Hiểu lầm kinh điển của DEV qua Demo tối ưu câu lệnh "tụt huyêt áp" - từ 9s còn vài mili giây như thế nào? | High Water Mark trong tối ưu Cơ sở dữ liệu
Bài đăng này đã không được cập nhật trong 3 năm
Cách để bạn thu được nhiều giá trị nhất từ những bài viết của tôi
-
Những bài viết này đều được đúc kết từ dự án thực tế kết hợp với góc giải thích đi từ kiến trúc, bài bản. Rất nhiều bài viết của tôi sẽ làm bạn bất ngờ vì "NGHE RẤT VÔ LÝ so với những gì mà bạn TỪNG BIẾT". Nếu bạn muốn biết những dự án tối ưu mà tôi đã từng thực hiện, bạn có thể ấn vào đây.
-
Hãy đón đọc với một cái tâm rộng mở, và hãy tự mình kiểm chứng (tôi có chia sẻ cách để bạn tự thực hành và biết được những gì tôi chia sẻ có đúng hay không
-
Đừng vội tin những gì tôi viết, bạn hãy tự mình kiểm chứng chúng.
-
Nếu bạn muốn xem toàn bộ những bài viết về tối ưu SQL, tối ưu cơ sở dữ liệu của tôi: bạn có thể tham gia nhóm Tư Duy - Tối Ưu - Khác Biệt
1. Rất nhiều "tiên đề" mà anh em lập trình hiện nay đang hiểu sai
Rất nhiều người anh em lập trình viên tin vào các quy luật như:
- Số lượng bản ghi ít thì sẽ câu lệnh sẽ nhanh
- Cứ quét FULL TABLE sẽ tệ hơn là sử dụng Index
- Cứ đầu tư server thật khủng thì hệ thống sẽ cải thiện hiệu năng
- ...
Tôi đã trực tiếp tối ưu rất nhiều Cơ sở dữ liệu trọng yếu và có cơ hội được cố vấn, huấn luyện cho nhiều anh em lập trình viên và nhận thấy một loạt các "tiên đề" (những thứ mặc định đúng mà không cần chứng minh) của anh em là SAI BÉT. Chính vì sự hiểu sai này mà Cơ sở dữ liệu của các doanh nghiệp thường gặp các hiện tượng như:
- Thời gian triển khai ban đầu thì hoạt động rất mượt
- Sau khi phát triển được một vài năm thì chậm dần, treo
- Anh em DEV chẳng thể giải thích nguyên nhân... Cơ sở dữ liệu giống như một chiếc xe, chúng ta cần hiểu được ĐỘNG CƠ, CÁCH VẬN HÀNH của cái XE đó, nếu như muốn tham gia các dự án tối ưu cho Core banking, Core chứng khoán... Tại bài viết trước, tôi đã chia sẻ 6 bước thực hiện nội bộ của cơ sở dữ liệu khi nhận câu lệnh SQL từ người dùng. Quy trình 6 bước thực hiện ấy là nền tảng mà bất kỳ anh em nào muốn trở thành chuyên gia tối ưu cơ sở dữ liệu đều phải biết. Nếu bạn chưa đọc bài viết này thì có thể click vào đây: Bài viết Tối ưu cơ sở dữ liệu cải thiện 97% thời gian thực hiện bằng một "chấm nhẹ" thế nào? Tại bài viết này tôi sẽ giúp bạn hiểu sâu hơn, cách mà Cơ sở dữ liệu sẽ "lấy các dữ liệu kiểu gì".
