bottleneck). Bao gồm việc đưa ra những phương án thi triển 1 cách cụ thể và có cơ sở khoa học để với bất kỳ hệ thống nào các bạn cũng có thể tiến hành phân tích và đưa ra solution.
Bottleneck của hệ thống là thuật ngữ để ám chỉ các điểm ứ đọng, các điểm cản trở performance của toàn bộ hệ thống. Tìm bottleneck của hệ thống là bước đầu tiên trong tối ưu performance của hệ thống.
Và không dài dòng thêm nữa, quẩy luôn cho nóng nào.
Bắt đầu từ đâu?
Trở ngại đầu tiên của hầu hết những người mới bước chân vào giới tối ưu hóa đó chính là: Không biết bắt đầu từ đâu đúng không? Bởi vì một hệ thống thì luôn luôn bao gồm rất nhiều các vấn đề về performance, những vấn đề này có thể đứng riêng, hoặc tương tác với nhau để gây ra những vấn đề to hơn, rồi biến đổi tiến hóa liên tục khi tiếp cận với các công nghệ mà bản thân chưa nắm rõ,...
Mình cũng đã từng như vậy, cũng đọc rất nhiều bài tut trên mạng, đọc sách, blog... về performance. Nhưng những thứ đó nó giống chỉ học những mảnh ghép rất nhỏ, phân mảnh và rời rạc. Làm sao để nó trở thành 1 phương pháp thật sự áp dụng được vào công việc của mình mà không bị vướng chân vào những cái thừa thãi.
1 số bạn dân công nghệ thuần túy mình thấy trước kia thường xuyên bị sa lầy vào micro-optimization, tức là tối ưu từ cái lựa chọn foreach hay for truyền thống cơ. Nói không phải mê tín chứ thật sự các bạn làm được thì cũng tốt, nhưng cái việc làm của các bạn ấy thì theo mình phần lớn vẫn là mất thời gian vô ích, bởi vì dù tốn thời gian vào tối ưu, nhưng kết quả đem lại chẳng được mấy, hay nói đúng hơn là thay đổi nó nhỏ tới nỗi vác kính hiển vi vào soi còn khó thấy.
TIPs: Micro-optimization là thuật ngữ để chỉ hoạt động tối ưu từng dòng code nhỏ, chủ yếu là tối ưu các kỹ thuật và đường lối code để có performance cao hơn. Bạn có thể hay gặp những bài viết dạng: for vs foreach vs for of.
Vậy thì làm sao để không mất thời gian vào tối ưu những cái thừa thãi? Chính là tìm ra cái gì mới thật sự là bottleneck của hệ thống. Bắt đầu từ việc đo lường và theo dõi hệ thống một cách thường xuyên và có chủ đích. Sau đó học cách thiết đặt priority của vấn đề bằng cách xem xét xem cái gì mới thật sự có ảnh hưởng lớn.

1 ví dụ về tầm ảnh hưởng và mức độ impact của các vấn đề giảm dần:
Slow query > caching > connection pool > memory leak > coding optimization.
Lưu ý: Ở trên chỉ là 1 ví dụ thường thấy về mặt định tính cho sự sắp xếp của các vấn đề. Để có thể đưa ra kết luận cho hệ thống của bạn thì sẽ phải cần đo lường.
Mọi con đường đều dẫn tới thành Rome
Phần này sẽ đề cập tới những con đường để các bạn bắt đầu truy đuổi bottleneck. Cái này cũng không phải mình nghĩ ra mà đã được đề cập trong quyển Systems Performance: Enterprise and the cloud. Trước khi đọc sách thì mình cũng từng làm na ná vậy nhưng không biết là người ta đã quy kết nó thành phương pháp từ lâu rồi.
Có rất nhiều phương pháp, tuy nhiên mình sẽ chỉ liệt kê 1 số cái mình thấy đem lại kết quả rõ ràng nhất.
