Kotlin regular expressions
Bài đăng này đã không được cập nhật trong 7 năm
Kotlin regular expression
Trong kotlin, Chúng ta sử dụng Regular expressions (Cụm từ thông dụng) với Regex Pattern là regular expression để xác định đoạn text mà chúng ta cần tìm kiếm hay thao tác. Nó bao gồm cả chữ và metacharacters(kí tự đặc biệt). Metacharacters là kí tự đặc biệt. Ví dụ với \s chúng ta tìm kiếm khoảng trắng
Chú ý : Kí tự đặc biệt chúng ta phải double kép hoặc trong chuỗi string.
Sau khi chúng ta tạo pattern, Chúng ta có thể sử dụng một trong số chức năng để ứng dụng pattern trên đoạn text. Chức năng bao gồm : matches(), containsMatchIn(), find(), findall(), replace(), and split().
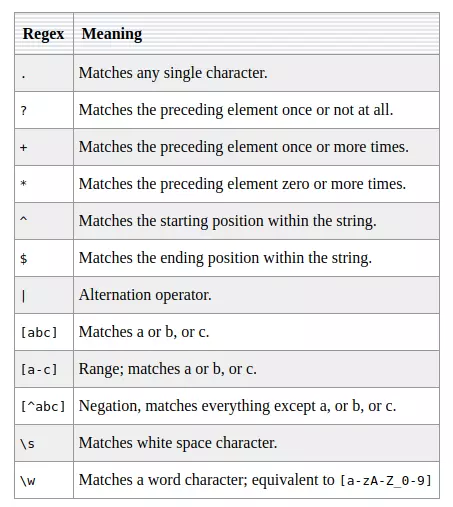
Bảng dưới đây hiện cho bạn một số cú pháp thông thường
Phương thức : matches và containsMatchIn
matches() trả về true nếu pattern khớp hoàn toàn với chuỗi string.
containsMatchIn() tìm thấy ít nhất 1 pattern bên trong chuỗi string.
val words = listOf("book", "bookworm", "Bible",
"bookish","cookbook", "bookstore", "pocketbook")
val pattern = "book".toRegex()
println("*********************")
println("containsMatchIn function")
words.forEach { word ->
if (pattern.containsMatchIn(word)) {
println("$word matches")
}
}
println("*********************")
println("matches function")
words.forEach { word ->
if (pattern.matches(word)) {
println("$word matches")
}
}
Kết quả chúng ta sẽ thấy được như sau :
*********************
containsMatchIn function
book matches
bookworm matches
bookish matches
cookbook matches
bookstore matches
pocketbook matches
*********************
matches function
book matches
Find()
find() trả về kết quả lần đầu tiên gặp pattern trong chuỗi String, bắt đầu tại vị trí bằng không nên để mặc định
val text = "I saw a fox in the wood. The fox had red fur."
val pattern = "fox".toRegex()
val found = pattern.find(text)
val m = found?.value
val idx = found?.range
println("$m found at indexes: $idx")
val found2 = pattern.find(text, 11)
val m2 = found2?.value
val idx2 = found2?.range
println("$m2 found at indexes: $idx2")
Trong đoạn code trên ta có thấy 2 hàm như sau :
val found2 = pattern.find(text, 11)
Bắt đầu tìm từ vị trí thứ 11
val m = found?.value
val idx = found?.range
value: Giá trị được tìm thấy
range : Độ dài của giá trị được tìm thấy từ đầu tới cuối.
