
[Paper Explain] EFFICIENT MASKED FACE RECOGNITION METHOD DURING THECOVID-19 PANDEMIC
Bài đăng này đã không được cập nhật trong 4 năm
Source paper: https://arxiv.org/pdf/2105.03026.pdf
Giới thiệu
Trong thời kì địa dịch Covid-19 bùng nổ trên khắp toàn cầu, có thể nói khẩu trang là một vật dụng vô cùng thiết yếu. Với lĩnh vực Computer Vision thì một bài toán mới được sinh ra: làm thể nào để nhận diện khuôn mặt khi khuôn mặt đó đeo khẩu trang (khi mà một nửa khuôn mặt đã bị che khuất). Mình đã tìm kiếm khá nhiều tuy nhiên đây là một đề tài khá mới và cũng chưa có nhiều công bố trên các hội nghị khoa học. Hầu hết các bài báo liên quan đến Mask chủ yếu là phân loại xem có đeo khẩu trang hay không, hay có đúng cách hay không, còn về nhiệm vụ phân loại khuôn mặt thì tương đối ít (Mình tìm được có 3). Bài báo hôm nay mình muốn giới thiệu được đăng trên arXiv vào tháng 5 năm nay.
Về ý tưởng tổng quan, chúng ta có dữ liệu gồm khuôn mặt đã đeo khẩu trang và chưa đeo khẩu trang. Trong paper này dùng 2 tập dataset
- Real-world Masked Face Recognition Dataset (RMFRD)
- Simulated Masked Face Recognition Dataset (SMFRD)
Đối với dữ liệu đầu vào là đeo khẩu trang, ta sẽ loại bỏ phần khẩu trang, chỉ giữ lại phần khẩu trang không che mất (mắt, trán). Dữ liệu sau đó sẽ được đưa qua 1 pretrained model để trích xuất các đặc trưng của ảnh. Sau đó tác giả sẽ sử dụng một kĩ thuật có tên Bag-of-features (BoF) để lượng tử hóa các đặc trưng để có được một biểu diễn nhỏ, sau đó tiếp tục đi vào Fully connected layer cho bài toán phân loại.
Bây giờ chúng ta sẽ cùng tìm hiểu chi tiết hơn về các phần trong paper này nhé!
Nội dung
Theo pipeline của bài báo, có thể chia làm 4 phần chính (Do mình thấy để tiêu đề tiếng anh gốc sẽ hay hơn khi dịch ra :>>)
- Preprocessing and cropping filter
- Feature extraction layer
- Deep bag of features layer
- Fully connected layer and classification
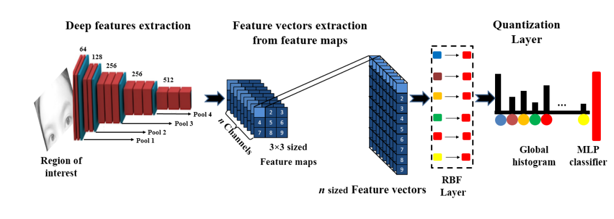
1. Preprocessing and cropping filter
Dữ liệu trong bài báo là đã được detect khuôn mặt, vì vậy bài báo này chỉ tập trung vào việc xây dựng mô hình phân loại khuôn mặt
Trước hết, tác giả đề xuất sử dụng thư viện Dlib-ml để xác định 68 vị trí trên khuôn mặt, dựa vào vị trí của mắt để có thể căn chỉnh ảnh sao cho thẳng. Đây là bước tiền xử lý tương đối quan trọng trong bài toán nhận diện khuôn mặt
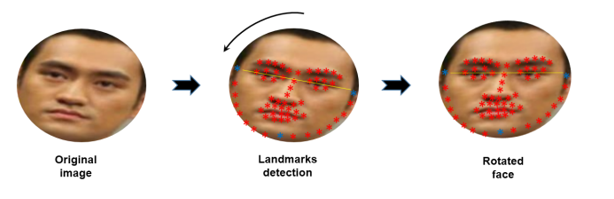
Ngoài ra, như đã đề cập, đối với các ảnh là mask (có đeo khẩu trang), ta cần xác định vùng ảnh chứa thông tin khuôn mặt không bị che (mắt, trán) để giữ lại. Đối với bài báo, phương pháp họ dùng là reshape bức ảnh về kích cỡ 240x240, sau đó chia là 100 khối vuông (tức là mỗi khối có kích cỡ 24x24). Và theo kinh nghiệm của họ thì thường đeo khẩu trang sẽ chiếm 50% và ở bên dưới bức ảnh, vì vậy họ sẽ bỏ 50 blocks bên dưới đi, chỉ giữ lại 50 blocks bên trên.