2. Kịch bản demo câu lệnh SELECT vẫn làm việc cực kỳ lâu với Table có 0 bản ghi
Nếu nói về một bảng có số lượng bản ghi ÍT, thì trường hợp này sẽ chứng minh cho các bạn thấy: một bảng 0 bản ghi cũng có thể cực kỳ chậm. Vì bản chất quá trình Cơ sở dữ liệu làm việc không dựa vào số lượng bản ghi!! Tôi sẽ làm một Demo như sau:
- Tôi có 2 bảng cùng cấu trúc, có cùng số lượng bản ghi với nhau (0 bản ghi)
- Một bảng tên là FAST
- Một bảng tên là SLOW
- 2 bảng này cùng ở trên 1 cơ sở dữ liệu, nằm trên cùng 1 máy chủ
- Trong demo sử dụng Cơ sở dữ liệu Oracle phiên bản 12.2.0.1
- Thực hiện kiểm thử thời gian thực hiện của hai câu lệnh giống nhau
SELECT COUNT(*) from FAST
SELECT COUNT(*) from SLOW
Để đảm bảo các số liệu là đúng, tôi thực hiện Demo qua video. Các bạn có thể xem tại đây:
3. Phân tích kết quả của Demo
3.1. Về chiến lược thực thi:
Cả 2 câu lệnh đều sử dụng chung 1 chiến lược thực thi: quét toàn bộ bảng (thuật ngữ gọi là FULL TABLE SCAN),
- Chiến lược thực thi của câu lệnh thứ nhất
SELECT COUNT(*) from FAST;
-------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 1 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| FAST | 1 | 2 (0)| 00:00:01 |
- Chiến lược thực thi của câu lệnh thứ hai
SELECT COUNT(*) from SLOW;
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 1 | 121K (1)| 00:00:05|
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| SLOW | 1 | 121K (1)| 00:00:05|
3.2. Về thời gian thực thi của câu lệnh:
- Câu lệnh làm việc trên bảng FAST thực thi với thời gian <1s (cực kỳ nhanh)
- Câu lệnh làm việc trên bảng SLOW thực hiện mất 8.97s (chậm hơn hàng nghìn lần) Khi phân tích chi tiết số công việc mà Cơ sở dữ liệu cần làm việc cần thực hiện để trả ra kết quả, ta thấy có sự khác nhau rất lớn (chi tiết số liệu trong video demo bên dưới)
- Số lượng block dữ liệu phải thực hiện tại câu lệnh trên bảng SLOW gấp hàng trăm nghìn lần so với câu lệnh trên bảng FAST
- Câu lệnh làm trên bảng SLOW cần phải rà soát qua rất nhiều block dữ liệu, trong đó có nhiều block ở trên đĩa cứng
- Câu lệnh làm việc với bảng FAST chỉ cần thực hiện trên bộ nhớ
- Các số liệu này cũng rất hợp lý với việc thời gian thực thi giữa 2 câu lệnh chênh nhau vài nghìn phần trăm
 (từ đơn vị mili second sang ~9s)
(từ đơn vị mili second sang ~9s)
4. Giải thích nguyên lý
Như vậy bản chất của việc Cơ sở dữ liệu thực hiện lấy dữ liệu không phải dựa vào số lượng bản ghi.
Bạn có thể hình dung các Table giống như những cốc đựng nước.
Hành động thêm dữ liệu vào Table, cũng giống như chúng ta đổ nước vào trong cốc.
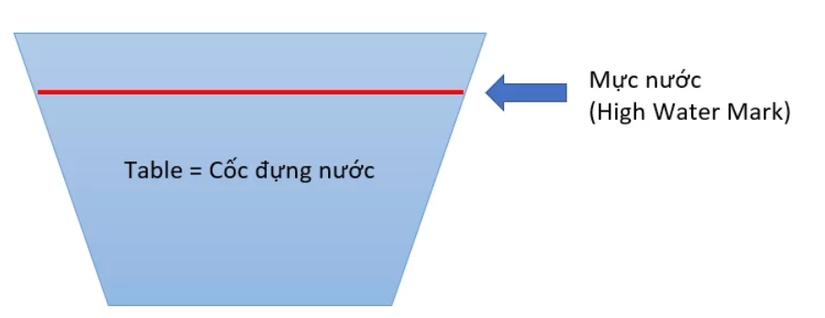
Khi bạn đổ nước vào, phần nước cao nhất lúc này sẽ đánh dấu trên cốc nước, gọi là "Mực nước" - hay thuật ngữ trong cơ sở dữ liệu gọi là High Water Mark.
