MiniCPM-V: Mang sức mạnh của Multimodal LLM ngang tầm GPT4-V lên thiết bị di động

Như đã đề cập trong bài viết trước về MiniCPM, mình đã giới thiệu về sự đột phá của các mô hình ngôn ngữ nhỏ (ở đây là MiniCPM) trong việc tối ưu hóa hiệu suất mà vẫn duy trì kích thước gọn nhẹ. Trong bài viết này, mình sẽ đi sâu vào giải thích cách MiniCPM-V - một mô hình thị giác ngôn ngữ (MLLM) đạt được hiệu suất tương đương GPT-4V, đồng thời vẫn đủ nhẹ để có thể triển khai trên các thiết bị di động như điện thoại thông minh và máy tính bảng.
I. MiniCPM-V là gì?
MiniCPM-V là một loạt các mô hình Ngôn ngữ Lớn Đa Phương Thức (Multimodal Large Language Model) được thiết kế để hoạt động hiệu quả trên các thiết bị di động và yếu hơn. Thay vì đòi hỏi hạ tầng đám mây mạnh mẽ, MiniCPM-V được xây dựng để chạy trực tiếp trên các thiết bị có tài nguyên hạn chế mà không làm mất đi hiệu suất.
Mô hình mới nhất được giới thiệu trong bài viết này, MiniCPM-V 2.6 với 8 tỷ tham số, đã vượt qua cả những mô hình khủng như GPT-4V và Gemini Pro trong nhiều bài kiểm tra tiêu chuẩn.
II. Tổng thể kiến trúc
Kiến trúc của MiniCPM-V mang đến sự cân bằng giữa hiệu suất cao và thiết kế thông minh, giúp mô hình này nhẹ mà vẫn mạnh mẽ.

Ở giai đoạn cuối của kiến trúc, mô hình LLM (MiniCPM-2.4B) tiếp nhận các token đã được nén. Trước đó, hình ảnh input sẽ trải qua nhiều lớp và thành phần xử lý khác nhau để chuyển đổi thành các token nén này:
1. Mã hoá hình ảnh thích ứng (Adaptive Visual Encoding)
Một thách thức lớn đối với các mô hình đa phương thức là việc xử lý các hình ảnh có kích thước và tỉ lệ khung hình khác nhau. MiniCPM-V vượt qua bằng kỹ thuật "mã hóa hình ảnh thích ứng". Hình ảnh lớn được chia thành nhiều phần nhỏ (slices), mỗi phần được chuyển đổi về kích thước phù hợp với mô hình Vision Transformer. Điều này không chỉ giúp mô hình xử lý các hình ảnh đa dạng một cách hiệu quả, mà còn giảm thiểu yêu cầu về tài nguyên tính toán mà vẫn giữ được độ chi tiết cao của hình ảnh.
2. Bộ mã hoá hình ảnh (Vision Encoder)
Bộ mã hóa hình ảnh đóng vai trò quan trọng trong khả năng xử lý đa phương thức của MiniCPM-V. Bộ mã hóa này sử dụng mô hình Vision Transformer đã được tinh chỉnh (ở đây là SigLIP-SoViT-400m/14) để có thể xử lý hình ảnh độ phân giải cao. Quá trình này giúp chuyển đổi hình ảnh thành các token mà mô hình có thể hiểu và kết hợp với phần xử lý ngôn ngữ.
3. Nén token (Token Compression): Yếu tố tăng tốc
Việc xử lý hình ảnh tạo ra rất nhiều token, điều này có thể tiêu tốn tài nguyên bộ nhớ và làm chậm quá trình tính toán. MiniCPM-V sử dụng một lớp nén token, giúp giảm số lượng token đáng kể. Ví dụ, với MiniCPM-Llama3-V 2.5, quá trình nén token giảm từ hàng ngàn token chỉ còn 96 token cho mỗi phần hình ảnh. Điều này giúp mô hình sử dụng bộ nhớ hiệu quả hơn và giảm thời gian xử lý trong quá trình suy luận (inference).
4. Sơ đồ không gian (Spatial Schema): Duy trì cấu trúc
Khi hình ảnh được chia thành các phần nhỏ, điều quan trọng là mô hình vẫn phải giữ được cấu trúc không gian giữa các phần khác nhau của hình ảnh. MiniCPM-V giải quyết vấn đề này bằng cách sử dụng một sơ đồ không gian, trong đó các token đặc biệt (special tokens) được chèn vào để đánh dấu vị trí của từng phần hình ảnh. Điều này giúp mô hình hiểu rõ hơn về vị trí của các đối tượng trong không gian và cải thiện độ chính xác của các tác vụ liên quan đến hình ảnh.
