Caching đại pháp 2: Cache thế nào cho hợp lý?
Bài đăng này đã không được cập nhật trong 5 năm
Caching rất dễ
Mình không nói đùa đâu, caching rất là dễ. Ai cũng có thể làm được chỉ sau 10 phút đọc tutorial. Nó cũng giống như việc đứa trẻ lên 3 đã có thể cầm bút để vẽ vậy. Thế nhưng biết cầm bút vẽ khác với việc vẽ được cái gì đó, và lại càng khác hơn việc vẽ được cái gì đó đẹp. Nghệ thuật caching cũng vậy.

Nếu bạn đã từng nghe đến câu nói nổi tiếng này:
There are only two hard things in Computer Science: cache invalidation and naming things. - Phil Karlton
Thì nếu là người chưa từng sử dụng cache các bạn sẽ tự hỏi: cache invalidation là cái gì mà nó khó tới vậy?
Tất nhiên, cache invalidation các bạn đừng nên hiểu chỉ ở vấn đề invalidate cache, mà hãy hiểu rộng hơn ra đến vấn đề sử dụng cache nói chung.
Trong bài viết này mình sẽ đề cập đến một câu hỏi mà đến tận bây giờ vẫn không có lời giải chính xác, cũng không có những định lý mệnh đề được đúc kết thành sách vở mà chỉ có kinh nghiệm được truyền miệng từ những bậc tiền nhân. Đó chính là câu hỏi: Cache thế nào cho hợp lý?.
First things first
Đầu tiên là 1 chút chia sẻ về câu chuyện đưa mình tới bài viết này. Việc đầy nhan nhản tutorial trên mạng về caching khiến cho mình có 1 nhận định sai lầm là viết về caching cũng dễ như tìm thấy tutorial về nó. Nhưng KHÔNG, viết về caching rất khó. Mình phải thừa nhận vậy khi đặt bút viết series Caching đại pháp này. Nó tiêu tốn của mình rất rất nhiều thời gian, gõ ra rồi lại xóa đi, xóa đi rồi lại gõ lại,...
Mình viết ra xong, cảm thấy có gì đó chưa đúng lắm, lại xóa đi, rồi lại tìm hiểu thêm sách vở, rồi lại viết tiếp, xong lại xóa đi, rồi đi tham vấn các đàn anh đi trước, viết tiếp, xong lại xóa đi... Quá trình này cứ lặp đi lặp lại vài ngày. Có lúc mình phải xóa đi hoàn toàn để viết lại theo 1 cách tiếp cận khác mà mình thấy là dễ tiếp thu hơn. Cái mà các bạn đang đọc đây có thể là phiên bản thứ 7 hay 8 gì đó. Hy vọng là kể cả nó chưa hoàn thiện thì cũng giúp ích được các bạn điều gì đó về chủ đề này.
À quên, mình là Minh Monmen, developer kiêm devops với sở thích to lớn về solution architect và security. (đam mê thôi chứ mình mới tìm được lỗ hổng 2 trang nạp thẻ khá lớn xong, như người ta mà hack dữ liệu đi bán chắc cũng chục ngàn đô là ít rồi, đây chỉ được lời cảm ơn suông nên chán đời lắm).
Trở lại với bài viết, thì đây là bài viết thứ 2 của series Caching đại pháp:
- Caching đại pháp 1: Nấc thang lên level của developer
- Caching đại pháp 2: Cache thế nào cho hợp lý <~ YOU ARE HERE
- Caching đại pháp 3: Vấn đề và cách giải quyết
Bài viết lần trước mình đã giới thiệu cho các bạn con đường mà mình đã trải qua có những loại cache gì rồi, cũng nói rõ rằng tại đâu thì quyền control của các bạn sẽ là lớn nhất rồi. Trong bài viết này mình sẽ đi sâu hơn vào phần mà các bạn có khả năng kiểm soát tốt nhất, chính là cache ở lớp backend application. 3 câu hỏi chính mà bạn sẽ tìm cách trả lời từ bài viết này là:
- Có cần cache data này không?
- Nếu có, thì cache ở đâu?
- Và cache bao lâu?
Rõ ràng chưa nào? Bắt đầu thôi.