Kết quả của phương thức find()
fox found at indexes: 8..10
fox found at indexes: 29..31
Kotlin findAll
FindAll() trả về tất cả giá trị pattern trong chuỗi string. Trả về 1 mảng nếu có nhiều giá trị được tìm thấy
val text = "I saw a fox in the wood. The fox had red fur."
val pattern = "fox".toRegex()
val found = pattern.findAll(text)
found.forEach { f ->
val m = f.value
val idx = f.range
println("$m found at indexes: $idx")
}
Kotlin split function
split() tách chuỗi string ra thành nhiều mảng dựa vào pattern
val text = "I saw a fox in the wood. The fox had red fur."
val pattern = "\\W".toRegex()
val words = pattern.split(text).filter { it.isNotBlank() }
println(words)
Tách chuỗi string ra thành mảng dựa vào tên \w như là khoảng trắng, phẩy, hoặc chấm. Sử dụng chúng để chia từ trong đoạn text.
val words = pattern.split(text).filter { it.isNotBlank() }
Kết quả sau khi tách ra như sau :
[I, saw, a, fox, in, the, wood, The, fox, had, red, fur]
Case insensitive match
Để bật trạng thái lờ trong search match, Chúng ta truyền RegexOption.IGNORE_CASE vào toReget()
val words = listOf("dog", "Dog", "DOG", "Doggy")
val pattern = "dog".toRegex(RegexOption.IGNORE_CASE)
words.forEach { word ->
if (pattern.matches(word)) {
println("$word matches")
}
}
Trong ví dụ trên ta sử dụng patterm là val pattern = "dog".toRegex(RegexOption.IGNORE_CASE)
Kết quả bạn nhận được là :
dog matches
Dog matches
DOG matches
Dấu .
Đại diện cho kí tự đơn lẻ trong text val words = listOf("seven", "even", "prevent", "revenge", "maven", "eleven", "amen", "event")
val pattern = "..even".toRegex()
words.forEach { word ->
if (pattern.containsMatchIn(word)) {
println("$word matches")
}
}
Trong ví dụ, chúng ta có 8 text trong list. Chúng ta sử dụng pattern chứa 2 dấu "." cho mỗi từ
Kết quả : prevent matches eleven matches
Dấu ?.
Định lượng mà khớp mới các kí tự phía trước ko có hoặc nhiều hơn.
val words = listOf("seven", "even", "prevent", "revenge", "maven", "eleven", "amen", "event")
val pattern = ".?even".toRegex()
words.forEach { word ->
if (pattern.matches(word)) {
println("$word matches")
}
}
Ví dụ có nghĩ là trong pattern chúng ta có thể cố 1 kí tự tùy ý. hoặc không có kí tự nào phái trước nó kết quả seven matches even matches
Định lượng{n,m}
Tìm chuỗi ít nhất là n kí tự và nhiều nhất là m kí tự
val words = listOf("pen", "book", "cool", "pencil", "forest", "car",
"list", "rest", "ask", "point", "eyes")
val pattern = "\\w{3,4}".toRegex()
words.forEach { word ->
if (pattern.matches(word)) {
println("$word matches")
} else {
println("$word does not match")
}
}
Trong ví dụ trên chúng t tìm từ có từ 3 đến 4 kí tự trừ khoảng trắng ra. kết quả là :
pen matches book matches cool matches pencil does not match forest does not match car matches list matches rest matches ask matches point does not match eyes matches
Anchors(Neo đậu)
Khớp với vị trí của bên trong của chuỗi String. ^ là vị trí đầu của đoạn text, $ là vị trí cuối của đoạn text.
val sentences = listOf("I am looking for Jane.",
"Jane was walking along the river.",
"Kate and Jane are close friends.")
val pattern = "^Jane".toRegex()
sentences.forEach { sentence ->
if (pattern.containsMatchIn(sentence)) {
println("$sentence")
}
}
Kết quả Jane was walking along the river.