III. Các kỹ thuật tối ưu hoá để chạy trên thiết bị di động
Một trong những điểm ấn tượng nhất của MiniCPM-V là khả năng hoạt động trên các thiết bị di động. Các điện thoại di động có bộ nhớ hạn chế, vi xử lý chậm hơn và GPU nhỏ hơn so với các máy chủ đám mây. Tuy nhiên, MiniCPM-V đã giải quyết vấn đề này nhờ các kỹ thuật sau:
1. Lượng tử hóa (Quantization)
Lượng tử hóa là kỹ thuật giảm kích thước mô hình mà không làm giảm hiệu suất. Với MiniCPM-Llama3-V 2.5, kỹ thuật lượng tử hóa 4-bit giúp giảm yêu cầu bộ nhớ từ 16GB xuống còn khoảng 5GB, phù hợp để chạy trên các điện thoại như Xiaomi 14 Pro.
2. Tối ưu hóa bộ nhớ
Các thiết bị di động có bộ nhớ hạn chế, vì vậy việc tải đồng thời cả bộ mã hóa hình ảnh và mô hình ngôn ngữ có thể gây ra chậm trễ. MiniCPM-V giải quyết vấn đề này bằng cách tải tuần tự từng thành phần, giúp sử dụng bộ nhớ hiệu quả hơn.
3. Tăng tốc NPU (Neural Processing Unit)
Một số điện thoại di động hiện nay được trang bị NPU, là các chip chuyên dụng cho xử lý AI. MiniCPM-V tận dụng NPU để tăng tốc quá trình mã hóa hình ảnh, giảm đáng kể thời gian xử lý.
IV. Các giai đoạn huấn luyện
Để đạt được hiệu suất cao, MiniCPM-V trải qua nhiều giai đoạn huấn luyện cũng tương đồng như cách họ đã sử dụng cho MiniCPM:
- Pre-training: Mô hình được huấn luyện trên các tập dữ liệu hình ảnh-văn bản lớn, giúp học kiến thức cơ bản về đa phương thức.
- Supervised Fine-tuning (SFT): Ở giai đoạn này, mô hình được tinh chỉnh trên các tập dữ liệu chất lượng cao với nhãn do con người cung cấp, cải thiện khả năng xử lý và phản hồi chi tiết.
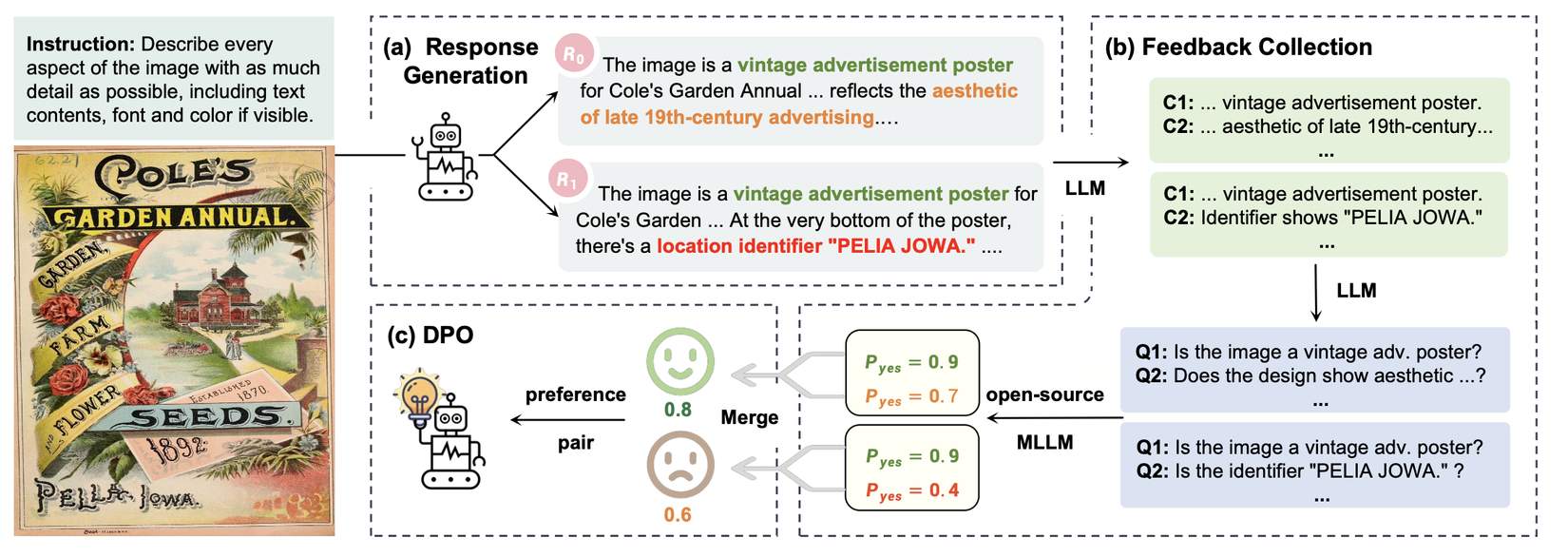
- RLAIF-V Alignment: Kỹ thuật Reinforcement Learning từ phản hồi AI được sử dụng để giảm tỷ lệ "ảo giác" (hallucination), giúp mô hình trở nên đáng tin cậy hơn trong các ứng dụng thực tế.