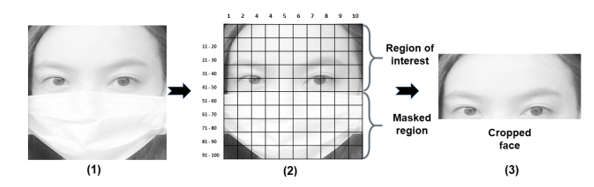
Theo đánh giá cá nhân, mình thấy cách cắt này tuy là dễ thực hiện, tuy nhiên nó chỉ tốt khi chụp trực diện, chứ mấy trường hợp nghiêng hay cúi là trông dữ liệu chán ngày. Có thể tác giả biết sẽ có những ý kiến như mình nên đã nêu ra lý do cho phương pháp của họ: hiện nay có một số phương pháp supervised learning để khôi phục vùng ảnh bị che, trong paper có đề cập tới paper này sử dụng GAN để khôi phục vùng ảnh bị che. Tuy nhiên nếu dùng phương pháp này sẽ tốn khá nhiều thời gian và tài nguyên, chưa phù hợp với bài toán thực tế.
2. Feature extraction layer
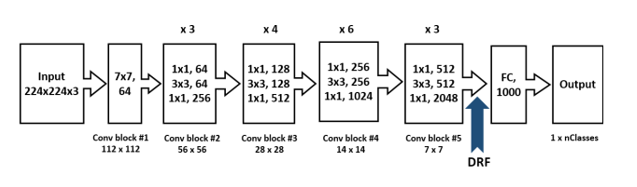
Để trích xuất thông tin từ ảnh, tác giả thử nghiệm trên 3 pretrain model CNN tiêu biểu trong các bài toán về nhận diện khuôn mặt: VGG16, AlexNet và ResNet-50. 3 pretrain model này được đào tạo với bộ dữ liệu tương đối lớn và kiến trúc mô hình tương đối khủng nên với nhiệm vụ trích xuất đặc trưng của ảnh hay được ưa chuộng. Tuy nhiên, với các pretrain model, tác giả chỉ lấy tới convolutional layer cuối cùng của mô hình (trước khi Fully connected).
- VGG-16: Mô hình được train trên tập ImageNet dataset, gồm 14 triệu ảnh và 1000 classes. Cái tên VGG-16 mang ý nghĩa nó có 16 layers. Các bạn có thể tìm hiểu sâu hơn về VGG-16 tại đây
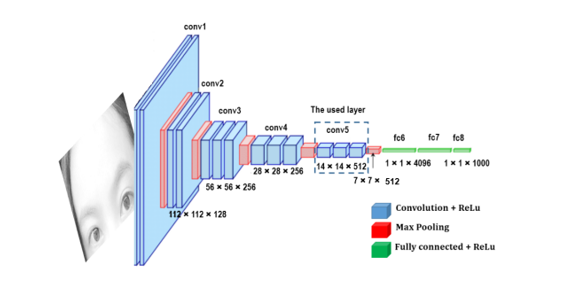
- AlexNet: Mô hình đạt kết quả tương đối cao trong các bài toán phân loại. Mô hình được train trên tập ImageNet dataset. Về mô hình AlexNet, các bạn có thể tìm hiểu kĩ hơn tại đây
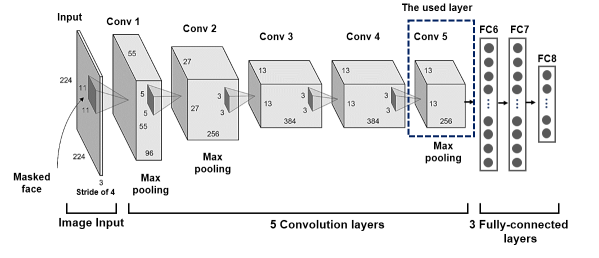
- RestNet-50: Mô hình đạt kết quả tương đối các trong các task phát hiện khuôn mặt, phát hiện người đi bộ. Mô hình chứa 50 layers cũng được train trên ImageNet dataset. Các bạn có thể tìm hiểu thêm về ResNet-50 tại đây
3. Deep bag of features layer
Thay vì điều hướng tạo ra feature vectors bằng cách sử dụng luôn Fully connected layer, BoF-based pooling layer được sử dụng giữa convolutional layer cuối cùng và Fully connected layer. Việc này có thể giúp giảm kích cỡ của Fully connected layer, đồng thời cho phép CNN sử dụng ảnh với bất cứ kích cỡ nào
BoF kết hợp với CNN còn được gọi là Convolutional BoF (CBoF), cần lưu ý cần xây dựng BoF layer sao cho có thể end-to-end training
Sau khi đi qua pretrain model, ta lấy được đặc trưng của ảnh sẽ là đầu vào cho bước lượng tử hóa (quantization) bằng cách sử dụng mô hình BoF
Về BoF, có riêng 1 paper nói khá chi tiết về nó tại đây, trong phạm vi paper này, mình sẽ nói các nội dung chính về BoF
Coi Vij là feature vector thứ j của ảnh i, và Vij thuộc RD, D là số filters được sử dụng trong convolutional layer cuối cùng. Giả sử dùng VGG-16 với size ảnh đầu vào là (224x224x3) thì output features thu được có 14x14x512 chiều 14x14=196 feature vectors, D = 512 Xét tập tất cả các feature vectors là F = {Vij, i=1..V, j=1..Vi}
Để hiểu rõ hơn về BoF, bạn đọc có thể đọc thêm về BoW (Bag-of-word) trên Wikipedia để dễ hình dung. Nhiệm vụ của BoF là chuyển đổi các feature vectors về các từ mã (codeword). Một codeword có thể được coi là đại diện của đặc trưng ảnh đó. Lưu ý rằng chiều dài của từ mã không phụ thuộc vào số lượng feature vectors, chính điều này đã giúp cho mô hình có thể với đầu vào ảnh ở bất kì size nào.