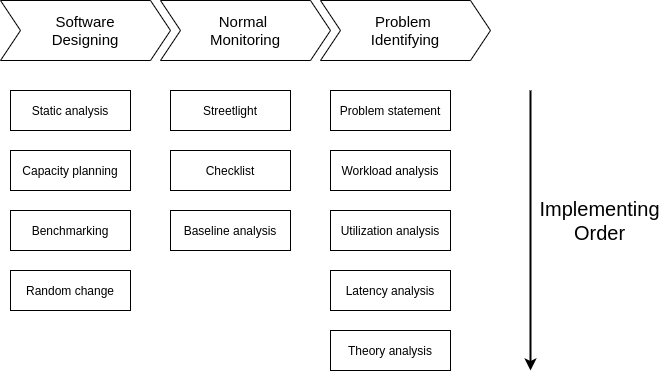
Ở đây mình sẽ chia làm 3 giai đoạn: Software Designing (giai đoạn phát triển), Normal Monitoring (giai đoạn vận hành bình thường), Problem Identifying (khi có vấn đề). Đi từ trên xuống dưới là trình tự thực hiện của từng giai đoạn. Nhưng như vậy không có nghĩa là phải thực hiện lần lượt từ trên xuống đâu nhé. Mình thường kết hợp 1 vài phương pháp và thực hiện song song để ra kết quả nhanh nhất.
Software Designing
1. Static analysis
Trong giai đoạn đầu khi phát triển, mình sẽ cần developer cung cấp những thứ sau để tiến hành đánh giá:
- Sơ đồ thiết kế các component: Cách các component của hệ thống hoạt động và kết hợp với nhau. Ví dụ là connect tới database nào, cache nào, bên thứ ba nào,... Sơ đồ này càng chi tiết thì càng dễ nhìn ra vấn đề. Đây là ví dụ 1 sơ đồ cơ bản và sơ lược:
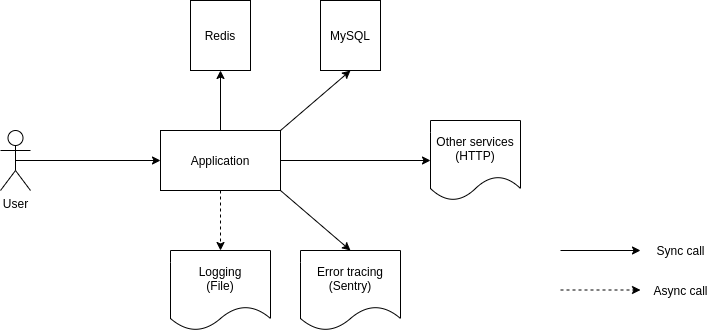
Trong hình các bạn có thể hình dung sơ bộ được application sẽ có những thành phần nào, và mình sẽ cần theo dõi những cái gì. Chỗ này đừng bỏ qua những thành phần kiểu logging, monitoring hay error tracing nhé. Trông thì đơn giản vậy thôi nhưng nó giúp các bạn thấy những vấn đề mà các bạn không hề ngờ tới, ví dụ vụ Error tracing (sentry) được gọi theo kiểu sync request, dẫn tới kéo chết cả service khi có vấn đề chẳng hạn. Bọn mình đã từng gặp qua case này rồi.
- Thiết kế database và 1 số query cơ bản: Database thường là bottleneck hay gặp của 1 hệ thống, do đó việc đánh giá lại thiết kế database trở nên rất quan trọng. Tất nhiên nếu các bạn có DBA để thiết kế thì tốt rồi, vì họ là những chuyên gia database, tuy nhiên sự thật thì đâu có được như vậy. Phần lớn các team làm product mình đã từng join cả ở công ty lớn hay nhỏ thì đều có phần database do dev tự thiết kế, nên chất lượng thường không được đảm bảo. Việc dev cung cấp thiết kế db (bao gồm cả index, trigger,...) và các loại query mà ứng dụng đang dùng sẽ giúp bọn mình nhận ra những vấn đề phổ biến và tránh chủ quan để nó ảnh hưởng tới sản phẩm.
Một số phân tích có thể đưa ra ngay được từ thiết kế DB: Chia bảng không hợp lý, Join quá nhiều, Thừa thiếu index,...
- API document: List endpoint và chức năng của chúng. Cái này là đánh giá lướt qua, bọn mình sẽ xem xét 1 số API với chức năng đặc biệt hoặc có tiềm ẩn nguy cơ cao và thường bỏ qua các tác vụ CRUD cơ bản. Mục đích của đánh giá này là tìm ra điểm code phức tạp nhất, chưa xét tới tải hay data volume gì. Nếu cần thì sẽ xem xét sâu hơn ở các xử lý trong source code. Tất nhiên điều này khá khó với các bạn Sys Admin thông thường vì những cái này đều động vô code, do đó thường việc này sẽ do Tech Lead hoặc Solution Architect đảm nhiệm.