![image.png]() Hình 2. RLAIF-V framework cho việc giảm hiện tượng ảo giác. (a) Tạo câu trả lời: tạo nhiều câu trả lời cho một câu prompt sử dụng mô hình chính sách (policy model). (b) Thu thập phản hồi: đánh giá tính trình xác của từng câu trả lời theo cách chia để trị. (c) DPO: tối ưu mô hình trên tập dữ liệu về mức độ ưu tiên
Hình 2. RLAIF-V framework cho việc giảm hiện tượng ảo giác. (a) Tạo câu trả lời: tạo nhiều câu trả lời cho một câu prompt sử dụng mô hình chính sách (policy model). (b) Thu thập phản hồi: đánh giá tính trình xác của từng câu trả lời theo cách chia để trị. (c) DPO: tối ưu mô hình trên tập dữ liệu về mức độ ưu tiên
V. Kết quả thực nghiệm
MiniCPM-V đã được đánh giá qua nhiều thử nghiệm và so sánh với các mô hình lớn hơn để chứng minh hiệu suất và tính khả thi của nó khi chạy trên các thiết bị có tài nguyên hạn chế. Dưới đây là một số kết quả nổi bật:
1. Benchmark Perplexity (Độ bối rối)
Perplexity là một chỉ số quan trọng để đánh giá hiệu suất của các mô hình ngôn ngữ, đo lường khả năng dự đoán chính xác chuỗi từ tiếp theo của mô hình. MiniCPM-V 2.6 đạt được mức perplexity rất ấn tượng, tương đương với các mô hình lớn như GPT-4V trên các tác vụ về ngôn ngữ tự nhiên.
2. Hiệu suất trong tác vụ đa phương thức
Trong các thử nghiệm về nhận diện hình ảnh và trả lời câu hỏi dựa trên hình ảnh (Visual Question Answering - VQA), MiniCPM-V đã thể hiện sự vượt trội so với nhiều mô hình lớn khác. Nhờ vào khả năng kết hợp thông tin từ cả hình ảnh và ngôn ngữ, mô hình này có thể xử lý các tác vụ phức tạp, từ nhận dạng đối tượng trong hình ảnh cho đến trả lời câu hỏi về bối cảnh của hình ảnh.

Dựa trên cách tiếp cận tổng quát đa phương thức đa ngôn ngữ từ VisCPM, MiniCPM-Llama3-V 2.5 mở rộng khả năng xử lý đa phương thức của mình sang hơn 30 ngôn ngữ. Như được minh họa trong Hình 3, MiniCPM-Llama3-V 2.5 vượt trội hơn so với Yi-VL 34B và Phi-3-vision-128k-instruct trên thang đánh giá LLaVA đa ngôn ngữ. Khả năng đa phương thức đa ngôn ngữ đầy hứa hẹn này giúp MiniCPM-Llama3-V 2.5 trở nên hữu ích trong việc phục vụ nhóm đối tượng rộng lớn hơn, với sự đa dạng về ngôn ngữ.
3. Nhận dạng ký tự quang học (OCR)
Với khả năng xử lý hình ảnh có độ phân giải cao, MiniCPM-V thể hiện hiệu suất cao trong các tác vụ OCR, giúp mô hình đọc và hiểu văn bản trong hình ảnh với độ chính xác cao. Kết quả cho thấy MiniCPM-V có khả năng cạnh tranh với các mô hình OCR chuyên dụng trong việc nhận diện văn bản từ hình ảnh chụp tài liệu, biển báo, và các dạng văn bản khác.
4. So sánh với các mô hình lớn hơn
MiniCPM-V đã được so sánh với các mô hình lớn như Llama2-7B và Gemini Pro trên nhiều bài kiểm tra về hiệu suất và độ chính xác. Mặc dù có kích thước nhỏ hơn nhiều, MiniCPM-V vẫn đạt được hiệu suất tương đương hoặc thậm chí vượt trội trên một số tác vụ, đặc biệt là trong các ứng dụng yêu cầu xử lý hình ảnh và văn bản kết hợp.
