Lecture 1: Introduction to NLP and Deep Learning
Bài đăng này đã không được cập nhật trong 5 năm
Nhằm mục đích cung cấp một nguồn tài liệu tiếng Việt tốt cho các bạn bắt đầu tìm hiểu về xử lý ngôn ngữ tự nhiên, mình thực hiện việc dịch lại nội dung bài giảng trong khóa học "CS224n: Natural Language Processing with Deep Learning" của đại học Stanford.
Thông tin chi tiết của khóa học:
- website: http://cs224n.stanford.edu/
- video bài giảng: https://www.youtube.com/watch?v=OQQ-W_63UgQ&list=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6
Bài viết đầu tiên gồm những nội dụng chính sau:
- Xử lý ngôn ngữ tự nhiên là gì? Bản chất của ngôn ngữ con người.
- Deep Learning là gì?
- Tại sao xử lý ngôn ngữ tự nhiên là một nhiệm vụ khó?
- Ứng dụng của Deep Learning cho NLP.
Xử lý ngôn ngữ tự nhiên(NLP) là gì?
Xử lý ngôn ngữ tự nhiên là một lĩnh vực đặc biệt, là sự kết hợp giữa các ngành khoa học máy tính, trí tuệ nhân tạo và ngôn ngữ học.
Mục tiêu của việc xử lý ngôn ngữ tự nhiên là để cho máy tính xử lý và hiểu được ngôn ngữ tự nhiên của con người, giúp máy tính có thể thực hiện được một số nhiệm vụ hữu ích thay cho con người như đặt lịch hẹn, mua bán hàng hóa, dịch từ ngôn ngữ này sang ngôn ngữ khác, các hệ tư vấn, hệ hỏi đáp(Ví dụ: Siri, Google Assistant, Facebook M, Cortana,...).
Để máy tính có thể hiểu được đầy đủ và thể hiện được đúng ý nghĩa của ngôn ngữ là một nhiệm vụ cực kì khó.
Một vài bài toán của xử lý ngôn ngữ tự nhiên như:
- Spell checking: phát hiện và sửa lỗi chính tả
- Finding synonyms: Tìm từ có nghĩa tương đồng
- Extracting information: Trích rút thông tin từ websites như giá sản phẩm, ngày tháng, địa điểm, tên người và tên công ty
- Classifying: Phân loại quan điểm(Tích cực/ Tiêu cực) của một văn bản dài, phân loại tin tức,...
- Machine translation: Dịch từ ngôn ngữ nguồn sang ngôn ngữ đích
- Spoken dialog systems: Các hệ thống hội thoại giữa người và máy(Tư vấn khách hàng tự động, điều khiển thiết bị, đặt hàng,...)
- Question Answering: Các hệ hỏi đáp