Đoạn code quen thuộc
Trước hết, các bạn hãy cùng xem 1 đoạn code rất quen thuộc với mọi ngôn ngữ (ví dụ được implement bằng PHP với cú pháp của framework laravel):
function getArticles() {
// Check if cache has data
if ( Cache::has('articles') ) {
$articles = Cache::get('articles');
} else {
// Populate articles data from database
$articles = Articles::all();
// Put articles data to cache and set TTL to 60s
Cache::put('articles', $articles, 60);
}
return $articles;
}
Đây là đoạn code mà mình nghĩ ai cũng đã biết cách dùng. Nó cũng đã thể hiện được chiến lược cache thường gặp nhất - cache aside. Cụ thể về flow sẽ như sau:
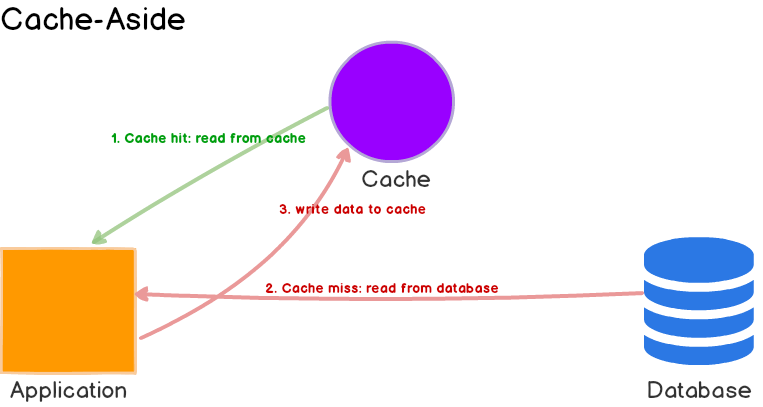
Đây là chiến lược phù hợp với nhiều nhu cầu, đặc biệt là các ứng dụng có lượng đọc > ghi. Trong bài viết này thì mình cũng không nói thêm mấy cái chiến lược khác làm gì cho rối rắm. Các bạn có thể dễ dàng tìm thấy usecase, ưu điểm, nhược điểm,... của chiến lược này đầy rẫy trên mạng cũng được.
Đoạn code này được sử dụng rộng rãi trong các document của các thư viện, framework, ngôn ngữ,... khác nhau. Và như thường lệ, kể cả với các bạn developer mới bước chân vào nghề và làm quen với cache thì clone đoạn code này về ứng dụng của mình lại quá đơn giản đi.
Mình thời mới đi làm cũng thường dùng 1 đoạn snippet cache tương tự thế này để cứ thấy chỗ nào có query DB là nhét vô. Tất nhiên là nó cũng làm tăng tốc độ ứng dụng của mình lên trông thấy. Giết nhầm còn hơn bỏ sót mà. Nhưng lúc đó ứng dụng của mình quá nhỏ và quá ít người dùng để mà nói tới việc cache đúng hay sai, hiệu quả hay không hiệu quả. Và mình nghĩ là nhiều bạn ở đây có khi cũng đang như vậy. Hệ thống có cache là auto ngon rồi nghĩ nhiều làm chi.
Qua giai đoạn chiếc chiếu mới 1 thời gian, mình dần dần thấy việc mình sử dụng cache vô tội vạ như trên làm ứng dụng của mình sai data tè le, chỗ chậm thì vẫn chậm, chỗ nhanh thì kiểu phải có điều kiện lắt léo mới nhanh được, rồi full disk, hết ram,... Mình bắt đầu mới suy ngẫm lại 1 cách kỹ càng về việc khi nào thì cache, cache cái gì, ở đâu và cache như thế nào.
Thật ngạc nhiên là việc tìm tài liệu cho vấn đề này lại rất mơ hồ. Hay là người ta thấy vấn đề nó đơn giản quá rồi không cần nói nữa không biết. Có mấy quyển sách trên O'Reilly có nói về caching, nhưng chủ yếu là caching HTTP request qua HTTP header. Tức là người ta cũng chỉ hướng dẫn cách làm về mặt kỹ thuật, chứ còn không thấy hướng dẫn cách làm về mặt logic nào cả.
Tôi có cần cache cái này không?
