Nhận dạng giọng nói Web App sử dụng SpeechRecognition Web API
This post hasn't been updated for 5 years
Vào 2018, Google thông báo rằng có 27% người dùng online sử dụng giọng nói để tìm kiếm trên các thiết bị di động (thông tin tại đây). Với nhận dạng giọng nói trong trình duyệt, chúng ta có thể cho phép người dùng nói chuyện với trang web của chúng ta trên nhiều nền tảng, và từ đó chúng ta có thể tạo ra nhiều ứng dụng hữu ích. Trong bài viết này mình sẽ giới thiệu với các bạn cách đơn giản để nhận dạng giọng nói với Web Speech API. Bắt đầu nào 
Web Speech API
- Web Speech API được định nghĩa là một JavaScript API cho phép chúng kết hợp nhận dạng và tổng hợp giọng nói vào trang web. Nó cho phép chúng ta sử dụng script để chuyển text-to-speech và sử dụng nhận dạng giọng nói làm đầu vào. JavaScript API cho phép trang web của chúng ta kiểm soát được việc kích hoạt, thời gian và xử lý kết quả.
- API được thiết kế cho phép cả đầu vào giọng nói ngắn(một lần) và đầu vào giọng nói liên tục. Kết quả nhận dạng giọng nói được cung cấp cho trang web dưới dạng danh sách hypotheses cùng với các thông tin liên quan cho mỗi hypotheses
Chức năng chính của Web Speech API
- Như đã giới thiệu ở phần trên thì
Web Speech APIcó 2 chức năng chính:- Speech synthesis: tổng hợp giọng nói hay chuyển văn bản thành giọng nói (text to speech)
- Speech recognition: nhận dạng giọng nói hay chuyển giọng nói thành văn bản (speech to text)
SpeechRecognition API
Constructor
- Tạo một instance object SpeechRecognition hoặc webkitSpeechRecognition:
var SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
var recognition = new SpeechRecognition();
recognition.start();
Chúng ta có thể thử trên trình duyệt của mình bằng cách vào brower dev tools và copy đoạn code trên và paste vào. Mình sẽ thử trên trình duyệt Chrome
Khi chúng ta chạy đoạn code trên, Chrome sẽ yều quyền truy cập sử dụng microphone của chúng ta. Sau khi cấp quyền, chúng ta nói điều gì đó thì sau khi ngừng nói sẽ phát ra event SpeechRecognitionEvent và sẽ nhận được kết quả từ event.
SpeechRecognition Attributes
grammars
- Kiểu của nó là
SpeechGrammarList, đại diện choSpeechGrammarchứa các từ hoặc mẫu từ mà chúng ta muốnrecognition servicenhận dạng - Grammar được định nghĩa sử dụng JSpeech Grammar Format (JSGF)
lang
- Kiểu của nó là DOMString, thuộc tính này sẽ đặt ngôn ngữ nhận dạng cho yêu cầu của chúng ta. Nếu không được chỉ định, mặc định giá trị thuộc tính là HTML lang
continuous
- Thuộc tính này cho phép chúng ta kiểm soát xem các kết quả trả về là liên tục hay là một kết quả duy nhất (single). Mặc định là single (false)
interimResults
- Thuộc tính này cho phép chúng ta kiểm soát xem kết quả tạm thời có được trả về (true) hay không (false)
maxAlternatives
- Đặt số lượng
SpeechRecognitionAlternatives(xem thêm ở phầnSpeechRecognitionEvent) tối đa được cung cấp cho mỗi kết quả. Giá trị mặc định là 1
SpeechRecognition Methods
- start(): Khi phương thức
start()được gọi khi ứng dụng web của chúng ta bắt đầu nhận dạng giọng nói. Khi chúng ta bắt đầu nói thông qua microphone thì thời điểm này là thời điểm mà dịch bắt đầu để lắng nghe và match ngữ pháp với yêu cầu của chúng ta. Sau khi hệ thống lắng nghe nhận dạng thành công, lúc này chúng ta phải đưa ra eventstart. Nếu phương thứcstart()được gọi trên một đối tượng đã được start, thì chúng ta phải trả về mộtInvalidStateErrorDOMException và loại bỏ việc call. - stop(): Phương thức này cho phép chúng ta thông báo với
recognition servicedừng việc lắng nghe âm thanh và trả lại kết quả dựa trên âm thanh mà đã nhận được để nhận dạng. - abort(): Phương thức này cho phép chúng ta dừng việc lắng nghe và ngừng nhận dạng và không trả lại bất kỳ thông tin nào mà hệ thống đã thực hiện
SpeechRecognitionEvent
- Đối tượng
SpeechRecognitionEventthì thuộc tính quan trọng nhất của nó làresults, danh sách các đối tượngSpeechRecognitionResult. Sau khi ngừng lắng nghe sẽ trả về một đối tượngresult.SpeechRecognitionResulttrả về kết quả là danh sách các đối tượngSpeechRecognitionAlternative, đối tượng này có 2 thuộc tính:- transcript: bản ghi những gì mà chúng ta đã nói thông qua microphone
- confidence: giá trị giữa từ 0 đến 1
- Mặc định thì result sẽ trả về một
Alternative, nhưng chúng ta có thể thêm các lựa chọnAlternativetừrecognition service, điều này cho phép chúng ta cho phép người dùng chọn những lựa chọn sát nhất với những gì họ nói.