Bây giờ nếu chúng ta muốn đổ bớt nước trong cốc ra ngoài, chuyện gì sẽ xảy ra với "Mực nước" đã được đánh dấu ở phía trước?
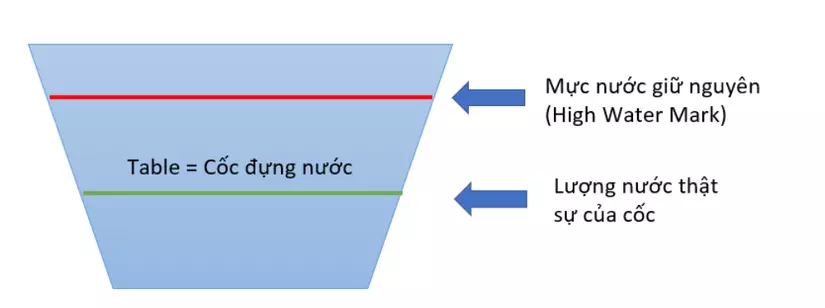 Tại trường hợp này:
Tại trường hợp này:
- Mặc dù lượng nước thật sự của cốc đã giảm đi, tuy nhiên "Mốc đánh dấu" ban đầu thì không hề giảm (High Water Mark vẫn còn như cũ) Vấn đề này cũng giống hệt như việc khi bạn thực hiện lệnh DELETE từ TABLE:
- Số lượng bản ghi trong bảng giảm đi
- High water mark của phần lưu trữ thì không hề giảm Khi cơ sở dữ liệu tìm kiếm thông tin, nó cần tìm toàn bộ vùng dữ liệu từ block đầu tiên cho tới block được đánh dấu bởi high water mark. Chính vì vây mặc dù số lượng bản ghi của bảng cực kỳ nhỏ (0 bản ghi), nhưng nếu High Water Mark rất lớn thì câu lệnh vẫn chạy cực kỳ lâu
5. Đừng tin tôi, bạn hãy tự kiểm chứng những gì tôi vừa nói về High Water Mark
Bạn có thể giả lập và kiểm tra những gì tôi vừa nói một cách rất đơn giản
Bước 1: Hãy tạo 1 Table tùy ý
Bước 2: Insert thật nhiều dữ liệu vào bảng (cho bảng có dung lượng tầm 2-3 GB cho việc test là đẹp)
Bước 3: Thực hiện câu lệnh DELETE toàn bộ các bảng ghi trong bảng và thực hiện COMMIT. Kết thúc bước này bảng của bạn sẽ có 0 bản ghi
Bước 4: Thực hiện câu lệnh
SELECT * FROM <Tên TABLE>
Câu lệnh này sẽ trả ra 0 bản ghi đúng không nào?
Hãy cho tôi biết thời gian thực hiện của câu lệnh là bao nhiêu giây nhé
6. Cách để kiểm tra thông tin High Water Mark và ứng dụng trong bài toán tối ưu thực tế
6.1. Cùng tôi thực hiện một Demo nữa
Chúng ta cùng nhau tạo một bảng có 2 triệu bản ghi để phục vụ demo việc tìm kiếm thông tin High Water Mark
SQL> create sequence wecommit_seq start with 1 increment by 1;
Sequence created.
SQL> create table wecommit_test(id number, col1 varchar2(30), col2 varchar2(30), col3 varchar2(30),col4 varchar2(30),col5 varchar2(30),col6 varchar2(30));
Table created.
SQL> BEGIN
FOR i IN 1 ..2000000 LOOP
insert into wecommit_test values(wecommit_seq.nextval, 'TRAN QUOC HUY','TRAN QUOC HUY','TRAN QUOC HUY','WECOMMIT','WECOMMIT','WECOMMIT');
commit;
END LOOP;
END;
Kết quả của script giả lập dữ liệu như sau:
- Tại đây chúng ta đã tạo ra table WECOMMIT_TEST có 2 triệu bản ghi dữ liệu.