Ok, vậy thì đầu tiên hãy trả lời câu hỏi: Tôi có cần cache cái này không? Xác định được mình cần cache cái gì rất quan trọng khi ứng dụng của chúng ta ngày càng phức tạp và có sự tham gia của nhiều loại dữ liệu. Liệu mình nên cache toàn bộ trang html, hay là cache data sau khi tính toán, hay là cache ngay data từ DB, hay là cache đoạn config dùng chung?
Như mình có nói sơ qua từ bài viết đầu tiên. 2 yếu tố chính để các bạn xác định cần cache cái gì chính là:
- Tốn nhiều time / resource
- Kết quả dùng lại được nhiều lần
1 yếu tố phụ phải cân nhắc đó là:
- Mức độ chấp nhận sai lệch dữ liệu: Sau khi data của bạn thỏa mãn 2 câu hỏi trên, thì liệu bạn có chấp nhận việc sai số do dùng cache hay không?
Cụ thể hơn, tốn nhiều time / resource ở đây chính là việc để tính toán ra 1 kết quả thì application của chúng ta phải tốn time, CPU usage, disk iops, network banwidth, file descriptor,... và việc cache của chúng ta sẽ giúp giảm được thời gian cũng như tài nguyên tiêu tốn cho việc tính toán lại.
Còn kết quả dùng lại được nhiều lần tức là kết quả mà chúng ta cache phải được sử dụng lại thì mới nên cache. Nếu data được cache mà không bao giờ được dùng lại, hoặc dùng lại với tỷ lệ quá thấp kiểu 50% hit ratio thì hệ thống cache của chúng ta đang làm điều vô nghĩa.
Phân tích theo chiều dọc
Trớ trêu thay 2 câu hỏi này lại có xu hướng giới tính trái ngược nhau. Hãy cùng xem lược đồ request theo chiều dọc như sau:
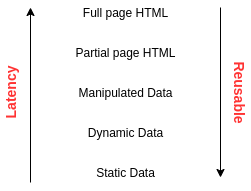
Đi từ trên xuống dưới chính là việc mình đào sâu vào 1 request, lớp ở trên chứa kết quả lớp ở dưới. Càng xuống sâu thì latency / resource càng cần ít hơn và mức độ reuse được dữ liệu cũng tăng lên. Do đó xu hướng của mình sẽ là:
- Càng cache lớp ở trên càng tốt cho hệ thống: Đây chính là việc nhanh chóng kết thúc request và trả về kết quả
- Cố gắng mang tính chất lớp dưới lên lớp trên: Chính là việc đưa dần tính chất static data / shared data lên trên.
Ví dụ, với 1 trang blog, các bạn đi theo chiều dọc sẽ được tương ứng là:
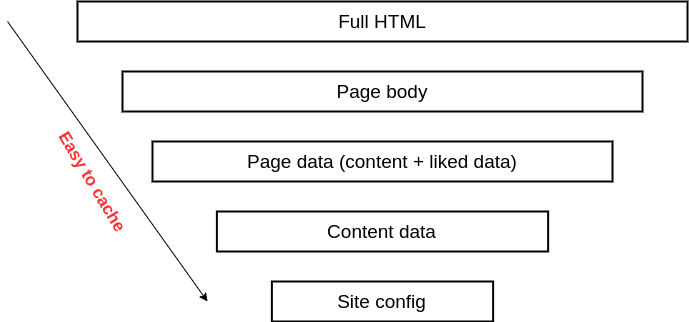
Hướng mũi tên chính là hướng chỉ khả năng cache dễ dần, nhưng cũng khiến cho giá trị cache đem lại giảm dần (vì thời gian tiết kiệm cho 1 request sẽ giảm đi). Tùy thuộc vào mức độ chấp nhận sai số trong dữ liệu và yêu cầu từ traffic mà các bạn chọn 1 tầng cache cụ thể.
- Nếu trang blog của mình lèo tèo vài mống, mình có thể chỉ cần cache ở site config hay content data thôi.
- Nếu trang blog của mình hot như MV của Sếp, mình có thể cân nhắc cache Full HTML hoặc Body page và chấp nhận có sai số trong dynamic data như liked data.
