Paper reading | Tạo âm thanh từ văn bản sử dụng Latent Diffusion Models
Giới thiệu
Tạo hiệu ứng âm thanh, nhạc, hoặc giọng nói theo yêu cầu là 1 ý tưởng hay cho các ứng dụng như thực tế tăng cường, thực tế ảo, phát triển trò chơi và chỉnh sửa video. Trước đây, việc tạo âm thanh thường được thực hiện thông qua các kỹ thuật xử lý tín hiệu. Thời gian gần đây, chúng ta đã có những mô hình Generative AI mạnh mẽ, giúp xử lý các task này 1 cách đơn giản hơn 
Các nghiên cứu trước đây thường chỉ tạo âm thanh dựa trên một số nhãn âm thanh cố định. Tuy nhiên, việc sử dụng ngôn ngữ tự nhiên giúp ta có thể mô tả chi tiết hơn về âm thanh, ví dụ như "tiếng chim hót nhẹ nhàng trong rừng vào buổi sáng" hoặc "tiếng sóng vỗ bờ biển vào một ngày lặng gió".
Nhiệm vụ tạo âm thanh dựa trên mô tả ngôn ngữ tự nhiên này được gọi là tạo âm thanh từ văn bản (text-to-audio, TTA). Điều này cho phép tạo ra các âm thanh phức tạp và chi tiết hơn dựa trên mô tả cụ thể từ ngôn ngữ tự nhiên.
Các hệ thống TTA được thiết kế để tạo ra nhiều loại tín hiệu âm thanh phức tạp. Để mô hình hóa dữ liệu hiệu quả, nhóm tác giả sử dụng phương pháp tương tự như DiffSound, đó là áp dụng learned discrete representation để biểu diễn các tín hiệu âm thanh cao chiều (high-dimensional). Bên cạnh đó, nhóm tác giả cũng lấy cảm hứng từ những tiến bộ gần đây trong mô hình autoregressive áp dụng learned discrete representation trên waveform, chẳng hạn như AudioGen (mạnh hơn mô hình DiffSound )
Đặc biệt, sử dụng sức mạnh của model StableDiffusion trong việc tạo ra hình ảnh chất lượng cao nhóm tác giả mở rộng phương pháp TTA sang biểu diễn liên tục (continous) thay vì rời rạc (discrete). Điều này giúp tạo ra âm thanh chất lượng cao và chính xác hơn.
Các nghiên cứu trước đây về TTA có 1 hạn chế tiềm năng về chất lượng là yêu cầu phải có các cặp dữ liệu âm thanh-văn bản chất lượng cao và quy mô lớn, vốn thường không sẵn có hoặc có chất lượng và số lượng hạn chế. Để tận dụng dữ liệu chất lượng thấp, một số phương pháp tiền xử lý văn bản đã được đề xuất. Tuy nhiên, các bước tiền xử lý này làm giảm hiệu suất tạo âm thanh do bỏ qua mối quan hệ giữa các sự kiện âm thanh.
Ngược lại, phương pháp đề xuất trong bài báo chỉ cần dữ liệu âm thanh để huấn luyện mô hình generative, hạn chế được thách thức của việc tiền xử lý văn bản và đạt hiệu suất tốt hơn so với việc sử dụng dữ liệu dạng cặp âm thanh-văn bản. Nhóm tác giả giới thiệu hệ thống TTA có tên AudioLDM, giúp tạo audio chất lượng cao sử dụng mô hình Latent Diffusion. Ngoài ra, phương pháp này cũng cho phép chỉnh sửa audio sử dụng ngôn ngữ tự nhiên luôn
Text-Conditional Audio Generation
Contrastive Language-Audio Pretraining
Các mô hình generate hình ảnh từ văn bản hiện nay đã cho ra kết quả rất ấn tượng bằng cách sử dụng phương pháp Contrastive Language-Image Pretraining (CLIP). Lấy cảm hứng từ điều này, nhóm tác giả sử dụng phương pháp Contrastive Language-Audio Pretraining (CLAP) cho bài toán TTA.
Với mẫu âm thanh là và văn bản mô tả là . Ta sẽ sử dụng 1 bộ text encoder và 1 bộ audio encoder để trích xuất embedding văn bản và embedding âm thanh , với là kích thước của embedding CLAP. Nhóm tác giả sử dụng audio encoder là HT-SAT và text encoder là RoBERTa. Nhóm tác giả cũng sử dụng loss function là symmetric cross-entropy loss.