Chắc hẳn các bạn đã biết thuật toán K-means, phân cụm sử dụng các tâm được khởi tạo ngẫu nhiên. BoF lấy ý tưởng từ K-means, các feature vectors của cùng 1 ảnh thì biểu diễn trên không gian chúng nên gần nhau hơn so với các feature vectors của các ảnh khác. K-means có 2 việc chính phải làm, đó là tìm các điểm được coi là “gần gũi” với tâm cụm nào nhất và cập nhật tâm cụm sau khi đã xong công việc thứ nhất và 2 công việc này cứ lặp đi lặp lại tới khi thỏa mãn điều kiện dừng.
Đối với BoF, các RBF centers chính là các tâm cụm
Mô hình BoF bao gồm 2 layers con: RBF layer và Quantization layer.
RBF layer đo lường sự tương đồng của input features với RBF centers. RBF neuron thứ i: φ(Xj ) được định nghĩa bởi
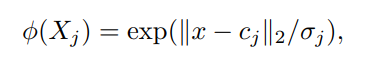
Trong đó:
- x là feature vector
- cj là trung tâm của RBF nuron thứ j
- Mỗi nơron RBF cũng được trang bị hệ số tỷ lệ σj để điều chỉnh độ rộng của hàm Gaussian của nó.
Quantization layer: đầu ra của tất cả RBF neurons được đưa vào layer này, compile ra đại diện cuối cùng của từng ảnh theo công thức
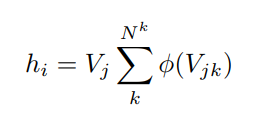
Trong đó:
- φ(x, t) = ([φ(x, t)]1, ..., [φ(x, t)]NK ) T là output vector của RBF layer
Vector thu được sau đó có thể được sử dụng cho các mục đích phân loại tiếp theo như dưới đây À mình có tham khảo được 1 đoạn code mẫu về BoF layer dưới dây, trên Tensorflow nhé. (Nguồn: https://github.com/firasl/BoCF/blob/main/BoF_layers.py)
import numpy as np
import tensorflow as tf
from keras import backend as K
from sklearn.cluster import KMeans
from sklearn.metrics.pairwise import pairwise_distances
class BoF_Pooling(tf.keras.layers.Layer):
"""
Implements the CBoF pooling
"""
def __init__(self, n_codewords=100, spatial_level=0,**kwargs):
"""
Initializes a BoF Pooling layer
:param n_codewords: the number of the codewords to be used
:param spatial_level: 0 -> no spatial pooling, 1 -> spatial pooling at level 1 (4 regions). Note that the
codebook is shared between the different spatial regions
:param kwargs:
"""
self.N_k = n_codewords
self.spatial_level = spatial_level
self.V, self.sigmas = None, None
super(BoF_Pooling, self).__init__(**kwargs)
def build(self, input_shape):
self.V = self.add_weight(name='codebook', shape=(1, 1, input_shape[3], self.N_k), initializer='uniform',
trainable=True)
self.sigmas = self.add_weight(name='sigmas', shape=(1, 1, 1, self.N_k), initializer=tf.keras.initializers.Constant(0.1),
trainable=True)
super(BoF_Pooling, self).build(input_shape)