Phân tích theo chiều dọc giúp bạn chọn 1 level để cache cụ thể. Việc cache nhiều level thì cũng ok, nhưng sẽ gây trùng lặp dữ liệu và cũng không cần thiết do level ở trên đã cover được cho level thấp rồi.
Phân tích theo chiều ngang
Vẫn tiếp tục bám theo 2 câu hỏi trên, nhưng mình lại phân tích request của mình theo chiều ngang thì sao?
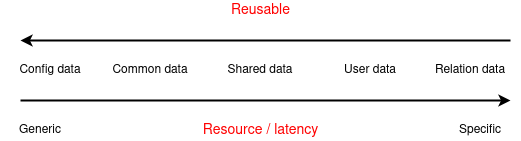
Như các bạn thấy, với 1 trang web hay 1 request mình sẽ bóc tách nó thành các thành phần ngang hàng dựa trên tính chất generic / specific, tức là dữ liệu chung hay riêng.
Ví dụ vẫn là trang blog trên, nhưng mình sẽ tách nó thành các thành phần như sau:
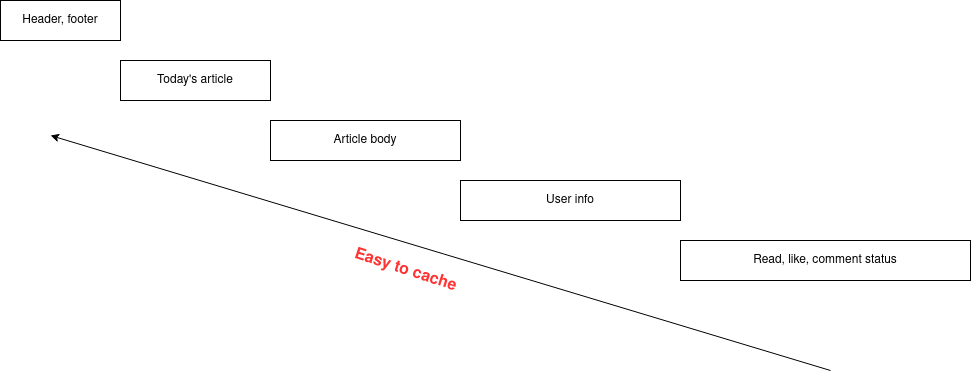
Cụ thể hơn:
- Header, footer (config cả trang)
- Top bài viết hôm nay (sidebar bên cạnh)
- Nội dung bài viết (body)
- Thông tin current user (hiển thị ở góc góc)
- Thông tin của user liên quan đến bài viết hiện tại (đã đọc, like, comment,...)
Áp những tiêu chí mình vừa nêu ở trên vào, hướng mũi tên chính là hướng chỉ khả năng cache dễ dần. Ở đây vì được tách theo chiều ngang, do đó các bạn có thể cache riêng từng phần tuỳ theo đặc điểm dữ liệu của các bạn. Ngoài ra việc tách request theo chiều ngang giúp mọi người có thể đánh giá đâu là phần chiếm nhiều tài nguyên / latency time nhất và đâu là phần được sử dụng lại nhiều nhất. Từ đó sẽ dễ xác định việc mình có cần cache cái này không:
- Nếu phần article body chiếm 100ms, nhưng được dùng chung nhiều lần ~> nên cache
- Nếu phần user info chiếm 120ms, nhưng rất ít dùng (do trang toàn guest chẳng hạn) ~> chưa cần cache
Phân tích theo chiều ngang giúp bạn tách 1 request thành nhiều thành phần có thể cache khác nhau (thường là sẽ thay đổi nơi lưu cache + thời gian TTL)
Nếu cần cache thì cache ở đâu?
Vì bài viết này chỉ đi sâu vào khu vực cache tại backend application. Do đó mình sẽ chỉ liệt kê các storage cache dành cho backend application mà mọi người hay gặp mà thôi.
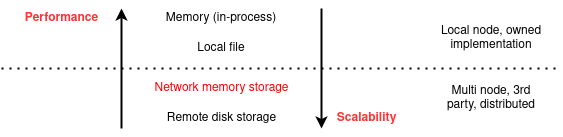
Cụ thể hơn:
Nếu lưu data trên chính server chạy code thì có 2 loại:
Memory (in-process) là lưu data luôn vào variable của process chạy ứng dụng. Kiểu lưu có thể là dạng array, hashmap,...