- Speech recognition: Nhận dạng giọng nói
Ta chia việc xử lý ngôn ngữ tự nhiên thành các cấp độ khác nhau:
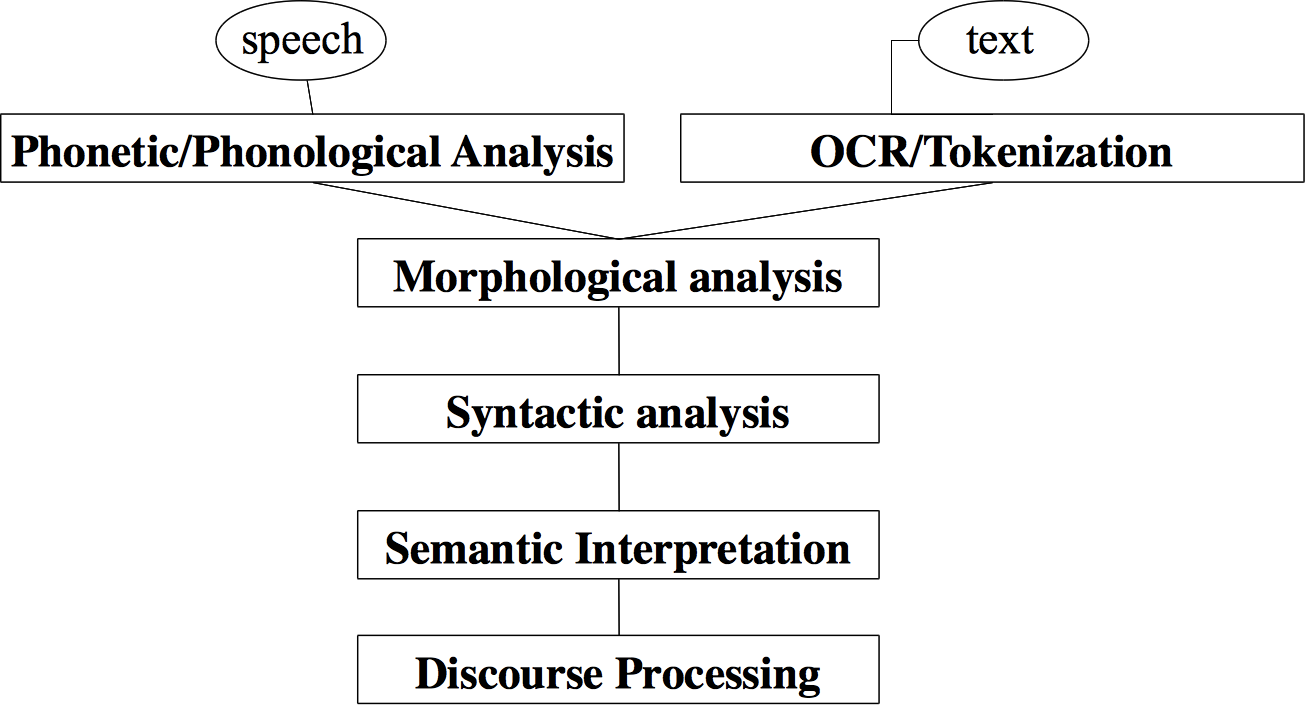
Trong đó, đầu vào thường là hai dạng chính của ngôn ngữ gồm lời nói(speech) và văn bản(text). Sau khi phân tích ngữ âm(đối với dạng speech) hoặc OCR/Tokenization văn bản, chúng ta sẽ trải qua các bước xử lý ngôn ngữ theo các cấp độ:
- Morphological analysis: phân tích hình thái của ngôn ngữ, bao gồm các khâu xử lý:
- Phân đoạn từ vựng (word segmentation): phân giải câu văn được nhập vào thành các từ có thứ tự.
- Phân loại từ (part-of-speech tagging): quyết định từ loại của từ vựng
- Phục hồi thể nguyên dạng của từ (lemmatization)(đối với tiếng anh): làm trở lại nguyên dạng ban đầu các từ vựng bị biến đổi thể ( inflection) hoặc được kết hợp (conjugatetion).
- Syntactic analysis: phân tích cú pháp, tìm hiểu cấu trúc của câu(chủ ngữ, động từ chính,...)
- Semantic interpretaion: diễn dịch ngữ nghĩa, ý nghĩa của câu dựa vào các từ tạo nên câu
- Discourse processing: phân tích ngữ nghĩa dựa trên bối cảnh của câu.
Những điều đặc biệt về ngôn ngữ của con người.
Ngôn ngữ của con người là một hệ thống các tín hiệu/ký hiệu được xây dựng một cách đặc biệt để truyền đạt được thông tin có chủ đích của người viết/người nói. Các tín hiệu/ký hiệu này được con người sử dụng để giao tiếp với nhau theo nhiều cách:
- Âm thanh
- Cử chỉ
- Chữ viết
- Hình ảnh/Tranh vẽ
Mỗi người sẽ có cách mã hóa các tín hiệu/ ký hiệu này khác nhau(giọng nói khác nhau, chữ viết khác nhau, nét vẽ khác nhau). Tuy nhiên, ngữ nghĩa là bất biến và thống nhất không phụ thuộc vào đối tượng thể hiện.
Deep Learning là gì?
Deep Learning là một lĩnh vực con của học máy(Machine learning).
Các phương pháp học máy truyền thống(decision tree, logistic regression, naive bayes, support vector machine,...) làm việc tốt nhờ có sự thiết kế các đặc trưng, các thuộc tính đầu vào của con người(Feature extraction). Machine learning sẽ tối ưu các trọng số của thuật toán để được kết quả dự đoán cuối cùng tốt nhất.
