[Fundamental] Inside Ruby Hash
Bài đăng này đã không được cập nhật trong 4 năm
Previously, I have written a post talking about Ruby Class and Object and today I would like to present another basic component of Ruby, Hash table.
1. Briefly about Hash Table in Ruby
Hash tables are widely used in programming due to its benefits during implementation. Basically, Hash tables group values into places or bins based on integer values which are calculated from hash function. When retrieving a value, it is pushed to reversed hash function to get position of bins so searching speed can be improved.
1.1 Structure of Hash Table
I guess that the short description above, nobody can understand about Hash Table in Ruby, so let write some codes for easier understanding
new_hash = Hash.new
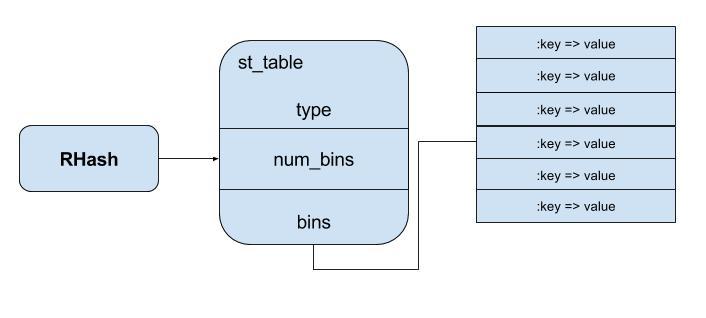
Right after we called Hash class to create a new hash object, there are there component made: RHash, st_tables and bins. Each RHash, a Ruby Structure contains a pointer to a corresponding st_table which is a C structure carries necessary information about hash table including number of bins, number of entries and a pointer to the bins. Regarding to the bins, from Ruby 1.9 and before, there are 11 bins created when initializing a new hash and based on value from hash function, the position of new value will be store in suitable bins
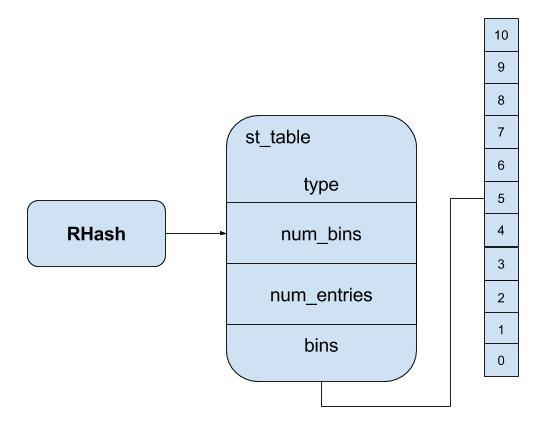
However, it is just an empty hash so we have to add new key/value to it
Adding new value to hash
simple_hash[:key] = "value"
Behind this simple line some, there are some magical things happened:
- Ruby calculates a pseudo-random value from
:keyby itsinteral_hash_function(I will explain more in bellow part)ruby pseu_value = internal_hash_function(:key) - Ruby takes
pseu_valueand calculates the modulus by the number of bins, which is the remainder after diving by the bins numberruby pseu_value % 11 = 2 - Ruby creates a new structures called an
st_table_entrythat it will save into the hash table forsimple_hashand it is placed under bucket number two
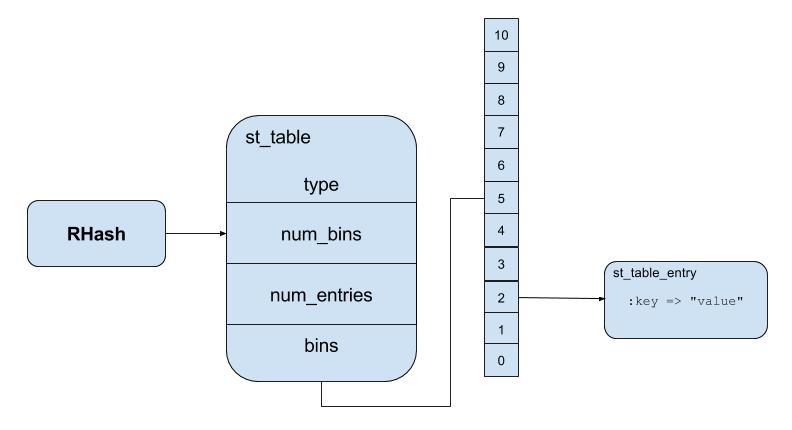
For the next key/value added to hash
simple_hash[:key2] = "value2"
Ruby will do exactly with process of first element, however, the pseu_value will be different and I assume that the new value can get remainder of 5 when dividing by 11. So now we have two couples of key/value in simple_hash in third and sixth place.