- Lưu trực tiếp data type mà không cần serialize.
- Insanely fast.
- Phù hợp với ứng dụng có process chung và share được memory giữa các request. Đa số ngôn ngữ chạy kiểu này như nodejs, python, java, .net,...
- Phù hợp với data có độ trễ rất thấp và tần suất truy cập lớn, dung lượng nhỏ, có giới hạn và biết trước, ứng dụng tiết kiệm tới cả CPU để tính toán. Độ trễ của data dạng này thường ở mức < 1ms
Các loại data mình hay lưu trong memory:
- Configuration (từ DB hoặc HTTP endpoint)
- Common data mà tất cả các request đều cần
- Kết quả parse user agent, thông tin token,... thường xuyên phải lấy từ request
Local file là lưu data vào file trực tiếp trên server. Lưu kiểu string hoặc binary
- Cần qua 1 bước serialize
- Fast (nhưng bị phụ thuộc nhiều vào tốc độ local disk)
- Phù hợp với ứng dụng không có process chung hoặc không share memory như ứng dụng viết bằng PHP.
- Phù hợp với ứng dụng chạy trực tiếp trên VM, bare metal.
- Phù hợp với giai đoạn sớm của việc phát triển (mới bắt đầu dùng cache) hoặc sau này có mục đích đặc biệt
- Phù hợp với data lớn hơn hoặc native với file (như html, css, js, image, video,... động)
Các loại data mình hay lưu file:
- Static asset cache
- Session data
- Full page HTML, template view,...
Việc tự lưu data trên server code như trên có ưu điểm là rất nhanh, tuy nhiên chỉ phù hợp với ứng dụng có ít instance hoặc các instance ở rất xa và ít liên hệ với nhau. Khả năng mở rộng bộ nhớ bị giới hạn trong phạm vi 1 node và hiệu quả cache (hit/miss ratio) sẽ trở thành vấn đề trong các hệ thống nhiều node.
Nếu sử dụng các giải pháp remote qua network thì cũng có 2 loại:
Remote memory storage là các giải pháp của bên thứ 3 lưu data trực tiếp trên memory như redis, memcache,...
- Cung cấp 1 số loại data cơ bản
- Fast (nhưng bị phụ thuộc vào tốc độ network)
- Phù hợp với phần lớn các kiểu ứng dụng
- Dễ dàng mở rộng mà không thất thoát quá nhiều performance, không phụ thuộc vào số lượng server code. Latency của data trên các hệ thống cache này thường trong khoảng 1 ~> 10ms
- Hiệu quả (hit/miss ratio) cao nhờ việc dùng chung cache với nhiều server code
- Phù hợp với data từng item nhỏ vì limit dung lượng RAM và việc data lớn cũng gặp bottleneck khi transfer qua network
- Phù hợp với data có TTL thấp
Đây là loại cache được sử dụng rộng rãi nhất, do nó đáp ứng được nhiều nhu cầu, tốc độ cao vừa phải và khả năng mở rộng dễ dàng. Nhưng bản chất thì dù có dùng memory để store data thì cũng vẫn mất network latency để truyền tải. Hãy nhớ điều đó và đừng nhầm lẫn.
Các loại data mình hay lưu trên remote memory storage:
- Về cơ bản là tất cả đều có thể lưu được =)))
- Trừ HTML page hoặc các data nặng
- Trừ các loại data cần super fast thì chuyển qua in-memory
Remote disk storage là các giải pháp của bên thứ 3 lưu data hybrid (memory + disk) hoặc trên disk, thường là các Key-value database như aerospike, hazencast,...
- Cung cấp nhiều tính năng và kiểu dữ liệu hơn
- Fast kiểu normal =))) Mấy thằng db này được tối ưu cho SSD các thứ, cho tốc độ nhanh hơn DB thường khá nhiều
- Dễ dàng mở rộng về dung lượng và số lượng node mà vẫn giữ performance ở mức ổn
- Phù hợp với data có mức độ mở rộng lớn và personalize nhiều do có lợi thế về lưu trữ
- Phù hợp với các ứng dụng có yêu cầu về High Availability, Resiliency, auto failover... cao
- Phù hợp với data có TTL dài
Các loại data hay lưu trên remote disk storage:
- Personalize data (recommendation, advertising, tracking, analytic,...)