VI. Ứng dụng thực tế
Nhờ khả năng tối ưu hóa hiệu quả, MiniCPM-V có thể được sử dụng trong nhiều ứng dụng thực tế, từ trợ lý AI trên điện thoại di động đến xử lý tài liệu ngoại tuyến.
Mô hình này đặc biệt xuất sắc trong các nhiệm vụ như:
- Trả lời câu hỏi hình ảnh (VQA): MiniCPM-V có khả năng xử lý và trả lời câu hỏi dựa trên hình ảnh một cách chính xác, hoàn hảo cho các trợ lý AI.
- Nhận dạng ký tự quang học (OCR): Với khả năng xử lý hình ảnh độ phân giải cao, MiniCPM-V có thể đọc và hiểu văn bản trong hình ảnh với độ chính xác cao.
VII. Triển khai MiniCPM-V
Trong phần này, mình sẽ sử dụng mô hình MiniCPM-V 2.6 (4.76B params) từ Hugging Face để xây dựng một API nho nhỏ làm nhiệm vụ tạo caption cho ảnh đầu vào. Mình sẽ chia sẻ các bước chi tiết từ tải mô hình, tạo API bằng FastAPI, đến việc xây dựng giao diện người dùng (UI) đơn giản với Bootstrap để chạy thử API trên local.
Bước 1: Tải model từ Hugging Face
Mình sử dụng MiniCPM-V 2.6 phiên bản int4, một phiên bản được tối ưu hóa để sử dụng ít bộ nhớ GPU hơn (khoảng 7GB). Tải model artifacts về máy bằng snapshot_download của Hugging Face:
from huggingface_hub import snapshot_download
snapshot_download(
repo_id='openbmb/MiniCPM-V-2_6-int4',
local_dir='model',
local_dir_use_symlinks=False
)

Bước 2: Xây dựng API với FastAPI
Sau khi đã tải mô hình, bước tiếp theo là tạo một API đơn giản để xử lý ảnh đầu vào và sinh caption tương ứng. API này sẽ có các endpoint cho phép người dùng tải ảnh lên, xử lý và trả về kết quả caption. API này sẽ có các endpoint như:
- /ping: Kiểm tra sức khỏe của hệ thống (health check), đảm bảo rằng API hoạt động bình thường. Khi truy cập endpoint này, hệ thống sẽ trả về thông báo đơn giản như
"message": "ok". - /invocations: Endpoint chính để nhận ảnh từ người dùng, xử lý và trả về caption. Người dùng tải ảnh lên dưới dạng file, sau đó hệ thống sẽ sử dụng mô hình MiniCPM-V để tạo caption dựa trên nội dung hình ảnh và gửi kết quả trả về.
File main.py sẽ đặt bên trong thư mục /app:
import io
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import RedirectResponse
from fastapi.staticfiles import StaticFiles
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
# Load model and tokenizer
MODEL_PATH = 'model'
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model.eval()
app = FastAPI()
app.mount("/static", StaticFiles(directory="app/static"), name="static")
async def process_image(image: UploadFile):
image_data = await image.read()
image = Image.open(io.BytesIO(image_data)).convert('RGB')
return image
# Endpoint for image caption generation
@app.post("/invocations")
async def invocations(
image: UploadFile = File(...),
prompt: str = 'Describe the image in one accurate sentence.'
):
image = await process_image(image)
msgs = [{'role': 'user', 'content': [image, prompt]}]
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer,
temperature=0.7
)
return res
# Health check endpoint
@app.get("/ping")
async def ping():
return {"message": "ok"}
# Redirect to the main page
@app.get("/", include_in_schema=False)
def redirect():
return RedirectResponse("/static/index.html")
Để chạy được API với FastAPI sử dụng Uvicorn, bạn cần tạo file run_server.py:
# run_server.py
import uvicorn
import logging
logging.basicConfig(level=logging.INFO)
if __name__ == "__main__":
uvicorn.run(
"app.main:app",
host="0.0.0.0",
port=8000,
reload=True
)
Trong đó:
"app.main:app"có nghĩa là bạn đang chạy ứng dụng FastAPI từ filemain.pytrong thư mụcapp, với đối tượng FastAPI được gọi làapptrong file đó.host="0.0.0.0"giúp mở API để có thể truy cập từ các thiết bị khác trong mạng (thay vì chỉ chạy cục bộ trên máy tính của bạn).port=8000là port mà bạn có thể thay đổi tùy theo nhu cầu.reload=Truesẽ tự động tải lại server khi có thay đổi trong code, hữu ích khi bạn phát triển và thử nghiệm.