2. Capacity planning
Kết hợp cùng phân tích tĩnh sẽ là việc lên plan tài nguyên để triển khai và chịu tải. Nói thì nói vậy chứ đây là 1 chủ đề rất khó. Tại sao lại khó bởi vì nó phụ thuộc vào rất nhiều yếu tố và thường những người có kinh nghiệm mới kết hợp được những yếu tố đó để đưa ra những con số hợp lý. Còn nếu bạn chưa hề có kinh nghiệm gì về vấn đề này, mọi con số bạn đưa ra (kể cả là có tính toán hay ước lượng) thì đều là phỏng đoán. Mình cũng chỉ dám đưa cho các bạn 1 số gợi ý ban đầu để các bạn thực hiện.
Tài nguyên thường được đưa vào bước planning này thường là các tài nguyên về lưu trữ (disk capacity, disk IOPS, memory, record,...) và network bandwidth (thường thì với phần mềm cỡ nhỏ và trung thì bandwidth chưa phải vấn đề to lắm). CPU là cái khó planning do không có 1 cách tính cụ thể nào mà chủ yếu dựa vào thực nghiệm để kết luận.
Ở đây mình sẽ ví dụ về planning cho số lượng record và memory vì thông thường 2 cái này sẽ có nhiều ý nghĩa đối với performance:
Database transaction mỗi ngày sinh ra ~1 triệu record, 30 ngày sẽ có 30 triệu. Mỗi record nếu nặng 200 bytes (tính từ tổng dung lượng các field) và index cho record đó khoảng 20 bytes thì data trong 30 ngày sẽ là:
Data size:
30.000.000 x 200 = 6.000.000.000 bytes = 6 GB
Index size:
30.000.000 x 20 = 600.000.00 bytes = 600 MB
Nếu database được chia ra các phân vùng active (gần đây được access nhiều) và các phân vùng ít active riêng biệt, trong đó thời gian active của 1 phân vùng là 3 tháng, vậy thì dung lượng index active (thường xuyên truy cập) sẽ là:
600 MB x 3 = 1.8 GB
Với 1 database thì thường sẽ có giới hạn vùng memory (RAM) được dùng làm cache hoặc chứa index cỡ 50-75% (cái này tuỳ DB nhé), do đó dung lượng RAM của database tối thiểu sẽ phải gấp đôi dung lượng index của các phân vùng active (để có thể giữ được những index này trong RAM). Trong ví dụ này là tối thiểu 4 GB. Đây là con số tối thiểu, còn bạn sẽ phải tăng dung lượng RAM thêm để nó có dư chỗ cho các index cho phân vùng ít active, cache data, tính toán,... nữa.
Có ước lượng này các bạn có thể đánh giá được hệ thống có vấn đề performance thì có phải do mình chưa cung cấp đủ tài nguyên có nó hay không.
Lưu ý: Đây chỉ là ước lượng tối thiểu và dựa trên hệ thống giả định và kinh nghiệm của mình.
3. Benchmarking / Profiling
Đây là phần mà có thể dev tự làm hoặc bọn mình sẽ làm trước khi release để có 1 cái đánh giá thực tế về performance của application trước những tình huống giả định về traffic. Thực tế là việc tự benchmarking và profiling cũng không nhất thiết phải quá đao to búa lớn case nọ case kia làm gì (đủ case thì bạn có đủ info hơn thôi). Mình nên nhìn vào thực tế là đây vẫn là kỹ năng khó với đa số mọi người, nên sự kỳ vọng dành cho nó cũng nên ít đi.
Mọi người hãy list ra 1 số case test benchmark và profile cơ bản thôi và test được là cũng là tốt lắm rồi. Thông thường mình thường benchmark API với 1 số tool simple như Apache Bench, wrk, h2load,... Nếu các bạn muốn thử tool phức tạp thì có thể thử jMeter. Trong đó có 1 vài case test sương sương là kiểm tra throughput, latency và error rate khi tăng dần lượng concurrent request:
- Concurrent = 1 và test liên tục để kiểm tra các chỉ số base như throughput, latency cơ bản bao nhiêu, tài nguyên lên như nào, có bị leak gì không,...
- Concurrent tăng dần để kiểm tra các chỉ số trên thay đổi như thế nào.
