1 triệu bản ghi VARCHAR2(400) và VARCHAR2(2) có hiệu năng khác biệt ra sao - Thay đổi thứ tự các bảng khi JOIN có ảnh hưởng hiệu năng không?
Bài đăng này đã không được cập nhật trong 3 năm
Tại bài này, tôi sẽ giúp các bạn giải quyết "một lần và mãi mãi" những hiểu lầm kinh điển sau
- Hiệu năng của câu lệnh phụ thuộc vào số lượng bản ghi của bảng - đúng hay sai
- Cùng số lượng bản ghi thì thiết kế kiểu dữ liệu ảnh hưởng thế nào đến hiệu năng
- Thay đổi thứ tự các bảng trong câu lệnh JOIN khi chúng ta viết lệnh SQL thì có ảnh hưởng đến hiệu năng hay không
> Ghi chú:
- Nếu bạn muốn đọc** toàn bộ những kỹ thuật tối ưu** mà tôi đã áp dụng trong các dự án tại FPT, Sở giao dịch chứng khoán Hà Nội (HNX), EVN, VNPT, Mobifone..., bạn có thể xem tại đây: Link toàn bộ kỹ thuật tối ưu
- Nếu bạn muốn xem danh sách các dự án mà tôi đã trực tiếp tối ưu: Danh sách dự án của tôi
- Nếu bạn muốn đọc những bài viết có mật khẩu (các bài viết có giải pháp, bài viết đặc biệt quan trọng), bạn có thể lấy mật khẩu trong nhóm Zalo Tư Duy - Tối Ưu - Khác Biệt, bạn tham gia nhóm miễn phí. Click vào link sau để tham gia nhóm: Tham gia nhóm.
1. Cùng 1.000.000 bản ghi thì VARCHAR2(400) và VARCHAR(2) có hiệu năng khác nhau thế nào?
1.1. So sánh hiệu năng của 3 bảng cùng số lượng bản ghi nhưng thiết kế kiểu dữ liệu khác nhau - VARCHAR2(400) và VARCHAR2(400)
Bước 1: Tạo bảng
Tạo 2 bảng có 20 cột varchar2(400) và 1 bảng có 20 cột varchar2(2)
- Bảng TEST_BIG_VARCHAR_2 sử dụng để chứa toàn những dữ liệu thật sự có độ dài 400 bytes.
- Bảng TEST_BIG_VARCHAR chỉ sử dụng để chứa những dữ liệu có độ dài tối đa là 2
- Tạo một bảng tên là test_small_varchar có cùng số lượng cột, nhưng kiểu giá trị là VARCHAR2(2). Bảng này sẽ có dữ liệu giống hệt với bảng test_big_varchar
CREATE TABLE TEST_BIG_VARCHAR_2
(
col1 VARCHAR2 (400),
col2 VARCHAR2 (400),
col3 VARCHAR2 (400),
col4 VARCHAR2 (400),
col5 VARCHAR2 (400),
col6 VARCHAR2 (400),
col7 VARCHAR2 (400),
col8 VARCHAR2 (400),
col9 VARCHAR2 (400),
col10 VARCHAR2 (400),
col11 VARCHAR2 (400),
col12 VARCHAR2 (400),
col13 VARCHAR2 (400),
col14 VARCHAR2 (400),
col15 VARCHAR2 (400),
col16 VARCHAR2 (400),
col17 VARCHAR2 (400),
col18 VARCHAR2 (400),
col19 VARCHAR2 (400),
col20 VARCHAR2 (400)
);
CREATE TABLE test_big_varchar
(
col1 VARCHAR2 (400),
col2 VARCHAR2 (400),
col3 VARCHAR2 (400),
col4 VARCHAR2 (400),
col5 VARCHAR2 (400),
col6 VARCHAR2 (400),
col7 VARCHAR2 (400),
col8 VARCHAR2 (400),
col9 VARCHAR2 (400),
col10 VARCHAR2 (400),
col11 VARCHAR2 (400),
col12 VARCHAR2 (400),
col13 VARCHAR2 (400),
col14 VARCHAR2 (400),
col15 VARCHAR2 (400),
col16 VARCHAR2 (400),
col17 VARCHAR2 (400),