- Dữ liệu của bảng WECOMMIT_TEST có dạng:
- Cột đầu tiên có giá trị tăng dần từ 1
- Ba cột tiếp theo có giá trị là TRAN QUOC HUY
- Ba cột cuối cùng có giá trị là WECOMMIT
- Ví dụ dữ liệu của bảng WECOMMIT_TEST
 Thực hiện xóa một số dữ liệu của bảng
Thực hiện xóa một số dữ liệu của bảng
SQL> DELETE FROM wecommit_test WHERE id between 1000 and 3000;
SQL> DELETE FROM wecommit_test WHERE id between 1000 and 3000;
2001 rows deleted.
SQL> DELETE FROM wecommit_test WHERE id between 5000 and 6500;
1501 rows deleted.
SQL> DELETE FROM wecommit_test WHERE id between 10000 and 20000;
10001 rows deleted.
SQL> DELETE FROM wecommit_test WHERE id between 200000 and 300000;
100001 rows deleted.
SQL> DELETE FROM wecommit_test WHERE id between 500000 and 900000;
400001 rows deleted
SQL> DELETE FROM wecommit_test WHERE id between 1000000 and 130000;
300001 rows deleted.
SQL> commit;
Commit complete
6.2. Script kiểm tra thông tin HWM của table, bạn có thể áp dụng ngay trong các hệ thống Production.
Để kiểm tra thông tin High Water Mark của table WECOMMIT_TEST các bạn có thể sử dụng lệnh sau
SQL> SET SERVEROUT ON
DECLARE
CURSOR cu_tables IS
SELECT a.owner,
a.table_name
FROM dba_tables a
WHERE a.table_name = '&TABLE_NAME'
AND a.owner = '&OWNER';
op1 NUMBER;
op2 NUMBER;
op3 NUMBER;
op4 NUMBER;
op5 NUMBER;
op6 NUMBER;
op7 NUMBER;
BEGIN
Dbms_Output.Enable(1000000);
Dbms_Output.Put_Line('TABLE UNUSED BLOCKS TOTAL BLOCKS HIGH WATER MARK');
Dbms_Output.Put_Line('------------------------------ --------------- --------------- ---------------');
FOR cur_rec IN cu_tables LOOP
Dbms_Space.Unused_Space(cur_rec.owner,cur_rec.table_name,'TABLE',op1,op2,op3,op4,op5,op6,op7);
Dbms_Output.Put_Line(RPad(cur_rec.table_name,30,' ') ||
LPad(op3,15,' ') ||
LPad(op1,15,' ') ||
LPad(Trunc(op1-op3-1),15,' '));
END LOOP;
END;
/
Đoạnh lệnh trên cho phép bạn kiểm tra thông tin các block dữ liệu đã được cấp phát và HWM của một table bất kỳ. Trong đoạn lệnh sử dụng 2 biến:
- Biến &TABLE_NAME: bạn nhập tên của Table muốn kiểm tra (nhớ là nhập IN HOA giá trị này)
- Biến &OWNER: bạn nhập tên của uesr sở hữu table (nhớ là nhập IN HOA giá trị này)
Nhập giá trị cần tìm kiếm như sau:
Enter value for table_name: WECOMMIT_TEST
old 6: WHERE a.table_name = '&TABLE_NAME'
new 6: WHERE a.table_name = 'WECOMMIT_TEST'
Enter value for owner: HUYTQ
old 7: AND a.owner = '&OWNER';
new 7: AND a.owner = 'HUYTQ';
--- Kết quả
TABLE UNUSED BLOCKS TOTAL BLOCKS HIGH WATER MARK
WECOMMIT_TEST 238 22528 22289
Ghi chú:
- Một block dữ liệu có thể chứa nhiều bản ghi, do đó số block chứa dữ liệu sẽ khác với số lượng bản ghi!