Các bạn cần lưu ý với mỗi kết quả nên thực hiện ít nhất 3 lần để nó có tính chất tái hiện được chứ đừng thử 1 lần rồi kết luận luôn nhé. Benchmarking thường đưa cho mình 1 kết luận sương sương về yếu tố có thể là bottleneck, ví dụ là thấy disk iops tăng cao chẳng hạn, mình sẽ biết disk có thể là 1 cái bottleneck.
Đây là 1 cái template để xây dựng kết quả test với application trên kubernetes mình thu lượm được từ bài blog này: https://docs.google.com/spreadsheets/d/1rXN471mG4PuCi0vcuvEEUQOXTUlCN9e66z2oMfMGlnM/edit#gid=0. Mọi người có thể tham khảo cái idea xem bên trong người ta log những gì.
Profiling thì thường được dùng khi muốn đào sâu hơn vào code, như kiểm tra lượng CPU, RAM mà từng object hay function sử dụng. Cái này thường được mình dùng SAU KHI có kết quả benchmark để tìm hiểu các nguyên nhân về latency cũng như resource usage của từng trường hợp. Thông thường quá trình profiling mới là quá trình giúp bạn xác định bottleneck của ứng dụng.
Thông thường kịch bản profiling sẽ là:
- Chuẩn bị tool đo lường: memory profiler, cpu profiler, time log (log time thực hiện từng function),...
- Chạy benchmark với 1 kịch bản xác định nhiều lần: tái hiện đủ số lần để đo lường nhưng được giữ nguyên kịch bản workload để tránh các thành phần thay đổi làm ảnh hưởng kết quả.
- Phân tích kết quả: từ công cụ trên xác định function nào chiếm thời gian nhiều nhất, object nào chiếm nhiều RAM nhất, action gì chiếm nhiều CPU nhất,... Đây là các điểm bottleneck cần tối ưu nếu giá trị impact lớn.
Bản chất của benchmarking là sự so sánh, tức là phải có nhiều workload, nhiều kết quả để so sánh với nhau và kết luận. Còn bản chất của profiling là sự thấu hiểu, tức là phân tích từng kết quả nhiều lần để hiểu bên trong code các thành phần đóng vai trò như nào.
4. Random change
Bước này được sử dụng khi bọn mình phải deploy 1 service mới, hoặc 1 application nào đó mới của bên thứ 3 như DB, webserver,... Lúc này bọn mình sẽ thay đổi các param theo hướng tăng, giảm rồi chạy benchmark để xem các param đó ảnh hưởng tới performance như thế nào.
Ví dụ thay đổi các thông số của webserver nginx, php-fpm,... kiểm tra với cùng lượng workload thì thông số nào là tối ưu.
Normal Monitoring
1. Streetlight
Phương pháp này có ý nghĩa là tìm chỗ nào nhiều thông tin nhất (đoạn đường có đèn sáng nhất) để soi. Ví dụ mình có hệ thống monitor CPU, RAM của ứng dụng. Việc mình thi thoảng vào liếc dashboard xem application của mình sử dụng tài nguyên ra sao, app nào chiếm nhiều tài nguyên nhất,... giúp mình phát hiện các vấn đề về performance như memory leak, peak CPU,... 1 cách ngẫu hứng. Phương pháp này phụ thuộc nhiều vào việc các bạn có monitor ứng dụng của mình được không và việc rèn luyện đôi mắt nhìn số liệu của các bạn. Cái này sẽ được mình đề cập trong bài viết sau về cách monitoring ứng dụng nhé.
1 cái rất hay gặp của phương pháp này là thi thoảng mình sẽ vào nhòm slowlog của DB. Bình thường thì nó cũng không có gì mấy, hoặc có thể nổi lên 1 vài request chậm của CMS nhưng không đáng bận tâm. Nhưng thi thoảng vào giúp mình detect ra nhiều cú query láo nháo kiểu bình thường thì không chậm lắm nhưng ngẫu nhiên nó lại chạy chung với 1 query khác và làm cả 2 thằng cùng chậm.
2. Checklist
Phương pháp này được rút ra từ kinh nghiệm vận hành của đội Sys Admin và thường được thực hiện 1 vài lần khi khởi tạo service, sau đó được check tự động trong các tool monitoring, alerting. Mình thường thấy phương pháp này được dùng để kiểm tra phần cứng (khi mà bạn phải làm đi làm lại 1 công việc) hoặc để kiểm tra loại bỏ nhanh những yếu tố đã biết gây ảnh hưởng tới performance của hệ thống (tránh việc mất thời gian debug lâu la).