Bước 3: Xây dựng giao diện cơ bản với Bootstrap
Sau khi đã có API, chúng ta sẽ dựng một giao diện đơn giản cho phép người dùng upload ảnh và nhận về kết quả caption. File index.html dưới đây và script.js sẽ đều được đặt bên trong thư mục /app/static:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Image Caption Generator</title>
<!-- Bootstrap CSS CDN -->
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha3/dist/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<div class="container mt-5">
<h1 class="text-center">Image Caption Generator</h1>
<div class="card mt-4">
<div class="card-body">
<form id="captionForm">
<div class="mb-3">
<label for="image" class="form-label">Upload Image</label>
<input class="form-control" type="file" id="image" name="file" accept="image/*" required>
</div>
<div class="mb-3">
<img id="preview" src="#" alt="Image Preview" style="display: none; width: auto; height: 300px;" />
</div>
<button type="submit" class="btn btn-primary">Generate Caption</button>
</form>
<div id="result" class="mt-4" style="display: none;">
<h3>Generated Caption:</h3>
<p id="captionText" class="alert alert-success"></p>
</div>
</div>
</div>
</div>
<!-- Bootstrap JS and dependencies -->
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha3/dist/js/bootstrap.bundle.min.js"></script>
<script src="/static/script.js"></script>
</body>
</html>
File script.js để xử lý ảnh upload và gửi request tới API:
// Image preview functionality
document.getElementById('image').addEventListener('change', function(event) {
const file = event.target.files[0];
const preview = document.getElementById('preview');
if (file) {
const reader = new FileReader();
reader.onload = function(e) {
preview.src = e.target.result;
preview.style.display = 'block';
}
reader.readAsDataURL(file);
} else {
preview.style.display = 'none';
}
});
// Form submission and caption generation
document.getElementById('captionForm').addEventListener('submit', async function(event) {
event.preventDefault();
const imageInput = document.getElementById('image');
const resultDiv = document.getElementById('result');
const captionText = document.getElementById('captionText');
// Show loading message
resultDiv.style.display = 'block';
captionText.textContent = 'Loading...';
// Create a FormData object to send the image only
const formData = new FormData();
formData.append('image', imageInput.files[0]);
// Send the POST request to the FastAPI backend
const response = await fetch('/invocations', {
method: 'POST',
body: formData
});
if (response.ok) {
const data = await response.json();
captionText.textContent = data;
} else {
captionText.textContent = 'Failed to generate caption.';
console.error('Failed to generate caption.');
}
});
Cấu trúc các folder và file cuối cùng sẽ có dạng như sau:

Để chạy server, bạn chỉ cần thực hiện lệnh sau trong terminal:
python run_server.py
Bước 4: Chạy kết quả
Sau khi server đã chạy thành công, khi truy cập vào localhost, bạn sẽ thấy giao diện dưới đây:

Người dùng có thể upload ảnh từ máy tính của mình. Sau đó, mô hình sẽ xử lý và trả về caption tương ứng cho bức ảnh. Trong ví dụ này, khi upload một ảnh chứa hình ảnh của một chú mèo và một chú chó, mô hình đã tạo ra caption chính xác: "Two puppies in astronaut suits are standing on a red planet with a device between them."

VIII. Lời kết
MiniCPM-V đánh dấu một bước tiến quan trọng trong việc đưa các mô hình ngôn ngữ đa phương thức lên thiết bị di động. Khả năng cung cấp hiệu suất tương đương với các mô hình lớn như GPT-4V nhưng vẫn duy trì tính gọn nhẹ và hiệu quả giúp MiniCPM-V trở thành một giải pháp vượt trội cho các thiết bị có tài nguyên hạn chế. Nhờ các cải tiến như mã hóa hình ảnh thích ứng (adaptive visual encoding), nén token, và lượng tử hóa (quantization), mô hình này không chỉ giảm thiểu yêu cầu về phần cứng mà còn mở ra tiềm năng ứng dụng rộng rãi trong thực tế, từ trợ lý AI đến xử lý hình ảnh và tài liệu.
Tham khảo
- https://arxiv.org/abs/2408.01800
- https://huggingface.co/openbmb/MiniCPM-V-2_6-int4
- https://www.geeksforgeeks.org/fastapi-uvicorn/
- https://getbootstrap.com/docs/5.3/getting-started/introduction/
🔗 Kết nối với Pixta Vietnam: http://bit.ly/3kdkzvW
All rights reserved