Về cơ bản thì chúng ta cũng chỉ hay gặp 4 loại storage phía trên mà thôi. Thông thường nếu là 1 ứng dụng nhỏ thì việc lựa chọn cache storage nó chưa quá kinh khủng. Cứ cái gì tiện thì mọi người dùng luôn thôi. Ví dụ:
- Với ngôn ngữ thông dịch, không share memory như PHP thì lựa chọn chủ yếu là Local file và Network memory storage. Tuỳ thuộc vào việc chạy 1 instance hay multiple instance mà chọn file hoặc redis / memcached.
- Với ngôn ngữ nhẹ nhàng kiểu nodejs, python, golang thì lựa chọn chủ yếu là In memory và Network memory storage. Tuỳ thuộc vào data lưu nhỏ hay lớn. Nếu nhỏ và dùng nhiều thì có thể xài in-memory, nếu lớn và dùng không quá nhiều thì chọn redis / memcached.
- Với ngôn ngữ nặng nề kiểu java, .net thì mình thấy lựa chọn chủ yếu là In memory do tận dụng được khả năng quản lý phức tạp datatype của ngôn ngữ cũng như tốc độ của server.
Tuy nhiên khi đã qua giai đoạn nhỏ và bước đến giai đoạn traffic lớn với yêu cầu chặt chẽ hơn thì việc chọn nơi lưu cache cần được tính toán kỹ càng. Mình có 1 số kinh nghiệm ở đây như sau:
Xác định tính chất access dữ liệu: hot-cold sẽ phù hợp với local cache. even-distributed sẽ phù hợp với remote cache.
Hot-cold tức là có những item được access rất nhiều lần, có những item được access rất ít. Kiểu lưu 1 key cho configuration và 1 key cho user data chẳng hạn. Do đó nếu dùng distributed cache như redis cluster, memcached cluster thì việc sharding dữ liệu giữa các node sẽ làm cache của chúng ta phân tải không đều. Node chứa item hot được access rất nhiều, node chứa item cold chả được access mấy. Do đó sẽ phù hợp với local cache trên memory và duplicated trên các process.
Even-distributed tức là các item có lượng access đồng đều nhau. Kiểu lưu 1 key cho từng user. Kiểu này nếu dùng local cache thì tỷ lệ hit/miss sẽ bị giảm do việc phải duplicated data giữa các server. Do đó hiệu quả cache sẽ giảm xuống. Nếu sử dụng distributed remote cache như redis cluster, memcached cluster sẽ phù hợp hơn vì khả năng sharding và chia tải đều hơn.
Xác định lượng dữ liệu: Ít, xác định được trước thì local còn nhiều và không xác định trước thì remote
Xác định yêu cầu performance: Bình thường thì remote, siêu nhanh thì local (nhưng phải có cách xử lý phù hợp)
Và cache bao lâu?
Cuối cùng chính là câu hỏi khù khoằm oái oăm nhất này: Cache trong bao lâu? Đây là câu hỏi khoai nhất và cũng cần chúng ta động não nhiều nhất. Nhiều khi chọn cache ở memory hay ở redis thì kết quả đem lại cho hệ thống của các bạn chưa nhiều bằng việc set TTL cho hợp lý. Bởi vì cache bao lâu sẽ ảnh hưởng trực tiếp tới tính đúng đắn và hiệu quả cache của các bạn.
Hãy cùng xem xét lợi hại của việc set TTL dài hay ngắn:
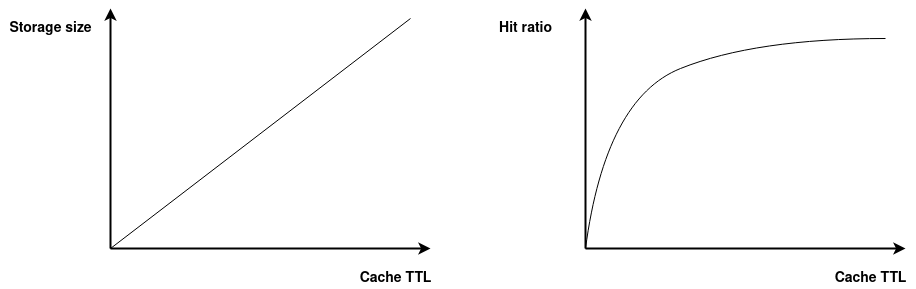
Đây là 2 đồ thị được mình mô phỏng mối quan hệ giữa việc tăng cache TTL với hiệu quả cache đo bằng hit ratio và chi phí cache là storage size.