Ví dụ trong checklist của bọn mình sẽ có những cái như là:
- Ping server của bên thứ 3, mục đích là để loại bỏ nguyên nhân mạng lag bất thường hoặc cảnh báo sớm.
- Slow log từ database có user là cms
- Push notification kéo user cũ từ vận hành (thay đổi về tính chất workload)
3. Baseline analysis
Phương pháp này được mình dùng hàng ngày. Nói theo kiểu nông dân là mình nhớ được application của mình bình thường sử dụng bao nhiêu tài nguyên, CPU ra sao RAM thế nào. Tự nhiên 1 ngày đẹp trời vào thấy nó bất thường mà không có yếu tố bên ngoài đã biết nào tác động thì rõ ràng là nó tiềm ẩn nguy cơ gì đó phải tìm hiểu. Mặc dù được mình sử dụng hết sức nông dân và nhạt nhẽo, thế nhưng đừng coi thường phương pháp này. Đây là thứ giúp mình kiếm ra phần lớn các vấn đề của hệ thống đó.
Thông thường mình thường xuyên nhìn qua hình đồ thị của các chỉ số liên quan tới CPU, IOPS hoặc throughput của hệ thống. Những cái này là những cái hay có thay đổi bất thường. RAM, disk capacity thường ít khi thay đổi chóng mặt như thế mà sẽ có xu hướng từ từ nên các bạn chỉ detect dc vấn đề của tụi này khi so sánh trong 1 khoảng thời gian dài.
Nhiều anh em bảo phần phân tích lịch sử này nói thì dễ nhưng làm thì không biết nhìn như nào, hoặc cứ muốn lần đầu nhìn rồi biết luôn nó có bình thường không. Mình cũng nói luôn là đã gọi là lịch sử thì bạn phải tích luỹ từ kinh nghiệm, trăm hay không bằng tay quen thôi. Thế nên trong bài viết sau mình sẽ nói về monitoring ứng dụng để các bạn bắt đầu tập xem dần. Các bạn chỉ cần làm 1 việc lặp đi lặp lại là ngày nào cũng vào ngắm nó. Tới lúc đó sẽ tự giác ngộ ra cái pattern của nó để mà biết khi nào thì là abnormal.
Problem Identifying
1. Problem Statement
Bộ câu hỏi khoanh vùng vấn đề. Công việc hàng ngày của bọn mình (DevOps) là đi tìm diệt code cỏ và làm điều tra viên khi dev báo hệ thống có vấn đề. Chỗ này mình sẽ thực hiện giống cảnh sát đi điều tra 1 vụ giết người và hỏi nhân chứng ấy. Ví dụ 1 hôm có dev báo với mình API trong màn hình A bị chậm. Đây là những câu hỏi mà mình sẽ đưa ra để mọi người cùng trả lời:
- API đó đã từng chạy ngon chưa?
- Điều gì đã thay đổi gần đây? Code mới? Phần cứng mới? User tăng?
- Vấn đề đó thể hiện ở khía cạnh nào? Queue đầy? Latency tăng? Tỷ lệ lỗi cao?
- Vấn đề đó có thể tái hiện được với những user khác không?
Sau khi có được các thông tin trên, bọn mình sẽ dễ dàng khoanh vùng xem vấn đề để tìm thủ phạm.
2. Workload Analysis
Trong bước này, mình dựa vào việc tái hiện vấn đề hoặc nếu không tái hiện được thì phải có thông tin từ log để phân tích đặc tính của workload:
- Concurrency khi xảy ra vấn đề là bao nhiêu?
- Tổng workload khi xảy ra vấn đề là bao nhiêu?
- 1 user hay nhiều user?
- 1 user sẽ bị 1 lần hay nhiều lần?
Ví dụ:
- Khi có 1 API read từ DB được báo có latency rất cao, bọn mình đã thử tái hiện bằng benchmark nhiều lần nhưng đều chưa tái hiện thành công.
- Khi đó mình phải phân tích phần API bị chậm từ log và phát hiện ra pattern của phần chậm là: mỗi user sẽ bị chậm 1 lần khi mới gọi lần đầu. Mặc dù mỗi user chỉ bị 1 lần nhưng với nhiều user thì thành ra tổng số request bị chậm nhiều lên làm bọn mình ban đầu hiểu nhầm cái workload này.
