NOSQL DATABASE – RIAK
Bài đăng này đã không được cập nhật trong 4 năm
1. NoSQL Database
NoSQL database bao gồm rất nhiều phương pháp lưu trữ cơ sở dữ liệu, có thể đáp ứng nhu cầu tăng nhanh về khối lượng dữ liệu lưu trữ của người dùng trong khi hiệu năng, tần suất truy cập vẫn được đảm bảo. Khác với kiểu cơ sở dữ liệu dạng mối quan hệ (Relational database), phải đối mặt với những thách thức không nhỏ với dữ liệu lớn và thay đổi liên tục, NoSQL database đã thể hiện được những ưu điểm của mình không chỉ về mặt kỹ thuật mà còn về cả mặt kinh tế.
Có nhiều tiêu chí để phân loại NoSQL database, nhưng đơn giản và dễ hiểu nhất là dựa trên mô hình dữ liệu:
- Column: Accumulo, Cassandra, Druid, HBase
- Document: Clusterpoint, Apache CouchDB, Couchbase, MarkLogic, MongoDB
- Key-value: Dynamo, FoundationDB, MemcacheDB, Redis, Riak, FairCom c-treeACE, Aerospike
- Graph: Allegro, Neo4J, InfiniteGraph, OrientDB, Virtuoso, Stardog
Tùy theo yêu cầu lưu trữ của hệ thống mà các nhà phát triển có thể lựa chọn cho mình loại lưu trữ phù hợp để có thể đạt được lợi ích cao nhất. Trong khuôn khổ bài viết này, chúng ta sẽ đi sâu Riak, một loại NoSQL database rất mới
2.Riak
2.1 Overview about Riak
Riak là một loại cơ sở dữ liệu phân tán được xây dựng bởi Basho Technology để có thể tối đa hóa quá trình chuyển dữ liệu tới người dùng qua nhiều server. Riak được chia làm2phần chính: Riak server và Riak client. Khi Riak client có thể kết nối tới một server là có thể truy cập dữ liệu.
Với Riak chúng ta có thể xây dựng hệ thống theo hai mô hình chính:
- Eventually consistent system: Dữ liệu mong muốn nên được lưu trữ để có thể sẵn sàng trong hầu hết các kịch bản xảy ra sự cố mặc dù dữ liệu này có thể không phải là dữ liệu được cập nhật mới nhất.
- Strongly consistent system : với mô hình hệ thống này, quá trình đọc dữ liệu sẽ trả về dữ liệu gần như là mới nhất nhưng một vài nút sẽ có thể không sẵn sàng để ghi dữ liệu này vào.
2.2 Một số đặc điểm cơ bản của Riak
- Availability: Riak có thể ghi và đọc dữ liệu từ nhiều server và đề nghị dữ liệu sẵn sàng trong các trường hợp phần cứng hoặc network gặp sự cố
- Operational simplicity :Dễ dàng để thêm mới một riak cluster mà không ảnh hưởng tới toàn bộ hệ thống
- Scalibility: Riak tự động phân tán dữ liệu xung quanh các cluster và yield với hiệu năng tăng dần theo khối lượng
- Masterless: Request nếu không được giữ trong một serrver cụ thể nào đó thì có nghĩa là nó không tồn tại
2.3 Storing data in Riak
Trong Riak, dữ liệu được tự động lưu phân tán trên các node sử dụng phương pháp consistent hashing nghĩa là chia nhỏ dữ liệu và phân bố đều trên các node. Consistent hashing đảm bảo dữ liệu được phân tán đều trong nhóm các node và các node có thể thêm vào tự động, tối thiểu quá quá trình sắp xếp lại dữ liệu. Điều này đã làm giảm đi đáng kể những điểm nóng trong cơ sở dữ liệu, dễ dàng tăng quy mô của hệ thống.
Riak lưu trữ dữ liệu sử dụng mô hình Object {key: value}. Các object thuộc cùng một namspace sẽ được nhóm lại với nhau thành các bucket.