Sau khi huấn luyện mô hình CLAP, mẫu âm thanh có thể được chuyển thành embedding trong không gian embedding liên kết giữa âm thanh và văn bản. Mô hình CLAP có khả năng tổng quát tốt thể hiện ở các task như zero-shot audio classification.
Conditional Latent Diffusion Models
Hệ thống TTA có thể tạo ra một mẫu âm thanh dựa trên văn bản mô tả . Với các mô hình LDMs, nhóm tác giả sẽ so sánh true conditional data distribution với model distribution , trong đó là compressed representation của mẫu âm thanh trong không gian mel-spectrogram , và là embedding văn bản có được từ pretrained text encoder trong CLAP.
Ở đây, biểu thị mức độ nén, biểu thị kênh của biểu diễn nén, và biểu thị các kích thước thời gian và tần số trong mel-spectrogram . Với CLAP đã được pretrained để embed đồng thời thông tin âm thanh và văn bản, audio embedding và text embedding sẽ chia sẻ một không gian mô hình chung giữa các phương thức (multi-modal). Điều này cho phép nhóm tác giả sử dụng để huấn luyện các LDM, và dùng để tạo TTA.
Nhắc lại 1 chút, Diffusion models bao gồm 2 quá trình chính:
- Forward process: Chuyển đổi phân phối dữ liệu thành phân phối Gaussian chuẩn với một noise schedule được xác định trước .
- Reverse process: Từng bước sinh lại mẫu dữ liệu từ noise theo inference noise schedule.
Trong forward process, tại mỗi bước thời gian , xác suất chuyển tiếp (transition probability) được cho bởi:
với là noise được inject vào, là reparameterization của và là tích của qua các bước. Tại bước cuối cùng , có phân phối Gaussian đẳng hướng chuẩn.
Để tối ưu hóa mô hình, nhóm tác giả sử dụng 1 objective như sau:
với là embedding của waveform được tạo từ pretrained audio encoder trong CLAP.
Trong quá trình reverse, bắt đầu từ phân phối nhiễu Gaussian và text embedding , một quá trình khử noise có điều kiện (denoising process conditioned) trên dần sinh ra audio theo quá trình sau:
Trung bình và phương sai được tham số hóa như sau:
với là nhiễu dự đoán được sinh ra. Trong giai đoạn training, bản chất mô hình sẽ học cách gen ra audio dựa trên không gian biểu diễn cross-modal của một mẫu âm thanh. Sau đó, trong quá trình TTA, ta sẽ dùng text embedding để dự đoán noise . Dựa trên embedding CLAP, mô hình LDM sẽ thực hiện việc tạo TTA mà không cần train lại trong giai đoạn gen mẫu.
Conditioning Augmentation
Trong các mô hình gen hình ảnh từ văn bản, diffusion-based models cho thấy khả năng gen được những chi tiết nhỏ, các đường nét tinh vi giữa các đối tượng và nền. 1 trong những lý do mà các mô hình diffusion thực hiện được điều này là nhờ vào các bộ dữ liệu cặp text-image lớn, chẳng hạn như bộ dữ liệu LAION với 400 triệu cặp.
Trong việc tạo tín hiệu âm thanh từ văn bản (TTA generation), mục tiêu là tạo ra các tín hiệu âm thanh tổng hợp có mối quan hệ tương ứng với các mô tả ngôn ngữ tự nhiên. Tuy nhiên, thách thức lớn ở đây là size của các bộ dữ liệu ngôn ngữ-âm thanh không lớn bằng các bộ dữ liệu ngôn ngữ-hình ảnh. Để giải quyết vấn đề này, AudioGen đã áp dụng chiến lược mixup để tăng cường dữ liệu, bằng cách mix các cặp mẫu âm thanh và ghép nối các chú thích văn bản tương ứng để tạo ra dữ liệu cặp mới. Ý tưởng khá dễ hiểu phải không
Trong bài báo, tác giả sử dụng audio embedding đóng vai trò là thông tin điều kiện khi huấn luyện các LDMs. Điều này cho phép họ áp dụng augment dữ liệu chỉ trên tín hiệu âm thanh, mà không cần augment các cặp ngôn ngữ-âm thanh. Cụ thể, việc augment mixup trên các mẫu âm thanh và được thực hiện bằng công thức:
trong đó, là hệ số tỷ lệ biến thiên trong khoảng [0, 1], được lấy mẫu từ phân phối Beta .