- Từ pattern của workload và hiểu biết về DB (mongodb) bọn mình liên kết được việc mongodb dù có index nhưng vẫn mất thời gian để chuyển data từ disk lên working set trong RAM, từ đó tìm ra hướng giải quyết.
3. Utilization Analysis
Phân tích tài nguyên hệ thống khi xảy ra vấn đề và so sánh với những số liệu có từ benchmark xem có tài nguyên nào đạt ngưỡng tới hạn chưa.
- CPU hay RAM có cao không, bao nhiêu phần trăm?
- Có xuất hiện tài nguyên cao bất thường khi xảy ra vấn đề không?
- Tài nguyên đã đạt điểm tới hạn (kiểm tra từ benchmark) chưa?
Ví dụ: Khi bọn mình nhận được báo cáo request bị chậm và tái hiện thành công bằng benchmark, kết hợp với monitor hệ thống phát hiện các tài nguyên đều bình thường, chỉ có node redis có mức CPU utilization là 50%, nhưng đã đạt điểm tới hạn (vì redis chỉ chạy có 1 CPU) và bắt đầu làm chậm request.
Điểm tới hạn (Saturation) là thời điểm tải cao nhất tài nguyên đã được sử dụng tới hạn và bắt đầu gây lỗi, request tới phải xếp hàng hoặc bị từ chối.
4. Latency Analysis
Đôi khi phân tích utilization không đem lại kết quả bởi mọi resource đều hoạt động dưới ngưỡng. Nhưng API vẫn chậm thì phải làm sao? Khi ấy phân tích latency được bọn mình sử dụng khi không thể tìm ra ngay bottleneck từ việc theo dõi utilization. Bước này gần như là debug, có thể thực hiện cả trong quá trình profiling. Nhưng ở đây là thực hiện để tập trung vào vấn đề chứ không phải là chỉ phân tích chung chung.
Phân tích latency tức là bạn bóc tách latency của 1 quá trình thành các quá trình con và xem thời gian từng quá trình.
Vấn đề: API response 1.5s. Phân tích latency phát hiện ra: latency không phải do query DB slow, mà là do gọi tới sentry để log lỗi lâu.
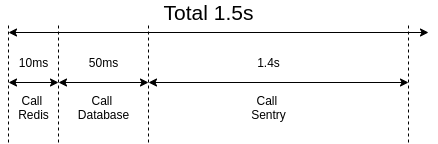
Latency là phương pháp thượng thừa để truy tìm bottleneck hệ thống, tuy nhiên có đặc điểm là khá khó setup và theo dõi trên production. Do đó thường chỉ được mình dùng khi có 1 vấn đề cụ thể, hoặc trong các kịch bản profile cụ thể.
Nên nhớ chính việc bạn theo dõi latency từng bước trong code cũng tốn thời gian và performance
5. Theory Analysis
Đây là bí thuật kinh khủng nhất của việc phân tích performance. Làm đúng sẽ giúp các bạn tiết kiệm rất rất nhiều thời gian và công sức. Làm sai sẽ khiến các bạn mất niềm tin vào cuộc sống và sự tự tin của bản thân =)))

Cụ thể là đứng trước các vấn đề về performance mà chưa biết nguyên nhân thì mình sẽ dùng trí tưởng tượng và khả năng phân tích tĩnh để đưa ra 1 giả thuyết về nguyên nhân gây ra vấn đề performance.
Các bạn sẽ thấy tất cả các phương pháp phía trên đều bao gồm rất nhiều bài test phải làm, nhiều resource phải kiểm tra khiến cho quá trình xác định vấn đề của các bạn kéo dài rất lâu và điều này không phù hợp với các sự cố cần phản ứng nhanh. Còn phương pháp này sẽ nhanh chóng đưa ra 1 giả thuyết và kiểm tra nó. Tức là trực tiếp chọn 1 resource để kiểm tra chứ không phải là đi qua hết các resource.
Nghe thì rất đơn giản nhưng trong thực tế thực hiện nó không hề đơn giản tí nào và thường nó còn là con dao 2 lưỡi làm bạn mất nhiều thời gian xử lý hơn nếu đi sai cơ. Người đưa ra giả thuyết này thường phải là người nắm rất chắc hệ thống, cách xử lý luồng,... cũng như kinh nghiệm tìm ra bottleneck. Ngoài ra thì trí tưởng tượng phong phú sẽ giúp bạn rất rất nhiều trong việc xử lý các vấn đề chưa gặp bao giờ (mà thường là vậy). Chỗ này không nói chơi nhé. Trí tưởng tượng thật đó.