def call(self, x):
# Calculate the pairwise distances between the codewords and the feature vectors
x_square = K.sum(x ** 2, axis=3, keepdims=True)
y_square = K.sum(self.V ** 2, axis=2, keepdims=True)
dists = x_square + y_square - 2 * K.conv2d(x, self.V, strides=(1, 1), padding='valid')
dists = K.maximum(dists,K.epsilon())
# Quantize the feature vectors
quantized_features = K.softmax(- dists / (self.sigmas ** 2))
# Compile the histogram
if self.spatial_level == 0:
histogram = K.mean(quantized_features, [1, 2])
elif self.spatial_level == 1:
shape = K.shape(quantized_features)
mid_1 = K.cast(shape[1] / 2, 'int32')
mid_2 = K.cast(shape[2] / 2, 'int32')
histogram1 = K.mean(quantized_features[:, :mid_1, :mid_2, :], [1, 2])
histogram2 = K.mean(quantized_features[:, mid_1:, :mid_2, :], [1, 2])
histogram3 = K.mean(quantized_features[:, :mid_1, mid_2:, :], [1, 2])
histogram4 = K.mean(quantized_features[:, mid_1:, mid_2:, :], [1, 2])
histogram = K.stack([histogram1, histogram2, histogram3, histogram4], 1)
histogram = K.reshape(histogram, (-1, 4 * self.N_k))
else:
# No other spatial level is currently supported (it is trivial to extend the code)
assert False
# Simple trick to avoid rescaling issues
return histogram * self.N_k
def compute_output_shape(self, input_shape):
if self.spatial_level == 0:
return (input_shape[0], self.N_k)
elif self.spatial_level == 1:
return (input_shape[0], 4 * self.N_k)
4. Fully connected layer and classification
- Tới đây, đầu ra của BoF layer sẽ là input để tác giả áp dụng Multilayer perceptron classifier (MLP) cho tác vụ phân loại với số classes chính là số identities trong dataset.
- Tác giả sử dụng 2 dataset là RMFRD và SMFRD, trong đó với RMFRD dataset, sử dụng 10-fold cross-validation
Kết quả paper
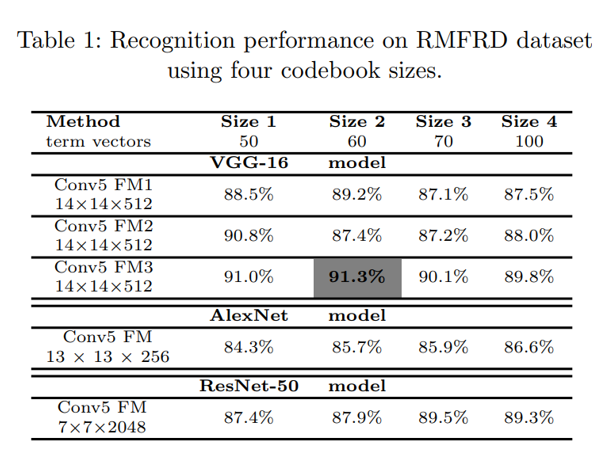
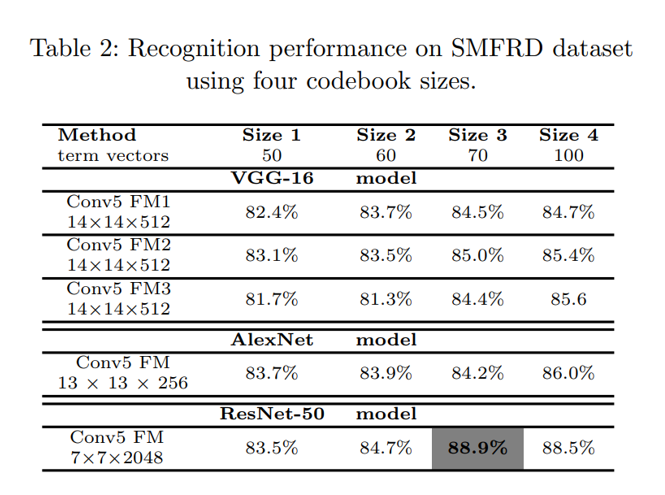
Dataset:
- Real-world Masked Face Recognition Dataset (RMFRD): 5000 ảnh mask, của 525 người, 90000 ảnh non-mask của 525 người
- Simulated Masked Face Recognition Dataset (SMFRD): 500000 ảnh mask của 10000 người lấy từ 2 tập dataset Faces in the Wild và Webface
Table 1, 2 biểu diễn khả năng phân loại trong RMFRD và SMFRD dataset sử dụng 4 size khác nhau của codebook (50, 60, 70, 100 termvectors trên mỗi ảnh), Conv5 FM1 của VGG-16 tức là ta sẽ lấy đầu ra là convolutional layer đầu tiến trong khối convolutional cuối cùng của VGG16, tương tự Conv5 FM2 và Conv FM3 là 2 layer tiếp theo trong last convolutional block
References
All rights reserved