- Khi tăng cache TTL thì storage size sẽ tăng. Hiển nhiên rồi.
- Khi tăng cache TTL thì hit ratio cũng sẽ tăng, tuy nhiên sẽ không tăng tuyến tính mà sẽ giống kiểu đồ thị đang miêu tả. Càng về sau thì việc tăng cache TTL càng không cải thiện nhiều tỷ lệ cache hit.
Ngoài ra ở đây còn có 1 vấn đề chưa nhắc tới đó chính là tính đúng đắn của dữ liệu sẽ giảm đi với thời gian cache càng dài. Cái này mình không biểu diễn được.
Lý thuyết cơ bản là vậy. Thế thực tế thì bạn sẽ cache 1 item trong bao nhiêu lâu? Phần này không có cách nào đưa luôn con số cụ thể mà bạn sẽ phải tự đi tìm sự kết hợp hoàn hảo cho hệ thống của mình. Mình chỉ gợi ý 1 số điểm sau để các bạn cân nhắc:
- Điều chỉnh cache TTL để cache hit ratio càng cao càng tốt, thông thường mình sẽ set mức cache hit ratio tối thiểu là 85%, mức hiệu quả là > 90%.
- Tăng cache TTL sẽ đi kèm cái giá về storage. Đừng cố gắng đẩy cache TTL lên với 1 cái giá storage quá đắt. Ví dụ để tăng được hit ratio từ 88% lên 90% mà phải trả bằng 3 lần memory size thì không đáng.
- Cache TTL nên được dựa trên độ fresh của dữ liệu. Tức là ta chấp nhận độ sai lệch dữ liệu trong bao lâu.
- Cache nhiều khi được dùng để throttle query vào DB. Do đó nhiều khi mình có thể chỉ cần cache 5-10s là có thể hạn chế peak query vào DB cho những dữ liệu hot rồi.
Thông thường thì cache TTL ở backend application mình sẽ set < 1 ngày. Dao động quanh khoảng 1 phút ~> 30 phút là nhiều. Trong 1 vài trường hợp mình set cache dài lên tới 6 giờ hay 1 ngày thì mình sẽ phải implement thêm các cơ chế chủ động invalidate cache khi có thay đổi nữa.
TIPs: Bạn càng control được việc invalidate cache chủ động thì càng dễ để tăng cache TTL. Mình có thể set cache TTL cho dữ liệu user trên memory được truy cập nhiều nhất hệ thống lên tới 1 ngày vì có sử dụng cơ chế invalidate chủ động khi có thay đổi data trong DB.
Chốt lại cho câu hỏi này là: không có con số nào là chính xác, cũng đừng set 1 lần rồi bỏ đó, hãy theo dõi cache hit ratio và storage size để điều chỉnh cho phù hợp.
Tổng kết
Vậy là chúng ta đã dạo qua được 3 câu hỏi chủ yếu khi sử dụng caching rồi. Đó chính là:
- Cache cái gì?
- Cache ở đâu?
- Cache bao lâu?
Hy vọng rằng qua bài viết này các bạn sẽ có 1 cái nhìn khoa học hơn với việc sử dụng hệ thống vừa dễ vừa khó là caching. Trong bài viết sau với tiêu đề: Caching đại pháp 3: Vấn đề và cách giải quyết mình sẽ đề cập tới những vấn đề khi sử dụng hệ thống caching và những chiến lược để giải quyết / giảm thiểu ảnh hưởng của nó. Các bạn hãy upvote, clip lại bài viết này cũng như cả series Caching đại pháp để có ngay thông báo khi bài viết tiếp theo ra đời nhé.
Gút bai.
All rights reserved