Phương pháp này mình để xuống cuối cùng, để các bạn nếu có dùng thì hãy thận trọng. Bản thân mình cũng khá may mắn là dùng phương pháp này thường xuyên nhưng tỷ lệ trúng bottleneck cao nên vẫn được anh em tin tưởng giao phó việc tìm phương án phản ứng khi có vấn đề.
1 số ví dụ:
- Khi mình thấy 1 API bị chậm mà API đó có sử dụng DB để read, mình đưa ra giả thuyết query vào DB chưa được tối ưu. Sau đó mình sẽ tiến hành test thử, explain query, soi slow log xem có đúng là query vào DB chậm hay không.
- Khi mình thấy tỷ lệ cache hit/miss có chiều hướng thấp hơn quá khứ, mình đưa ra giả thuyết về workload thay đổi và bắt đầu kiểm tra đặc tính workload. Và đúng là như vậy, có 1 service bắt đầu gọi lại những data ở quá khứ (do đó không được cache)
- Khi mình thấy các background job có p99 latency (99% latency thấp hơn con số p99) cao nhưng p90 vẫn thấp và mọi thứ đều bình thường, mình đưa ra giả thuyết có job chứa HTTP request tới bên ngoài bị chậm và kiểm tra số ít job chứa HTTP request. Tại sao mình lại không kiểm tra DB, bởi vì nếu DB có vấn đề thì mình sẽ thấy mức độ impact cao hơn là chỉ có 1% số job.
Như bạn thấy, việc đưa ra 1 theory đúng rất quan trọng, nó có thể giúp bạn nói trúng phóc bottleneck của hệ thống, mà... cũng có thể không. Phương pháp này có thể làm tiền đề cho các phương pháp khác, hoặc dùng như chiêu cuối sau khi các phương pháp khác đã thất bại.
Tới Rome rồi thì làm gì?
Sau khi bạn có vấn đề (hoặc 1 list vấn đề trong tay), công việc tiếp theo lại là 1 ít công việc giấy tờ thôi. Đó là ngồi tính xem: nếu mình fix cái này, hệ thống được gì?
Thang xếp hạng thông thường được dựa trên thời gian (latency), khả năng serve request (throughput, concurrency) và tỷ lệ lỗi (error rate). Cái nào đáng làm thì mới làm, đừng làm cái không đáng hoặc chưa quan trọng quá.

Ví dụ:
Request ban đầu có latency 500ms.
- Tối ưu DB giúp giảm 300ms
- Sử dụng caching giúp giảm thêm 100ms
- Sử dụng redis pipeline giúp giảm thêm 20ms
- Bỏ logging giúp giảm 5ms
- Optimize thêm đoạn code loop giúp giảm 5ms
Okay, làm tất cả mấy cái trên thì đúng là nhanh rồi, nhưng sao có thời gian mà làm hết? Chưa kể vấn đề data sai lệch, phức tạp trong xử lý, không có log thì không trace được,...
Do vậy ta sẽ làm lần lượt từ trên xuống tới khi nào Chấp nhận được. Ví dụ tối ưu xong query giúp giảm 300ms rồi, có thể không cần cache nữa nếu cần data phải chuẩn. Còn nếu muốn nhanh thêm thì cứ tối ưu tiếp nữa.
1 ví dụ khác:
Request ban đầu có throughput 2k rps
- Cache tập trung với Redis thì throughput = 10k rps với 1GB RAM, hit/miss = 95%
- Cache phân tán bằng Memory thì throughput = 16k rps
- 5GB RAM, hit/miss = 80%
- 10GB RAM, hit/miss = 90%
Các bạn đã thấy rõ hơn chi phí tối ưu performance rồi chứ? Với 1 số hệ thống mình đã chọn cách tối ưu số 1 nếu workload nhỏ và latency chấp nhận được. 1 số sẽ chọn cách số 2 là mức chấp nhận được nếu data không cần tỷ lệ hit cao. 1 số hệ thống đã chọn cách số 3 để tăng throughput nhưng sẽ phải trả giá bằng chi phí hạ tầng.