Phương pháp này không cần đến thông tin mô tả văn bản khi huấn luyện các LDMs, do đó đơn giản hóa quá trình huấn luyện. Bằng cách mix các cặp âm thanh, số lượng cặp dữ liệu huấn luyện cho các LDMs được tăng lên, giúp các LDMs trở nên mạnh mẽ hơn. Trong quá trình lấy mẫu, với text embedding từ các unseen text data, các LDMs sẽ tạo ra tín hiệu âm thanh tương ứng từ .
Classifier-free Guidance

Trong diffusion models, việc tạo ra kết quả có kiểm soát (controllable generation) có thể đạt được bằng cách thêm hướng dẫn tại mỗi bước sampling. Có 2 phương pháp hướng dẫn chính được sử dụng là hướng dẫn bằng bộ phân loại (classifier guidance) và hướng dẫn không dùng bộ phân loại (classifier-free guidance - CFG).
Classifier guidance sử dụng một bộ phân loại để cung cấp hướng dẫn cho diffusion models. Bên cạnh đó, phương pháp CFG là 1 cách hiệu quả khác trong việc hướng dẫn diffusion models.
Trong quá trình huấn luyện, embedding điều kiện được ngẫu nhiên loại bỏ với một xác suất cố định, ví dụ 10%, để huấn luyện cả diffusion models có điều kiện và diffusion models không điều kiện . Điều này giúp mô hình học được cách hoạt động trong cả hai trường hợp có và không có điều kiện.
Trong quá trình sampling, embedding văn bản được sử dụng làm điều kiện và thực hiện sampling với một ước lượng biến đổi . Công thức để tính ước lượng này là:
trong đó, xác định quy mô hướng dẫn (guidance scale). Việc này cho phép diffusion models sử dụng thông tin từ cả mô hình có điều kiện và không điều kiện để tạo ra kết quả cuối cùng.
So với AudioGen, có hai điểm khác biệt chính trong phương pháp tiếp cận này. Đầu tiên, AudioGen sử dụng CFG trên một mô hình auto-regressive dựa trên transformer, trong khi các LDMs (Latent Diffusion Models) duy trì công thức lý thuyết của CFG.
Thứ hai, AudioGen loại bỏ các mô tả văn bản thể hiện các mối quan hệ không/thời gian trong bước tiền xử lý văn bản. Ngược lại, trong nghiên cứu này, embedding văn bản được trích xuất từ ngôn ngữ tự nhiên chưa qua xử lý, cho phép CFG sử dụng các mô tả chi tiết làm hướng dẫn cho việc sinh mẫu.
Như vậy, phương pháp được mô tả ở đây cho thấy sự khác biệt và ưu điểm của việc sử dụng embedding văn bản chưa qua xử lý trong việc hướng dẫn diffusion models, so với phương pháp của AudioGen. Điều này cho phép mô hình tận dụng được thông tin chi tiết từ ngôn ngữ tự nhiên để tạo ra kết quả chính xác và phù hợp hơn.
Decoder
Trong phần này, chúng ta sử dụng VAE (Variational Autoencoder) để nén mel-spectrogram vào một latent space nhỏ , trong đó là mức độ nén của latent space.
VAE bao gồm một encoder và decoder với stacked convolutional modules. Trong training, ta sẽ sử dụng các loss function như sau:
- Reconstruction Loss
- Adversarial Loss
- Gaussian Constraint Loss
Trong quá trình sampling, decoder được sử dụng để tái cấu trúc mel-spectrogram từ âm thanh gốc được tạo ra từ LDMs.
Để chọn tối ưu, nhóm tác giả thử nghiệm với các giá trị thuộc tập hợp và chọn làm thiết lập mặc định do tính hiệu quả tính toán cao và chất lượng sinh mẫu.
Trong quá trình thực hiện conditioning augmentation cho LDMs, nhóm tác giả sử dụng các phương pháp data augmentation với VAE để đảm bảo chất lượng reconstruction của các mẫu tổng hợp. Nhóm tác giả cũng sử dụng HiFi-GAN để gen mẫu âm thanh từ mel-spectrogram đã được reconstruction.