Alternations (Thay thế)
Toán tử | được tạo trong pattern để có thể có nhiều lựa chọn khác nhau
val words = listOf("Jane", "Thomas", "Robert", "Lucy", "Beky", "John", "Peter", "Andy")
val pattern = "Jane|Beky|Robert".toRegex()
words.forEach { word ->
if (pattern.matches(word)) {
println("$word")
}
}
Kết quả sẽ tìm kiếm các kí tự là Jane , Beky, Rebert. nếu là các pattern đó sẽ được cho qua
Subpatterns
Là pattern trong pattern. Subpatterns được tạo với () val words = listOf("book", "bookshelf", "bookworm", "bookcase", "bookish", "bookkeeper", "booklet", "bookmark")
val pattern = "book(worm|mark|keeper)?".toRegex()
words.forEach { word ->
if (pattern.matches(word)) {
println("$word matches")
} else {
println("$word does not match")
}
}
Có nghĩ là tìm kiếm khớp với book + thành phần con. Bạn có thể xem kết quả trả về để rõ hơn
book matches bookshelf does not match bookworm matches bookcase does not match bookish does not match bookkeeper matches booklet does not match bookmark matches
Character classes
Dựa vào kí tự được thiết lập, được đặt trong []
val words = listOf("a gray bird", "grey hair", "great look")
val pattern = "gr[ea]y".toRegex()
words.forEach { word ->
if (pattern.containsMatchIn(word)) {
println("$word")
}
}
Việc tìm kiếm sẽ gồm gray và grey không bao gồm cả great
a gray bird grey hair
Named character classes
Có một số được xác định trước. Như \s khớp với khoảng trắng như [\t\n\t\f\v], \d là số [0-9], \w là chữ [a-zA-Z0-9].
val text = "We met in 2013. She must be now about 27 years old."
val pattern = "\\d+".toRegex()
val found = pattern.findAll(text)
found.forEach { f ->
val m = f.value
println("$m")
}
như pattern ở ví dụ trên sẽ tìm kiếm các kí tự số và kết quả trả về như sau : 2013 27
Capturing groups
Là cách để xử lý nhiều kí tự dưới dạng một đơn vị duy nhất. Capturing groups được tạo bằng cách đoạt trong ngoặt tròn. Ví dụ, (book) là group kí tự độc lập chứ 'b','o','o','k'.
val content = "
The Pattern is a compiledrepresentation of a regular expression.
val pattern = "(<\\/?[a-z]*>)".toRegex()
val found = pattern.findAll(content)
found.forEach { f ->
val m = f.value
println("$m")
}
Ví dụ trên là in ra HTML tags. Có nghĩ là có dấu '<' có thể có hoặc không có kí tự từ a-z do có dấu '?'và có kí tự '>' Kết quả chúng ta nhận được là :
<p>
<code>
</code>
</p>
Kotlin regex với emal Kiểm trả trong chuỗi string và lấy ra các email val emails = listOf("luke@gmail.com", "andy@yahoocom", "34234sdfa#2345", "f344@gmail.com", "dandy!@yahoo.com")
val pattern = "[a-zA-Z0-9._-]+@[a-zA-Z0-9-]+\\.[a-zA-Z.]{2,18}".toRegex()
emails.forEach { email ->
if (pattern.matches(email)) {
println("$email matches")
} else {
println("$email does not match")
}
}
Giải thích như sau:
Email gồm có 5 phần là
1: nickname
2: @
3: domain
4: .
5: .com
Dự vào đó chúng ta có pattern như sau : val pattern = "[a-zA-Z0-9._-]+@[a-zA-Z0-9-]+\.[a-zA-Z.]{2,18}".toRegex()
Kí tự {2,18} chiều dài từ 2 đến 18 kí tự
kết quả chúng ta nhận được là :
uke@gmail.com matches
andy@yahoocom does not match
34234sdfa#2345 does not match
f344@gmail.com matches
dandy!@yahoo.com does not match
Đây là bài mình giới thiệu về Regx trong kotlin. Mong là bài viết này hữu ý cho bạn. Cảm ơn các bạn đã đọc qua bài của ạ. Bạn có thể demo onlien trực tiếp trên : https://try.kotlinlang.org Tài liệu tham khảo : http://zetcode.com/kotlin/regularexpressions/
All rights reserved