Hình ảnh sử dụng block segment của table như sau:
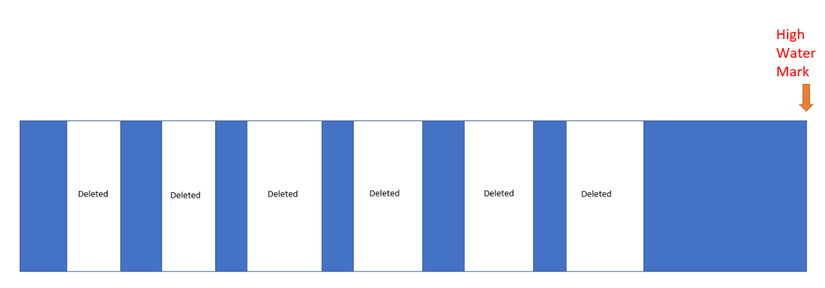 Theo kết quả phân tích bên trên:
Theo kết quả phân tích bên trên: - Tổng số block dữ liệu màu trắng (dữ liệu đã bị xóa): chiếm 238 Block
- Tổng số dữ liệu màu xanh: 22528 block
- High Water Mark đánh dấu của table: 22289.
6.2. Việc hiểu về High Water Mark có thể giúp bạn tối ưu trong thực tế ra sao
Do trong quá trình Insert dữ liệu, Cơ sở dữ liệu sẽ thực hiện đưa dữ liệu lấp đầy các khoảng trống bên dưới High Water Mark (việc này sẽ khiến công việc bị chậm), trong những hệ thống yêu cầu việc Insert dữ liệu nhanh chóng, chúng ta có kỹ thuật bắt buộc tiến trình sẽ Insert ở phía bên trên High Water Mark, do đó tăng tốc đáng kể các job Insert. Với những Table bị phân mảnh quá nhiều, chúng ta có thể thực hiện tối ưu lại, giúp dữ liệu được sắp xếp liền mạch hơn, từ đó giảm thiểu số lượng block cần phải thực hiện khi SELECT.
7. Câu hỏi dành cho bạn đọc
Các bạn hãy nghiên cứu và trả lời các câu hỏi sau nhé.
Những câu hỏi này sẽ giúp các bạn tiến gần hơn các công việc tối ưu dữ liệu trong dự án lớn.
- Làm thế nào phát hiện được toàn bộ các bảng đang bị phân mảnh lớn trong Cơ sở dữ liệu?
- Khi phát hiện các bảng đang bị phân mảnh lớn, chúng ta có các giải pháp gì?
- Giả sử tôi đang có một bảng bị phân mảnh tên là bảng SLOW, nếu tôi tạo một bảng mới tên là SLOW_NEW sử dụng câu lệnh dưới đây, thì bảng SLOW_NEW có bị phân mảnh không?
CREATE TABLE SLOW_NEW AS SELECT * FROM SLOW;
Hãy email cho tôi biết giải pháp của bạn nhé. Tôi sẽ lựa chọn ra 1 bạn có phương án hay nhất để phân tích trong 1 bài viết khác.
Ghi chú: Định kỳ thứ 5 hàng tuần, tôi sẽ chia sẻ các bài viết liên quan đến tối ưu Cơ sở dữ liệu dành cho anh em lập trình. Các bạn có thể vào nhóm sau để không bỏ lỡ những bài viết của tôi: Nhóm Tư Duy - Tối Ưu - Khác Biệt
Các bạn có thể đón đọc và phản hồi góp ý qua email: huy.tranquoc@wecommit.com.vn
8. Nếu bạn muốn xem các giải pháp tối ưu được áp dụng trong những hệ thống Production giao dịch 24x7
Nếu bạn chưa thuộc nhóm học viên đặc quyền của tôi nhưng vẫn muốn xem một số giải pháp tối ưu thực tế (giải pháp chi tiết, phân tích cụ thể), bạn có thể nhận mật khẩu để đọc giải pháp thông qua nhóm Zalo sau: Nhóm Tư Duy - Tối Ưu - Khác Biệt
9. Dành cho các bạn muốn kết nối với tôi và nhận thêm nhiều thông tin có giá trị hơn nữa.
- Các bạn có thể đăng ký kênh youtube của tôi: Kênh youtube Trần Quốc Huy
- Nếu muốn kết bạn với tôi qua facebook cá nhân: https://www.facebook.com/tran.q.huy.71
- Facebook Fanpage của tôi: https://www.facebook.com/ora.huytran
- Email: huy.tranquoc@wecommit.com.vn
- Zalo: 0888549190
All rights reserved