col18 VARCHAR2 (400),
col19 VARCHAR2 (400),
col20 VARCHAR2 (400)
);
CREATE TABLE TEST_SMALL_VARCHAR
(
col1 VARCHAR2 (2),
col2 VARCHAR2 (2),
col3 VARCHAR2 (2),
col4 VARCHAR2 (2),
col5 VARCHAR2 (2),
col6 VARCHAR2 (2),
col7 VARCHAR2 (2),
col8 VARCHAR2 (2),
col9 VARCHAR2 (2),
col10 VARCHAR2 (2),
col11 VARCHAR2 (2),
col12 VARCHAR2 (2),
col13 VARCHAR2 (2),
col14 VARCHAR2 (2),
col15 VARCHAR2 (2),
col16 VARCHAR2 (2),
col17 VARCHAR2 (2),
col18 VARCHAR2 (2),
col19 VARCHAR2 (2),
col20 VARCHAR2 (2)
)
Bước 2: Thực hiện Insert 1.000.000 bản ghi vào cả 3 bảng trên
- Thực hiện đối với bảng: TEST_BIG_VARCHAR_2
BEGIN
FOR i IN 1 .. 1000000
LOOP
INSERT INTO TEST_BIG_VARCHAR_2
VALUES (LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400),
LPAD ('A', 400));
COMMIT;
END LOOP;
END;
PL/SQL procedure successfully completed.
- Thực hiện với bảng TEST_SMALL_VARCHAR
BEGIN
FOR i IN 1 .. 1000000
LOOP
INSERT INTO TEST_SMALL_VARCHAR
VALUES ('1',
'2',
'3',
'4',
'5',
'6',
'7',
'8',
'9',
'10',
'11',
'12',
'13',
'14',
'15',
'16',
'17',
'18',
'19',
'20');
COMMIT;
END LOOP;
END;
PL/SQL procedure successfully completed.
Bước 3: Đánh giá hiệu năng với các câu lệnh TABLE ACCESS FULL
Như vậy lúc này 3 bảng đều có số lượng bản ghi giống nhau. Để đảm bảo tính chính xác của tất cả việc demo bên dưới, tôi sẽ tiến hành gather statistics cho toàn bộ 3 bảng trên.
SQL> EXEC dbms_stats.gather_table_stats('HUYTQ','TEST_BIG_VARCHAR_2',cascade=>TRUE);
PL/SQL procedure successfully completed.
Elapsed: 00:02:34.90
SQL> EXEC dbms_stats.gather_table_stats('HUYTQ','TEST_BIG_VARCHAR',cascade=>TRUE);
PL/SQL procedure successfully completed.
Elapsed: 00:00:01.86
SQL> EXEC dbms_stats.gather_table_stats('HUYTQ','TEST_SMALL_VARCHAR',cascade=>TRUE);
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.78
Chúng ta kiểm tra dung lượng của 3 bảng này xem có khác gì nhau không nhé.
select owner, segment_name, bytes/1024/1024 "SIZE_MB" from dba_segments where segment_name in ('TEST_BIG_VARCHAR','TEST_SMALL_VARCHAR','TEST_BIG_VARCHAR_2');
OWNER SEGMENT_NAME SIZE_MB
------ -------------------- ----------
HUYTQ TEST_BIG_VARCHAR_2 17270
HUYTQ TEST_SMALL_VARCHAR 62
HUYTQ TEST_BIG_VARCHAR 62
Như vậy với cùng số lượng bản ghi:
- Hai bảng TEST_SMALL_VARCHAR và TEST_BIG_VARCHAR có cùng dung lượng vì bản chất dữ liệu đưa vào là giống nhau (mặc dù định nghĩa chiều dài kiểu ký tự một bảng là VARCHAR2, một bảng là VARCHAR2(400)).
- Bảng TEST_BIG_VARCHAR_2 có dung lượng lớn hơn nhiều lần: 17270 MB (so với 62MB của 2 bảng bên trên).
Do dung lượng bảng khác nhau, nên sẽ ảnh hưởng rất nhiều đến hiệu năng của các câu lệnh cần phải thực hiện TABLE ACCESS FULL.