Text-Guided Audio Manipulation
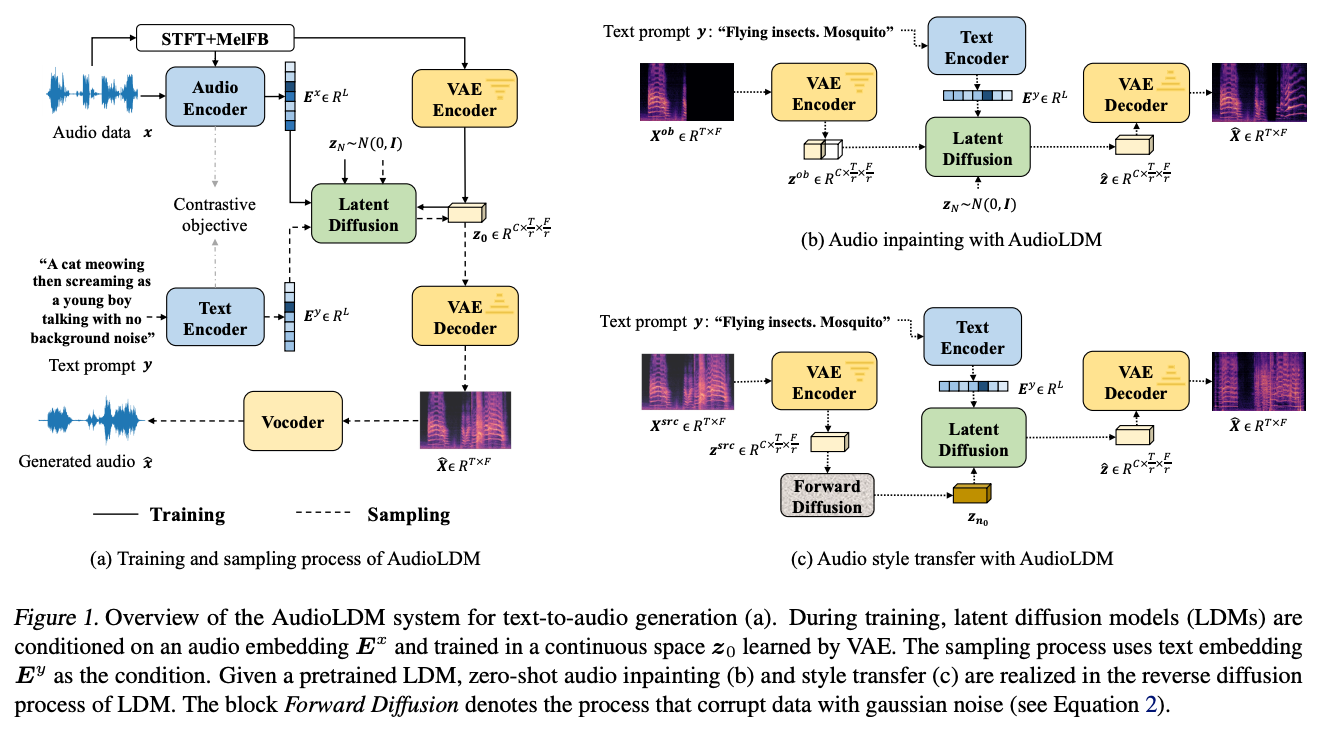
Khi có một mẫu âm thanh gốc , chúng ta có thể tính toán noisy latent representation với một thời điểm xác định trước theo forward process. Bằng cách sử dụng làm điểm khởi đầu của reverse process của mô hình pretrained AudioLDM, chúng ta có thể chỉnh sửa âm thanh với đầu vào văn bản bằng quá trình được gọi là shallow reverse process :
trong đó kiển soát kết quả chỉnh sửa. Nếu ta đặt , thông tin được cung cấp bởi âm thanh gốc sẽ không được giữ lại và kết quả sẽ tương tự như TTA generation. Hình dưới minh họa hiệu ứng của .

Audio inpainting và audio super-resolution đều là bài toán gen ra phần thiếu của tín hiệu âm thanh dựa trên phần quan sát được . Nhóm tác giả thực hiện nghiên cứu task này bằng cách tích hợp phần quan sát trong latent space vào generated latent representation .
Cụ thể, trong reverse process, bắt đầu từ , sau mỗi bước infer, ta sẽ điều chỉnh generated latent representation với công thức:
trong đó là modified latent representation, kaf observation mask trong latent space, và thu được bằng cách thêm noise vào trong forward process.
Giá trị của observation mask phụ thuộc vào phần quan sát được của mel-spectrogram . Vì sử dụng cấu trúc convolutional trong VAE để học latent representation nên ta có thể giữ lại xấp xỉ sự tương ứng không gian trong mel-spectrogram.
Do đó, nếu 1 bin time-frequency được quan sát, ta sẽ đặt observation mask trong latent space. Bằng cách sử dụng để biểu thị phần generate và phần quan sát trong , ta có thể tạo ra phần thiếu được điều kiện hóa bởi văn bản hướng dẫn với các mô hình TTA, đồng thời giữ lại được ground-truth observation .
Tài liệu tham khảo
[1] AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
All rights reserved
