Lecture 2: Simple Word Vector representations: Word2vec
Bài đăng này đã không được cập nhật trong 7 năm
Trong bài viết trước, mình đã giới thiệu qua về các nhiệm vụ trong xử lý ngôn ngữ tự nhiên cũng như lợi ích của việc sử dụng Deep Learning cho các nhiệm vụ xử lý ngôn ngữ.
Bài viết tiếp theo này được viết dựa trên bài giảng tuần thứ 2 của khóa CS224n, gồm những nội dung chính sau:
- Giới thiệu về Word2vec
- Hàm đánh giá trong Word2vec
- Tối ưu tham số
Việc sử dụng các phương pháp Word embedding cũng đã được mình trình bày rất kỹ ở bài viết Xây dựng mô hình không gian vector cho Tiếng Việt, để việc hiểu nội dung của bài viết này thật tốt, bạn có thể nên xem lại tại đây.
Bài viết này sẽ dựa vào những nội dung đã đề cập trong bài viết nêu ở trên để từ đó đi sâu vào tìm hiểu cách mà word2vec hoạt động.
Giới thiệu về Word2vec
Nhắc lại một chút về word2vec, word2vec là một phương pháp word embedding chuyển một từ hoặc cụm từ từ không gian 1 chiều cho mỗi từ sang không gian nhiều chiều số thực với số chiều cố định.
Nghĩa của từ được thể hiện thông qua ngữ cảnh là những từ xuất hiện xung quanh nó, được biểu diễn bởi vector trọng số của một mạng neural 1 lớp ẩn, số nút trong lớp ẩn bằng với số chiểu của không gian số thực cần biểu diễn cho mỗi từ.
Khi từ w xuất hiện trong một văn bản, ngữ cảnh của nó là tập hợp các từ ở gần nó(trong một cửa sổ có kích thước định trước).
Chúng ta sẽ xây dựng một vector dày đặc là biểu diễn cho mỗi từ, sao cho các từ có nghĩa tương tự nhau(thường xuất hiện trong các ngữ cảnh giống nhau) sẽ có các vector biểu diễn tương tự nhau.
Về Word2vec, Word2vec là một framework cho việc học các vector biểu diễn từ, được Mikolov xây dựng vào năm 2013 dựa trên ý tưởng:
- Việc tìm ra vector biểu diễn cho mỗi từ sẽ dựa vào một tập hợp lớn các văn bản
- Mỗi từ trong từ điển sẽ được đại diện bởi một vector số thực
- Khi đi qua mỗi vị trí t của văn bản, một từ sẽ được chọn làm từ trung tâm c và các từ ngữ cảnh của c được gọi là outside o
- Sử dụng sự tương đồng giữa các vector đại diện cho c và o để tính toán xác suất để xuất hiện từ o khi đã biết sự xuất hiện của từ c(hoặc ngược lại).
- Sử dụng các phương pháp tối ưu để điều chỉnh các word vector để cực đại xác suất này.
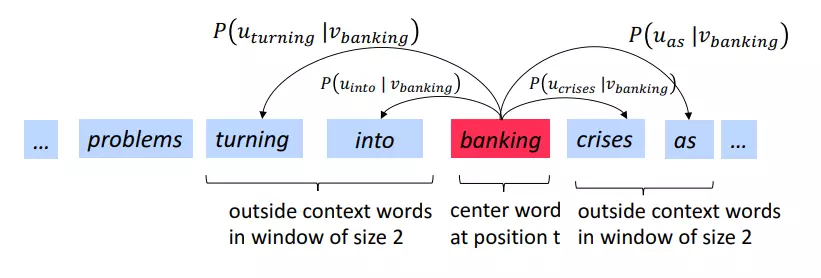
Ví dụ với windows size = 2(lấy ngữ cảnh là 2 từ ở 2 bên từ trung tâm) và tiến hành tính xác suất
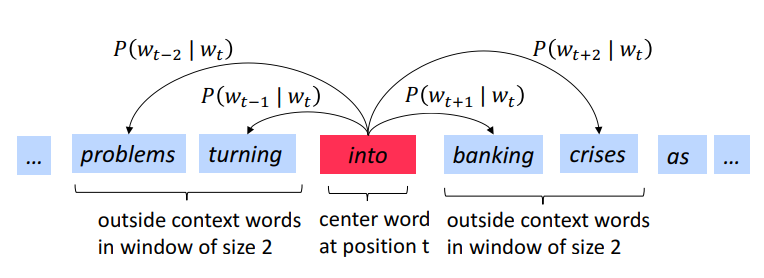
Như hình vẽ trên, các từ ngữ cảnh o là các từ problems, turning, banking, crises. Từ trung tâm là từ into.