Các phương pháp học máy cơ bản được triển khai dựa trên sự mô tả dữ liệu của bạn bằng các thuộc tính mà máy tính có thể hiểu được(Điều này đòi hỏi người thiết kế phải có sự hiểu biết nhất định trong lĩnh vực của bài toán đó), sau đó các thuộc tính được đưa qua thuật toán học nhằm tối ưu các trọng số của mô hình.
Trái ngược với các phương pháp học máy truyền thống, Deep learning lỗ lực học các biểu diễn tốt nhất, tìm ra những đặc trưng tốt nhất của dữ liệu một cách tự động.
Ở đây có thể hiều, đầu vào cho các thuật toán Deep Learning có thể là dữ liệu thô(Ví dụ: sound, pixels, ký tự hoặc từ ngữ,...)
Lý do để Deep Learning trở lên vượt trội so với các phương pháp truyền thống:
- Các thuộc tính được trích chọn một cách thủ công thường được xác định 1 cách rõ ràng, tuy nhiên, có thể thiếu hoặc thừa thông tin, tốn nhiều thời gian thiết kế và xác thực tính chính xác.
- Việc học ra các thuộc tính được thực hiện dễ dàng và nhanh chóng hơn, linh hoạt hơn trong việc tìm biểu diễn cho thông tin của ngôn ngữ
- Deep Learning có thể học không giám sát(không cần dữ liệu có nhãn sẵn, từ chính dữ liệu thô) hoặc học có giám sát(Với các nhãn đặc biệt như positive/negative).
Trong những năm gần đây, sự phát triển của hệ thống phần cứng(CPU/GPU/TPU) cũng như việc dữ liệu training được cung cấp ngày càng nhiều trên internet đã khiến cho Deep learning ngày càng phát triển mạnh mẽ. Bắt đầu với sự phát triển trong xử lý tiếng nói và hình ảnh, và giờ là xử lý ngôn ngữ tự nhiên(NLP).
Tại sao xử lý ngôn ngữ tự nhiên là một nhiệm vụ khó?
-
Sự phức tạp trong việc biểu diễn, học và sử dụng ngôn ngữ
-
Thông tin được truyền đạt bởi ngôn ngữ không chỉ phụ thuộc và bản thân nó mà còn phụ thuộc vào tính huống, ngữ cảnh hoặc kiến thức hiểu biết sẵn có của con người
-
Ngôn ngữ của con người là không rõ ràng (không giống như ngôn ngữ lập trình)
Ví dụ:
- "Hổ mang bò lên núi."
- "Ông lão đi nhanh quá."
- "Nữ sinh tặng hoa Tổng thống Donald Trump thi Hoa hậu Việt Nam."
Ứng dụng của Deep Learning cho NLP: Deep NLP
Kết hợp các ý tưởng và muc tiêu của xử lý ngôn ngữ tự nhiên với việc sử dụng các biểu diễn đặc trưng của ngôn ngữ thống qua các thuật toán Deep Learning.
Một số cải tiến lớn trong những nằm gần đây trong xử lý ngôn ngữ tự nhiên:
- Cấp độ ngôn ngữ: Speech recognition(Viettel team), Text to Speech(Viettel, VBee), word2vec,...
- Cấp độ xử lý core: parts-of-speech,entities,parsing,...
- Cấp độ ứng dụng hoàn chỉnh: Sentiment Analysis, Question Answering, dialogue agents, machine translation,...
Word2vec:

NLP Tools:Parsing for sentence structure

Sentiment Analysis
Suggested Readings:
- Linear Algebra Review and Reference
- Review of Probability Theory
- Convex Optimization Overview
- More Optimization (SGD) Review
Trong bài viết tiếp theo, chúng ta sẽ tìm hiểu về các phương pháp biểu diễn từ sang không gian vector bằng word2vec từ đó mở rộng ra các kỹ thuật doc2vec, sentence2vec sau này. Bài viết sẽ khả dụng tại đây. Bạn cũng có thể đọc trước một cách tổng quát về các phương pháp word embedding tại bài viết này.
All rights reserved