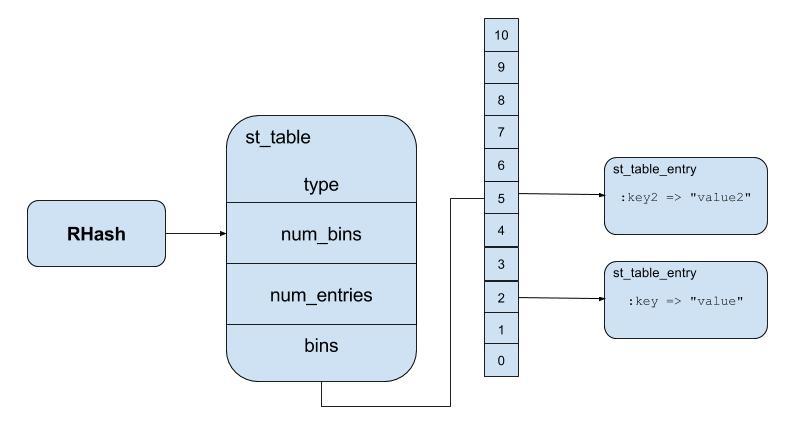
Retrieving value from hash
Many people think that all of storing steps are so complicated and unnecessary if we just need to save data. That's right but I can bet that they will change their opinion when see how hash retrieve data.
puts simple_hash[:key]
=> "value"
Let's think about storing keys/values in arrays or linked list, we have to iterate over all elements in arrays or list, just looking for :key and I can sure that it might take very long time,depending on the number of elements. If we employ hash table, Ruby can jump straight to the needed key by recalculating pseu_value for that key then point to right position based on remainder when dividing for 11.
1.2 Expandable
Ruby has only 11 bins for storing key/value, so what will happen if the number of key/value exceeds 11?. During working with Ruby,I have seen many case that a hash can include up to 100,000 elements and obviously, eleven bins cannot satisfy unique key/value each bin. Let's find out how Ruby hash distribute value for limited number of bucket.
Hash Collisions
From the first part, we can see that in some case two or more entry can be save into same bin due to the fact that pseu_value divides for 11 can get same remaining number. It means that Ruby is no longer able to uniquely identify and retrieve a key based on value from hash function.
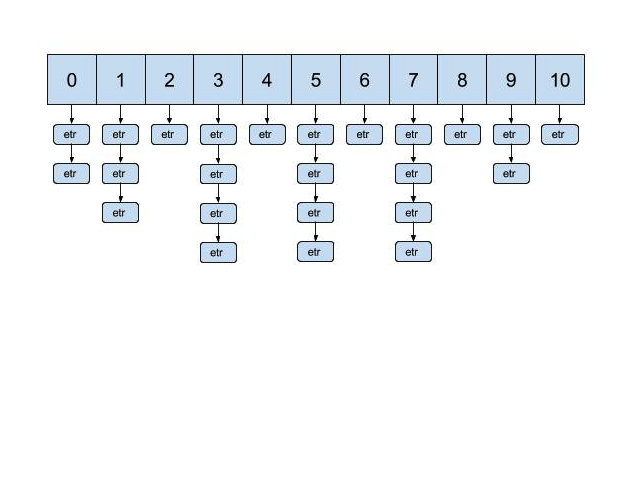
To deal with this circumstance, instead of storing single entry, a Ruby linked list is made and each st_table_entry structure contains a pointer to next entry of same bin. As much more entries to the hash, the linked list get longer and longer.
To retrieve a value, after point out bin number, Ruby doesn't have another better solution than iterate every key/value to take exact key/value. For the case that keys are symbols or number, just directly compare value to find needed key meanwhile complex data structure likes object, Ruby have to use function eql?.