Ví dụ như sau: Chúng ta cùng đánh giá chiến lược và thông số khi thực thi của 3 câu lệnhSELECT * FROM <TABLE_NAME>
select * from TEST_BIG_VARCHAR_2

select * from TEST_BIG_VARCHAR

select * from TEST_SMALL_VARCHAR

Cả 3 câu lệnh trên đều có mục đích: lấy ra toàn bộ 1.000.000 bản ghi. Tuy nhiên thời gian và chi phí thực hiện các câu lệnh cho chúng ta thấy sự chênh lệch rất lớn:
- Thời gian của câu lệnh làm việc trên bảng TEST_BIG_VARCHAR_2 ước tính là** 1 giờ, 59 phút và 42 giây)**. Chi phí để thực hiện câu lệnh là 598K
- Thời gian của 2 câu lệnh còn lại chỉ mất ước tính 26s, chi phí thực hiện là 2131 (nhỏ hơn 280 lần!!!)
Bước 4: Đánh giá hiệu năng khi làm việc với Index
Bây giờ chúng ta sẽ xem nếu tạo Index trên 3 bảng này thì có sự khác biệt nào không nhé. Tôi sẽ tạo Index trên cả 3 cột Col1 của 3 bảng
SQL> create index idx_small_col1 on test_small_varchar(col1);
Index created.
Elapsed: 00:00:01.16
SQL> create index idx_big_col1 on test_big_varchar(col1);
Index created.
Elapsed: 00:00:01.57
SQL> create index idx_bigdata_col1 on test_big_varchar_2(col1);
Index created.
Elapsed: 00:01:05.48
Thời gian tạo Index cũng có sự chênh lệch lớn:
- Tạo index trên 2 bảng đầu tiên chỉ mất thời gian gần như nhau (1.57s)
- Thời gian tạo index trên bảng TEST_BIG_VARCHAR_2 là hơn 1 phút.
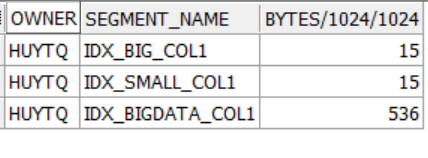
Dung lượng các Index tạo ra cũng có sự chênh lệch lớn :
SELECT owner, segment_name, bytes / 1024 / 1024
FROM dba_segments
WHERE segment_name IN ('IDX_BIGDATA_COL1', 'IDX_SMALL_COL1', 'IDX_BIG_COL1')
ORDER BY 3;
Kết quả:
SQL> select * from test_big_varchar_2 where col1='0';

Statistics
0 recursive calls
0 db block gets
5 consistent gets
0 physical reads
0 redo size
1597 bytes sent via SQL*Net to client
513 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
SQL> select * from test_big_varchar where col1='0';

Statistics
0 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
1597 bytes sent via SQL*Net to client
513 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
SQL> select * from test_small_varchar where col1='0'

Statistics
0 recursive calls
0 db block gets
3 consistent gets
0 physical reads
0 redo size
1597 bytes sent via SQL*Net to client
513 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
Khi tìm kiếm trên Index, số lượng block cần phải đọc của câu lệnh làm việc trên bảng TEST_SMALL_VARCHAR và bảng TEST_BIG_VARCHAR chỉ là 3 block, trong khi làm việc với bảng TEST_BIG_VARCHAR_2 là 5 block
2. Thay đổi thứ tự viết câu lệnh có ảnh hưởng đến hiệu năng không?
2.1. Thay đổi thứ tự trong mệnh đề WHERE khi làm việc với 1 bảng
Trường hợp 1: Nếu bảng không có Index
Chúng ta sẽ đánh giá hiệu năng của 2 câu lệnh sau
- Câu lệnh thứ nhất:
select * from emp where first_name='TRAN' and last_name='HUY'
- Câu lệnh thứ hai thực hiện đổi chỗ các cột tìm kiếm trong mệnh đề WHERE
select * from emp where last_name='HUY' and first_name='TRAN'
Chiến lược thực thi của 2 câu lệnh như sau:
select * from emp where first_name='TRAN' and last_name='HUY'
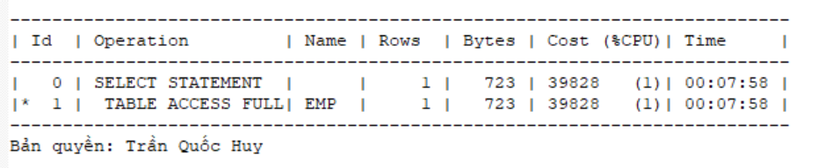
select * from emp where last_name='HUY' and first_name='TRAN'
Hai câu lệnh này cùng có 1 chiến lược thực thi: quét toàn bộ các block dữ liệu trong bảng (TABLE ACCESS FULL).