Trượt cửa sổ này cho đến hết câu, ta được các cặp từ trung tâm và ngữ cảnh của nó, đây sẽ là dữ liệu training cho thuật toán.
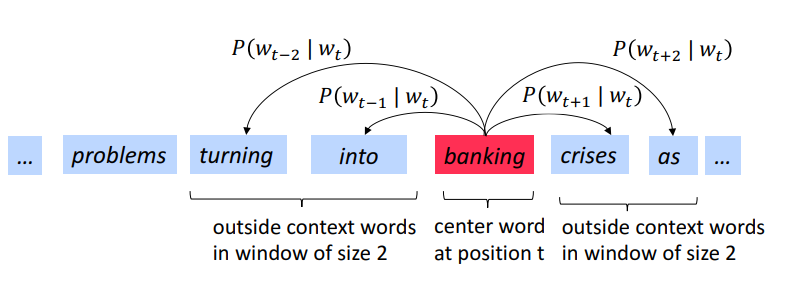
Hàm đánh giá trong Word2vec
Giả sử câu có độ dài T, với mỗi vị trí , dự đoán ngữ cảnh của từ trong cửa sổ trượt có kích thước là m khi đã biết được từ trung tâm .
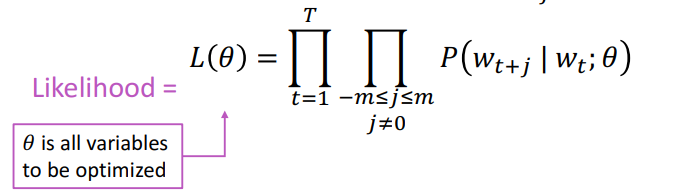
Hàm lỗi là đối dấu của giá trị trung bình của logarithm .(Lý do lấy logarithm là vì phép logarithm giúp ta chuyển từ phép nhân về phép cộng, và phép luôn đồng biến khi x > 0, dễ thấy tối ưu hóa một tổng tốt dễ hơn nhiều so với 1 tích).
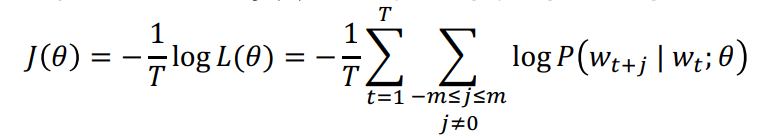
Việc tối ưu tham số để cực đại hóa dự đoán tương đương với việc cực tiểu hóa hàm lỗi .
Để cực tiểu hóa hàm , ta sử dụng 2 vector cho mỗi từ w:
- vector khi w là từ trung tâm
- vector khi w là một từ trong ngữ cảnh của một từ khác
Sau đó, với mỗi cặp từ trung tâm c và một ngữ cảnh của nó, từ o, tính theo công thức:
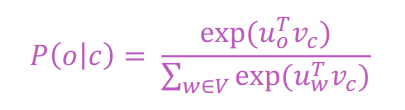
Công thức trên chính là hàm softmax:
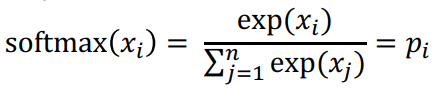
Trong đó, là đại lượng đánh giá mức độ tương đồng về mặt ngữ nghĩa giữa từ c và ngữ cảnh của nó o và được đo bằng tích vô hướng giữa 2 vector. Giá trị này càng cao, mức độ tương đương càng lớn.
Hàm softmax ánh xạ một giá trị tùy ý sang một phân phối xác suất. Hàm này thường được sử dụng trong các kiến trúc Deep Learning.
Ta sẽ tính với tất cả các cặp c và o từ kho dữ liệu:
Tối ưu tham số
Nhớ rằng, việc training mô hình ở đây được hiểu chính là việc ta đi tối ưu bộ tham số sao cho là nhỏ nhất.
Trong trường hợp này, các giá trị cần tối ưu ở đây chính là các vector đại diện cho các từ trong từ điển.
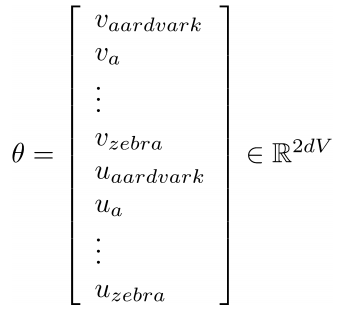
Trong đó, d là số chiều vector cần được biểu diễn, V là số từ trong từ điển và mỗi từ luôn luôn tồn tại 2 vector(vector khi từ đó là từ trung tâm và khi từ đó là ngữ cảnh của một từ khác). Chúng ta sẽ đi tối ưu các tham số này.