Các bạn có thể sử dụng đoạn code dưới đây để thử trên console của trình duyệt:
var SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
var recognition = new SpeechRecognition();
recognition.onresult = console.log;
recognition.start();
Sau khi chạy, cấp quyền sử dụng microphone trên trình duyệt và nói hello thì kết quả trên console của trình duyệt sẽ trả về như sau:
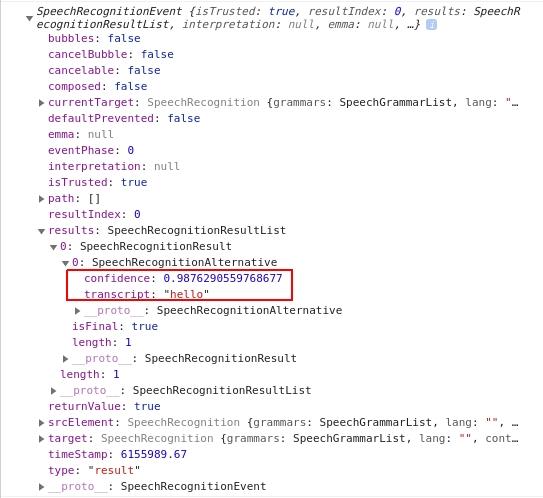
Cơ chế hoạt động
Sau khi cấp quyền cho microphone recognition service bắt đầu lắng nghe và chúng ta nói điều gì đó, tùy theo cài đặt thuộc tính của chúng ta việc ngừng nói để gọi đến phương thứcstop() hay nút bấm để thông báo với recognition service sẽ dừng việc lắng nghe, sau đó:
- Đối với
Chrome:Chromelấy âm thanh và gửi đến máy chủ của Google để thực hiện quá trình phiên âm. Hiện tạispeech recognitionchỉ được hỗ trợ trongchromevà một vài trình duyệt dựa trênChromium - Đối với
Firefox: Mozilla đang sử dụng cộng cụDeepSpeechcủa họ. sau đó trả về dữ liệu cho chúng ta thông quaSpeechRecognitionEvent.
Nhược điểm, vì dữ liệu của chúng ta được gửi lên một API server nên bắt buộc chúng ta phải online thì mới thực hiện được việc này.
Các trường hợp có thể sử dụng
Sau đây mình giới thiệu với các bạn một số trường hợp chúng ta có thể sử dụng Web Speech API này vào:
các case này mình tham khảo tại đây
- Voice Web Search
- Speech Command Interface
- Domain Specific Grammars Contingent on Earlier Inputs
- Continuous Recognition of Open Dialog
- Domain Specific Grammars Filling Multiple Input Fields
- Speech UI present when no visible UI need be present
- Voice Activity Detection
- Temporal Structure of Synthesis to Provide Visual Feedback
- Hello World
- Speech Translation
- Speech Enabled Email Client
- Dialog Systems
- Multimodal Interaction
- Speech Driving Directions
- Multimodal Video Game
- Multimodal Search
- Rerecognition
Demo
Trong demo này thì đơn giản mình chỉ cần một button để start speech recognition. Sau khi click button Voice chat: trình duyệt sẽ yều cầu cấp quyền cho ứng dụng:
- Trường hợp đầu tiên: mình đã từ chối việc cho phép quyền của microphone và ứng dụng sẽ trả về một error
- Trường hợp tiếp theo là mình cho phép quyền của microphone và sau đó mình nói
xin chào. Sau khi mình ngừng nói thìSpeechRecognitionnhận được đầu vào là âm thanh mình đã nói và gửi tới server của API và xử lý phiên âm âm thanh mình đã nói sau. Sau đó kết quả trả về sẽ hiển thị trên màn hình:
var message = document.querySelector('#message');
var SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
var SpeechGrammarList = SpeechGrammarList || webkitSpeechGrammarList;
var grammar = '#JSGF V1.0;'
var recognition = new SpeechRecognition();
var speechRecognitionList = new SpeechGrammarList();
speechRecognitionList.addFromString(grammar, 1);
recognition.grammars = speechRecognitionList;
recognition.lang = 'vi-VN';
recognition.interimResults = false;
recognition.onresult = function(event) {
var lastResult = event.results.length - 1;
var content = event.results[lastResult][0].transcript;
message.textContent = 'Voice Input: ' + content + '.';
};
recognition.onspeechend = function() {
recognition.stop();
};
recognition.onerror = function(event) {
message.textContent = 'Error occurred in recognition: ' + event.error;
}
document.querySelector('#btnTalk').addEventListener('click', function(){
recognition.start();
});

Kết luận
Trong bài viết này mình đã giới thiệu với các bạn cách đơn giản để nhận dạng giọng nói trên Web App sử dụng SpeechRecognition Web API. Từ đó chúng ta có thể tích hợp và làm một số ứng dụng thú vị. Cảm ơn các bạn đã theo dõi bài viết 
All Rights Reserved