So, we still have to use linked list and employ loop function to get correct key/value. So when key/value number growing to an enormous number, we need other technique. That is rehashing
Rehashing entries
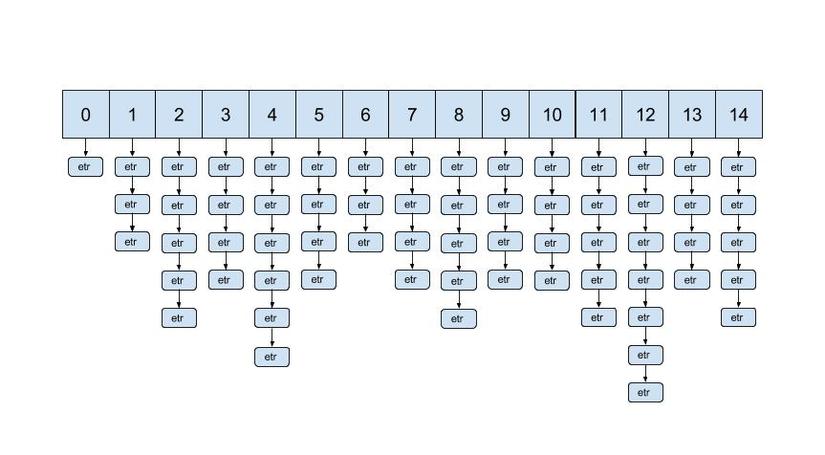
For now, we couldn't refuse that if a hash continue to grow, it will be out of control. Besides, limited number of bins can lead to the worst case that almost entries concentrate at a few bins and that's an nightmare for performance. To tackle this serious problem, Ruby measures the density or in other hand, average number of entries per bins and provide an edge for it. When the density cross over the border, Ruby will re-distribute entry by providing more bins to guarantee that the density bellow threshold. Then after rehashing, the performance definitely will be much better For example, picture bellow portraits the case when average bins number stay bellow 4
2. Hash function in Ruby
Now, we have known how Ruby create and organize hash tables. In this part, I want to dive into hash function to get a closer look about making pseu_value which is important for choosing bin position. This function is a heart of Ruby Hash, if it works well Ruby hashes are fast but poor hash function can cause performance problems. As mentioned before, the bin index is calculated follow this formula
bin_index = internal_hash_function(key) % bin_count
It seems internal_hash_function is so complicated but for short, we can use hash function of Ruby which use to generate a Fixnum for any object
bin_index = :key.hash % 11
=> 8
"test".hash
=> 222145299833251999
12.hash
=> 2601843811801843354
Class.hash
=> -3617190151587507367
Object.hash
=> -4386137482250518487
[1,2,3].hash
=> 371267256257006386
What a special function when it can create a random integer number from any kind of data input from Array, Symbol, String, Numeric even Hash and it can guarantee that hash table can also store any kind of data.
However, the magical thing from hash function is it always return same value with same input data and it is not just a random number so we can use it to retrieve data from hash.
There are some significant points about hash function:
- It was defined in Object class and in Ruby, everything's object so it's always available
- The base of hash function came from C code and its purpose to get pointer value of each object which basically is memory address. After a complex C function, the pointer will be transformed into pseudo-random integer, which can satisfy requirement: unique within an object
- If key is Array or String, Ruby actually iterates through all of characters/element the calculate a cumulative hash value because when an element changes, we will get completely different pair of key/value For the case of Integer/Symbol, Ruby poses their values directly to hash function so using symbol/number key can improve performance of hash table
- From Ruby 1.9, the background of hash function is MurmurHash function which was invented by Austin Appleby in 2008. This function using random seed that's initialized when ruby start It means that when we restart Ruby, we'll get another value for hash function but in same Ruby process, it keep the same
3. Hash improvement from Ruby 2.0
From Ruby 2.0, there's a significant change in hash table which can make hashes work even more faster. For hashes that contains 6 or fewer elements, Ruby store it directly into an array so we can skip calculating the hash value for this simple case. And this array's called as packed hashes.
Because small hashes don't need bins so additional structure for each part of key value. When the seventh element is added to hash, Ruby will discard the array and create a bin array then move all entry to bins To find the needed key, Ruby iterates through the array and use method eql? to collect the key
All rights reserved