Ôn lại một chút về gradient
- Cơ bản nhất:
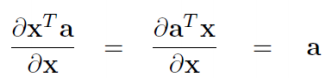
- Chain rule: Nếu và hay thì ta có công thức:
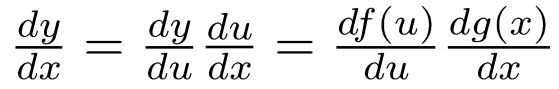
Tiến hành tính đạo hàm cho bằng việc tính đạo hàm cho tất cả các từ trung tâm cho mỗi cửa sổ với tất cả các từ ngữ cảnh.
Gradient Descent
Gradient Descent là một thuật toán để cực tiểu hóa .
Ý tưởng cốt lõi của thuật toán này là: Tại mỗi thời điểm tham số có trạng thái ${\theta}{r} $, tính đạo hàm của với giá trị ${\theta}{r} $ sau đó tiến hành dịch chuyển 1 khoảng nhỏ ngược chiều với đạo hàm. Việc này sẽ giúp ta tiến gần hơn với giá trị cực tiểu của hàm số.
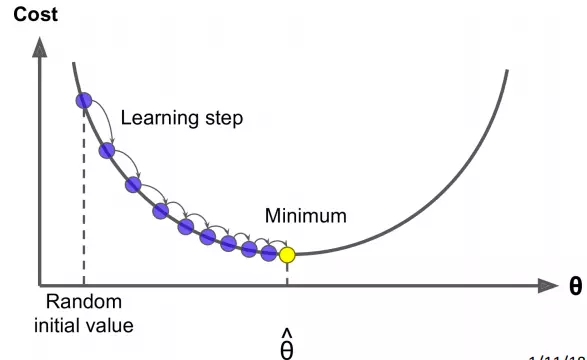
Ví dụ với hàm lồi đơn giản chỉ có 2 tham số, sự dịch chuyển này được diễn ra như hình vẽ dưới đây:
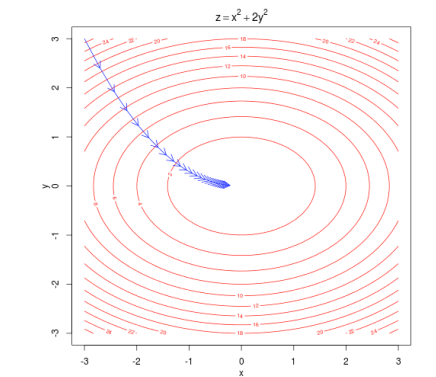
Việc cập nhật tham số được tính toán theo công thức:
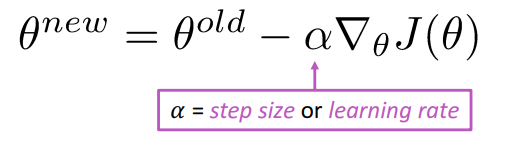
Lưu ý: khi learning rate càng nhỏ, hàm lồi hội tụ càng chậm, nhưng khí để learning rate quá lớn, hàm số có thể phân kì(không thể đạt được trạng thái hội tụ).
Thuật toán:
while True:
theta_grad = evaluate_gradient(J, corpus, theta)
theta = theta - learning_rate* theta_grad
Stochastic Gradient Descent
Tuy nhiên, vấn đề là ở chỗ hàm được tính toán trên tất cả các của sổ trượt trong tập lớn các văn bản nên việc tính đạo hàm của nó là cực kỳ tốn chi phí tính toán và thời gian tính toán cực kỳ nhiều cho 1 lần cập nhật tham số.
Khái niệm Stochastic Gradient Descent(SGD) được hình thành để giải quyết vấn đề này. Thay vì tính đạo hàm và cập nhật lại tham số khi tính toán với tất cả các cửa sổ trượt thì ta thực hiện cập nhật lại sau mỗi lần cửa sổ trượt được quét.
Thuật toán:
while True:
window = sample_window(corpus)
theta_grad = evaluate_gradient(J, window, theta)
theta = theta - learning_rate* theta_grad
Suggested Readings:
- Word2Vec Tutorial - The Skip-Gram Model
- Distributed Representations of Words and Phrases and their Compositionality
- Efficient Estimation of Word Representations in Vector Space
Bài viết tiếp theo sẽ không phải là bài viết lý thuyết mà chúng ta sẽ tiến hành thực hiện Assignments 1- tiến hành cài đặt thuật toán word2vec bằng python để hiểu rõ hơn về cách làm việc của thuật toán này. Bài viết sẽ khả dụng tại đây.
All rights reserved