Tổng kết
Bottleneck là 1 kẻ thù khó nắm bắt với muôn hình vạn trạng. Nhưng có phương pháp đúng đắn và cách tiếp cận hiệu quả, kinh tế sẽ giúp các bạn chinh phục được kẻ thù này. Vấn đề là sớm hay muộn thôi. Tiện đây mình sẽ tóm tắt lại các phương pháp trong bài viết này cho các bạn bằng sơ đồ sau. Đừng ngại nếu nhìn nó quá kinh nhé, tập dần rồi bạn sẽ quen thôi.
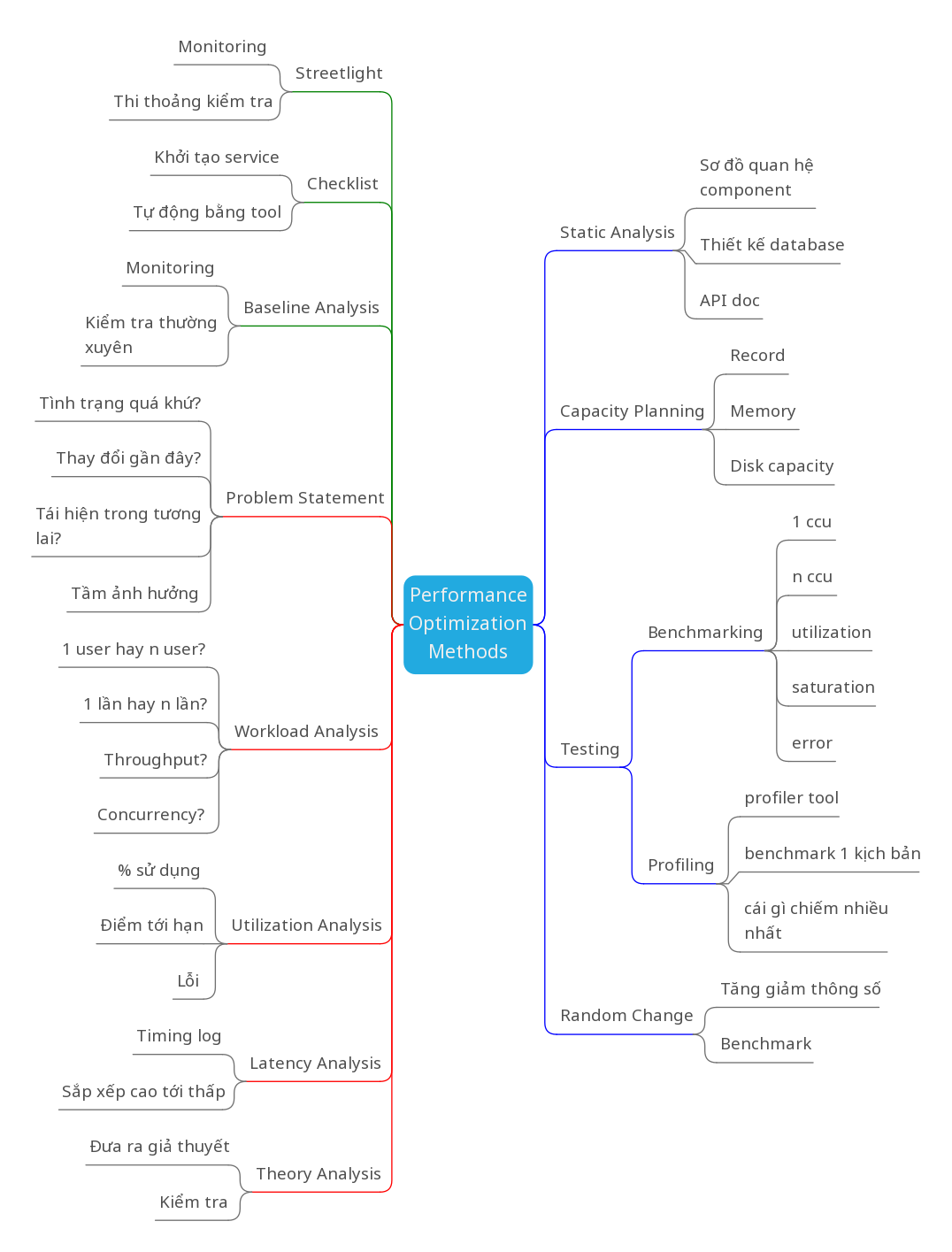
Hẹn gặp lại các bạn ở bài viết thứ 4: Trinh sát ứng dụng với monitoring / profiling. Đừng quên upvote và clip lại bài viết này để xem dần nhé.
All rights reserved