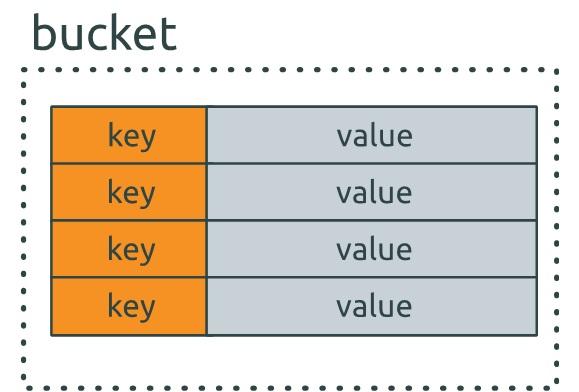
Khi ghi một key mới vào Riak, đối tượng bucket/key sẽ được chia thành các phần nhỏ. Giá trị trả về sẽ được gán vào 160-bit integer và 160-bit này sẽ được tổ chức thành vòng tròn (ring) để có thể quyết định server vật lý nào mà dữ liệu sẽ được lưu trữ. Ở đây, Riak sẽ chia tổng dung lượng thành nhiều phân mảng nhỏ có dung lượng bằng nhau (thông thường sẽ chia làm 64 phần). Mỗi phân mảnh sẽ được nhận một khoảng giá trị nằm trên vòng tròn và có trách nhiệm lưu trữ cho tất cả các key/bucket. Node ảo ( vnode) là quá trình quản lý mỗi phần của những phân mảnh nằm trên các nút vật lý khác nhau. Nói một cách đơn giản rằng, mỗi một server vật lý sẽ sở hữu nhiều vnode.
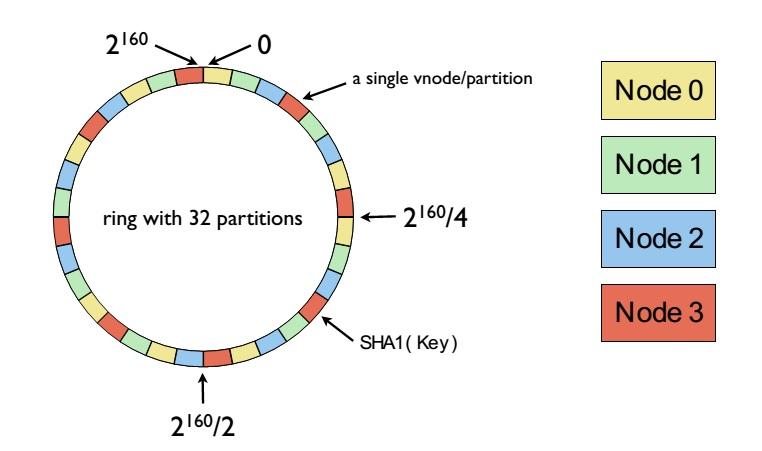
Quá trình chia nhỏ dữ liệu cũng như chia sẻ trách nhiệm lưu trữ các key trên nhiều node đảm bảo rằng dữ liệu trên Riak sẽ được phân tán đều. Khi một server vật lý mới được thêm vào, thiết bị này sẽ phải tính toán lại lượng dữ liệu hiện giờ đang sở hữu và sẽ yêu cầu phân mảng dữ liệu cho tới khi lượng dữ liệu này được cân bằng với các thiết bị khác. Để giúp đỡ quá trình này, Riak có sử dụng giao thức trao đổi (gossip protocol) và định hướng dữ liệu (guide for routing request).
2.3 Should and shouldn't use Riak
Should:Riak sẽ phát huy hết khả năng của mình trong những trường hợp sau:
-
Immutable data - dữ liệu ít thay đổi: Riak có khả năng giải quyết các xung đột dữ liệu giữa các bản sao của object, tuy nhiên điều này có thể dẫn tới hiệu năng thấp trong một số trường hợp. Lưu trữ dữ liệu ít thay đổi có nghĩa là user có thể hạn chế được những yêu cầu tất cả các process chạy đồng thời và đưa ra bên ngoài Riak
-
Small object - các đối tượng nhỏ: Riak không được thiết kế để lưu trữ những đối tượng có dung lượng lớn như video hay BLOBs (Binary Large OBject). Với Riak, nên sử dụng : JSON, log file, sensor data, HTML file và các loại file khác có dung lượng nhỏ hơn 1MB
-
Independent object - đối tượng độc lập: Các đối tượng không có liên quan tới các đối tượng khác
-
Object with "natural" keys - Đối tượng sử dụng các key tự nhiên: Riak khuyến khích user cấu trúc dữ liệu sữ dụng các key tự nhiên "natural key" để có thể phân biệt với các object khác với mục tiêu tăng nhanh hiệu năng trong quá trình tìm kiếm object
Shouldn't : Không nên sử dụng Riak khi:
-
Dung lượng của đối tượng có thể vượt quá 1-2 MB: Với những file có dung lượng lớn hơn, chúng ta có thể sử dụng Riak CS. Lưu trữ các đối tượng có dung lượng lớn sẽ dẫn tới hiệu năng thấp của toàn hệ thống
-
Đối tượng với cấu trúc phụ thuộc phức tạp: Nếu như dữ liệu sử dụng không thể chia nhỏ thành các phần độc lập và yêu cầu các quan hệ liên kết thì nên sử dụng mối loại database khác phù hợp (relational database: SQL, mySQL....)