Do cùng chiến lược thực thi nên thời gian và hiệu năng của hai cách viết này là như nhau.
Bây giờ ta sẽ xem xét 2 trường hợp khi bảng có Index - Trường hợp gặp nhiều nhất trong các dự án thực tế.
Mật khẩu và nội dung phần phân tích này tôi gửi trong nhóm Zalo Tư Duy - Tối Ưu - Khác Biệt. Đây là nhóm dành cho những anh em DEV muốn tìm hiểu chuyên sâu về Tư duy tối ưu cũng như kỹ thuật tối ưu. Bạn có thể tham gia nhóm (miễn phí). Link tham giá nhóm: https://zalo.me/g/spohzm074
2.2. Thay đổi thứ tự trong câu lệnh JOIN nhiều bảng
Chúng ta sẽ xem xét các câu lệnh có cùng ý nghĩa nghiệp vụ sau
- Câu lệnh thứ nhất:
select * from emp e, dept d where e.deptno=d.deptno and e.salary=1000 and d.DNAME like '%K%'
- Câu lệnh thứ hai: thực hiện đổi chỗ hai bảng DEPT và EMP trong thứ tự JOIN
select * from dept d, emp e where e.deptno=d.deptno and e.salary=1000 and d.DNAME like '%K%'
- Câu lệnh thứ ba: thực hiện đổi chỗ hai bảng DEPT và EMP trong thứ tự JOIN, đồng thời đổi chỗ cả vị trí trong mệnh đề WHERE
select * from dept d, emp e where e.salary=1000 and d.deptno=e.deptno and d.DNAME like '%K%'
Chiến lược thực thi của các câu lệnh như sau
- Câu lệnh thứ nhất:
select * from emp e, dept d where e.deptno=d.deptno and e.salary=1000 and d.DNAME like '%K%'
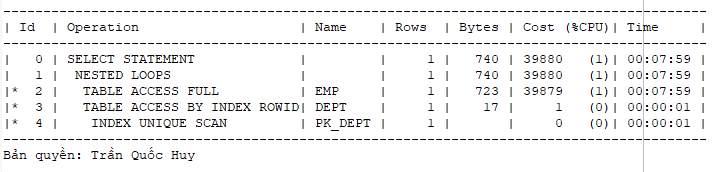
- Câu lệnh thứ hai:
select * from dept d, emp e where e.deptno=d.deptno and e.salary=1000 and d.DNAME like '%K%'
- Câu lệnh thứ ba:
select * from dept d, emp e where e.salary=1000 and d.deptno=e.deptno and d.DNAME like '%K%'
3. Bảng có 0 bản ghi thì có thể bị chậm hay không?
Câu trả lời là CÓ. Tôi đã từng chia sẻ demo và giải thích nguyên lý một cách chi tiết. Các bạn có thể tìm đọc lại nội dung này trong nhóm Zalo Tư Duy - Tối Ưu - Khác biệt
4. Link bài viết gốc
Các bạn có thể đọc bài viết gốc tại đây: https://wecommit.com.vn/varchar2-va-varchar2400/
5. Tổng hợp toàn bộ các kỹ thuật tối ưu Cơ sở dữ liệu (cập nhật liên tục) của tôi
- Tổng hợp toàn bộ các bài viết về tối ưu của tôi (cập nhật hàng tuần): https://wecommit.com.vn/tong-hop-link-cac-bai-viet-hay-tren-trang-wecommit-com-vn/
6. Thông tin tác giả
- Tác giả: Trần Quốc Huy - Founder & CEO Wecommit
- Facebook: https://www.facebook.com/tran.q.huy.71
- Email: huy.tranquoc@wecommit.com.vn
- Youtube: Trần Quốc Huy
- Số điện thoại: 0888549190
- Nhóm Zalo chia sẻ các bài viết về Tư duy Tối ưu, các bài viết tối ưu chuyên sâu về Cơ sở dữ liệu trong những dự án lớn: Tham gia nhóm tại đây
All rights reserved