2.4 Riak with Ruby and Rails
Như đã giới thiệu ở trên, Riak bao gồm 2 thành phần chính là Riak Client và Riak server. Trong khuôn khổ bài viết này, tôi sẽ tập trung đi sâu cách xây dựng một hệ thống Riak cơ bản chạy trên một PC chạy Ubuntu 14.04
2.4.1 Riak server
Riak hiện nay đã được nâng lên phiên bản 2.0.1 và có thể dễ dàng cài đặt từ apt-resource của Ubuntu:
sudo apt-get install riak
Sau đó khởi động service của Riak:
sudo riak start
Lưu ý Riak sử dụng hai port là 8087 (đối với Riak thông thường) và 10017 (đối với Riak sử dụng nhiều cluster) nên trong iptable phải cho phép 2 cổng này cung cấp dịch vụ thì Raik server mới hoạt động được.
Và như thế Riak database đã sẵn sàng để lưu trữ dữ liệu. Hai câu lệnh này cài đặt và cấu hình Riak ở mức độ cơ bản để có user có thể sử dụng nhanh chóng. Về việc xây dựng một hệ thống Riak có quy mô hơn, với những bucket, node được tổ chức rõ ràng, tôi xin phép được cung cấp trong bài viết sau
***2.4.2 Riak client:
Về phía client, Riak cung cấp công cụ là Riak client có thể cài đặt trực tiếp bằng gem trên ruby:
gem install riak-client
Trước khi có thể mang riak vào sử dụng trong Ruby on Rails, phải kiểm tra trước hoạt động của Riak trên ruby thuần bằng Interactive Ruby Shell (irb):
require "riak"
client = Riak::Client.new(:protocol => "pbc", :pb_port => 8087)
client.ping
Trong trường hợp kết quả trả về là true thì Riak client đã có thể kết nối tới Riak-server. Nếu như xảy ra lỗi hoặc client.ping trả về false, cần xem lại quá trình cài đặt và cấu hình cho Riak
Một số thao tác với data trên Riak:
Tạo Object và Bucket:
# with normal data type
my_bucket = client.bucket("test")
val_1 = 1obj_1 = my_bucket.new("one")
obj_1.data = val_1 obj_1.store()
val_2 = "two"obj_2 = my_bucket.new("two")
obj_2.data = val_2 obj_2.store()
val_3 = { value: 3 }
obj_3 = my_bucket.new("three")
obj_3.data = val3 obj_3.store()
#with complex data structure
book = {
isbn: "123456789"
author: "Chu Lai",
title: "Pho",
published: "2008",
price: "23000"
}
book_bucket = client.bucket("book")
new_book = book_bucket.new(book[:isbn])
new_book.data = book
new_book.store()
Lấy thay đổi và xóa dữ liệu:
#get from bucket
fetched1 = my_bucket.get("test)
fetched2 = my_bucket.get("two)
fetched3 = my_bucket.get("book")
#update
fetched3.data["price"] = 200000
fetched3.store()
#delete
my_bucket.delete("test")
fetched2.delete()
fetched3.delete()
Sử dụng Riak trong Ruby on Rails:
Để có thể sử dụng Riak trong Ruby on Rails, cần một số thay đổi cơ bản trong Rails application:
# Gemfile
gem "ripple", "1.0.0.beta2" #new data model, not use active record
gem "excon" #improve HTTP perfromance
gem "yajl-ruby" #faster JSON
#config/ripple
development:
http_port: 8098
pb_port: 8097
host: 127.0.0.1 # may be use another remote host
Lưu ý hiện nay ripple chỉ hỗ trợ cho các phiên bản Rails 3.x, các phiên bản Rails sau này, Basho không còn khuyến cáo sử dụng ripple do ripple không phản ánh đúng tính chất của Riak và sử dụng cách gọi Riak client gốc. Tuy nhiên, với những developer đã quá quen thuộc với mô hình MVC, ripple vẫn là một gem đáng để lưu tâm. Nếu sử dụng ripple, các model sẽ có dạng như sau
class Person
include Ripple::Document
property :name, String, :presence => "true"
property :age, Integer
property :address, String
end
Và bây giờ Riak đã sẵn sàng để sử dụng trên ruby on Rails
3. Conclusion
Mặc dù có rất nhiều ưu điểm vượt trội về mặt hiệu năng cũng như phương pháp sử dụng nhưng Riak vẫn còn khá là mới để có thể ứng dụng trên các sản phẩm thương mại. Tuy nhiên, trong tương lai không xa Riak sẽ là một giải pháp không thể thiếu được cho các ứng dụng NoSQL database, tương tự như điều mà MongoDB đã và đang làm được.
All rights reserved
